




查询优化器(Query Optimizer)是数据库的标志技术,也是其中最难懂、最少懂的部分(以及事务处理[54])。它能够影响SQL执行速度达2x~100x[14](例如扫描vs索引、Join实现的选择)。此外,
现代数据库语言支持往往远超SQL[52],数据种类多样,查询优化器有更大发挥空间;例如嵌入Python/Java语言,直接调用Spark、Hadoop,组建数据处理管线(Pipeline/Dataflow)。
数据库对大数据、OLAP 、异构集成的支持,对(Continuous) Stream、Graph、机器学习的集成,也为查询优化器带来新的挑战。
数据库之外,查询优化器的设计可被学习至更多领域,例如
如何将CSV文件[35]当作数据表用SQL查询,如何用类SQL语言进行日志搜索。更丰富的工具引入更丰富的接口,直至领域语言(Domain Specific Language、DSL),产生语法解析和优化的需求。
代价模型(Cost Model)的设计[6],如何计量建模CPU、IO、网络开销,可应用于更多系统的资源调度,如分布式存储。
搜索巨大复杂空间的方法,例如SQL执行计划。更重要的是如何将其抽象成整洁易扩展的设计。
目录
复杂度的来源
基本名词
基于代价的优化器(Cost-based Optimizer)、基于规则的优化器(Rule-based Optimizer )、Heuristic-based optimizer
Selectivity、Cardinality
逻辑计划(Logical Plan)、物理计划(Physical Plan)
Operator、Logical Operator、Physical Operator
Volcano和Cascades
基本概念 – 三大组件
基本概念 – Operator
基本概念 – Pattern/Rule
基本概念 – Memo
基本概念 – 任务调度
Volcano与Cascades的区别
搜索计划空间(Plan Enumeration)
局部最优问题
关于Property和Enforcer
搜索优先级
避免重复搜索
剪枝(Pruning)
搜索退出条件
Join Order Enumeration
搜索算法的详细例子
Columbia的详细例子
Memo的详细例子
代价模型(Cost Model)
基础Cost Variable
更复杂的代价模型
代价模型的分析和验证
统计信息(Statistics)
柱状图(Histogram)
Statistics Derivation
查询执行(Query Execution)
切分和平衡
NUMA架构
分布式Operator
总结
相关资料
复杂度的来源
组合[33]是宇宙神秘之一,简单规则[51]即可突破宇宙原子数,空间结构[53]可研究但仍不足。
SQL语句被翻译为关系代数(Relation Algebra)表达式后,查询优化器需在大量等价表达中寻找最优。逻辑(Logical)优化的典型例子是交换Join的顺序,见下表[10P27],组合增长迅速。

进一步,物理优化需选择Join实现算法,如Nested-loop Join、Hash Join、Index Join、Sort-merge Join;更多组合。分布式数据库还需选择Join数据移动策略,如Broadcast、Shuffle,甚至更细致的Track Join[19]。(Join组合如此之多,大部分优化器甚至只搜索Left-deep Tree,而忽略Bushy Tree)
除Join外,诸多其它Operator同样需要优化,如谓词下推(Predict Pushdown)。此外,优化搜索需要在有限时间完成,否则增加SQL整体执行时间;需要准确计算每种执行计划的代价;还需要维护代价相关的统计信息,尤其是不同模式的数据快速输入时。
基本名词
基于代价的优化器(Cost-based Optimizer)、基于规则的优化器(Rule-based Optimizer )、Heuristic-based optimizer
它们的差异在于判断执行计划好坏的方法。
基于规则的优化器根据固定的、通常是手写的规则,决定哪个执行计划更好。例如当Selectivity小于0.01时使用索引,否则做全表扫描。Heuristic-based optimizer一般与基于规则的优化器同义,Heuristic指人工想出规则(启发式)。
基于代价的优化器实地计算各个执行计划的CPU、IO等代价(代价模型),然后比较好坏。显而易见,基于代价的优化器更加准确[6],也更加复杂。现代优化器(通常以Volcano/Cascades为原型)和企业级数据库(Oracle、SQL Server等),主流都是基于代价的优化器。
(此外,Rule-based、Cost-based有时也用来区分查询计划遍历方法[14],例如Rule-based用固定规则枚举Join顺序,而Cost-based通常配套动态规划搜索。)
实际上,基于代价的优化器常常结合基于规则的优化。首先做基于规则的优化,例如那些总是更优的转换(Transform);然后对不确定的部分基于代价搜索。例如CockroachDB使用基于代价的优化器,但用声明式的Optgen领域语言[37]定义了许多规则转换。
Selectivity、Cardinality
Selectivity指查询会从表中返回多大比例的数据。例如表有1000行(Tuple),Select where column < 10返回10行,那么Selectivity是1%。当Selectivity极高时,全表扫面通常比索引查询更高效。
Cardinality的基本含义是表的unique行数[34],查询计划中常指Operator需要处理的行数[36]。初始表的行数是叶节点Operator需处理的Cardinality。Operator的输出(例如Join)可看作广义的表,它又是上游Operator(下一个待处理的Operator)的Cardinality。Operator输出输入的比例是Selectivity。
显而易见,Cardinality估算(Cardinality Estimation)是为执行计划计算代价的核心[14]。
逻辑计划(Logical Plan)、物理计划(Physical Plan)
以“复杂度的来源”中的Join为例,交换Join的顺序属于逻辑优化,对应逻辑计划。将Join展开为Nested-loop Join、Hash Join等,属于物理优化,对应物理计划。
SQL语句被翻译为关系代数表达式树后,可以看出Operator需执行的先后顺序;这就是逻辑计划。树中Operator是关系代数运算符,称作Logical Operator。优化器需探索大量等价的表达式树,搜索逻辑计划空间,称作逻辑优化。逻辑优化通常只需基于规则的转换(Transform),不会将Logical Operator转换为Physical Operator,不需计算代价。
一个Logical Operator通常可选择多种物理实现算法,即Physical Operator。优化器会逐步将Logical Operator展开为Physical Operator,根据代价模型选择优者。此时称作物理优化。最终表达式树完全由Physical Operator构成,组成一颗树(表达式树),可由执行引擎直接执行;称作物理计划,也作执行计划。
逻辑计划和物理计划例下图[1]。
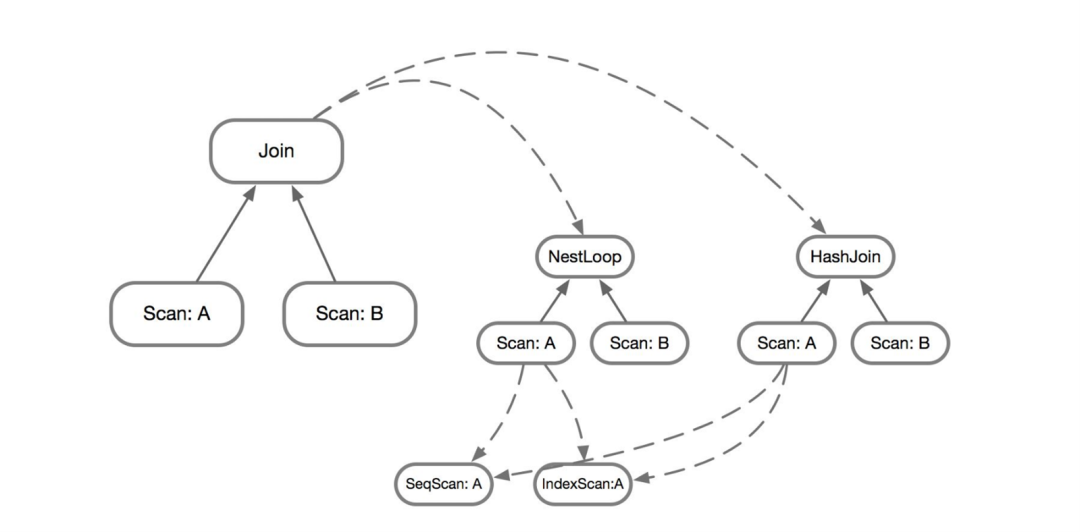
(基于代价的优化器鼻祖Volcano论文中,逻辑优化和物理优化分为两个阶段。但后来Cascades论文中,逻辑优化和物理优化合二为一,以此避免探索无效的逻辑计划空间。因而今日“逻辑计划”与“物理计划”术语也有些混淆。)
Operator、Logical Operator、Physical Operator
逻辑、物理执行计划通常表达为树的形式,每个节点为Operator。Operator意指一个SQL操作,例如Join、Filter(Select Predict);逻辑上对应Logical Operator,物理实现算法对应Physical Operator;逻辑计划对应Logical Operator,物理计划对应Physical Operator。
Operator执行时,以Filter为例,一面输入扫描表中行,一面输出满足Filter谓词的行。更多地,
可用迭代器Poll方式实现,父Operator调用next以使子Operator返回下一结果。
可用Push方式实现,子Operator凑齐结果后上推给父Operator。
可用向量化[17](Vectorized)方式实现,Operator一次处理多行(Vector)而不是单行。
可用Compiled Query[20],将多Operator合并紧凑编译(Loop Fusion、Loop Pipelining)以提速。
Volcano和Cascades
Volcano[7]和Cascades[8]源自如下两篇论文,它们是现代基于代价的优化器的鼻祖。如今各大企业级数据库和开源数据库的查询优化器仍采用其架构(如TiDB[2]、CockroachDB[5]、Greenplum(Orca[12])、Apache Calcite[11])。
The Volcano Optimizer Generator: Extensibility and Efficient Search
The Cascades Framework for Query Optimization
Volcano继承自更古老的System-R、Exodus、Starburst。Cascades升级Volcano做了诸多改进,二者出自同一作者(Goetz Graefe等),很多文献把Volcano/Cascades名词混用。
Volcano/Cascades的卓越之处在于为混沌复杂的查询优化器世界划定了优雅的抽象框架,后来者只需继承抽象类[2]就能构造新的查询优化器。
与其直接罗列Volcano/Cascades的概念,我们从解决设计问题的角度讲述。
基本概念 – 三大组件
在设计的开始,首先需要确定优化器的输入、输出,如下图[10P15]
输入:SQL文本首先被语法解析(Parse)为AST(Abstract Syntax Tree),然后翻译成Logical Operator树(关系代数表达式,初始的逻辑计划),作为优化器的输入。因SQL语法成熟固定,这步并无太多讨论,可采用BNF范式状态机等。
输出:代价最优的Physical Operator树,即物理计划;交由执行引擎执行,访问存储、汇聚结果。执行引擎如何切分并行化Operator、如何分布式调度、如何向量化,大有文章,但不在查询优化器范围内。
元数据:通常有外部服务提供数据库表目录(Catalog),提供有关代价的统计信息。元数据Provider甚至可以插件[11]提供,以兼容异构平台。
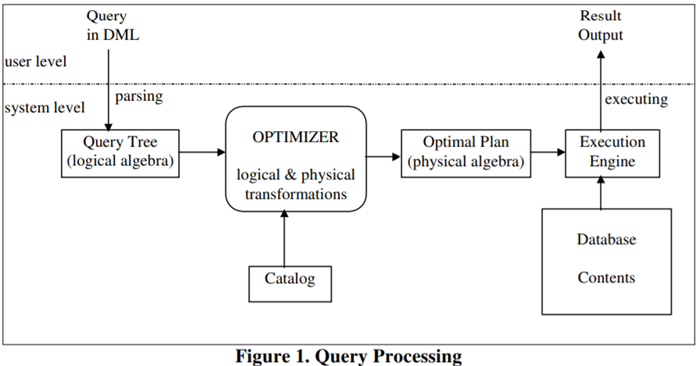
优化过程中, 优化器需要搜索最优逻辑、物理计划,需要评估每种计划的代价;由此可以将优化器分解为三大部分。(事实上,每个都是一门研究方向。)
搜索计划空间(Plan Enumeration):Volcano/Cascades采用动态规划(Dynamic Programming),继承自[9]System-R;搜索自顶向下。搜索需要在短暂时间内探索大量逻辑、物理计划,并评估代价。
代价模型:如何为一个物理计划(Physical Operator树)确定代价,如何为每个Physical Operator确定代价。Logical Operator需展开为Physical Operator后才能确定代价,但能提前估算更好。
统计信息(Statistics):代价模型需要统计信息作为输入,例如Selectivity、Cardinality。经过Operator输出后的“表”,例如Join结果,也需要导出统计信息(Statistics Derivation),为下一步计算代价。
基本概念 – Operator
Operator、Logical Operator、Physical Operator已在“基本名词”一节讲过,不再敷述。
Volcano/Cascades中,它们抽象了SQL的基本操作单元,接口基本是输入行-输出行。存储引擎只需按照接口实现Physical Operator,即可执行优化器的输出的执行计划(Operator树)。
Volcano/Cascades通过Operator的抽象,划分了优化器和存储引擎的界限,也让扩展变得简单。
基本概念 – Pattern/Rule
搜索过程驱动优化器工作,不断生成等价的Operator树(逻辑计划、物理计划),扩展搜索空间,寻找最优。如何为其建立精炼的抽象概念?Volcano/Cascades的答案是Pattern和Rule
Pattern:当Operator树的某个局部形态匹配Pattern时,可以对其应用Rule来转换树的形态;例下图[10P62]。
Rule:如何转换Operator树,即将其匹配的节点替换(Substitute)为新形态。从而生成新的、等价的Operator树。
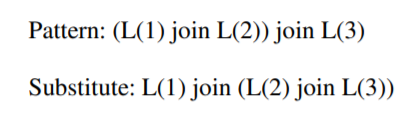
逻辑优化和物理优化都需不断应用Pattern/Rule。在逻辑优化阶段
Transformation Rule:逻辑优化应用Pattern/Rule生成新的Operator树(逻辑计划)以供探索;例如根据Rule生成不同Join顺序的多个逻辑计划。此时的Rule称作Transformation Rule(对应Implementation Rule)。
Normalization:逻辑优化中有些总是更优的转换,例如谓词下推、去掉不需要的Select字段(Cropping)。这些转换(Transform)往往在优化开始阶段执行;也可由Pattern/Rule定义。CockroachDB称其为Normalization[5]。
在物理优化阶段
Implementation Rule:将Logical Operator转换为对应的(多种)Physical Operator的Rule称作Implementation Rule。该过程生成新的(多个)Operator树,逐步优化,最终生成完全由Physical Operator组成的物理计划。
至此,优化器搜索过程被抽象为不断匹配Pattern然后应用Rule转换,搜索空间递归展开,应用代价模型择优。开发者只需添加新的Pattern和Rule即可扩展优化器(如继承抽象类、添加Optgen[37]文件)。
基本概念 – Memo
上文将搜索过程抽象为Pattern/Rule;之后还有一大特性需要抽象,那就是“等价”。如何表达它呢?Volcano/Cascades使用Group Expression
Expression:关系代数表达式,对应Operator树中一个节点。优化器需搜索Expression的不同等价形式,选择代价最优
Group Expression:一个Operator有多种Logical Operator、Physical Operator供选择,它们互相等价,编为一组,称作Group Expression(其实称作Expression Group更易理解)。Group Expression也可看作一个Expression;Operator树中,节点实际指向的是Group Expression,这样就将可选的等价范围表达在树中了。
动态规划搜索中,需要维护共享数据结构。很明显应该基于Group Expression构造它,Volcano/Cascades中称其为Memo
Memo如何记录可探索的计划空间?Memo中各Group指Group Expression,保存等价的Expression,可以是Logical或Physical Operator。Group 0是表达式树的顶层,父Expression的子指针指向后续Group Expression。从Group 0树遍历即可穷举计划空间。
Memo如何记录被选中的逻辑/物理计划?父Expression的子指针指向具体Expression即可,而不是Group Expression。动态搜索可以从子树开始,逐步构建最优结构,然后递推至父。
Memo例子1[2]
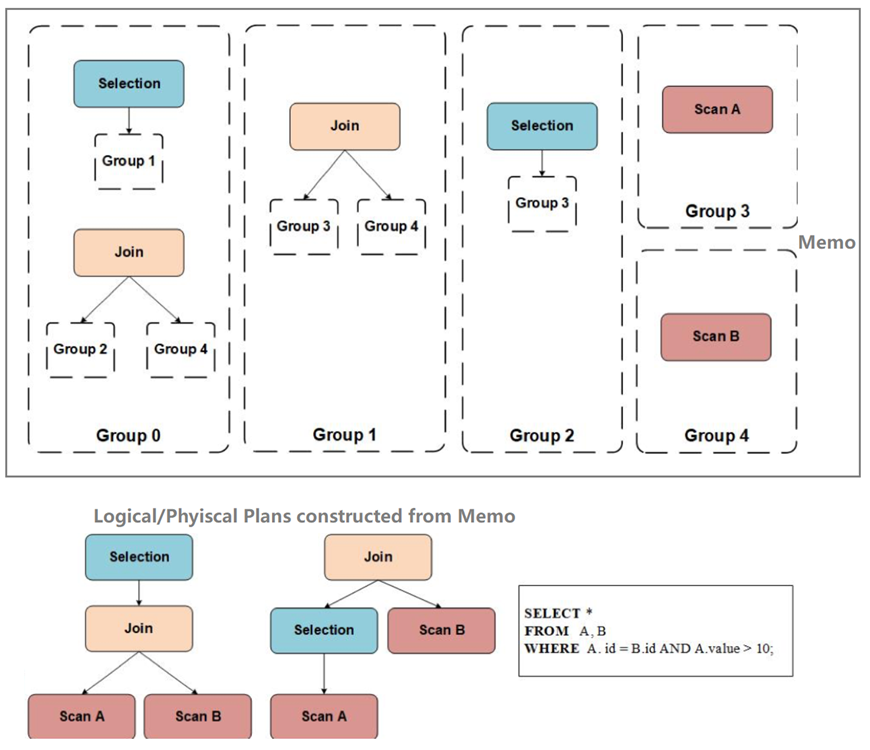
Memo例子2[1]
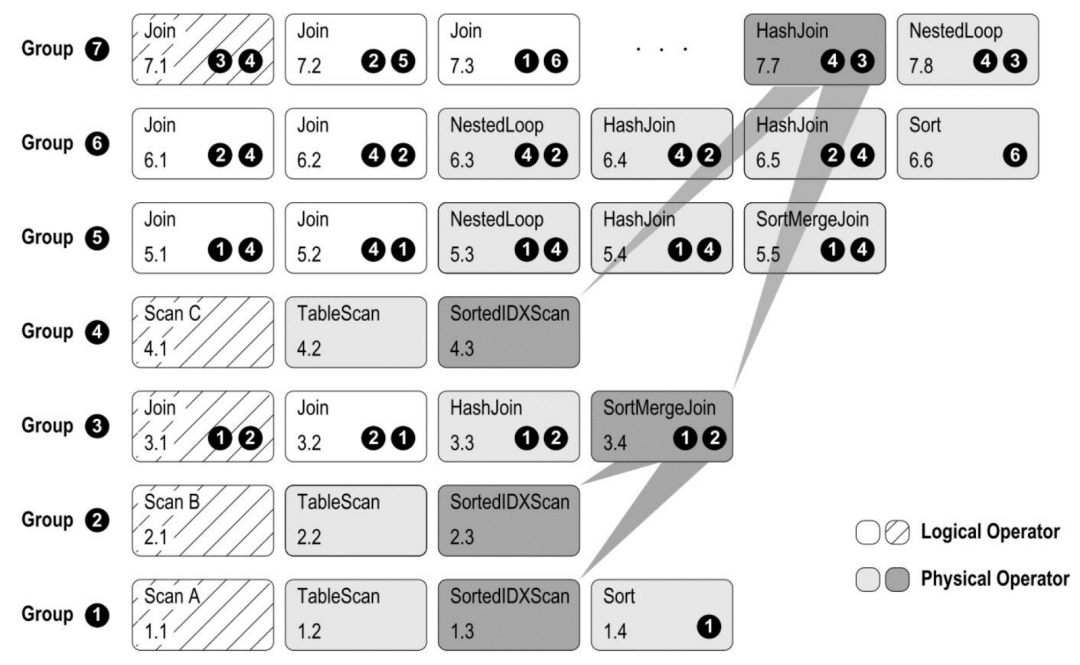
基本概念 – 任务调度
优化器搜索过程本质上是递归地动态规划,如何将其实现的易于扩展、能够多核调度呢?通常是实现为任务(Task/Job)调度框架。
下图来自Columbia[10P15]优化器。任务在执行过程中会创建新任务,推入栈中;执行器从栈中反复抽取任务执行,直到耗尽。任务有多种类型,如优化Group Expression、应用Rule转换、计算代价。

下图来自Orca[12]优化器,任务划分有所不用,但其展示了任务之间的依赖关系。递归中单一的Stack关系被更丰富准确的图关系所表达。调度器依照任务依赖图,用Task Pipeline方式在多核并行运行。
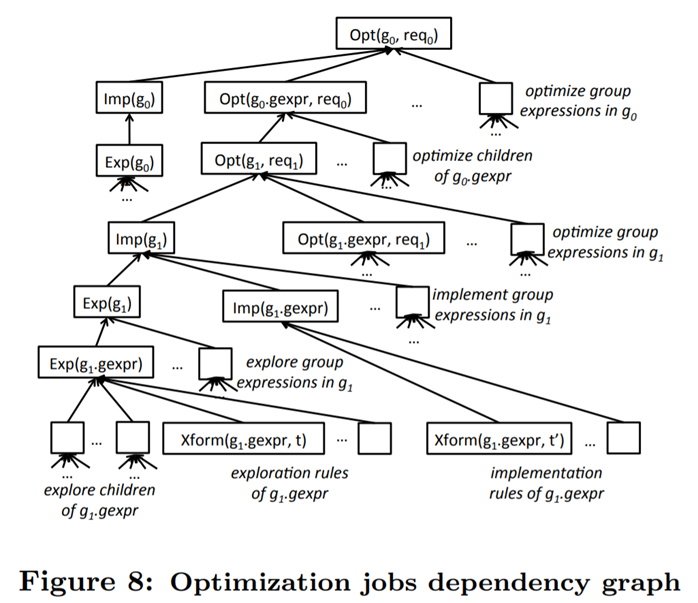
Volcano与Cascades的区别
Cascades由同一作者在Volcano后提出,相对Volcano比较关键的改进有
Cascades合并了逻辑优化和物理优化。Volcano则分为逻辑优化阶段和物理优化阶段,在逻辑优化阶段需穷举逻辑计划,但后期未必用得上,浪费了搜索资源。以此类推,Cascades也不再(严格)区分Logical Operator和Physical Operator,Transform Rule和Implementation Rule
Cascades提出了Memo数据结构,详见上文。Memo此后被广泛采用[41],成为优化器的核心之一。
搜索计划空间(Plan Enumeration)
上文已基本讲解搜索过程, 下面我们更加深入,并且带出Volcano/Cascades的另外几个概念:Interesting Order、Promise 、Logical Property、Physical Property、 (Property) Enforcer。
局部最优问题
动态规划的基本假设是子树最优导出父最优(最优子结构),但对于查询优化这是不正确的。例如,子树采用Hash Join也许更快,但结果无序,父需额外排序;Sort-merge Join更慢,但结果有序;两者并无确定优劣。
首先,如何表达这种差异呢?
Physical Property:Operator返回的结果带有的属性,最典型的例子是排序与否;还例如结果是否已计算Hash;结果在单服务器上,还是分散在多服务器(需要额外GatherMerge)。
在搜索中,稳妥的做法是子树对每种不同的Physical Property都返回一个最优计划,供父节点选择。父节点也可指定自己关注的Physical Property,然后让子树依此开始搜索
Interesting Order:(也许叫Interesting Property更合适,因为多数Interesting的都是排序属性。)由父节点传给子节点,要求其返回满足特定Physical Property的最优计划。
另一个能够解释“Interesting Order”名称的是Join Order。在多表互Join时,表的Join顺序(Join Order)排列组合数量巨大,且以数量级级别[14]影响查询性能;父节点需选择哪些Join Order应被进一步探索(Join Enumeration)。它们成了“Interesting Order”。
由此,动态规划局部最优问题得到解决。相比标准算法只保留一个局部最优结果,查询优化器将所有可能达成全局最优的局部最优列为候选,依次保留和探索。
关于Property和Enforcer
解释了Physical Property,那么Logical Property是做什么?
Logical Property:主要出自Volcano论文,它是从逻辑优化阶段的关系代数表达式中提取的属性,主要包括Operator输入输出的Schema(如有哪些列)、行数等统计信息。
什么是Property Enforcer呢?Operator树中,父节点要求的Physical Property可能在紧邻的子节点上是缺失的。例如父Operator要求结果排序,但子Operator给出无序的结果。此时需要“Enforce the missing property”
Property Enforcer:(也简称Enforcer)上例中,Property Enforcer会在父子节点间插入一个新的节点Sort Operator,使结果排序。即补上缺失的Physical Property。
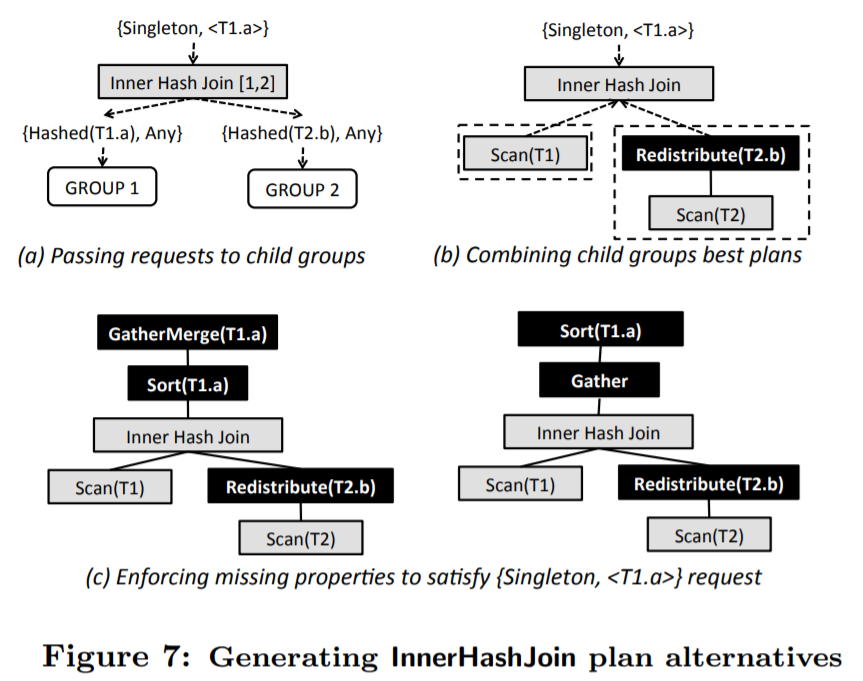
更复杂的例子[12]如下图。(b)要求输出Physical Property {Singleton,<T1.a>},即结果位于单服务器,且对T1表的a字段排序。(c)中Property Enforcer补上了缺失的Physical Property,左图选择先尝试添加排序<T1.a>,而右图选择先尝试添加单服务器Singleton。
搜索优先级
优化器搜索时间有限,而分支众多,不一定能全部穷举;此时需要优先选择“看上去”更优秀的分支。如何表达这一抽象呢?Volcano/Cascades中将其表达为Promise
Promise:前文中可见,发现一个搜索“分支”对应一个Rule的转换。每个Rule对外提供一个Promise值(正整数),越高表示该分支更有可能找到最有计划,而搜索任务调度器会优先选择。
开发者通过设定Promise值,可以引导优化器偏向预设的搜索空间。而Promise为零或负数时,则可禁止Rule被执行。
Promise值计算通常是启发式的(基于规则的),例如[12]优先选择更少Join条件的Inner Join,以规避更多Join条件带来的更大代价估算偏差。
除Promise外,Orca[12]还实现了Multi-Stage Optimization。Rule被分入不同Stage,优先执行资源消耗少的。各Stage可配置不同的退出条件。
避免重复搜索
动态规划中,同一个表达式可能被重复地发现并搜索,相同表达式可能被不同的Rule转换出。如何去重呢?
Duplicate Expression Detection:通常采用Hash方法[10P48],表达式可计算出其对应的Hash值,放入全局缓存中。去重功能甚至可以内置(Build-in)到Memo中。
可看到,上面引入了表达式缓存。SQL计划的优化结果能够被缓存,Operator树的子树也能被缓存。预编译查询往往能够更好利用缓存。
剪枝(Pruning)
动态规划搜索常常可以利用上下界剪枝,去掉不必要的搜索分支;查询优化器也不例外。如果已经搜索了一些候选计划,那么代价比它们更高的计划就可以跳过
Branch-And-Bound Pruning:已搜索完成的物理计划的代价最小值成为Cost Upper Bound。当新的搜索分支的代价高于它时,不需继续搜索。初始Cost Upper Bound可由优化器根据启发式规则估算。
此外,Columbia还实现了更多剪枝[10P83]算法,如Global Epsilon Pruning。
搜索退出条件
最后,动态规划搜索应该何时退出呢?典型[12]方法有
搜索退出条件:1)低于预设代价的物理计划被找到;或2)超时;或3)搜索空间穷举完毕。
Join Order Enumeration
从上文可以看出,搜索过程中,父节点需提供子树应探索的不同Join Order。尤其是OLAP数据库,Join参与表数量通常较多,可选Join Order排列组合成几何数量增长。而How Good Optimizers论文[14]指出,Join Order能影响SQL执行速度达数量级级别。
Join Order并没有完美的解决方案,常见方法如PostgreSQL[43]所用
当参与Join的表数量少于上限时(配置参数),遍历所有排列组合。否则,基于启发式规则选择一些Join Order,例如随机生成。此外,允许用户Explicit强制设定优化器采用的Join Order。
Oracle[45]数据库更详细地设计了如何用启发式规则猜测更优的Join Order
如果表更小,对Join条件有索引,需扫描的行更少;那么这个表更可能被排列到Join Order靠前。
MemSQL[13]针对OLAP雪花表(Snowflake Schema),设计了特殊的启发式规则优化Join Order
依靠雪花表的图关系(不需代价信息),区分Satellite节点(通常为Fact表,自带Filter条件),和Seed节点(通常为Dimension表)。调整Join Order以形成Bushy Join,方便谓词下推。
搜索算法的详细例子
Columbia的详细例子
这个算法来自与Columbia[10]论文,详细讲述了Cascades优化器的实现(以及效率改进)。下图为其任务划分,以及调用、创建关系
O_GROUP:优化一个Group Expression
E_GROUP:展开(Expand)一个 Group Expression,优化其中每个表达式
O_EXPR:优化一个表达式
APPLY_RULES:匹配(Bind)Pattern并应用Rule转换,新表达式被放入任务栈继续优化
O_INPUTS:计算表达式的代价,并决定剪枝

可以看见,优化器的算法驱动是循环调用任务栈

优化初始Operator树,作为一个O_GROUP被推入任务栈。

E_GROUP展开Group Expression

O_EXPR优化指定的Expression。Logical Operator在此通过应用Implementation Rule,被转换成Physical Operator。

Columbia为增加Pattern匹配速度做了一些优化,例如首先测试Pattern的根节点是否匹配,否则跳过。

O_INPUT会把自己重复推到栈上,自我重入,以迭代计算整个物理计划的代价。

Memo的详细例子
Orca[12]论文中的Memo图非常有益说明,并且是分布式查询优化。图中左中右分别是
Group Hash Table:Orca中的优化任务称作Request,记录于Group Hash Table中,Request去重通过Hash完成。图中Group Hash Table左中右字段分别是Request ID,Request输出的内容和其Physical Property,代价最优的表达式(指向中图Memo)。
Memo:如前文所述。一个Group中汇聚了输出内容相同,但Physical Property不同的表达式。每个表达式的子指针指向Group Hash Table中的Request ID。
Extracted Final Plan:根据图中Group Hash Table和Memo和指针关系,可以构建出来的代价最优的物理计划
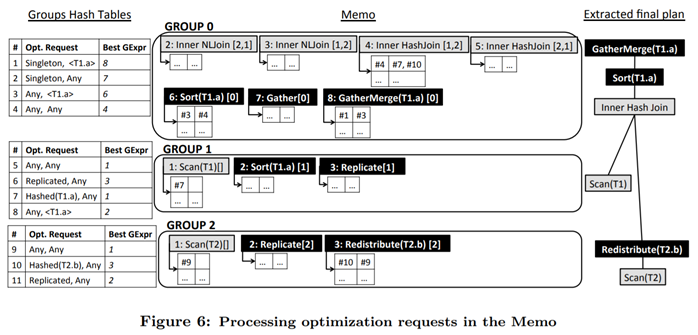
进一步解释图中内容;下面跟随指针关系,如下各步可以组装出Extracted Final Plan
优化器首先输入的是Request#1,要求查询表`T1 join T2 by T1.a == T2.b`,结果位于单个服务器,且按T1.a排序
Request#1的Best GExpr指向Memo中的8: GatherMerge(T1.a),后者指向Request#3。
Request#3仍输出`T1 join T2 by T1.a == T2.b`,但不要求结果位于单个服务器;这是因为其父GatherMerge汇聚结果。
Request#3的Best GExpr指向6: Sort(T1.a),后者指向Request#4
Request#4仍输出`T1 join T2 by T1.a == T2.b`,但不要求排序;这是因为其父Sort了结果
Request#4的Best GExpr指向4: Inner HashJoin,后者指向Request#7和Request#10
Request#7位于GROUP 1,它扫面T1,并且为T1.a计算Hash。它的Best GExpr指向1: Scan(T1)
Request#10位于GROUP 2,从指针关系可以看到其首先Scan(T2),然后Redistributed(T2.b)。Redistribute指按照T2.b的Hash值分散数据到对应服务器上,由此可以Join于T1.a。
由上面也可发现,Memo结构常常设计得节省内存(Memory Compact),以便有空间存放更多的表达式以供搜索。
代价模型(Cost Model)
简单直接地说,代价模型是Operator实现接口中的GetCost[39]函数,返回数值表示代价高低;例如下图[38]。最后Operator树遍历求和整个SQL表达式的代价。

基础Cost Variable
代价模型的底层通常来自CPU、内存、网络/磁盘IO等维度,在模型中加权求和得到最终分数。这些权重——即“单位代价”——如何取值是模型的基础。但常见方法仅仅是在配置文件中指定(如下图TiDB[40]、Columbia[10P110]、PostgreSQL[42]);PostgreSQL称它们为Cost Variables[42]。
(对,一切困难问题都可以代理给配置文件,或用接口推给具体Driver实现 …)

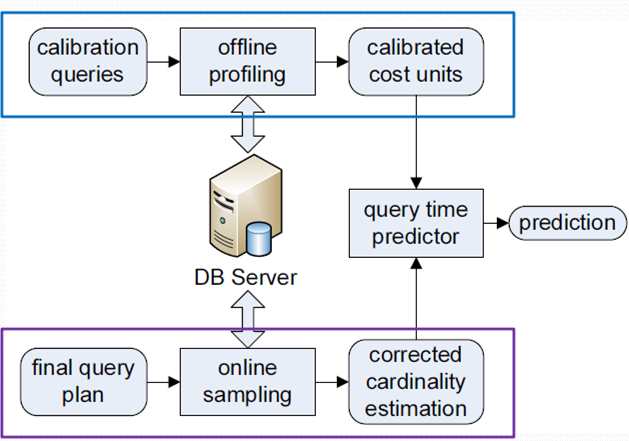
Cost Variable并不容易正确配置,往往来自运行大量用户场景负载(Workload)的经验。一些方法中,它们可由在指定硬件上运行与预期相符的样本来校准(Calibrating);例如使用机器学习[29],结合离线训练与在线抽样(Sampling)。类似思想也出现过在Quasar调度器[24]中。
更复杂的代价模型
真实的代价模型会考虑更多Cost Variable。行式(Row-oriented)与列式(Column-oriented)布局(Layout)、内存与磁盘数据库、OLTP与OLAP、单机与分布式,模型会有不同和侧重。例如
行的大小(影响扫描大小)
Cache Miss
压缩与否(影响的扫描速度)
结果集(Result Set)写出速度
扫描共享(一次扫描服务多个查询)
CPU指令流水线(Pipeline)的利用率(IPC)
分布式[13]数据库带来的额外数据移动(Data Movement)、Shuffle、Hashing代价
例如Access Path Selection[6]论文中下图
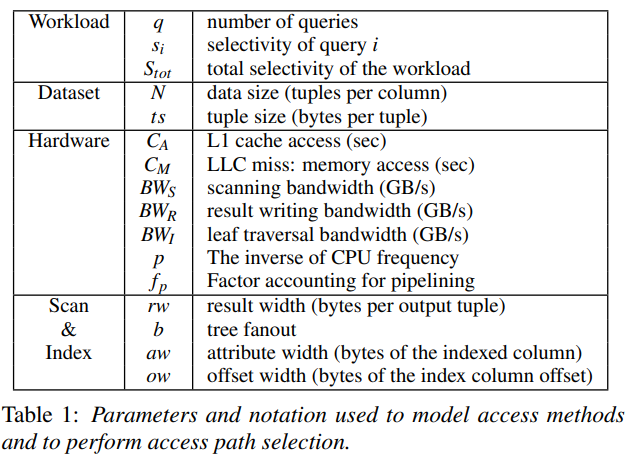
以上图中Cost Variable为基础,可以构造内存全表扫描查询的代价。可以发现Selectivity是除Cost Variable外的关键变量。

另一条路径, 可以构造B+树扫描查询的代价。尽管B+树省去全表扫描,但树跳转易Cache Miss;Selectivity高时,底层遍历同样耗时,且不能共享查询扫描。前后对比,才能得到最优执行计划。

现代数据库还允许用户自定义代价模型和其依赖的统计信息(User-Defined Statistics/Selectivity/Cost[46])。这得益于Volcano/Cascades框架的可扩展性, 也帮助处理难以确定代价的用户定义函数(UDF)。用户还可用它们获取业务逻辑有关的数据分布信息;数据库一般提供SQL ANALYZE命令主动触发信息收集。
进一步扩展,Apache Calcite[11]允许异构数据平台以插件的形式接入各自的代价模型、元数据接口、Rule等,同一SQL查询可联合不同数据源。
代价模型的分析和验证
How Good Optimizers论文[14]给出了很多精彩的方法。例如,SQL查询的真实代价是其执行时间;将代价模型的预测值与真实执行时间计算线性相关性,可以判断其准确程度。
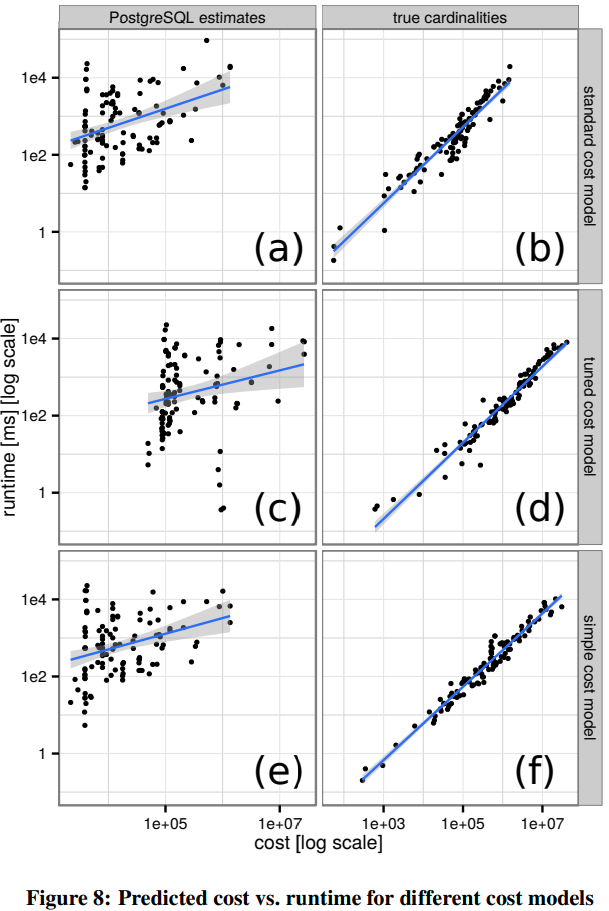
上图中(a)、(b)使用PostgreSQL代价模型,(c)、(d)的PostgreSQL额外校准了Cost Variable,而(e)、(f)使用只考虑结果行数的简单代价模型。左列使用PostgreSQL估算的统计信息Cardinality,右列使用真实准确的Cardinality。可以发现关键结论[14]
准确的统计信息,即Cardinality,远比代价模型本身重要。即使是简单代价模型,输入准确Cardinality,都能做出线性预测。
左列图左侧的大量离群点表示,查询优化器有时会给出估算代价很低,但实际很慢的执行计划。较低的估算代价可能来自很低但错误的Cardinality,误导优化器选择错误的Physical Operator,例如Nested-loop Join。
对比(a)、(b)、(c)、(d)表示,校准Cost Variable有用,但远逊于准确Cardinality带来的提高。
图(c)中,查询优化器意外发现了耗时很短的执行计划,但却误估出很高的代价
另一个方法,下图中,该论文[14]给出了展示Plan Space的方法:遍历所有可能的执行计划,为其执行时间绘制概率密度图(PDF)。可见最优执行计划往往比中位数计划快几个数量级。
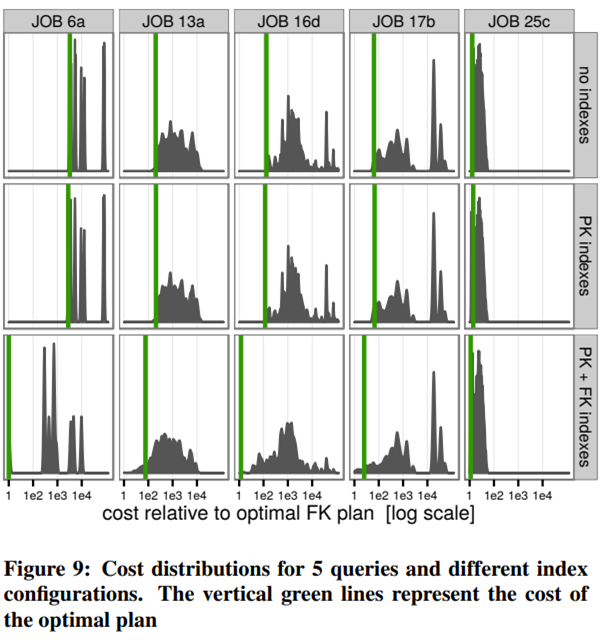
由此延伸,这一方法可以用来分析验证查询优化器。例如Orca TAQO[12]
优化器往往只够时间搜索部分Plan Space,被包含的部分包括最优执行计划吗?
Join Order Enumeration、Promise、Interesting Order能否将搜索过程引导向Plan Space较好的部分?(联想SGD[31])
在Plan Space中,代价模型估计的代价与真实执行时间,有怎样的匹配?最简单地,任取两个执行计划,代价模型能否正确排序?重度偏离的部分预示改进的方向
重点Plan Space可以被抽样(例如高度偏离的客户查询),组成Benchmark集,供代价模型以及优化器的回归测试和进一步优化
最终这又是一个组合[33]和空间结构[53]探索的问题。
统计信息(Statistics)
数据库最主要的统计信息是Operator输入输出的行数,从最初的表有多少行,到中间各步Operator,即Selectivity和Cardinality(Selectivity也可以归结为Cardinality)。How Good Optimizers论文[14]指出准确的Cardinality远比代价模型重要。
本文主要关注Cardinality。此外还有Count-Min Sketch[15],使用类似Bloom Filter的方法,快速估算一个值出现的次数。(类似的“Sketching”还有Zone map[47],通过记录各数据块的Min/Max边界,帮助扫描时快速跳过。)Synopses for Massive Data[26]有更多Sketch方法。
柱状图(Histogram)
数据库通过柱状图记录每一列的Cardinality,相当于离散版本概率密度图(PDF),针对列中各行取值。列值范围会被分桶(Bucket),通常等深直方图(Equi-Depth Histograms)有更好的效果。等深直方图指,维持每个桶中装有相等数量的行(Tuple),而不是将列值范围等分(等宽直方图)。
对于单列的范围查询,直方图可以估算选中的行数。只需找出范围条件覆盖的桶,求和桶中的行数。对于不完整覆盖的桶,则按照覆盖的比例线性推算;例如PostgreSQL例子[44]。
Statistics Derivation
由上文可以发现,单列的柱状图/Cardinality远不足供代价模型使用。我们还需要
通过单列的Cardinality推算多列组合查询的结果Cardinality
通过单列的Cardinality推算Join结果的Cardinality
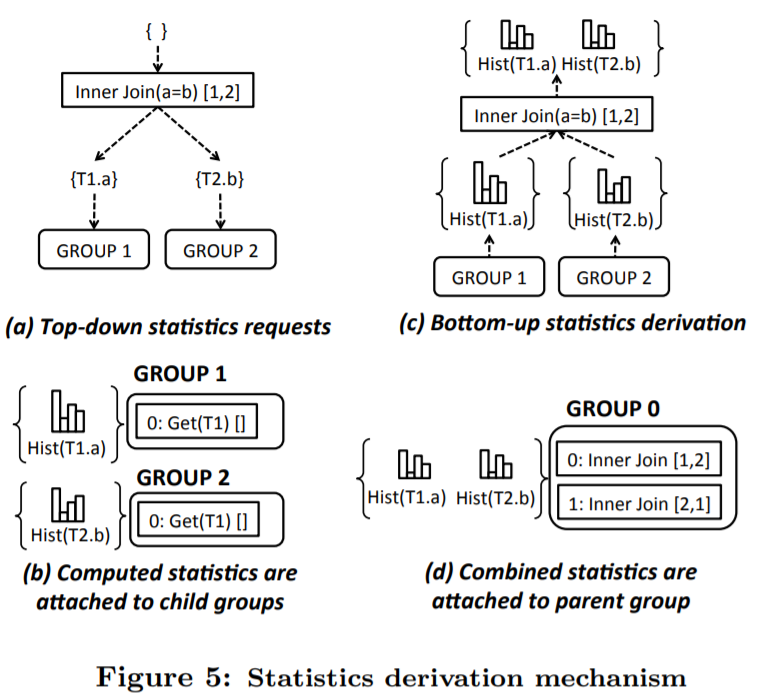
例如下图[12],更基础的统计信息能够逐层向上推导(Derive)出更高层的、包含更多组合的统计信息。
解决上述问题的经典方法基本是假设各列统计独立,即AVI: Attribute Value Independence[21](以及类似变种)。该方法简单粗暴,但广泛使用,如PostgreSQL(2015[14]),和许多商业数据库(2001[22])。

由此,多列组合查询的Cardinality可由各列相乘得到,而Join结果的Cardinality可用如下[14]方法估算
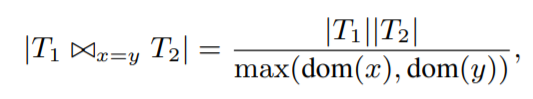
事实上,How Good Optimizers论文[14]指出,数据库Cardinality估算和实际情况常有几个数量级的差距,总体倾向(严重)低估。
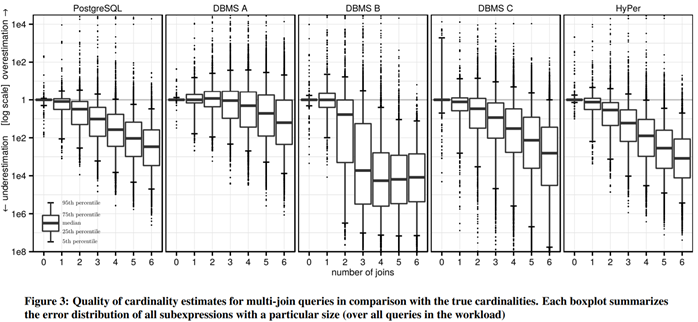
为提高Cardinality估算的质量,AVI以外,商业数据库往往支持更复杂更有效方法,如
Sampling[14] for base table estimation。仅随机抽样1000行也能取得不错的估计
Multi-attribute histograms (Column group statistics[49])。既然单列不够,那么统计多列协同的概率分布
Query Feedback[16] / Statistics Feedback[48] / LEO Feedback Loop[23]。用查询结果反馈,渐进地改善统计信息
另一个有意思的方向是,在Database Redbook[4]中提到,Eddies和Progressive Optimization。在Continuous Stream场景下,传统数据库的查询优化和执行步骤不再界限分明。Operator在执行Stream的同时收集统计信息,自适应优化执行计划。与此相应的是Dataflow Architecture。
查询执行(Query Execution)
查询优化器输出物理计划/执行计划,然后交由执行引擎进行查询执行。查询执行已经超出优化器范围,本文简单讲解。
基本名词“Operator”一节中,已介绍查询执行的Pull、Push等基本模型。向量化[17]、Compiled Query[20]、利用SIMD是内存数据库的热点之一;CPU成为新的瓶颈。
切分和平衡
并行Operator执行常采用水平和垂直的数据切分,在调度(Scheduling)和平衡(Balancing)中常面临如下[3]问题
数据倾斜(Skew):数据初始分区(Partition)不平衡,或者几经Operator处理后的中间结果不再平衡。数据倾斜会使某些任务分区变慢成Tail[27],拖慢整体执行
处理速度倾斜:单个处理服务器因硬件差异、临时负载变化、软硬件Bug引起的性能下降,变慢成为Tail,拖慢整体执行
Data Locality:我们希望Operator依赖的数据位于同一服务器,避免数据移动开销,即Locality。对CPU核、Cache、NUMA,同样有Locality需求。而与Locality相矛盾的是,调度器同时希望更细粒度的切分、更广泛的分布,以平衡负载
NUMA架构
Morsel-Driven Parallelism[18](HyPer)提供了支持NUMA的经典实现。Morsel与存储系统常见的异步Task Pipeline架构相似。此外特点有
尊重NUMA Locality,一个CPU核上的任务尽量存储在同一NUMA的内存中,并且优先向同核调度任务
Work Stealing来平衡负载,空闲CPU核“窃取”其它CPU核的队列任务。注意Work Stealing实际上会打破NUMA Locality
HyPer引入了Delay Scheduling[3],以防止过于频繁的 Work Stealing。空闲CPU核“窃取”前,会等待一小会儿,期待原CPU核完成任务。Delay Scheduling[28]也被YARN[50]采用,据说简单但实际效果意外地好
除HyPer的NUMA-aware调度方法外,SAP HANA[32P27]使用独立Watchdog线程检测工作线程负载,并且动态调整任务分配。而SQL Server SQLOS[32P32]是“用户态的OS Layer”,决定任务到线程的分配,线程调度是Non-preemptive的(Explicit yield calls)。
分布式Operator
在基本Operator外,分布式数据库引入了新Operator,以更好地抽象数据移动。它们可由Property Enforcer加入。
Broadcast[13] / Replicate[25]:对于需要多张表的操作,如Join,将一张表复制到另一张表的服务器上。如果另一张表的多个分区位于不同服务器,则需要复制到所有服务器
Exchange[3] / Shuffle[13] / Redistribute[12] / Partition[33]:对于参与Join的多张表,按照相同的Join Key取Hash,按照Hash值将它们分配到相应多个服务器上。这样相关联的行一定位于相同服务器,可以本地执行Join操作
Gather[12] / Merge[12]:对于分散在多个服务器的中间结果,需要将它们收集到单个服务器。收集过程中可同时排序
总结
查询优化器是数据库最复杂、重要、标志性的组件。本文讲述了查询优化器的几大方面;计划搜索、代价模型、统计信息、查询执行,每一门都是独立研究方向。
基本名词
Volcano/Cascades
如何搜索计划空间(Plan Enumeration)
代价模型(Cost Model)
统计信息(Statistics)
查询执行(Query Execution)
Volcano/Cascades是软件工程解决复杂抽象的样板。计划搜索是动态规划的经典应用,特别是如何解决局部最优问题,可借用别处。代价模型则可为各种资源调度系统提供参考。
最终,问题又化归于如何探索广袤[51]的组合空间[33],寻找最优迭代路径[31],亦或展开并绘制空间结构[53]。
相关资料

(微信公众号文章不允许贴外部链接,只能将所有引用都加到这里……)
[0] CMU 15-721 Spring 2020: https://15721.courses.cs.cmu.edu/spring2020/schedule.html
[1] Cascades Optimizer - hellocode: https://zhuanlan.zhihu.com/p/73545345
[2] 揭秘 TiDB 新优化器:Cascades Planner 原理解析: https://pingcap.com/blog-cn/tidb-cascades-planner
[3] OLAP 任务的并发执行与调度 - IO Meter: https://io-meter.com/2020/01/04/olap-distributed
[4] Database Redbook: Chapter 7: Query Optimization: http://www.redbook.io/ch7-queryoptimization.html
[5] How We Built a Cost-Based SQL Optimizer: https://www.cockroachlabs.com/blog/building-cost-based-sql-optimizer
[6] Access Path Selection in Main-Memory Optimized Data Systems: Should I Scan or Should I Probe: https://www.eecs.harvard.edu/~kester/files/accesspathselection.pdf
[7] The Volcano Optimizer Generator: Extensibility and Efficient Search: https://15721.courses.cs.cmu.edu/spring2020/papers/19-optimizer1/graefe-icde1993.pdf
[8] The Cascades Framework for Query Optimization: https://15721.courses.cs.cmu.edu/spring2020/papers/19-optimizer1/graefe-ieee1995.pdf
[9] An Overview of Query Optimization in Relational Systems: https://15721.courses.cs.cmu.edu/spring2020/papers/19-optimizer1/chaudhuri-pods1998.pdf
[10] EFFICIENCY IN THE COLUMBIA DATABASE QUERY OPTIMIZER: https://15721.courses.cs.cmu.edu/spring2019/papers/22-optimizer1/xu-columbia-thesis1998.pdf
[11] Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources: https://arxiv.org/pdf/1802.10233.pdf
[12] Orca: A Modular Query Optimizer Architecture for Big Data: https://15721.courses.cs.cmu.edu/spring2016/papers/p337-soliman.pdf
[13] The MemSQL Query Optimizer: A modern optimizer for real-time analytics in a distributed database: http://www.vldb.org/pvldb/vol9/p1401-chen.pdf
[14] How Good Are Query Optimizers, Really?: https://www.vldb.org/pvldb/vol9/p204-leis.pdf
[15] TiDB 源码阅读系列文章(十二)统计信息(上): https://pingcap.com/blog-cn/tidb-source-code-reading-12
[16] TiDB 源码阅读系列文章(十四)统计信息(下): https://pingcap.com/blog-cn/tidb-source-code-reading-14
[17] MonetDB/X100: Hyper-Pipelining Query Execution: http://cidrdb.org/cidr2005/papers/P19.pdf
[18] Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age: https://db.in.tum.de/~leis/papers/morsels.pdf
[19] Track Join: Distributed Joins with Minimal Network Traffic: http://www.cs.columbia.edu/~orestis/sigmod14II.pdf
[20] Everything You Always Wanted to Know About Compiled and Vectorized Queries But Were Afraid to Ask: http://www.vldb.org/pvldb/vol11/p2209-kersten.pdf
[21] Selectivity Estimation Without the Attribute Value Independence Assumption: https://www.vldb.org/conf/1997/P486.PDF
[22] Selectivity Estimation using Probabilistic Models: http://robotics.stanford.edu/~btaskar/pubs/sigmod01.pdf
[23] LEO – DB2’s LEarning Optimizer: https://www.vldb.org/conf/2001/P019.pdf
[24] Quasar: Resource-Efficient and QoS-Aware Cluster Management: https://www.csl.cornell.edu/~delimitrou/papers/2014.asplos.quasar.pdf
[25] Query Optimization in Microsoft SQL Server PDW: http://cis.csuohio.edu/~sschung/cis611/MSPDWOptimization_PaperSIG2013.pdf
[26] Synopses for Massive Data: Samples, Histograms, Wavelets, Sketches: https://dsf.berkeley.edu/cs286/papers/synopses-fntdb2012.pdf
[27] The Tail at Scale: https://cacm.acm.org/magazines/2013/2/160173-the-tail-at-scale/fulltext
[28] Delay Scheduling: A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling: http://elmeleegy.com/khaled/papers/delay_scheduling.pdf
[29] Predicting Query Execution Time: Are Optimizer Cost Models Really Unusable: http://pages.cs.wisc.edu/~wentaowu/slides/ICDE-2013.pdf
[30] Forecasting the Cost of Processing Multi-join Queries via Hashing for Main-memory Databases: http://acmsocc.org/2015/posters/socc15posters-final68.pdf
[31] An overview of gradient descent optimization algorithms: https://ruder.io/optimizing-gradient-descent
[32] CMU 15-721: Query Scheduling: https://15721.courses.cs.cmu.edu/spring2020/slides/12-scheduling.pdf
[33] 破晓之钟: 章六十四 囚笼 - 田渊栋: https://zhuanlan.zhihu.com/p/350919763
[34] DBARepublic: Selectivity Vs Cardinality: http://www.dbarepublic.com/2016/02/selectivity-vs-cardinilaty.html
[35] Apache Calcite Tutorial: Calcite-example-CSV: https://calcite.apache.org/docs/tutorial.html
[36] SQL Server Cardinality Estimation: https://docs.microsoft.com/en-us/sql/relational-databases/performance/cardinality-estimation-sql-server
[37] CockroachDB OptGen Rules (Github): https://github.com/cockroachdb/cockroach/tree/master/pkg/sql/opt/norm/rules
[38] TiDB Design Docs IndexMerge.md (GitHub): https://github.com/pingcap/tidb/blob/master/docs/design/2019-04-11-indexmerge.md
[39] TiDB Planner Core Task.go (Github): https://github.com/pingcap/tidb/blob/master/planner/core/task.go
[40] TiDB Cost Variables (Github): https://github.com/pingcap/tidb/blob/master/sessionctx/variable/tidb_vars.go
[41] TiDB Planner Memo (Github): https://github.com/pingcap/tidb/tree/master/planner/memo
[42] PostgreSQL Doc: Cost Variables: https://www.postgresql.org/docs/10/runtime-config-query.html
[43] PostgreSQL Doc: Join Order Enumeration: https://www.postgresql.org/docs/9.5/planner-optimizer.html
[44] PostgreSQL Doc: Row Estimation Examples: https://www.postgresql.org/docs/current/row-estimation-examples.html
[45] Oracle Concepts: Optimization of Joins: https://docs.oracle.com/cd/F49540_01/DOC/server.815/a67781/c20c_joi.htm
[46] Oracle Doc: User-Defined Statistics/Selectivity/Cost: https://docs.oracle.com/cd/B10500_01/appdev.920/a96595/dci08opt.htm
[47] Oracle Doc: Using Zone Maps: https://docs.oracle.com/database/121/DWHSG/zone_maps.htm
[48] Oracle Query Optimizer Concepts: Adaptive Query Plans: Statistics Feedback: https://docs.oracle.com/database/121/TGSQL/tgsql_optcncpt.htm
[49] Oracle Extended Statistics Enhancements: https://oracle-base.com/articles/11g/extended-statistics-enhancements-11gr2
[50] Hadoop: The Definitive Guide, 4th: Chapter 4 YARN: https://www.oreilly.com/library/view/hadoop-the-definitive/9781491901687/ch04.html
[51] 围棋符合现规则终局的所有下法比宇宙中的原子还多 - Zhihu: https://www.zhihu.com/question/342066985/answer/801498759
[52] 揭秘高性能DolphinDB - Zhihu: https://zhuanlan.zhihu.com/p/40049521
[53] 群论和魔方(P1)- Accela Zhao: https://mp.weixin.qq.com/s/D3ZHMDPgChuCKnMcu95a9A
[54] 分布式系统-分布式事务(P3完)- Accela Zhao: https://mp.weixin.qq.com/s/FvQO_ZfHbdXKlmRnrt1O7Q
