




由于大量数据存储在数据库中,性能和扩展会受到影响。分区很有帮助,因为它可以将大表分成较小的表,从而减少内存交换问题和表扫描,最终提高性能。庞大的数据集被分成更小的分区,更易于访问和管理。PostgreSQL,也称为 Postgres,是一个开源关系数据库管理系统。它健壮可靠,被用作许多应用程序的主要数据仓库。
本文将向您介绍 PostgreSQL主要特性和 PostgreSQL 分区。将用语法和示例解释不同类型的分区;并深入探讨 PostgreSQL 分区的优势和局限性。
什么是 PostgreSQL?
PostgreSQL 是一个开源关系数据库系统。它支持关系 (SQL) 和非关系 (JSON) 查询。它被用作基于 Web 、移动和分析应用程序的主要数据库。它最初被命名为 Postgres,后来在 1996 年改名为PostgreSQL。
以下是 PostgreSQL 的一些常见用例:
LAPP(Linux、Apache、PostgreSQL 和 PHP)堆栈中的强大数据库。
地理空间数据库。
通用事务数据库。
PostgreSQL 支持一些最流行的语言,如 Java、Python、C/C+、C#、Ruby、JavaScript 等。
PostgreSQL的主要特性
用户定义的数据类型:PostgreSQL 可以扩展以创建用户定义的数据类型。它必须具有输入和输出功能。
复杂的锁定机制:存在三种锁定机制,即行级锁定、表级锁和资询锁。
表继承:PostgreSQL 允许基于另一个表创建子表。
Foreign Key Referential Integrity:指定外键值对应于另一个表中的实际主键值。
嵌套事务(保存点):这意味着子查询的结果不会在其父查询回滚时回滚。但是对于保存点,如果顶层事务被回滚,所有的保存点也会被回滚。
什么是 PostgreSQL 分区?
分区是指将一个大表拆分成更小的物理块,这些块可以根据其用途存储在不同的存储介质中。每个部分都有其特点和名称。分区有助于提高数据库服务器的性能,因为需要读取、处理和返回的行数明显减少。您还可以使用 PostgreSQL 分区来划分索引和索引表。
PostgreSQL 分区主要有两种类型:垂直分区和水平分区。在垂直分区中,我们按列划分,在水平分区中,我们按行划分。
水平分区涉及将不同的行放入不同的表中。例如,您将 18 岁以上学生的详细信息存储在一个分区中,将 18 岁以下的学生详细信息存储在另一个分区中。可以在两个分区上创建联合视图以显示所有学生。
垂直分区包括创建列较少的表,并使用其他表来存储剩余的列。规范化还涉及到跨表的列分割,但是垂直分区不仅限于此,甚至在已经规范化的情况下还会对列进行分区。
了解 PostgreSQL 分区
如何创建分区表
首先,您需要使用 CREATE TABLE 并指定分区键和分区类型。
然后在指定每个分区方法的同时使用 CREATE TABLE 创建每个分区。
您可以使用以下代码片段创建主表:
CREATE TABLE main_table_name (
column_1 data type,
column_2 data type,
……
) PARTITION BY RANGE (column_2);复制
您可以使用以下代码片段来创建分区表:
CREATE TABLE partition_name
PARTITION OF main_table_name FOR VALUES FROM (start_value) TO (end_value);复制
PostgreSQL 分区的类型
PostgreSQL 分区:列表分区
在列表分区中,数据根据已指定的离散值进行分区。当需要对地区、部门等离散数据进行任意值分组时,这种方法效果很好。例如职位名称、按地区划分等。
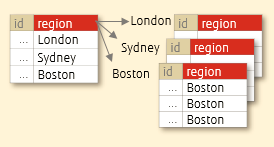
考虑这样一个场景,您正在使用一个管理每个分支机构销售的表并创建一个列表分区,该列表分区根据区域划分表。
创建分区表
mydb=# CREATE TABLE sales_region (id int, amount int, branch text, region text)
mydb-# PARTITION BY LIST (region);复制
创建分区
mydb=# CREATE TABLE London PARTITION OF sales_region FOR VALUES IN ('London');
mydb=# CREATE TABLE Sydney PARTITION OF sales_region FOR VALUES IN ('Sydney');
mydb=# CREATE TABLE Boston PARTITION OF sales_region FOR VALUES IN ('Boston');复制
向分区表添加数据
mydb=# COPY sales_region FROM '/home/tmp/listpart_1.sql';
复制
从分区表中检索数据
mydb=# SELECT * FROM sales_region;
id | amount | branch | region
-----+--------+------------+--------
136 | 150 | Kings Rd | London
147 | 10 | Regent St | London
245 | 100 | College St | Sydney
278 | 50 | George St | Sydney
561 | 100 | Charles St | Boston
537 | 5 | Ann St | Boston
510 | 10 | Park Dr | Boston
(7 rows)复制
从分区表中检索数据
mydb=# SELECT * FROM Boston;
id | amount | branch | region
-----+--------+------------+--------
561 | 100 | Charles St | Boston
537 | 5 | Ann St | Boston
510 | 10 | Park Dr | Boston
(3 rows)复制
PostgreSQL 分区:范围分区
对于范围分区,数据根据所选范围划分为段。当您需要访问时间序列数据时,提供日期(例如年份和月份)很有用。例如,入场日期、按销售日期拆分等。
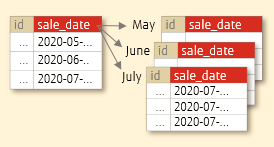
创建分区表
mydb=# CREATE TABLE sales (id int, p_name text, amount int, sale_date date)
mydb-# PARTITION BY RANGE (sale_date);复制
创建分区
mydb=# CREATE TABLE sales_2019_Q4 PARTITION OF sales FOR VALUES FROM ('2019-10-01') TO ('2020-01-01');
mydb=# CREATE TABLE sales_2020_Q1 PARTITION OF sales FOR VALUES FROM ('2020-01-01') TO ('2020-04-01');
mydb=# CREATE TABLE sales_2020_Q2 PARTITION OF sales FOR VALUES FROM ('2020-04-01') TO ('2020-07-01');复制
向分区表添加数据
mydb=# INSERT INTO sales VALUES (1,'prod_A',100,'2020-06-01');
mydb=# INSERT INTO sales VALUES (8,'prod_B', 5,'2020-03-02');复制
从分区表中检索数据
mydb=# SELECT * sales;
id | p_name | amount | sale_date
----+--------+--------+------------
1 | prod_A | 100 | 2020-06-01
8 | prod_B | 5 | 2020-03-02
2 | prod_F | 15 | 2020-03-02
3 | prod_B | 5 | 2020-01-15
4 | prod_C | 10 | 2020-02-11
6 | prod_F | 10 | 2020-01-05
10 | prod_E | 5 | 2020-02-10
5 | prod_E | 10 | 2020-05-15
7 | prod_D | 10 | 2020-04-11
9 | prod_C | 15 | 2020-04-30
(10 rows)复制
从分区中检索数据
mydb=# SELECT * FROM sales_2020_Q2;
id | p_name | amount | sale_date
----+---------+--------+------------
5 | prod_E | 10 | 2020-05-15
7 | prod_D | 10 | 2020-04-11
9 | prod_C | 15 | 2020-04-30
(3 rows)复制
PostgreSQL 分区:哈希分区
每个分区的数据通过提供模数和余数来分区。每个分区将包含模数除以分区键的哈希值得到给定余数的行。当您希望通过几乎均匀地分布数据来避免对单个表的访问集中时,这种方法很有效。
例如,你把它分成三部分(n 是从分区键中的值创建的哈希值)
n % 3 = 0 → 分配给分区 1
n % 3 = 1 → 分配给分区 2
n% 3 = 2 → 分配给分区 3
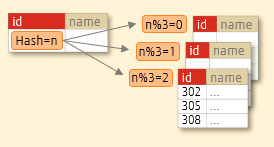
创建分区表
mydb=# CREATE TABLE emp (emp_id int, emp_name text, dep_code int)
mydb-# PARTITION BY HASH (emp_id);复制
创建分区
mydb=# CREATE TABLE emp_0 PARTITION OF emp FOR VALUES WITH (MODULUS 3,REMAINDER 0);
mydb=# CREATE TABLE emp_1 PARTITION OF emp FOR VALUES WITH (MODULUS 3,REMAINDER 1);
mydb=# CREATE TABLE emp_2 PARTITION OF emp FOR VALUES WITH (MODULUS 3,REMAINDER 2);复制
向分区表添加数据
mydb=# INSERT INTO emp SELECT num,
mydb-# 'user_' || num , (RANDOM()*50)::INTEGER FROM generate_series(1,1000) AS num;复制
查看分区表和每个分区的行数
mydb=# SELECT relname,reltuples as rows FROM pg_class
mydb-# WHERE relname IN ('emp','emp_0','emp_1','emp_2')
mydb-# ORDER BY relname;
relname | rows
---------+--------
emp | 0
emp_0 | 324 A
emp_1 | 333
emp_2 | 343
(4 rows)复制
PostgreSQL 分区:复合分区
要构建更复杂的 PostgreSQL 分区布局,可以在一个分区下建立多个分区,如下所示。复合分区有时称为子分区。
例如,可以为产品销售数据库(分区表)创建按月分隔的范围分区和按产品类别划分的列表分区。因为你可能会缩小搜索的分区,提高访问性能,比如当你想获取特定时间段内特定产品类别的销售数据时(例如7月份产品类别为'ghi'的销售数据)。

您可以通过为分区键指定新的范围和值来增加范围分区和列表分区的数量。但是哈希分区不能以同样的方式相加,因为分区的个数是由除法和指定余数的计算决定的。看一下通过划分和更新使用过多的值来重新哈希分区的示例。这里以上面创建的哈希分区为例。
您必须指定用于除法计算的当前值集的倍数。将hash分区从3个分区改为6个分区(3的倍数)的例子如下:

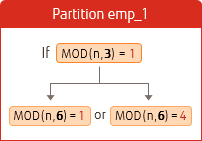

基于上面的例子,你可以看到如何划分为 6 个分区。
您可以假设一个分区表包含 100 万行,它们按如下方式拆分为分区。
mydb=# SELECT relname, reltuples as rows FROM pg_class
mydb-# WHERE relname IN ('emp','emp_0','emp_1','emp_2')
mydb-# ORDER BY relname;
relname | rows
---------+--------
emp | 0
emp_0 | 333263 A
emp_1 | 333497
emp_2 | 333240
(4 rows)复制
从分区表中分离分区
mydb=# ALTER TABLE emp DETACH PARTITION emp_0;
mydb=# ALTER TABLE emp DETACH PARTITION emp_1;
mydb=# ALTER TABLE emp DETACH PARTITION emp_2;复制
重命名分区
mydb=# ALTER TABLE emp_0 RENAME TO emp_0_bkp;
mydb=# ALTER TABLE emp_1 RENAME TO emp_1_bkp;
mydb=# ALTER TABLE emp_2 RENAME TO emp_2_bkp;复制
创建六个分区
mydb=# CREATE TABLE emp_0 PARTITION OF emp FOR VALUES WITH (MODULUS 6, REMAINDER 0);
mydb=# CREATE TABLE emp_1 PARTITION OF emp FOR VALUES WITH (MODULUS 6, REMAINDER 1);
mydb=# CREATE TABLE emp_2 PARTITION OF emp FOR VALUES WITH (MODULUS 6, REMAINDER 2);
mydb=# CREATE TABLE emp_3 PARTITION OF emp FOR VALUES WITH (MODULUS 6, REMAINDER 3);
mydb=# CREATE TABLE emp_4 PARTITION OF emp FOR VALUES WITH (MODULUS 6, REMAINDER 4);
mydb=# CREATE TABLE emp_5 PARTITION OF emp FOR VALUES WITH (MODULUS 6, REMAINDER 5);复制
从分离的分区恢复数据
mydb=# INSERT INTO emp SELECT * FROM emp_0_bkp;
mydb=# INSERT INTO emp SELECT * FROM emp_1_bkp;
mydb=# INSERT INTO emp SELECT * FROM emp_2_bkp;复制
删除分离的分区
mydb=# DROP TABLE emp_0_bkp;
mydb=# DROP TABLE emp_1_bkp;
mydb=# DROP TABLE emp_2_bkp;复制
将划分后的数据显示为六个分区
mydb=# SELECT relname,reltuples as rows FROM pg_class
mydb-# WHERE relname IN ('emp','emp_0','emp_1','emp_2','emp_3','emp_4','emp_5')
mydb-# ORDER BY relname;
relname | rows
---------+---------
emp | 0
emp_0 | 166480 A
emp_1 | 166904
emp_2 | 166302
emp_3 | 166783
emp_4 | 166593
emp_5 | 166938
(7 rows)复制
在庞大的数据集上执行上述步骤可能需要时间,因此您可以为每个分区单独执行这些步骤。
何时使用 PostgreSQL 分区?
如果单表无法提供分区的大部分好处,则可以选择分区表。因此,如果你想在任何给定时间向一张表写入大量数据,你会需要分区。除了数据之外,用户可能还应该考虑其他因素,例如分区带来的显著性能提升以及将 PostgreSQL 扩展到更大数据集的能力。
以下是有关何时对表进行分区的一些建议:
1、应考虑大于 2GB 的表。
2、包含历史数据和新数据的表仅添加到新分区。例如,一个表中只有当月的数据需要更新,其他 11 个月的数据是只读的。
PostgreSQL 分区的优点
分区有几个好处:
1、与从单个大表中进行查询相比,性能要高得多。
2、它非常灵活,可以为用户提供良好的控制。用户可以根据需要创建任意级别的分区,并为每个分区单独或一起使用约束、触发器和索引。
3、很少使用的数据可以移动到更便宜或更慢的媒体存储中。
4、批量加载和数据删除可以更快地完成,因为这些操作可以根据用户要求在各个分区上执行。
PostgreSQL 分区的限制
以下是 PostgreSQL 分区的一些限制:
1、没有在所有分区上自动创建匹配索引的选项。必须使用单独的命令向每个分区添加索引。这也意味着没有办法构建主键、唯一约束或跨越所有分区的排除约束;相反,每个叶分区必须单独约束。
2、不支持引用分区表的外键,以及从分区表到另一个表的外键引用,因为分区表不支持主键。
3、不可能在同一分区树中混合临时和永久关系。因此,如果分区表是永久的,则其分区也必须是永久的,如果分区表是临时的,其分区也必须是临时的。使用临时关系时,分区树的所有成员必须来自同一会话。
4、行触发器必须在单个分区上定义,而不是在分区表中定义。
5、范围分区不接受 NULL 值。
结论
简而言之,分区是关系数据库中用于将大表分解为较小分区的一种方法。这有助于更快地对大表执行查询。在本文中,您学习了 4 种类型的 PostgreSQL 分区以及如何使用它们。表从分区中受益的确切点由应用程序确定,但一个好的经验法则是表的大小应该超过数据库服务器的物理内存。
然而,作为一名开发人员,从数据库、CRM、项目管理工具、流媒体服务、营销平台等多种数据源中提取复杂数据到您的 PostgreSQL 数据库似乎非常具有挑战性。如果您来自非技术背景或数据仓库和分析游戏的新手,Hevo Data 可以提供帮助!


点击此处阅读原文
↓↓↓
