





MySQL的内存分配、使用、管理的模块较多,总体上分为上中下三篇介绍:上篇文章主要介绍InnoDB层和SQL层内存分配管理器;中篇介绍InnoDB的内存结构和使用特点;下篇介绍内存使用限制。本篇为上篇,代码版本主要基于8.0.25。
1.InnoDB层内存分配管理器
1.1 ut_allocator
ut_allocator可以作为std容器的内存分配器(如std::map<K, V, CMP, ut_allocator>),让容器内部的内存通过innodb提供的内存可追踪的方式进行分配。下面分别就ut_allocator提供的不同内存分配方式作进一步介绍。
#ifdef UNIV_PFS_MEMORY#define UT_NEW(expr, key) ::new (ut_allocator<decltype(expr)>(key).allocate(1, NULL, key, false, false)) expr...#define ut_malloc(n_bytes, key) static_cast<void *>(ut_allocator<byte>(key).allocate(n_bytes, NULL, UT_NEW_THIS_FILE_PSI_KEY, false, false))...#else /* UNIV_PFS_MEMORY */#define UT_NEW(expr, key) ::new (std::nothrow) expr...#define ut_malloc(n_bytes, key) ::malloc(n_bytes)...#endif
allocate
// 比实际申请多出一块pfx的内存total_bytes+=sizeof(ut_new_pfx_t)// 申请内存...// 返回实际内存开始的地址return (reinterpret_cast<pointer>(pfx + 1));
加入了内存分配重试机制
for (size_t retries = 1;; retries++) {// 内存分配malloc/callocmalloc(); // calloc()...if (ptr != nullptr || retries >= alloc_max_retries) break;std::this_thread::sleep_for(std::chrono::seconds(1));}
deallocate
deallocate_trace(pfx);free(pfx);
reallocate
allocate_large
申请大块内存(used in buf_chunk_init())、添加pfx信息。需要注意的是,mmap的方式没有消耗实际的物理内存,该部分的内存无法通过jemalloc等方式追踪。
pointer ptr = reinterpret_cast<pointer>(os_mem_alloc_large(&n_bytes));|->mmap()/shmget()、shmat()、shmctl()...allocate_trace(n_bytes, PSI_NOT_INSTRUMENTED, pfx);
deallocate_large
释放pfx指针,释放large内存
deallocate_trace(pfx);os_mem_free_large(ptr, pfx->m_size);|->munmap()/shmdt()
1.2 mem_heap_allocator
类似ut_allocator,mem_heap_allocator也可以作为stl的allocator来使用。但要注意的是,该类型的分配器只提供mem_heap_alloc函数进行内存的申请,没有内存的释放、复用和合并等操作。
class mem_heap_allocator {...pointer allocate(size_type n, const_pointer hint = nullptr) {return (reinterpret_cast<pointer>(mem_heap_alloc(m_heap, n * sizeof(T)))); // 内存申请调用mem_heap_alloc}void deallocate(pointer p, size_type n) {}; // 内存释放等为空操作...}
数据结构
该结构结构是一个非空的内存块链表,由一个个大小不一的mem_block_t线性连接。重点关注free_block和buf_block,某种程度上来说,这两个指针定义了实际数据存放的位置。根据申请类型的不同,数据存放在两者之一指向的内存。利用mem_heap_t进行内存分配的方式可以将多次的内存分配合并为单次进行,之后的内存请求就可以在InnoDB引擎内部进行,从而减小了频繁调用函数malloc和free带来的时间与性能的开销。
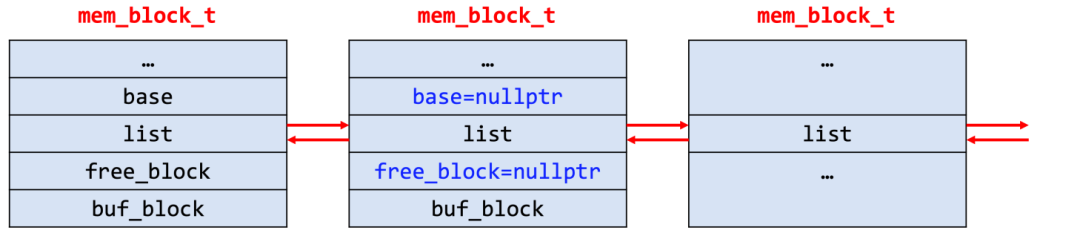
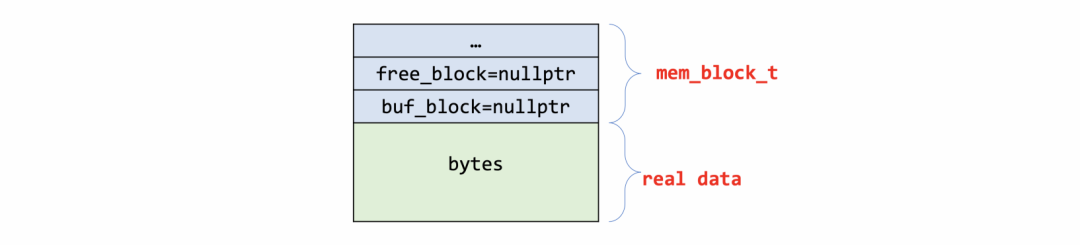
typedef struct mem_block_info_t mem_block_t;typedef mem_block_t mem_heap_t;.../** The info structure stored at the beginning of a heap block */struct mem_block_info_t {...UT_LIST_BASE_NODE_T(mem_block_t) base; /* 链表基节点,只在第一个block定义 */UT_LIST_NODE_T(mem_block_t) list; /* block链表 */ulint len; /*!< 当前block大小 */ulint total_size; /*!< 所有block总大小 */ulint type; /*!< 分配类型 */ulint free; /*!< 当前block的可用位置 */ulint start; /*!< block构建时free的起始位置(没看到较多的用途) */void *free_block; /* 包含有 MEM_HEAP_BTR_SEARCH 类型的heap中,heap root挂着free_block用以申请更多的空间,其他类型该指针为空 */void *buf_block; /* 内存从buffer pool申请,保存buf_block_t指针,否则为空 */};
内存类型
根据申请的内存来源,mem_heap_t可以分为下面几种类型:
#define MEM_HEAP_DYNAMIC 0 /* 原始申请,调用innodb内存申请ut_allocator相关 */#define MEM_HEAP_BUFFER 1 /* 从buffer_pool获取内存 */#define MEM_HEAP_BTR_SEARCH 2/* 使用free_block中的内存 */
在此基础上,组合定义了更多的分配方式,让内存的分配更加灵活。
/** Different type of heaps in terms of which data structure is using them */#define MEM_HEAP_FOR_BTR_SEARCH (MEM_HEAP_BTR_SEARCH | MEM_HEAP_BUFFER)#define MEM_HEAP_FOR_PAGE_HASH (MEM_HEAP_DYNAMIC)#define MEM_HEAP_FOR_RECV_SYS (MEM_HEAP_BUFFER)#define MEM_HEAP_FOR_LOCK_HEAP (MEM_HEAP_BUFFER)
根据传入的size和heap类型,构建一个memory heap结构,size最小为64。实际上在内部的构建逻辑中可以知道单个mem_block最大的size和定义的page_size相同(一般为16K)。
创建mem_heap_t首先需要构建一个root节点,即前文所提到的链表根节点。通过控制block创建函数 mem_heap_create_block传入的第一个参数heap=nullptr,表明该block为mem_heap_t中的第一个节点。在type包含MEM_HEAP_BTR_SEARCH操作位的情况下,可能会出现构建失败的情况,详细的逻辑和失败原因会在后文提出。
创建完第一个block后,将其置为base节点,同时更新链表信息,完成mem_heap_t (根结点)的创建。
mem_heap_t *mem_heap_create_func(ulint size, ulint type) {mem_block_t *block;if (!size) {size = MEM_BLOCK_START_SIZE;}// 创建mem_heap的第一个block,传入的第一个参数是nullptrblock = mem_heap_create_block(nullptr, size, type, file_name, line);// 在MEM_HEAP_BTR_SEARCH模式下,存在构建失败的可能性,返回空指针if (block == nullptr) {return (nullptr);}由于BP resize的可能性,因此第一个block不能从BP中获取ut_ad(block->buf_block == nullptr);// 初始化链表基节点(base不为空,标志该节点为基节点)UT_LIST_INIT(block->base, &mem_block_t::list);UT_LIST_ADD_FIRST(block->base, block);return (block);}
前文提及,若type包含MEM_HEAP_BTR_SEARCH的操作位,则数据有可能保存在free_block对应的内存单元中。此时需要单独释放创建的free_block,然后由后往前,逐个释放mem_heap_t链表上的各个block。
void mem_heap_free(mem_heap_t *heap) {...// 获取链表中最后一个节点block = UT_LIST_GET_LAST(heap->base);// 释放free_block节点(MEM_HEAP_BTR_SEARCH模式创建)if (heap->free_block) {mem_heap_free_block_free(heap);}// 由后往前逐个释放blockwhile (block != nullptr) {/* Store the contents of info before freeing current block(it is erased in freeing) */prev_block = UT_LIST_GET_PREV(list, block);mem_heap_block_free(heap, block);block = prev_block;}}
// case 1if (type == MEM_HEAP_DYNAMIC || len < UNIV_PAGE_SIZE / 2) {ut_ad(type == MEM_HEAP_DYNAMIC || n <= MEM_MAX_ALLOC_IN_BUF);block = static_cast<mem_block_t *>(ut_malloc_nokey(len));} else {len = UNIV_PAGE_SIZE;// case 2if ((type & MEM_HEAP_BTR_SEARCH) && heap) {// 从heap root的free_block获取内存buf_block = static_cast<buf_block_t *>(heap->free_block);heap->free_block = nullptr;if (UNIV_UNLIKELY(!buf_block)) {return (nullptr);}} else {// case 3buf_block = buf_block_alloc(nullptr);}block = (mem_block_t *)buf_block->frame;}
这段代码做了以下几件事:
1.当前block类型和mem_heap_t->base的类型不兼容:原始的根结点申请时若不包含MEM_HEAP_BTR_SEARCH位,则构建时free_block是nullptr,在line 12就会获得空指针而直接返回;
UNIV_MEM_FREE(block, len);UNIV_MEM_ALLOC(block, MEM_BLOCK_HEADER_SIZE);block->buf_block = buf_block;block->free_block = nullptr;
前面两句是将block对应的数据置为free状态,同时初始化头部的数据,为后面的len等数据的初始化做准备;后两句的设置分几种情况一一说明:
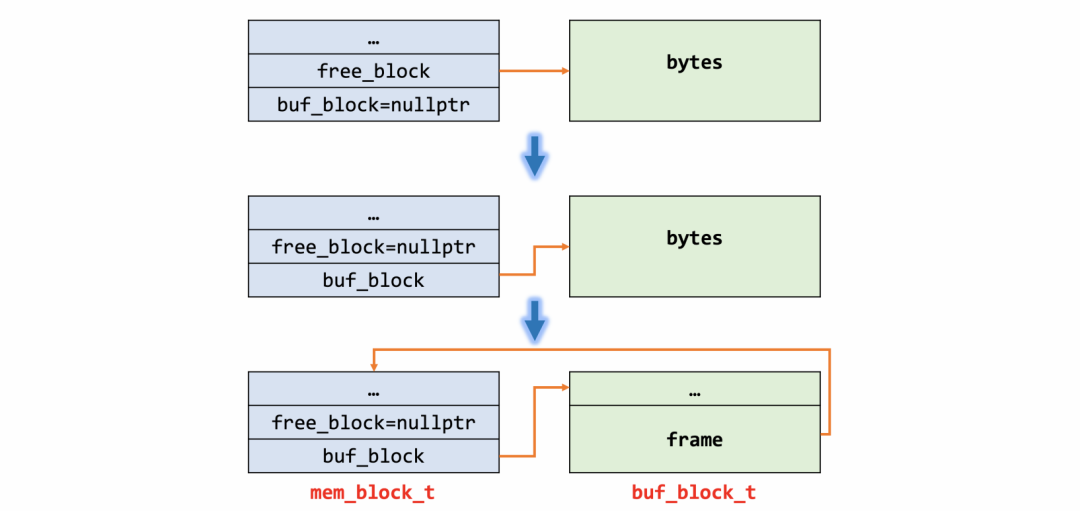
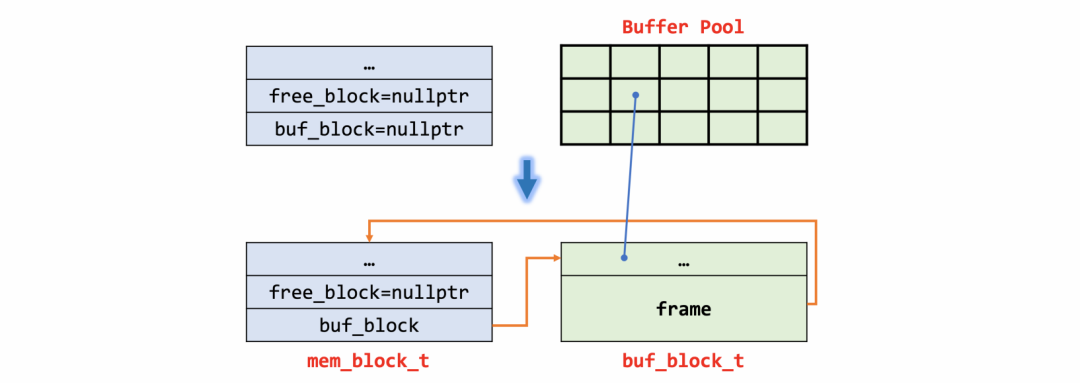
case 2/3内存结构最终形态是一致的,区别在于case2是从free_block转换得到buf_block,而case3是从BP中直接申请得到。其中free_block一般在构建mem_heap_t时由外部指定。
可以看到无论是case1、case2、case3或是多种case的组合,buf_block和free_block的修改都能达到正确设置数据的目的。
获取buf_block(alloc方式获取的将会是nullptr)
从mem_heap_t链表移除、修改total_size
ut_alloc方式申请的block,则调用ut_free方式释放block;否则初始化block数据(因为在从bP/free_block获取之后,block除头部之外的部分可能是是free的状态)并用buf_block_free方式释放,使之成为BP中直接可用的free page。
获取最后一个block,从最后一个block分配
申请给定大小的内存区域,不够则调用mem_heap_add_block添加新的block,MEM_HEAP_BTR_SEARCH下可能会失败,原因同上
更新free值(申请后可用空间变小了),初始化内存区域并返回数据指针buf(block+free偏移)
每次新添加的block size是上一个block的2倍,到达上限则保持不变
调用mem_heap_create_block并添加新的block到链表尾部
最后返回新的block
2.SQL层内存分配管理器MEM_ROOT
MEM_ROOT作为一种通用的内存管理对象,大量使用于sql层,如在THD、TABLE_SHARE等结构中都包含了其作为内存分配器。事实上,MEM_ROOT只是负责管理内存,实际分配的内存来源是其结构成员Block,MEM_ROOT中只包含一块Block且只对当前唯一的Block负责,Block则是含有指向前一Block节点的指针,串成一条链表。
和1.2.1小结提到的mem_heap_t不同,MEM_ROOT主要负责sql层相关的内存分配,mem_heap_t在innodb中单独实现,负责innodb相关的内存分配,但两者的结构和实现模式上是类似的。
2.1 MEM_ROOT数据结构
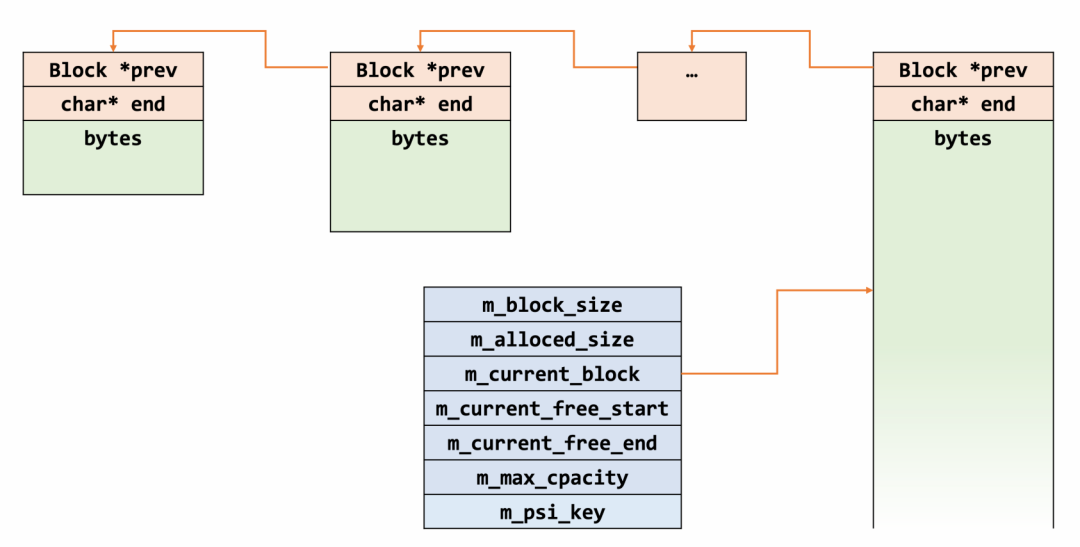
Block是其核心结构,所有的内存分配都源自于此。Block中包含了指向前1Block的指针prev,同时保留了end作为地址范围的标志,表明Block所管理的内存范围。 m_block_size记录了MEM_ROOT下一次要分配和管理的Block内存块的总大小,当申请新的Block块时,该值都会更新为原值的1.5倍。 m_allocated_size记录了MEM_ROOT从OS分配出的内存总量,每次分配新的Block时该值也会进行更新。 m_current_block、m_current_free_start、m_current_free_end分别记录了当前管理block的起始地址、空闲地址和结束地址。 m_max_capacity定义了MEM_ROOT的管理的最大内存,m_error_for_capacity_exceeded是内存超出最大限制的控制开关,m_error_handler是内存超出的错误处理函数指针;m_psi_key是PFS内存监测点。
2.2 MEM_ROOT关键接口
MEM_ROOT的原始构造方式内容很简单,只对m_block_size、m_orig_block和m_psi_key进行赋值,同时MEM_ROOT采用了移动构造和移动赋值的方式,对持有的MEM_ROOT进行接管,主要逻辑如下:
// 移动构造函数MEM_ROOT(MEM_ROOT &&other)noexcept: m_xxx(other.m_cxxx),...{other.m_xxx = nullptr/0/origin_value;...}// 移动赋值MEM_ROOT &operator=(MEM_ROOT &&other) noexcept {Clear();::new (this) MEM_ROOT(std::move(other));return *this;}
该函数用于申请新的Block,根据使用场景的差异,底层调用了两种分配模式,返回的内存地址同样是对齐的。
当所需的内存很大时或是有独占一块内存的需求时,在申请完新的内存块后,并不会将新生请的Block置为当前所管理的Block(除非是MEM_ROOT首次申请),而是将其置为链表中的倒数第2块(即current_block的前一节点)。设计者不希望大内存申请和独占内存的形式对后续的内存分配造成干扰,大内存的申请会导致后续分配Block时x1.5的基数变大,难以控制内存申请量的增长;同时,若后续的内存分配和有独占内存需求的内存块相接,会导致内存的控制复杂。通过保持原有的current_block的方式,能够很好地避免上述问题的发生。 在非上述的情况下,优先使用追加内存块到current_block尾部并更新current_block的方式进行分配。
void *MEM_ROOT::AllocSlow(size_t length) {// 本次申请的内存很大或是要求是独占一块内存的形式if (length >= m_block_size || MEM_ROOT_SINGLE_CHUNKS) {Block *new_block =AllocBlock(/*wanted_length=*/length, /*minimum_length=*/length);if (new_block == nullptr) return nullptr;if (m_current_block == nullptr) {new_block->prev = nullptr;m_current_block = new_block;m_current_free_end = new_block->end;m_current_free_start = m_current_free_end;} else {// Insert the new block in the second-to-last position.new_block->prev = m_current_block->prev;m_current_block->prev = new_block;}return pointer_cast<char *>(new_block) + ALIGN_SIZE(sizeof(*new_block));} else { // 常规情况if (ForceNewBlock(/*minimum_length=*/length)) {return nullptr;}char *new_mem = m_current_free_start;m_current_free_start += length;return new_mem;}}
在设置了内存超出限制的错误标志下,大内存的申请可能会导致失败。同时AllocBlock支持传入wanted_length和minium_length参数,在某些情况下能够分配出minium_length的内存大小。在每次分配完毕后,m_block_size都会调整为当前的1.5倍,避免后续频繁的调用alloc。
该函数对应上文AllocSlow的第二种内存分配方式,直接调用AllockBlock进行内存块的申请,然后将其挂在Block链表的尾部,并设置其为MEM_ROOT所管理的当前Block。
Clear函数执行的逻辑较为简单,主要做了两件事:
1.将MEM_ROOT的所有状态置为初始状态
2.遍历Block链表节点并释放
当此前使用的内存不再需要试图释放,但又不想再MEM_ROOT再次被使用时重新走一遍Alloc...的流程时,ClearForReuse起了很大的作用。和Clear函数free所有Block不同,ClearForReuse会保持当前的Block,而释放其他节点。换言之,经过ClearForReuse操作后,Block链表中只留下了最后的节点。但是在独占内存的场景下,代码逻辑依旧会走到Clear()。
2.3 MEM_ROOT在THD中的应用
THD中包括了三个MEM_ROOT(包括对象和指针),main_mem_root,user_var_events_alloc和mem_root。
THD::THD(bool enable_plugins): Query_arena(&main_mem_root, STMT_REGULAR_EXECUTION),...lex_returning(new im::Lex_returning(false, &main_mem_root)),... {main_lex->reset();set_psi(nullptr);mdl_context.init(this);init_sql_alloc(key_memory_thd_main_mem_root, &main_mem_root,global_system_variables.query_alloc_block_size,global_system_variables.query_prealloc_size);...}
当前mem_root的指针,在THD初始化时指向main_mem_root,但在实际应用时会发生变化,通过临时改变mem_root指向的方式使用其他对象的MEM_ROOT来申请内存,使用完毕后再将mem_root指向初始内存地址(main_mem_root)。
问:为什么要把mem_root设计成可变动的对象?为什么要把mem_root的内存指针嵌入到THD?
答:方便控制内存大小,若thd->mem_root始终指向main_mem_root,相应的内存会一直存在直到THD析构,改变mem_root指向可以更好地控制内存生存周期,让临时的内存占用得以释放,和长期存在的内存分离。嵌入到THD(实际上是其父类Query_arena)中,可以让THD占用的内存统计信息更清晰、管理过程更简洁,即尽管该部分内存不是直接由THD产生,而是在执行语句的过程中产生的,同样需要把“责任”归属在THD上。简化函数传参,减少一个MEM_ROOT的参数,传入THD即可。
THD::THD(bool enable_plugins): Query_arena(&main_mem_root, STMT_REGULAR_EXECUTION),...MEM_ROOT* old_mem_root = thd->mem_root; // 保存原来的mem_root(main_mem_root)thd->mem_root = xxx_mem_root; // mem_root大多是临时性的MEM_ROOT// do something using memory...thd->mem_root = old_mem_root; // 恢复成原来的mem_root(main_mem_root)
// sql/dd_table_share.ccopen_table_def()// sql/sp_head.ccsp_parser_data::start_parsing_sp_body() &&sp_parser_data::finish_parsing_sp_body()// sql/sp_instr.cc PSI_NOT_INSTRUMENTEDLEX *sp_lex_instr::parse_expr()// sql/sql_cursor.ccQuery_result_materialize::start_execution()// sql/sql_table.ccrm_table_do_discovery_and_lock_fk_tables()drop_base_table()lock_check_constraint_names()// sql/thd_raii.h 该类及其调用之处(sql/auth/sql_auth_cache.cc:grant_load())class Swap_mem_root_guard;// sql/auth/sql_authorization.ccmysql_table_grant() // 存储表级、行级权限mysql_routine_grant() // 存储routine级权限/* sql/dd/upgrade_57/global.h storage/ndb/pligin/ndb_dd_upgrade_table.cc该类及其调用之处 */class Thd_mem_root_guard
memroot指针,用于分配THD中的Binlog_user_var_event数组元素,通常和thd->mem_root指向相同。
3.总结
MySQL在内存的分配、使用、管理上做了很多工作和优化,各模块单独抽离出来也是一套内存分配管理系统,其设计方式和使用策略都有值得学习的地方。
InnoDB层中ut_allocator在最新的8.0版本中已经删去,对应的内存申请和释放代码修改为模版函数。mem_heap_allocator有效减少了内存碎片,比较适用于短周期多次分配小内存的场景。但其在使用过程中不会free内存,当单个block出现空闲较大的情况时,会有一定程度的内存浪费。
MEM_ROOT是SQL层中使用最多的内存分配器,类似mem_heap_t,其同样存在Block碎片问题,但其在设计时提供了ClearForReuse这样的接口,可以及时释放前面所占用的内存;此外,MEM_ROOT在设计中考虑了独占内存和大内存的场景,降低了后续申请的内存大小。同时在THD结构中,MEM_ROOT指针的灵活使用给内存的运用提供了新的思路,值得借鉴。
作者信息
宋华雄(桦雄)来自RDS MySQL内核组,从事RDS MySQL内核研发工作。有任何问题和咨询请发邮件至:vogts.wangt@alibaba-inc.com










 点击「阅读原文」了解云数据库RDS MySQL更多内容
点击「阅读原文」了解云数据库RDS MySQL更多内容
