





本文作者 | 韩医徽

在这篇文章中主要介绍 ELT 的模式,开源工具 DBT,以及 DBT 的简要用法。

数据准备模式:
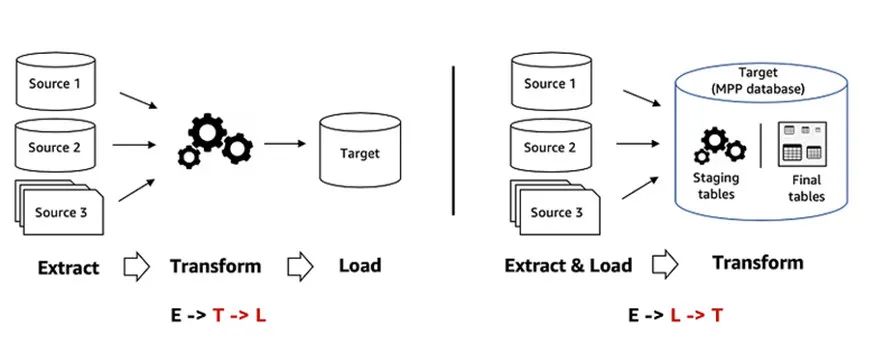
ETL 还是 ELT, 如何选择?
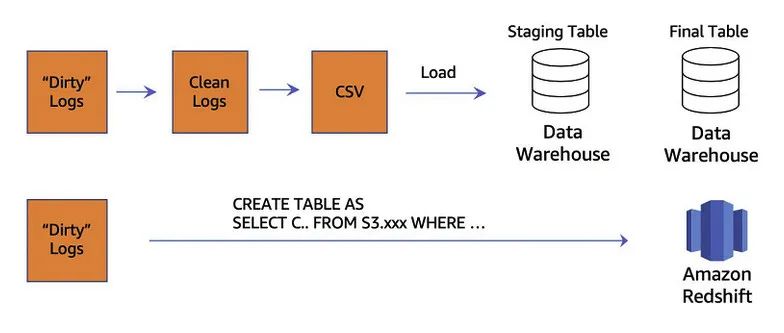
在 ETL and ELT design patterns for lake house architecture using Amazon Redshift 中,详细分析对比了 ETL 和 ELT 两种模式。在本篇文章中,不再详细去分析对比,只是选取其中关键部分加上笔者理解,目的是帮助大家能够更全面的理解本文中基于 DBT 做数据准备的方案。

扫码查看 Amazon Web Services Blog:
ETL and ELT design patterns for
lake house architecture using Amazon Redshift 文章
DBT 简介
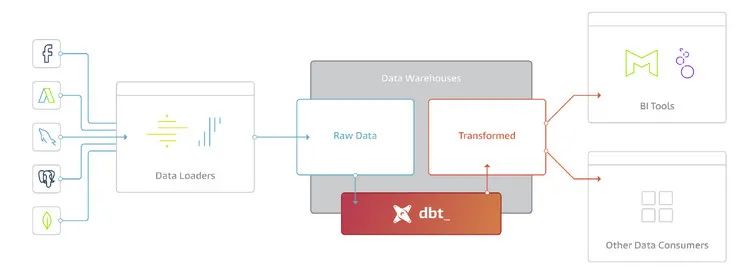

1、DBT 集成了 package manager 的功能。
数据分析人员可以把常用的包做成 Package,发布到私有或者公开的仓库,方便重用;
2、DBT 支持开发人员定义测试用例,可以方便的对编写的代码进行测试,保障代码质量;
3、DBT 支持根据开发人员编写代码中的元数据生成对应文档(类似于数据分析领域的 Swagger), 降低文档维护工作量。
使用 DBT 在 Redshift 中做数据转换
(Data Transformation)

扫码下载演示所使用的的示例代码
环境准备

扫码查看 Redshift 官方文档
▼Amazon Web Services CDK 开发环境搭建

扫码参看官方教程
npm install -g aws-cdk #安装cdk clicdk --version #查看版本
扫码查看详情
▼搭建测试 Redshift 集群
git clone https://github.com/readybuilderone/elt-with-dbt-demo.gitcd elt-with-dbt-demonpx projennpx cdk bootstrapnpx cdk deploy --profile <YOUR-PROFILE>用于存放需要加载到 Redshift 数据的 S3 的 BucketName; Redshift 的 Host 地址; Redshift 的 Execute Role 的 ARN。

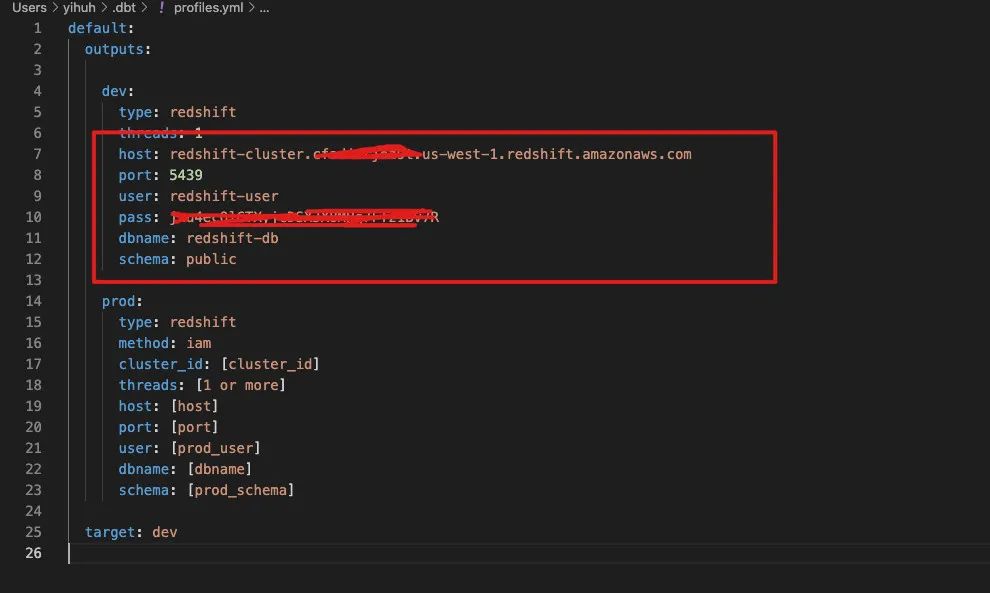
Redshift DB Name: redshift-db Redshift User: redshift-user Redshift Port: 5439 Redshift Host: 参考CDK运行截图


扫码查看详情
dbt --version#正确安装应该会输出如下内容installed version: 0.20.2 latest version: 0.20.2Up to date!Plugins: - bigquery: 0.20.2 - snowflake: 0.20.2 - redshift: 0.20.2 - postgres: 0.20.2▼新建 DBT Project
数据准备
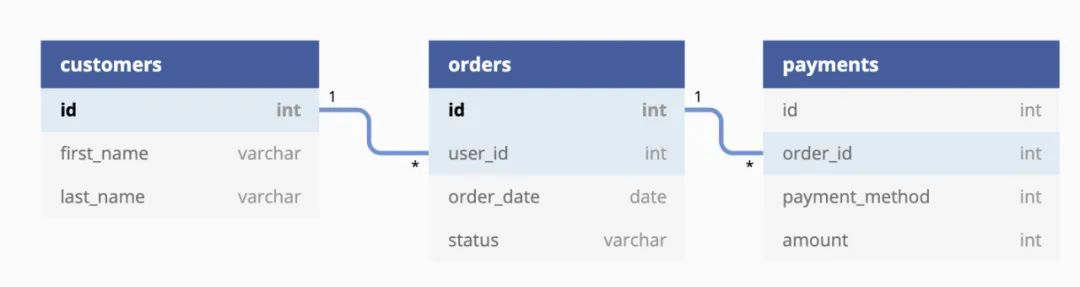
▼测试数据说明
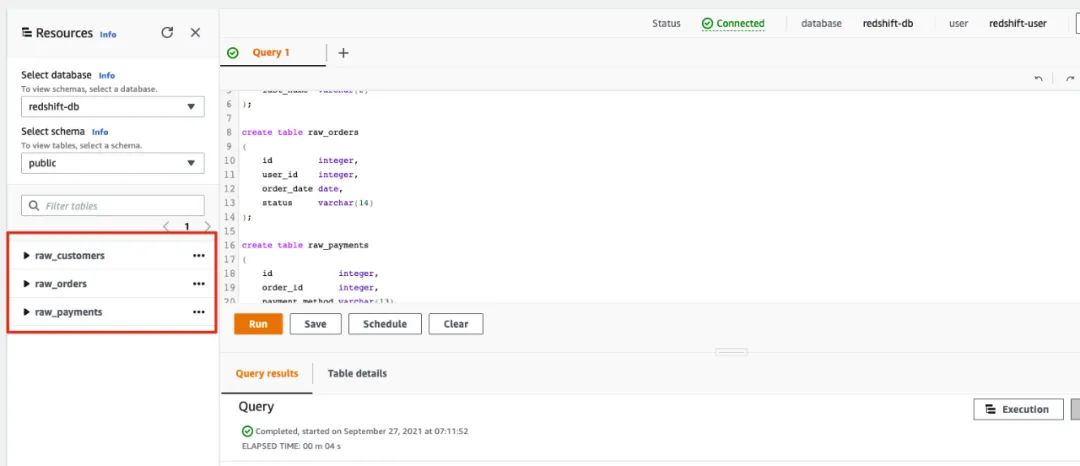
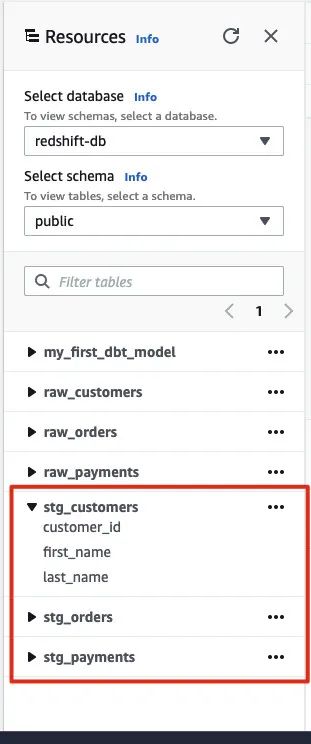
▼加载测试数据到 Redshift
cd ./sample_db/jaffle_shopaws s3 sync . s3://<YOUR-BUCKET>/jaffle_shop/ --profile <YOUR-PROFILE>



使用 DBT 做 Data Transform,Test 和 Generate Doc
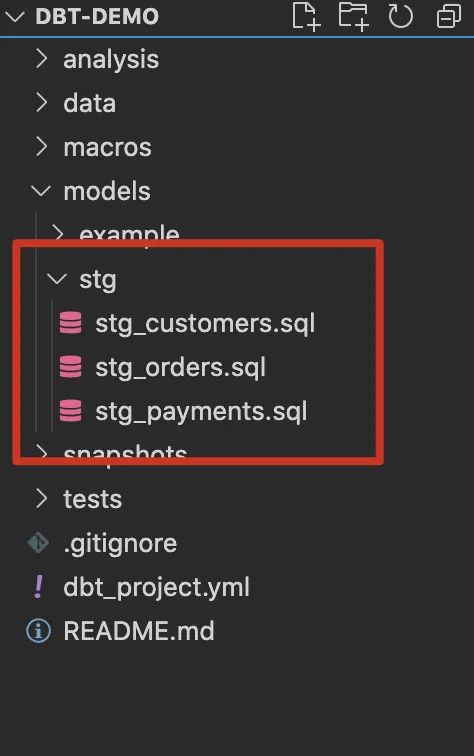
▼使用 DBT 做 Data Transform
stg_customers.sql
with source as (
select * from raw_customers
),
renamed as (
select
id as customer_id,
first_name,
last_name
from source
)
select * from renamed
stg_orders.sql
with source as (
select * from raw_orders
),
renamed as (
select
id as order_id,
user_id as customer_id,
order_date,
status
from source
)
select * from renamed
stg_payments.sql
with source as (
select * from raw_payments
),
renamed as (
select
id as payment_id,
order_id,
payment_method,
-- `amount` is currently stored in cents, so we convert it to dollars
amount / 100 as amount
from source
)
select * from renamed复制
▼使用 DBT 做 Test
customer_id, order_id, payment_id 要求唯一切不能为 null order的status 只能为 ’placed’, ‘shipped’, ‘completed’, ‘return_pending’, ‘returned’ 之一; payment method 只可以为 ‘credit_card’, ‘coupon’, ‘bank_transfer’, ‘gift_card’ 之一;
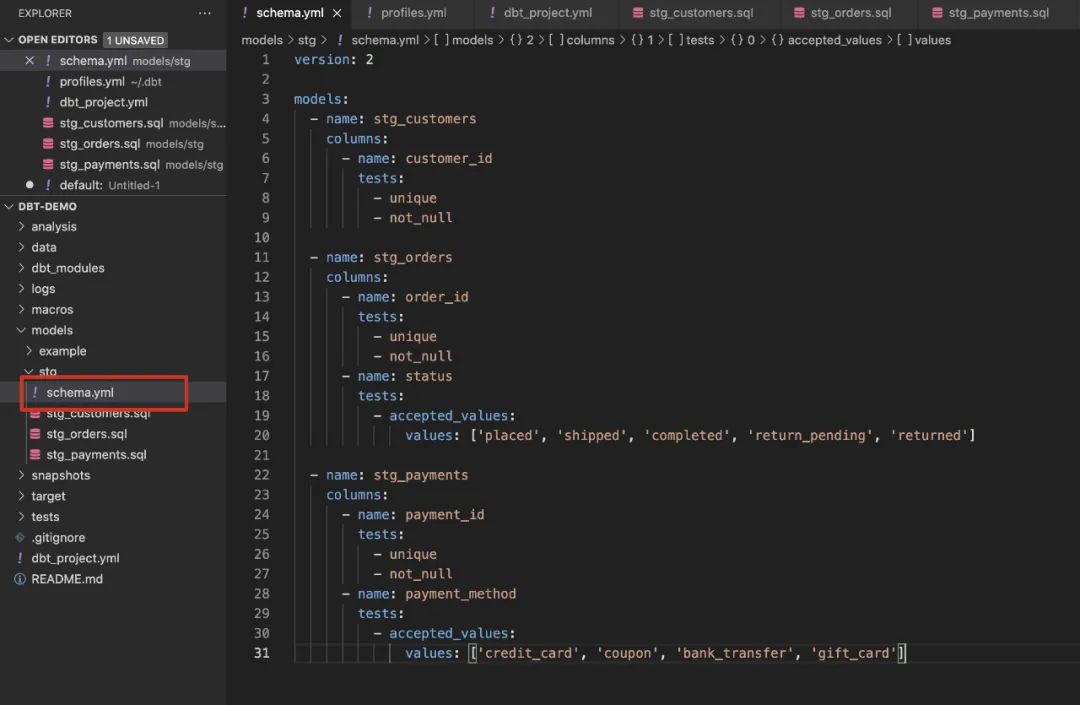
version: 2
models:
- name: stg_customers
columns:
- name: customer_id
tests:
- unique
- not_null
- name: stg_orders
columns:
- name: order_id
tests:
- unique
- not_null
- name: status
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
- name: stg_payments
columns:
- name: payment_id
tests:
- unique
- not_null
- name: payment_method
tests:
- accepted_values:
values: ['credit_card', 'coupon', 'bank_transfer', 'gift_card']复制
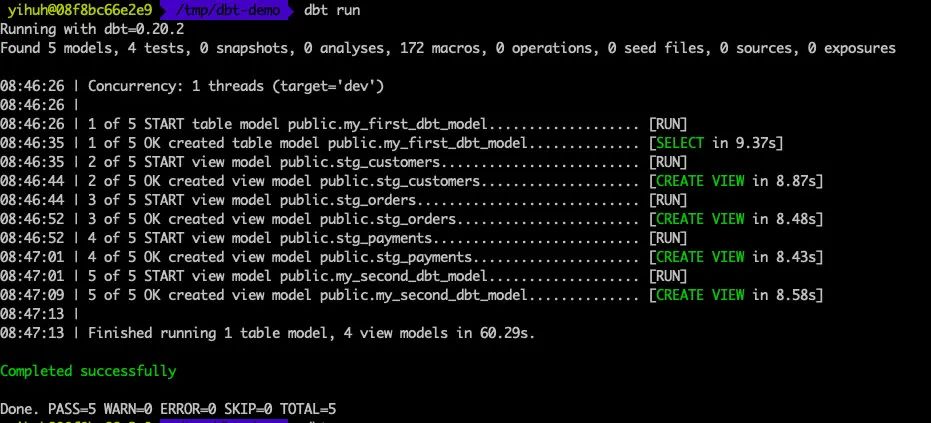
dbt test --models stg_customers, stg_orders, stg_payments
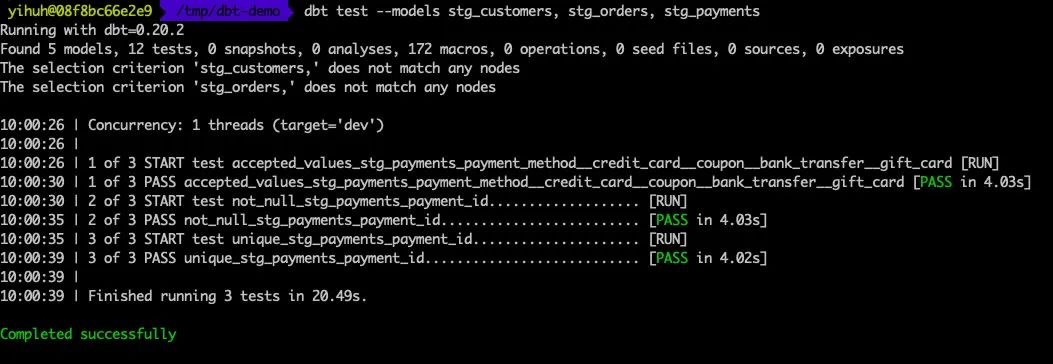
▼使用 DBT Generate Doc
version: 2
models:
- name: customers
description: One record per customer
columns:
- name: customer_id
description: Primary key
tests:
- unique
- not_null
- name: first_order_date
description: NULL when a customer has not yet placed an order.
- name: stg_customers
description: This model cleans up customer data
columns:
- name: customer_id
description: Primary key
tests:
- unique
- not_null
- name: stg_orders
description: This model cleans up order data
columns:
- name: order_id
description: Primary key
tests:
- unique
- not_null
- name: status
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']复制
dbt docs generatedbt docs serve
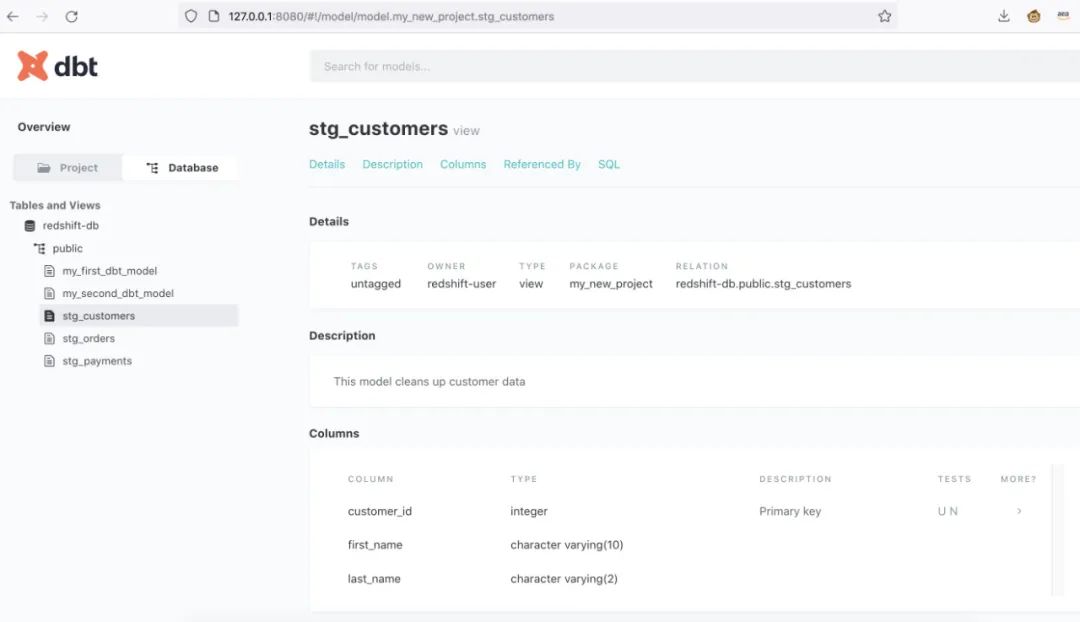
文档生成成功。
总结
●
作者介绍

韩医徽
亚马逊云科技解决方案架构师,负责亚马逊云科技合作伙伴生态系统的云计算方案架构咨询和设计,同时致力于亚马逊云科技云服务在国内的应用和推广。
- END -

长按识别左侧二维码
关注我们>>
宁夏西云数据科技有限公司(简称“西云数据”)是亚马逊云科技中国(宁夏)区域云服务的运营方和服务提供方,作为西云数据的战略技术合作伙伴,亚马逊云科技向西云数据提供技术、指导和专业知识。西云数据成立于 2015 年,是一家持有互联网数据中心服务和互联网资源协作服务牌照的云服务提供商。2017 年 12 月 12 日, 西云数据正式推出亚马逊云科技中国(宁夏)区域云服务,现已开通 3 个可用区。西云数据市场销售总部设立于北京,在全国多地设有分支机构以服务全国各地的企业客户。
西云数据致力于将世界先进的 Amazon Web Services 云计算技术带给中国客户,为客户提供优质、安全、稳定、可靠的云服务,全力支持中国企业和机构的创新发展。
15 年多以来,亚马逊云科技(Amazon Web Services)一直是世界上以服务丰富、应用广泛而著称的云平台。亚马逊云科技一直不断扩展其服务组合以支持几乎云上任意工作负载,目前提供了超过 200 项全功能的服务,涵盖计算、存储、数据库、联网、分析、机器人、机器学习与人工智能、物联网、移动、安全、混合云、虚拟现实与增强现实、媒体、以及应用开发、部署与管理等方面,遍及 25 个地理区域的 80 个可用区(AZ),并已公布计划在澳大利亚、印度、印度尼西亚、西班牙、瑞士和阿拉伯联合酋长国新建 6 个区域、18 个可用区。全球数百万客户,包括发展迅速的初创公司、大型企业和领先的政府机构都信赖亚马逊云科技,通过亚马逊云科技的服务强化其基础设施,提高敏捷性,降低成本。欲了解亚马逊云科技的更多信息,请访问:http://aws.amazon.com。




