1. 说明
本文档主要是有关oracle用户、对象、表空间相关的内容,希望对大家有所帮助。
2. 用户
2.1.用户的创建和删除
1、创建用户
create user 用户名identified by “密码”default tablespace 表空间名temporary tablespace 临时表空间名profile DEFAULTquota unlimited on 表空间名;
2、删除用户
drop user 用户名 cascade (删除用户和级联关系);
显示当前数据库下所有用户
SQL> select username from dba_users;USERNAME------------------------------------------------------------LIQIRMANTARGET1GGSSPATIAL_WFS_ADMIN_USRSPATIAL_CSW_ADMIN_USRHRAPEX_PUBLIC_USEROEDIPSHIXMDDATAPMBI复制
2.2. 权限的授予和回收
1、授予权限
语法:
GRANT CONNECT, RESOURCE TO 用户名;
GRANT SELECT ON 表名 TO 用户名;
GRANT SELECT, INSERT, DELETE ON表名 TO 用户名1, 用户名2;
(1)创建session的权限给ggs(create session就是允许使用这个用户在服务器上创建session。通俗的说,就是允许这个用户登录。)
SQL> grant create session to ggs;复制
复制
(2)创建表权限;
SQL> grant create table to ggs;复制
复制
(3)没有限制的表空间;
SQL> grant unlimited tablespace to ggs;复制
复制
(4)如果对权限要求不是很严格的话,直接赋予管理员权限;
SQL> grant dba to ggs;复制
复制
2、收回权限
语法如下:
REVOKE CONNECT, RESOURCE FROM 用户名;REVOKE SELECT ON 表名 FROM 用户名;REVOKE SELECT, INSERT, DELETE ON表名 FROM 用户名1, 用户名2复制
--收回查询表的权限复制
复制
revoke select on demo from ggs;revoke all on demo from ggs;复制
复制
--查询一个用户拥有的对象权限复制
select table_name,privilege from dba_tab_privs where grantee='ggs';复制
复制
--查询一个用户拥有的系统权限复制
select * from dba_sys_privs where grantee='ggs';复制
复制
--当前会话有效的系统权限复制
SQL> select * from session_privs;PRIVILEGE--------------------------------------------------------------------------------ALTER SYSTEMAUDIT SYSTEMCREATE SESSIONALTER SESSIONRESTRICTED SESSIONCREATE TABLESPACEALTER TABLESPACEMANAGE TABLESPACEDROP TABLESPACEUNLIMITED TABLESPACECREATE USERBECOME USERALTER USERDROP USERCREATE ROLLBACK SEGMENTALTER ROLLBACK SEGMENTDROP ROLLBACK SEGMENTCREATE TABLECREATE ANY TABLEALTER ANY TABLEBACKUP ANY TABLEDROP ANY TABLELOCK ANY TABLECOMMENT ANY TABLESELECT ANY TABLEINSERT ANY TABLEUPDATE ANY TABLEDELETE ANY TABLECREATE CLUSTERCREATE ANY CLUSTERALTER ANY CLUSTERDROP ANY CLUSTERCREATE ANY INDEXALTER ANY INDEXDROP ANY INDEXCREATE SYNONYMCREATE ANY SYNONYMDROP ANY SYNONYMCREATE PUBLIC SYNONYMDROP PUBLIC SYNONYMCREATE VIEWCREATE ANY VIEWDROP ANY VIEWCREATE SEQUENCECREATE ANY SEQUENCEALTER ANY SEQUENCEDROP ANY SEQUENCESELECT ANY SEQUENCECREATE DATABASE LINKCREATE PUBLIC DATABASE LINKDROP PUBLIC DATABASE LINKCREATE ROLEDROP ANY ROLEGRANT ANY ROLEALTER ANY ROLEAUDIT ANYALTER DATABASEFORCE TRANSACTIONFORCE ANY TRANSACTIONCREATE PROCEDURECREATE ANY PROCEDUREALTER ANY PROCEDUREDROP ANY PROCEDUREEXECUTE ANY PROCEDURECREATE TRIGGERCREATE ANY TRIGGERALTER ANY TRIGGERDROP ANY TRIGGERCREATE PROFILEALTER PROFILEDROP PROFILEALTER RESOURCE COSTANALYZE ANYGRANT ANY PRIVILEGECREATE MATERIALIZED VIEWCREATE ANY MATERIALIZED VIEWALTER ANY MATERIALIZED VIEWDROP ANY MATERIALIZED VIEWCREATE ANY DIRECTORYDROP ANY DIRECTORYCREATE TYPECREATE ANY TYPEALTER ANY TYPEDROP ANY TYPEEXECUTE ANY TYPEUNDER ANY TYPECREATE LIBRARYCREATE ANY LIBRARYALTER ANY LIBRARYDROP ANY LIBRARYEXECUTE ANY LIBRARYCREATE OPERATORCREATE ANY OPERATORALTER ANY OPERATORDROP ANY OPERATOREXECUTE ANY OPERATORCREATE INDEXTYPECREATE ANY INDEXTYPEALTER ANY INDEXTYPEDROP ANY INDEXTYPEUNDER ANY VIEWQUERY REWRITEGLOBAL QUERY REWRITEEXECUTE ANY INDEXTYPEUNDER ANY TABLECREATE DIMENSIONCREATE ANY DIMENSIONALTER ANY DIMENSIONDROP ANY DIMENSIONMANAGE ANY QUEUEENQUEUE ANY QUEUEDEQUEUE ANY QUEUECREATE ANY CONTEXTDROP ANY CONTEXTCREATE ANY OUTLINEALTER ANY OUTLINEDROP ANY OUTLINEADMINISTER RESOURCE MANAGERADMINISTER DATABASE TRIGGERMERGE ANY VIEWON COMMIT REFRESHRESUMABLESELECT ANY DICTIONARYDEBUG CONNECT SESSIONDEBUG ANY PROCEDUREFLASHBACK ANY TABLEGRANT ANY OBJECT PRIVILEGECREATE EVALUATION CONTEXTCREATE ANY EVALUATION CONTEXTALTER ANY EVALUATION CONTEXTDROP ANY EVALUATION CONTEXTEXECUTE ANY EVALUATION CONTEXTCREATE RULE SETCREATE ANY RULE SETALTER ANY RULE SETDROP ANY RULE SETEXECUTE ANY RULE SETEXPORT FULL DATABASEIMPORT FULL DATABASECREATE RULECREATE ANY RULEALTER ANY RULEDROP ANY RULEEXECUTE ANY RULEANALYZE ANY DICTIONARYADVISORCREATE JOBCREATE ANY JOBEXECUTE ANY PROGRAMEXECUTE ANY CLASSMANAGE SCHEDULERSELECT ANY TRANSACTIONDROP ANY SQL PROFILEALTER ANY SQL PROFILEADMINISTER SQL TUNING SETADMINISTER ANY SQL TUNING SETCREATE ANY SQL PROFILEMANAGE FILE GROUPMANAGE ANY FILE GROUPREAD ANY FILE GROUPCHANGE NOTIFICATIONCREATE EXTERNAL JOBCREATE ANY EDITIONDROP ANY EDITIONALTER ANY EDITIONCREATE ASSEMBLYCREATE ANY ASSEMBLYALTER ANY ASSEMBLYDROP ANY ASSEMBLYEXECUTE ANY ASSEMBLYEXECUTE ASSEMBLYCREATE MINING MODELCREATE ANY MINING MODELDROP ANY MINING MODELSELECT ANY MINING MODELALTER ANY MINING MODELCOMMENT ANY MINING MODELCREATE ANY CUBEFLASHBACK ARCHIVE ADMINISTE复制
复制
2.3. 密码验证函数
密码函数的作用就是要将用户密码进行限制,比如申请一个网站的账号的时候,密码会要求你不少于8位,必须要有一个大小写,字符,或者英文加上数字才可以,这些都是可以对create user的密码进行限制的,首先要接触一个profile的参数,之前没接触过这个,profile的作用就是对一些CPU的资源,或者用户密码进行限制的。
oracle 用户管理 :profile + tablespace + role + user
Oracle系统中的profile可以用来对用户所能使用的数据库资源进行限制,使用Create Profile命令创建一个Profile,用它来实现对数据库资源的限制使用,如果把该profile分配给用户,则该用户所能使用的数据库资源都在该profile的限制之内。
profile文件可以控制:CPU的时间 、I/O的使用 、IDLE TIME(空闲时间) 、CONNECT TIME(连接时间) 、并发会话数量 、口令机制。
1.查看oracle提供的密码函数脚本
[oracle@wyj admin]$ cat utlpwdmg.sql 可以查看oracle提供的密码函数脚本-- This script alters the default parameters for Password Management-- This means that all the users on the system have Password Management-- enabled and set to the following values unless another profile is-- created with parameter values set to different value or UNLIMITED-- is created and assigned to the user.-- Enable this if you want older version of the Password Profile parameters-- ALTER PROFILE DEFAULT LIMIT-- PASSWORD_LIFE_TIME 60-- PASSWORD_GRACE_TIME 10-- PASSWORD_REUSE_TIME 1800-- PASSWORD_REUSE_MAX UNLIMITED-- FAILED_LOGIN_ATTEMPTS 3-- PASSWORD_LOCK_TIME 1/1440复制
2、执行脚本
2.4. 用户profile
创建profile脚本
复制
DROP PROFILE PROFILEUSER CASCADE;CREATE PROFILE PROFILEUSER LIMITSESSIONS_PER_USER UNLIMITEDCPU_PER_SESSION UNLIMITEDCPU_PER_CALL UNLIMITEDCONNECT_TIME UNLIMITEDIDLE_TIME UNLIMITEDLOGICAL_READS_PER_SESSION UNLIMITEDLOGICAL_READS_PER_CALL UNLIMITEDCOMPOSITE_LIMIT UNLIMITEDPRIVATE_SGA UNLIMITEDFAILED_LOGIN_ATTEMPTS UNLIMITEDPASSWORD_LIFE_TIME UNLIMITEDPASSWORD_REUSE_TIME UNLIMITEDPASSWORD_REUSE_MAX UNLIMITEDPASSWORD_LOCK_TIME UNLIMITEDPASSWORD_GRACE_TIME UNLIMITEDPASSWORD_VERIFY_FUNCTION VERIFY_FUNCTION_11G;复制
复制
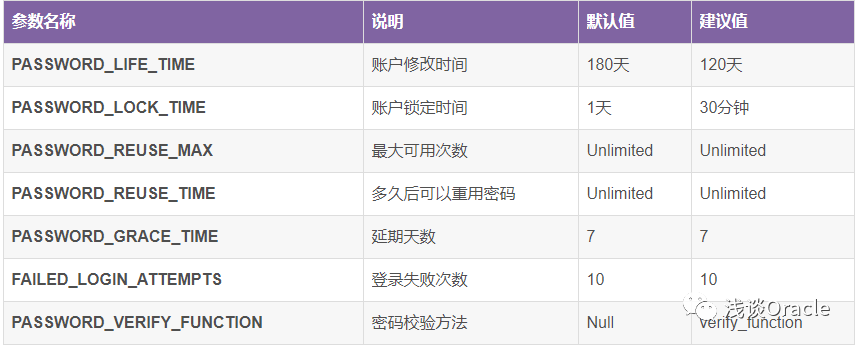
profile常见参数如下图:
2.5. 11G中关于用户密码的新特性
1、密码大小写敏感
从oracle 11gR1开始,数据库中的密码是大小写敏感的。密码大小写敏感是由sec_case_sensitive_logon参数控制的。
复制
SQL> show parameter sec_case_sensitive_logonNAME TYPE VALUE------------------------------------ ---------- -------sec_case_sensitive_logon boolean TRUE复制
复制
可见当前数据库是启用该新特性的。建议启用该新特性,以增强密码的安全性。
2、密码延迟验证
(1)等待用户输入密码的时间,随着输入错误密码的次数而不断延长。以此缓解暴力破解Oracle用户密码。
(2)密码延迟验证潜在风险
修改用户密码引发大量Library Cache Lock 数据库密码应该是定时修改,以提高数据库安全性,防止黑客攻击。但是, 大部署大量程序的业务 系统里,难免会有遗漏的情况。在修改完密码后,数据库会出现大量的Library Cache Lock等待事件。在MOS 上有说明:High 'library cache lock' Wait Time Due to Invalid Login Attempts(1309738.1)
BUG 用户登录数据库,哪怕正常登录,每次登录的时间都在延长。
(3)该特性编号: 28401 . 如果遇到这里描述的问题,将该特性关闭(临时或者永久)。
ALTER SYSTEM SET EVENT = '28401 TRACE NAME CONTEXT FOREVER, LEVEL 1' SCOPE = SPFILE;复制
复制
2.6. 11G中默认角色权限的差异
10g | 11g | 12c | |
CONNECT | ALTER SESSION, CREATE CLUSTER, | CREATE SESSION | CREATE SESSION |
resource | CREATE CLUSTER, CREATE INDEXTYPE, | CREATE CLUSTER, CREATE INDEXTYPE, | CREATE CLUSTER, CREATE INDEXTYPE, |
DBA | All system privileges WITH ADMIN OPTION | all system privileges that were created with the ADMIN option. | Provides a large number of system privileges, |
EXP_FULL | Provides the privileges required to | Provides the privileges required to | SELECT ANY TABLE, BACKUP ANY TABLE, |
IMP_FULL | Provides the privileges required to | Provides the privileges required to | Provides the privileges required |
DELETE_ | Provides DELETE privilege on the system audit table (AUD$) | Provides the DELETE privilege | Provides the DELETE privilege |
EXECUTE_ | Provides EXECUTE privilege on objects in the data dictionary. Also, HS_ADMIN_ROLE. | Provides EXECUTE privileges | Provides EXECUTE privileges |
SELECT_ | Provides SELECT privilege on objects in the data dictionary. Also, HS_ADMIN_ROLE. | Provides SELECT privilege | Provides SELECT privilege |
RECOVERY_ | CREATE SESSION, ALTER SESSION, CREATE SYNONYM, CREATE VIEW, CREATE DATABASE LINK,CREATE TABLE, CREATE CLUSTER, CREATE SEQUENCE, CREATE TRIGGER, and CREATE PROCEDURE | CREATE SESSION, ALTER SESSION, | CREATE SESSION, ALTER SESSION, |
SCHEDULER | execute the procedures | execute the procedures of the DBMS_SCHEDULERpackage | |
GATHER_SYSTEM | Provides privileges to | Provides privileges | |
LOGSTDBY_ | Provides administrative privileges to manage the SQL Apply (logical standby database) environment. | Provides administrative privileges |
2.7. 与用户、权限、角色相关的动态性能视图和数据字典
1、dba_users,描述了数据库中所有的用户信息。
复制
SQL> desc dba_users;Name Null? Type名称 是否为空 类型----------------------------------------- -------- ----------------------------USERNAME NOT NULL VARCHAR2(30)USER_ID NOT NULL NUMBERPASSWORD VARCHAR2(30)ACCOUNT_STATUS NOT NULL VARCHAR2(32)LOCK_DATE DATEEXPIRY_DATE DATEDEFAULT_TABLESPACE NOT NULL VARCHAR2(30)TEMPORARY_TABLESPACE NOT NULL VARCHAR2(30)CREATED NOT NULL DATEPROFILE NOT NULL VARCHAR2(30)INITIAL_RSRC_CONSUMER_GROUP VARCHAR2(30)EXTERNAL_NAME VARCHAR2(4000)PASSWORD_VERSIONS VARCHAR2(8)EDITIONS_ENABLED VARCHAR2(1)AUTHENTICATION_TYPE VARCHAR2(8)复制
复制
2、查看所有用户;
复制
SQL> select username from dba_users;USERNAME------------------------------------------------------------MGMT_VIEWSYSSYSTEMDBSNMPSYSMANGGSOUTLNFLOWS_FILESMDSYSORDSYSEXFSYSWMSYSAPPQOSSYSAPEX_030200OWBSYS_AUDITORDDATACTXSYSANONYMOUSXDBORDPLUGINSOWBSYSSI_INFORMTN_SCHEMAOLAPSYSSCOTTORACLE_OCMXS$NULLBIPMMDDATAIXSHDIPOEAPEX_PUBLIC_USERHRSPATIAL_CSW_ADMIN_USRSPATIAL_WFS_ADMIN_USR37 rows selected.复制
复制
注意:权限有两种:A、系统权限(dba_sys_privs );
B、对象权限。(dba_tab_privs )
3、查看权限: desc dba_sys_privs;desc dba_tab_privs;
复制
SQL> desc dba_sys_privs;Name Null? Type----------------- -------- ------------GRANTEE NOT NULL VARCHAR2(30)PRIVILEGE NOT NULL VARCHAR2(40)ADMIN_OPTION VARCHAR2(3)复制
复制
SQL> desc dba_tab_privs;Name Null? Type----------------- -------- ------------GRANTEE NOT NULL VARCHAR2(30)OWNER NOT NULL VARCHAR2(30)TABLE_NAME NOT NULL VARCHAR2(30)GRANTOR NOT NULL VARCHAR2(30)PRIVILEGE NOT NULL VARCHAR2(40)GRANTABLE VARCHAR2(3)HIERARCHY VARCHAR2(3)复制
复制
4、通过查询数据库字典视图 dba_role_privs 可以显示用户所具有的角色。
复制
SQL> desc dba_role_privs;Name Null? Type----------------- -------- ------------GRANTEE VARCHAR2(30)GRANTED_ROLE NOT NULL VARCHAR2(30)ADMIN_OPTION VARCHAR2(3)DEFAULT_ROLE VARCHAR2(3)复制
复制
##查看GGS用户所具有的的角色复制
复制
SQL> select * from dba_role_privs where GRANTEE='GGS';GRANTEE GRANTED_ROLE ADMIN_ DEFAUL------------------------------------------------------------ ---------------------------------- ------ ------GGS DBA NO YESGGS RESOURCE NO YESGGS CONNECT NO YES复制
5、role_role_privs ,描述授予角色的系统权限。只提供关于用户有权访问的角色的信息。
复制
SQL> desc role_role_privs;Name Null? Type----------------------------------------------------- -------- ------------------------------------ROLE NOT NULL VARCHAR2(30)GRANTED_ROLE NOT NULL VARCHAR2(30)ADMIN_OPTION VARCHAR2(3)复制
复制
6、V$PWFILE_USERS,列出密码文件中的所有用户,并表明该用户是否被授予SYSDBA、SYSOPER和syasm权限。
复制
SQL> desc V$PWFILE_USERS;Name Null? Type----------------------------------------------------- -------- ------------------------------------USERNAME VARCHAR2(30)SYSDBA VARCHAR2(5)SYSOPER VARCHAR2(5)SYSASM VARCHAR2(5)复制
7、DBA_COL_PRIVS,描述数据库中所有列对象授予的权限。
复制
SQL> desc DBA_COL_PRIVS;Name Null? Type----------------------------------------------------- -------- ------------------------------------GRANTEE NOT NULL VARCHAR2(30)OWNER NOT NULL VARCHAR2(30)TABLE_NAME NOT NULL VARCHAR2(30)COLUMN_NAME NOT NULL VARCHAR2(30)GRANTOR NOT NULL VARCHAR2(30)PRIVILEGE NOT NULL VARCHAR2(40)GRANTABLE VARCHAR2(3)复制
复制
3. 对象相关
3.1. 表相关
数据库开发步骤:
1) 创建表空间:默认使用的表空间: users, 表空间需要映射一个/多个数据文件
2) 创建用户: 绑定一个默认的表空间, 相当于这个用户创建的数据库对象(表...)都存在在绑定的这个表空间
3) 对用户进行授权, 撤销权限都必须使用系统管理员进行操作 --> DBA(数据库工程师)去执行的
4) 创建表: 存放数据
5) 进行数据添加;
6) 对数据查询,修改,删除 ;
3.1.1. 表的类型、创建方式
1、表的类型;
(1)堆表:heap table :数据存储时,行是无序的,对它的访问采用全表扫描。
复制
SQL> create table t_heap (object_id int primary key,object_name varchar2(60));Table created.##插数据SQL> insert into t_heap select object_id,object_name from dba_objects;86977 rows created.SQL> select * from t_heap where object_id<100;OBJECT_ID OBJECT_NAME---------- ------------------------------------------------------------------------------------------------------------------------2 C_OBJ#3 I_OBJ#4 TAB$5 CLU$6 C_TS#7 I_TS#8 C_FILE#_BLOCK#9 I_FILE#_BLOCK#10 C_USER#11 I_USER#12 FET$复制
复制
(2)分区表 (表>2G);
A、分区的目的
一般一张表超过2G的大小,ORACLE是推荐使用分区表的。
这张表主要是查询,而且可以按分区查询,只会修改当前最新分区的数据,对以前的不怎么做删除和修改。
数据量大时查询慢。
便于维护,可扩展:11g 中的分区表新特性:Partition(分区)一直是 Oracle 数据库引以为傲的一项技术,正是分区的存在让 Oracle 高效的处理海量数据成为可能,在 Oracle 11g 中,分区技术在易用性和可扩展性上再次得到了增强。
与普通表的 sql 一致,不需要因为普通表变分区表而修改我们的代码。
复制
--按年创建分区表SQL> create table test_part2 (3 ID NUMBER(20) not null,4 REMARK VARCHAR2(1000),5 create_time DATE6 )7 PARTITION BY RANGE (CREATE_TIME) INTERVAL (numtoyminterval(1, 'year'))8 (partition part_t01 values less than(to_date('2018-11-01', 'yyyy-mm-dd')));Table created.--创建主键SQL> alter table test_part add constraint test_part_pk primary key (ID) using INDEX;Table altered.-- Create/Recreate indexesSQL> create index test_part_create_time on TEST_PART (create_time);Index created.复制
(3)索引组织表(IOT);
复制
##创建索引组织表SQL> create table t_iot (object_id int primary key,object_name varchar2(60)) organization index;Table created.##插入数据SQL> insert into t_iot select object_id,object_name from dba_objects;86975 rows created.##查看SQL> select * from t_iot where object_id<100;OBJECT_ID OBJECT_NAME---------- ------------------------------------------------------------------------------------------------------------------------2 C_OBJ#3 I_OBJ#4 TAB$5 CLU$6 C_TS#7 I_TS#8 C_FILE#_BLOCK#9 I_FILE#_BLOCK#10 C_USER#11 I_USER#12 FET$13 UET$14 SEG$复制
复制
(4)簇表;
A、簇表的一些属性
簇键 cluster key
簇键是列或多列的组合,为簇表所共有。在创建簇表时指定簇键的列,以后在创建增加簇表中的每个表示,指定相同的列则可。每个簇键值在簇和簇索引中只存储1次,与不同表中有多少这样的行无关。
使用簇键的好处
减少磁盘I/O, 减少了因使用连接表所带来系统开销
节省了磁盘存储空间,因为原来要单独存放多张表,现在可以将连接的部分作为共享列存储。
什么情况下创建簇表?
对于经常查询,DML操作比较少的表
表中的记录经常被连接到其他表查询
创建簇表的步骤
创建簇表;
创建簇索引;
创建簇表的子表;
创建簇表时应考虑的问题
哪些表适用于创建簇表;
对于创建簇的表那些列用作簇列;
创建簇时Data Blocks的空间如何使用(pctfree, pctused);
平均簇键及所需相关行所需的空间大小;
簇索引的位置(比如存放到不同表空间);
预估簇的大小等。
复制
创建步骤为先建簇之后建簇索引,最后才建簇表##创建簇SQL> create cluster e_d_cluster2 (deptid number(2))3 size 10244 /Cluster created.这里首先创建了一个index cluster。这个cluster的key为 deptid,在table中这个列可以不命名为deptid,但数据类型number(2)必须匹配。Size选项是用来告诉oracle预计有1024字节数据和每个cluser key相关。Oracle将使用这个信息来计算每个block能容纳的最大cluster key数目。因此size太高,在每一block将得到很少的key,并且将使用比需要的更多的空间;设置容量太低,将得到过多的数据连接,这将偏离使用cluster的目的。Size是cluster的重要参数。#建cluster indexSQL> Cluster created.SP2-0734: unknown command beginning "Cluster cr..." - rest of line ignored.SQL> create index e_d_cluster_idx2 on cluster e_d_cluster3 /Index created.##建簇表SQL> create table department_cluster2 (deptid number(2) primary key,3 dname varchar2(14),4 loc varchar2(13))5 cluster e_d_cluster(deptid);Table created.##查看簇表desc SYS.department_clusterName Null? Type---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- -------- ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------DEPTID NOT NULL NUMBER(2)DNAME VARCHAR2(14)LOC VARCHAR2(13)复制
(5)临时表;临时表包含两种:
A、会话级临时表;
会话级的临时表因为这这个临时表中的数据和你的当前会话有关系,当你当前SESSION不退出的情况下,临时表中的数据就还存在,而当你退出当前SESSION的时候,临时表中的数据就全部没有了,当然这个时候你如果以另外一个SESSION登陆的时候是看不到另外一个SESSION中插入到临时表中的数据的。即两个不同的SESSION所插入的数据是互不相干的。当某一个SESSION退出之后临时表中的数据就被截断(truncate table,即数据清空)了。会话级的临时表创建方法:
复制
##创建方法Create Global Temporary Table Table_Name(Col1 Type1,Col2 Type2...) On Commit Preserve Rows;##例如SQL> create global temporary table Student2 (Stu_id Number(5),3 class_id Number(4),4 Stu_name Varchar(8))5 on Commit Preserve Rows;Table created.##查看SQL> desc ggs.studentName Null? Type----------------------------------------------------- -------- ------------------------------------STU_ID NUMBER(5)CLASS_ID NUMBER(4)STU_NAME VARCHAR2(8)复制
B、事务级临时表,事务级临时表是指该临时表与事务相关,当进行事务提交或者事务回滚的时候,临时表中的数据将自行被截断,其他的内容和会话级的临时表的一致(包括退出SESSION的时候,事务级的临时表也会被自动截断)。事务级临时表的创建方法:
复制
SQL> create global temporary table Student12 (Stu_id Number(5), class_id Number(4),Stu_name Varchar(8))3 on Commit Delete Rows;Table created.SQL> desc ggs.student1Name Null? Type----------------------------------------------------- -------- ------------------------------------STU_ID NUMBER(5)CLASS_ID NUMBER(4)STU_NAME VARCHAR2(8)复制
(6)压缩表,压缩表是用CPU来减少IO。(创建表的时候进行压缩,可以对创建完的表进行压缩)
SQL> create table t3 (tno number,tname varchar2(20),tsal varchar2(20)) compress;Table created.SQL> desc ggs.t3Name Null? Type----------------------------------------------------- -------- ------------------------------------TNO NUMBERTNAME VARCHAR2(20)TSAL VARCHAR2(20)复制
(7)嵌套表
嵌套表是表中之表。一个嵌套表是某些行的集合,它在主表中表示为其中的一列。对主表中的每一条记录,嵌套表可以包含多个行。在某种意义上,它是在一个表中存储一对多关系的一种方法。考查一个包含部门信息的表,在任何时间内每个部门会有很多项目正在实施。在一个严格的关系模型中,将需要建立两个独立的表department和project.
嵌套表允许在department表中存放关于项目的信息。勿需执行联合操作,就可以通过department表直接访问项目表中的记录。这种不经联合而直接选择数据的能力使得用户对数据访问更加容易。甚至在并没有定义方法来访问嵌套表的情况下,也能够很清楚地把部门和项目中的数据联系在一起。在严格的关系模型中,department和project两个表的联系需要通过外部关键字(外键)关系才能实现。
复制
##创建测试表SQL> create table dept2 (deptno NUMBER(2) PRIMARY KEY,3 dname VARCHAR2(14),4 loc VARCHAR2(13));Table created.SQL> CREATE TABLE emp2 (empno NUMBER(4) PRIMARY KEY,3 ename VARCHAR2(10),4 job VARCHAR2(9),5 mgr NUMBER(4) REFERENCES emp,6 hiredate DATE,7 sal NUMBER(7,2),8 comm NUMBER(7,2),9 deptno NUMBER(2) REFERENCES dept);Table created.SQL> INSERT INTO dept SELECT * FROM ggs.dept;0 rows created.SQL> INSERT INTO emp SELECT * FROM ggs.emp;0 rows created.##创建typeSQL> CREATE OR REPLACE TYPE emp_type AS OBJECT2 (empno NUMBER(4),3 ename VARCHAR2(10),4 job VARCHAR2(9),5 mgr NUMBER(4),6 hiredate DATE,7 sal NUMBER(7,2),8 comm NUMBER(7,2)9 );10 CREATE OR REPLACE TYPE emp_tab_type AS TABLE OF emp_type;##使用嵌套表CREATE TABLE dept_and_emp(deptno NUMBER(2) PRIMARY KEY,dname VARCHAR2(14),loc VARCHAR2(13),emps emp_tab_type)NESTED TABLE emps STORE AS emps_nest;复制
复制
2、创建方式
(1)、完全新建一张表;
语法格式如下:
create table 表名(复制
--列的定义复制
列名1 数据类型1 [约束],复制
列名2 数据类型2 [约束],复制
....复制
列名n 数据类型1 [约束]复制
);复制
复制
##例如SQL> CREATE TABLE t_student(2 stuNo CHAR(4),3 name VARCHAR2(20),4 age NUMBER(3),5 birthday DATE,6 sex VARCHAR2(5)7 );Table created.复制
(2)、在原有表的基础上新建一张表。
复制
Create table tableName as Selectto_date(sysdate,’yyyymmdd’) as exec_date,字段名1,字段名2,……From tableName2##例如SQL> create table t2 as select * from t1;Table created.SQL> create table t3 as select c1,c2,c3 from t1;Table created.复制
复制
3、修改表
(1)、增加新的一列
语法:alter table 表名 add 新的字段名 字段的类型;复制
#给学生表添加一个列 电话号码SQL> ALTER TABLE t_student ADD tel VARCHAR2(20);Table altered.复制
(2)、修改已存在的列复制
语法:alter table 表名 modify 字段的名 新的字段类型;复制
把电话号码 的数据类型修改为 varchar2(30)SQL> ALTER TABLE t_student MODIFY tel VARCHAR2(30);Table altered.复制
(3)、删除一列
语法:alter table 表名 drop column 字段名;复制
复制
把tel这个列删除SQL> ALTER TABLE t_student DROP COLUMN tel;Table altered.复制
(4)修改字段名
语法:alter table 表名 rename column 字段名 to 新的字段名;复制
把name 列名修改为snameSQL> ALTER TABLE t_student RENAME COLUMN name TO sname;Table altered.复制
(5)修改表名
语法:rename 表名 to 表名
把t_student的表名修改为tb_studentSQL> RENAME t_student TO tb_student;Table renamed.复制
(6)删除表
复制
语法:drop table 表名 [purge]purge 清除 加这个关键字, 表示这个删除了,不能找回来;没有加purge, 删除把这表添加到Oracle回收站, 可以找回--删除 DROP TABLE tb_student;--找回,从回收站还原回来 Flashback table tb_student to before drop;--永久删除,找不回 DROP TABLE tb_student purge;复制
复制
(7) truncate 删除
复制
语法:truncate table 表名;删除的是表格中所有数据,不删除表结构例如:truncate table tb_student;注意:truncate不能删除某一行,如果要删除某一行需要使用delete truncate table t_student;
复制
3.1.2. 分区表的类型、作用、使用场景
详见3.1.1表的类型(2)
3.1.3. 延迟段创建
延迟segment创建的意思是说:segment的空间分配是在插入记录的时候进行(注意不是commit的时候),在之前的数据库版本中,创建一个对象之后,会马上分配段和相应的extents。
复制
##创建表格,此时没有段和extentSQL> create table f_regs(reg_id number,reg_name varchar2(200));Table created.SQL> select count(*) from user_segments where segment_name='F_REGS';COUNT(*)----------0SQL> select count(*) from user_extents where segment_name='F_REGS';COUNT(*)----------0insert into f_regs values(1,'BRDSTN');1 row created. ##并没有执行commit##打开另一个session,发现段和extent已经有了,说明segment空间分配是在插入记录的时候进行。SQL> select count(*) from user_segments where segment_name='F_REGS';COUNT(*)----------1SQL> select count(*) from user_extents where segment_name='F_REGS';COUNT(*)----------1复制
3.1.4. 临时表的分类、创建语句、使用场景
详见3.1.1表的类型(5)
3.1.5. 高水位问题
1、高水位问题概述:在oracle里,使用delete删除数据以后,数据库的存储容量不会减少,而且使用delete删除某个表的数据以后,查询这张表的速度和删除之前一样,不会发生变化。
因为oralce有一个HWM高水位,它是oracle的一个表使用空间最高水位线。当插入了数据以后,高水位线就会上涨,但是如果你采用delete语句删除数据的话,数据虽然被删除了,但是高水位线却没有降低,还是你刚才删除数据以前那么高的水位。除非使用truncate删除数据。那么,这条高水位线在日常的增删操作中只会上涨,不会下跌,所以数据库容量也只会上升,不会下降。而使用select语句查询数据时,数据库会扫描高水位线以下的数据块,因为高水位线没有变化,所以扫描的时间不会减少,所以才会出现使用delete删除数据以后,查询的速度还是和delete以前一样。2、回收高水位的目的(1)、降低Oracle数据库中某些段(Segment)的高水位线,减少使用空间,从而避免不必要的表空间文件膨胀。(2)、提高表的扫描效率:由于Oracle的select语句会扫描高水位线以下的所有block,已分配而无数据的block过多时,必然会影响语句的执行效率。而降低高水位能提高这一效率。
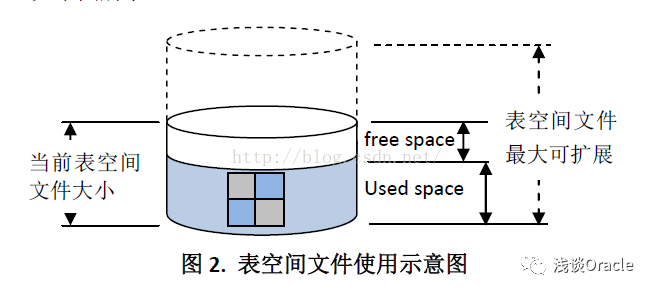
3、回收高水位方法(1)基本步骤:
操作前状态检查,供操作后比对;如下所示
复制
SQL> select sum(bytes)/1024/1024 "FREE_MB",tablespace_name from dba_free_space group by tablespace_name;FREE_MB TABLESPACE_NAME---------- ------------------------------------------------------------30.125 SYSAUX37.0625 UNDOTBS1.5625 USERS4.3125 SYSTEM28.25 EXAMPLESQL> select tablespace_name ,bytes/1024/1024 "USED_MB",maxbytes/1024/1024 "MAX_MB" from dba_data_files;TABLESPACE_NAME USED_MB MAX_MB------------------------------------------------------------ ---------- ----------USERS 5 32767.9844UNDOTBS1 60 32767.9844SYSAUX 540 32767.9844SYSTEM 770 32767.9844EXAMPLE 338.125 32767.9844复制
高水位回收操作;
操作后状态检查,与操作前状态比对。
(2)高水位回收方式
Oracle 10g开始采用了shrink技术
Shrink是通过事务的方式将数据行从一个数据块转移到另一个数据块。收缩过程中,表仍然可以进行DML操作
当然,事务要能够进行DML操作,还是需要等待收缩引起的事务锁释放。
收缩虽然是事务,但是数据并没有发生变化,因此不会引起触发器的触发。
使用shrink的前提条件
—表所在的表空间必须使用ASSM(自动段空间管理)
—在收缩表上必须启用row movement选项
复制
##开启行转移功能SQL> alter table t_student enable row movement ;Table altered.##压缩高水位线SQL> alter table t_student shrink space;Table altered.##回收后状态select BLOCKS,EMPTY_BLOCKS,NUM_ROWS from user_tables where table_name='t_student';复制
3、总结
(1).回收高水位操作shrink space可对高水位之下未储存数据的block加以回收,并降低高水位线。既能减少空间使用,又能提高查询效率,而对表内的数据、表上的索引没有影响。
(2).回收高水位操作shrink space是表和段级别的操作,能释放表空间文件内的空间,但不能缩小表空间文件的大小。
(3).回收操作是DDL操作而非DML操作,不由应用程序完成,需要管理员定期执行。
3.1.6. 与表相关的动态性能视图和数据字典
1、数据字典
是只读表和视图的集合,数据字典的所有者为sys用户。
用户只能在数据字典上执行查询操作(select语句),而其维护和修改是由系统自动完成的。
组成:数据字典基表和数据字典视图,其中基表存储数据库的基本信息,普通用户不能直接访问数据字典的基表;数据字典视图是基于数据字典基表所建立的视图,普通用户可以用过查询数据字典视图取得系统信息。
数据字典视图包括user_xxx、all_xxx、dba_xxx三中类型。
①user_tables:用于显示当前用户所拥有的所有表,它只返回用户所对应方案的所有表
eg:select table_name from user_tables;
SQL> select table_name from user_tables;TABLE_NAME------------------------------------------------------------STUDENTSTUDENT1F_REGSEMPDEPTT3T_STUDENT7 rows selected.复制
②all_tables:用于显示当前用户可以访问的所有表,它不仅返回当前用户方案的所有表,还会返回当前用户拥有访问其他权限的表
eg:select table_name from all_tables;
复制
SQL> select table_name from all_tables;TABLE_NAME------------------------------------------------------------XDB$NONCEKEYEPG$_AUTHORD_USAGE_RECSSI_IMAGE_FORMATS_TABSI_FEATURES_TABSI_VALUES_TABORDDCM_INTERNAL_TAGSORDDCM_DOC_TYPESORDDCM_INSTALL_DOCSORDDCM_DOCSORDDCM_DOC_REFSORDDCM_VR_DT_MAPORDDCM_STD_ATTRSORDDCM_PRV_ATTRSORDDCM_DICT_ATTRSORDDCM_CT_DAREFSORDDCM_MAPPING_DOCSORDDCM_MAPPED_PATHSORDDCM_ANON_RULE_TYPESORDDCM_ANON_ACTION_TYPESORDDCM_ANON_RULESORDDCM_ANON_ATTRS复制
③dba_tables:会显示所有方案拥有的数据库表。
但是查询这种数据库字典视图,要求用户必须是dba角色或是有select any table系统权限。(eg:当用户system用户查询数据字典视图dba_tables时,会返回system,sys,scott....方案所对应的数据库表)。
2、用户名、权限、角色
在建立用户时,oracle会把用户的信息存放到数据字典中,当给用户授予权限或是角色时,oracle会将权限和角色的信息存放到数据字典。
①查询dba_users可以显示所有数据库用户的详细信息;
复制
SQL> select t.username,t.password from dba_users t;USERNAME PASSWORD------------------------------------------------------------ ------------------------------------------------------------MGMT_VIEWSYSSYSTEMDBSNMPSYSMANGGSOUTLNFLOWS_FILESMDSYSORDSYSEXFSYSWMSYSAPPQOSSYSAPEX_030200OWBSYS_AUDITORDDATACTXSYSANONYMOUSXDBORDPLUGINSOWBSYSSI_INFORMTN_SCHEMAOLAPSYSSCOTTORACLE_OCMXS$NULLBIPMMDDATAIXSHDIPOEAPEX_PUBLIC_USERHRSPATIAL_CSW_ADMIN_USRSPATIAL_WFS_ADMIN_USR37 rows selected.复制
②查询数字字典视图dba_sys_privs可以显示用户所具有的系统权限;复制
SQL > select t.GRANTEE,t.privilege,t.ADMIN_OPTION from dba_sys_privs t;GRANTEE PRIVILIGE ADMIN_OPTION-------------------------------------------------------- ------------------------------------------------------------------------------ --------------------- CREATE ANY DIRECTORY NOSYSMAN CREATE PUBLIC SYNONYM NOAPEX_030200 UNLIMITED TABLESPACE YESAPEX_030200 CREATE PUBLIC SYNONYM NOAPEX_030200 DROP PUBLIC SYNONYM NOAPEX_030200 CREATE INDEXTYPE YESAPEX_030200 CREATE SYNONYM YESOWBSYS CREATE ANY CONTEXT NOOWBSYS ALTER SESSION YESOWBSYS CREATE SEQUENCE YESOWBSYS CREATE EXTERNAL JOB NOOWB$CLIENT ANALYZE ANY NOOWB$CLIENT CREATE DIMENSION NOSCOTT UNLIMITED TABLESPACE NOHR CREATE DATABASE LINK NOIX CREATE SEQUENCE NOIX CREATE OPERATOR NOSH CREATE SYNONYM NOBI ALTER SESSION NOBI UNLIMITED TABLESPACE NORESOURCE CREATE CLUSTER NORESOURCE CREATE PROCEDURE NORESOURCE CREATE TYPE NODBA CREATE ANY TABLE YESDBA CREATE ANY INDEX YESDBA CREATE ANY SEQUENCE YESDBA ALTER ANY ROLE YESDBA ANALYZE ANY YESDBA DROP ANY LIBRARY YESDBA CREATE ANY OPERATOR YESDBA CREATE INDEXTYPE YES复制
③查询数字字典视图dba_tab_privs可以显示用户所具有的对象权限;
④查询数据字典dba_col_privs可以显示用户具有的列权限;
⑤查询数据库字典视图dba_role_privs可以显示用户所具有的角色;(查询oracle中所有的角色,一般是dba:select * from dba_roles;)一般,Oracle数据库角色包含两种权限:系统权限和对象权限
(查询oracle中所有的系统权限,一般是dba:select * from system_privilege_map order by name;)
(查询oracle中所有对象权限,一般是dba:select distinct privilege from dba_tab_privs;)
(查询数据库的表空间:select tablespace_name from dba_tablespaces;)
3.2. 索引相关
3.2.1. 索引的类型、作用、创建语句、使用场景
1、索引的类型
1)位图索引(bitmap index)
假设数据库表中有一列其选择性非常窄,例如性别列,该用什么类型的索引?你可能会考虑对其使用位图索引。因为位图索引正是为相异值很少的列 而创建的。但需要考虑的因素还不只这些。一般而言,只有当你对表中值相宜度较小的多个不同的列都使用位图索引,这样位图索引才有用,因为你可以一起使用这 些索引才能对列产生更大的选择性,否则你还是需要对这些列进行一次全表扫描。例如,对于性别列,其索引只能有两个唯一值,那么用这个索引对表的任何搜索有 可能都返回一半的记录。其次,这些索引是为数据仓库而设计的,所以其假定条件是数据不会发生很大的改变。这些索引不能用来满足事务数据库或更新频繁的数据 库。应该说,对位图索引的表进行更新根本没有一点效率。
2)位图连接索引(bitmap join index)
位图连接索引比位图索引更进了一步。这些索引将位图化的列完全从表数据中抽取出来,并将其存储在索引中。其假定条件是这些列集合必须一起查 询。同样的,这也是为数据仓库数据库而设计的。除了在句法最后有一个WHERE子句之外,位图连接索引的创建指令就像创建位图索引的CREATE BITMAP INDEX一样。
3)压缩索引
压缩索引实际是标准b-tree索引的一个选项。压缩索引的叶节点更少,所以总的I/O数量和需要的缓存也更少。这些都意味着Oracle 的优化器更可能使用这些压缩索引,而不倾向于使用标准的非压缩索引。不过,这些好处也是有代价的,当你对这些压缩索引进行存取操作时,要消耗更多的CPU 来进行解压缩。而且,当你阅读关于优化器如何使用这些索引,又是如何选择合适的压缩级别的资料时,就开始变得晦涩了。不同的用户不同的设置从压缩索引中得 到的好处也可能会有所不同。
4)降序索引(descending index)
这是基于函数索引的一种特殊类型。降序索引可以显著优化ORDER BY x, y, z DESC子句查询的。
5)分区索引(partitioned index)
如果你的数据库中有一个分区表,你就有机会体验几种新的索引类型,从贯穿所有分区的全局分区索引(global)和集中于各个单独分区的本地分区索引(local)。这里不再进行赘述,想知道细节问题可以查询相关文献。
6)索引组织表(index organized table,IOT)
这是在Oracle 9i中引进的一种新类型表。Oracle会将级联索引及其扩展类型的索引用于表中所有的列。当所有数据都载入到索引结构之后,表就成多余的了,你尽可以将表本身删除掉。这就是索引组织表。
7)簇索引(cluster index)
基本上,簇索引就是将多个表的相同列放在一起,而对该列使用用一个簇索引。这种索引在实际应用中比较少,因为还有各种有待解决的性能问题存在。
8)域索引(domain index)
当我们创建为用户自定义数据类型(datatype)创建用户自定义索引类型(indextype)时就要使用域索引。
9)隐藏索引(invisible index)
这是Oracle 11g中推出的新特性。其创建过程和标准索引一样,但创建后对于基于代价的优化器(CBO)是不可见的。这可以让你对性能进行大型测试查询,而不会影响现有的正在运行的应用程序。
10)虚拟索引(virtual index)
这是为测试人员和开发人员准备的又一个工具。虚拟索引(不分配段空间)可以让你在不需要实际创建索引的情况下,测试新索引及其对查询计划的影响。对于GB级的表来说,构建索引非常耗费资源而且还要占用大量时间。
11)物理逻辑上的索引
逻辑上:
Single column 单行索引
Concatenated 多行索引
Unique 唯一索引
NonUnique 非唯一索引
Function-based函数索引
Domain 域索引
物理上:
Partitioned 分区索引
NonPartitioned 非分区索引
B-tree:
Normal 正常型B树
Rever Key 反转型B树
Bitmap 位图索引
2、作用
(1)若没有索引,搜索某个记录时(例如查找name=’wish’)需要搜索所有的记录,因为不能保证只有一个wish,必须全部搜索一遍;
(2)若在name上建立索引,oracle会对全表进行一次搜索,将每条记录的name值哪找升序排列,然后构建索引条目(name和rowid),存储到索引段中,查询name为wish时即可直接查找对应地方;
(3)创建了索引并不一定就会使用,oracle自动统计表的信息后,决定是否使用索引,表中数据很少时使用全表扫描速度已经很快,没有必要使用索引。
3、索引的创建
复制
##创建索引create index <index_name> on <table_name>(<column_name>) [tablespace<tablespace_name>];##重置索引alter index <index_name> rebuild;##删除索引drop index <index_name>##实例create table test asselect rownum as id,to_char(sysdate + rownum/24/3600,'yyyy-mm-dd hh24:mi:ss') as ttime,trunc(dbms_random.value(0,100)) as random_id,dbms_random.string('x',20) txtfrom dualconnect by level<=20000000;select count(id) from test;select * from test where txt='2W8U82V49FKZYK0JQETF';drop table test;复制
4、适用场景因不同索引的适用场景不同。
3.2.2. 如何监控索引的使用情况
a、单个索引监控
复制
-->演示环境SQL> select * from v$version where rownum<2;BANNER----------------------------------------------------------------------------------------------------------------------------------------------------------------Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production-->创建测试表SQL> create table tb_emp as select * from emp;Table created.-->为测试表创建索引SQL> create index i_tb_emp_empno on tb_emp(empno);Index created.-->收集统计信息SQL> exec dbms_stats.gather_table_stats('GGS','TB_EMP',cascade=>true);PL/SQL procedure successfully completed.-->查看索引信息SQL> @idx_infoEnter value for owner: ggsEnter value for table_name: tb_empTable Name INDEX_NAME CL_NAM CL_POS STATUS IDX_TYP DSCD------------------------- ------------------------------ -------------------- ------ -------- --------------- ----TB_EMP I_TB_EMP_EMPNO EMPNO 1 VALID NORMAL ASC-->查看索引使用情况-->此时use列为NO,表明索引未被使用到SQL> @idx_usage_tbEnter value for 1: tb_empEnter value for 2: allEnter value for 2: allTable Name INDEX_NAME USE START_MONITORING END_MONITORING------------------------- ------------------------------ --- ------------------- -------------------TB_EMP I_TB_EMP_EMPNO NO 02/19/2021 17:43:49-->实施即席查询SQL> select empno,ename,job from tb_emp where empno=7788;EMPNO ENAME JOB---------- ---------- ---------7788 SCOTT ANALYST-->再次查看时USE列已经为YESSQL> @idx_usage_tbEnter value for 1: tb_empEnter value for 2: allEnter value for 2: allTable Name INDEX_NAME USE START_MONITORING END_MONITORING------------------------- ------------------------------ --- ------------------- -------------------TB_EMP I_TB_EMP_EMPNO YES 02/19/2021 17:43:49-->禁用索引监控SQL> alter index I_TB_EMP_EMPNO nomonitoring usage;Index altered.b、schema级别的索引监控-->切换到另外一个数据库cnbo1SQL> conn goex_admin/xxxxx@cnbo1Connected.-->下面的查询表明没有表开启索引监控SQL> @idx_usage;no rows selected-->开启索引监控SQL> @idx_monitor_onINDEX_NAME MON USE START_MONITORING END_MONITORING------------------------------ --- --- ------------------- -------------------PK_AAH YES NO 02/19/2021 17:48:32IDX_GOAAE1 YES NO 02/19/2021 17:48:32PK_GOAAT YES NO 02/19/2021 17:48:32PK_GOAACTL YES NO 02/19/2021 17:48:32....... ................-->关闭索引监控SQL> @idx_monitor_offINDEX_NAME MON USE START_MONITORING END_MONITORING------------------------------ --- --- ------------------- -------------------PK_GOARL NO NO 03/19/2013 17:48:30 02/19/2021 17:50:02IDX_GOAQU1 NO NO 03/19/2013 17:48:30 02/19/2021 17:50:02IDX_GOAQU2 NO NO 03/19/2013 17:48:30 02/19/2021 17:50:02-->连接到原来的db,查看曾经开启索引监控的使用情况SQL> conn ggs/ggsConnected.SQL> @idx_usageEnter value for input_owner: GOEX_ADMINEnter value for input_owner: GOEX_ADMINOWNER INDEX_NAME Table Name MON USE START_MONITORING END_MONITORING--------------- ------------------------------ ------------------------- --- --- ------------------- ----------------GGS I_TB_EMP_EMPNO TB_EMP NO YES 02/19/2021 17:43:49 03/19/2013 17:46:04GOEX_ADMIN ACC_GRP_EXT_INFO_TBL_LOG_PK ACC_GRP_EXT_INFO_TBL_LOG YES YES 02/22/2021 15:58:42GOEX_ADMIN IDX_TDCL_CONTRACT_NUM TRADE_CLIENT_TBL YES YES 02/22/2021 15:58:42GOEX_ADMIN IDX_TDCL_SETTLED_DATE TRADE_CLIENT_TBL YES YES 02/22/2021 15:58:42GOEX_ADMIN IDX_TDCL_ACC_NUM TRADE_CLIENT_TBL YES YES 02/22/2021 15:58:41GOEX_ADMIN IDX_TDCL_INSTRU_ID TRADE_CLIENT_TBL YES YES 02/22/2021 15:58:42复制
3.2.3. 如何重建索引?什么情况下重建索引?复制
1、重建索引的情况
(1)、表上频繁发生update,delete操作;
(2)、表上发生了alter table ..move操作(move操作导致了rowid变化)。
2、重建索引
复制
##分析索引SQL> Analyze index i_tb_emp_empno validate structure;##说明:当查询出来的 height>=4 或者 DEL_LF_ROWS/LF_ROWS>0.2 的场合,该索引考虑重建 。##重建索引的方式1、drop 原来的索引,然后再创建索引;举例:删除索引:drop index IX_PM_USERGROUP;创建索引:create index IX_PM_USERGROUP on T_PM_USER (fgroupid);说明:此方式耗时间,无法在24*7环境中实现,不建议使用。2 、直接重建:举例:alter index indexname rebuild; 或alter index indexname rebuild online;说明:此方式比较快,可以在24*7环境中实现,建议使用此方式。复制
复制
3.3. dblink
3.3.1. 创建dblink的方法:
结合平日的经验,现总结几种创建dblink的方法:
1、最常用的方法:
复制
SQL> create database link dblink_120;Database link created.connect to ggs identified by “ggs”using '(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.213.120)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = bond)))’;复制
复制
2、利用tns的方法:
首先我们在服务端添加tns,注意这里一定是目标库服务端的tnsnames.ora下面添加,不是在客户端的tnsnames.ora下添加,否则会报错。
复制
db_110 =(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = orcl)(PORT = 1521))(CONNECT_DATA =(SERVER = DEDICATED)(ERVICE_NAME = orcl)))db_120 =(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.213.120)(PORT = 1521))(CONNECT_DATA =(SERVER = DEDICATED)(SERVICE_NAME = bond)))然后再创建dblink:3、 利用host:port/sid的方式:create database link dblink_120 connect to ggs identified by “ggs” using ‘192.168.213.110:1521/bond’;删除dblink方法:SQL> drop database link dblink_120;Database link dropped.复制
3.3.2. 分布式事务了解
1、不管是CBO(基于成本,或者讲统计信息)还是RBO(基于规则),如果SQL中涉及的表都是远端的,那么该语句在远端执行,在得到结果后返回调用端。2、无论是CBO还是RBO,当查询包含了本地表和远端表时,oracle总是先把远端表的数据通过网络传送到SQL的发起端,再跟本地表进行关联得到最终结果。3、可以通过driving_site这个hint来执行SQL在那端执行。这个hints在某些特定条件下的分布式查询调优非常有用。
3.3.3ORA-19706错误和_external_scn_rejection_threshold_hours参数了解
复制
$oerr ora 1970619706, 00000, "invalid SCN"// *Cause: The input SCN is either not a positive integer or too large.// *Action: Check the input SCN and make sure it is a valid SCN.复制
1、SCN的意思:SCN是当Oracle数据库更新后,由DBMS自动维护去累积递增的一个数字。在Oracle内部,SCN分为两部分存储,分别称之为scn wrap和scn base。SCN长度为48位,即它其实就是一个48位的整数。那么SCN这个48位长的整数,最大就是 2^48(2的48次方, 281万亿,281474976710656),这是很大的一个数字了。据推算这个值可以保证Oracle数据库理论上可以处理500年的数据。
(1)Maximum Reasonable SCN:在当前时间点,SCN最大允许达到的SCN值被称为" Maximum Reasonable SCN“(最大合理SCN),也称为Reasonable SCN Limit,简称RSL。这个值是一个限制,避免数据库的SCN无限制地增大,甚至达到了SCN的最大值。
(2)SCN Headroom:这个是指Maximum Reasonable SCN与当前数据库SCN的差值。在alert中通常是以“天”为单位,这个只是为了容易让人读而已。天数=(Maximum Reasonable SCN-Current SCN)/16384/3600/24。这个值就的意思就是,如果按SCN的每大增长速率,多少天会到达Maximum Reasonable SCN。但实际上即使如此,也不会到达Maximum Reasonable SCN,因为到那时Maximum Reasonable SCN也增大了(越时间增大),要到达Maximum Reasonable SCN,得必须以SCN最大可能速率的2倍才行。
2、SCN的异常增长几种类型
(1):数据库内部BUG触发,
(2):人为调整导致SCN异常增长过大,比如数据库通过特殊手段强制打开,手工把SCN递增得很大。
(3):通过db link传播。如果A库通过db link连接到B库,如果A库的SCN高于B库的SCN,那么B库就会递增SCN到跟A库一样,反之如果A库的SCN低于B库的SCN,那么A库的SCN 会递增到跟B库的SCN一样。也就是说,涉及到db link进行操作的多个库,它们会将SCN同步到这些库中的最大的SCN。
注意:从客户场景的实际情况来看,属于第3种类型导致SCN异常增长。B库的SCN值要高于A库的SCN,因此要将B库的SCN增同步到A库,但是如果B库的SCN过高,这样同步到A库之后, 使得A库面临Headroom过小的风险,那么A库会拒绝同步SCN,这个时候就会报ORA-19706: Invalid SCN错误。
3、解决办法
解决方法,如果A数据库版本低于11.2.0.4,需要给数据库打补丁,或直接升级至11.2.0.4及以上版本。然后修改隐含参数_external_scn_rejection_threshold_hours,此参数的含义为:当前库达到最大合理scn至少需要多少个小时,默认值为24,最小可调整至1。--修改增长到最大合理scn的最小时间SQL> alter system set "_external_scn_rejection_threshold_hours" = 122 comment='set threshold on 2015/09/01 - See MOS Document 1393363.1'3 scope=spfile;System altered.--重启数据库--查询修改是否成功select x.ksppinm name, y.ksppstvl value, x.ksppdesc describfrom sys.x$ksppi x, sys.x$ksppcv ywhere x.inst_id = userenv('instance')and y.inst_id = userenv('instance')and x.indx = y.indxand x.ksppinm like '%_external_scn_rejection_threshold_hours%';复制
3.3.4. 与dblink相关的动态性能视图和数据字典
1、V$FIXED_TABLE,用于列出所有可用的动态性能视图和动态性能表。
复制
SQL> desc V$FIXED_TABLEName Null? Type----------------------------------------- -------- ----------------------------NAME VARCHAR2(30)OBJECT_ID NUMBERTYPE VARCHAR2(5)TABLE_NUM NUMBER复制
复制
2、查看DBLINK
1* select * from dba_db_linksOWNER DB_LINK USERNAME HOST CREATED------------------------------ ------------------------------ ------------------------------ ------------------------------ ------------------------------GGS DBLINK_120 04-FEB-21复制
复制
1、含义:物化视图是包括一个查询结果的数据库对象,它是远程数据的的本地副本,或者用来生成基于数据表求和的汇总表。物化视图存储基于远程表的数据,也可以称为快照(类似于MSSQL Server中的snapshot,静态快照)。对于复制,物化视图允许你在本地维护远程数据的副本,这些副本是只读的。如果你想修改本地副本,必须用高级复制的功能。当你想从一个表或视图中抽取数据时,你可以用从物化视图中抽取。对于数据仓库,创建的物化视图通常情况下是聚合视图,单一表聚合视图和连接视图。(这个是基于本地的基表或者视图的聚合)。
2、作用:
能够提高查询速度,这主要是因为物化视图存储了实际的数据,其次具有查询重写功能。最后,物化视图具有实体表,你也可以在上面建立索引,总之大体上当作一个表用就可以了。
简化了开发任务,意思是开发的人员有的时候,无需直接关注部分sql的性能,而通过dba的努力,使用查询重写来完成性能的提升。
减少了工作量,因为物化视图可以定义两种刷新方式:立即刷新,按需刷新。所谓按需刷新就是你自己手动刷新,或者是定时刷新;所谓立即刷新,即视图主表发生变化的时候,视图立即刷新内容。 你可以根据自己的设备情况,应用情况和需求来控制刷新的方式。
刷新量的灵活限制,你可以快速是刷新(只刷新变化的),也可以全刷新。看你的需要。
3.4.1. 物化视图的分类、创建方式
1、分类
(1)、包含聚集的物化视图;
(2)、只包含连接的物化视图;
(3)、嵌套物化视图。
注意:
按刷新方式分:FAST/COMPLETE/FORCE
按刷新时间的不同:ON DEMAND/ON COMMIT
按是否可更新:UPDATABLE/READ ONLY
按是否支持查询重写:ENABLE QUERY REWRITE/DISABLEQUERY REWRITE
2、创建方式
(1)、BUILD IMMEDIATE是在创建物化视图的时候就生成数据。
(2)、BUILD DEFERRED则在创建时不生成数据,以后根据需要再生成数据。
复制
创建物化视图需要的权限:SQL> grant create materialized view to ggs;Grant succeeded.在源表建立物化视图日志:SQL> create materialized view log on test_part with primary key;Materialized view log created.##with primary key; -- 指定为主键类型在目标数据库上创建MATERIALIZED VIEW:SQL> create materialized view mv_materialized_test refresh force on demand start with sysdate next2 to_date(concat(to_char(sysdate+1,'dd-mm-yyyy'),'10:25:00'),'dd-mm-yyyy hh24:mi:ss') as3 select * from test_part;Materialized view created.--这个物化视图在每天10:25进行刷新修改刷新时间:SQL> alter materialized view mv_materialized_test refresh force on demand start with sysdate2 next to_date(concat(to_char(sysdate+1,'dd-mm-yyyy'),' 23:00:00'),'dd-mm-yyyy hh24:mi:ss');Materialized view altered.或SQL> alter materialized view mv_materialized_test refresh force on demand start with sysdate2 next trunc(sysdate,'dd')+1+1/24;Materialized view altered.##-- 每天1点刷新删除物化视图及日志:drop materialized view log on test_part; --删除物化视图日志:drop materialized view mv_materialized_test; --删除物化视图复制
复制
3.4.2. 物化视图的维护
复制
#1、查看刷新组信息:SQL> r1* select rowner,rname,refgroup,job,next_date,interval,broken from dba_refreshROWNER RNAME REFGROUP JOB NEXT_DATE INTERVAL BR------------------------------ ------------------------------ ---------- ---------- ------------ ------------------------------ --GGS MV_MATERIALIZED_TEST 1 23 05-FEB-21 trunc(sysdate,'dd')+1+1/24 N##2、查看刷新组内包含哪些要刷新的物化视图:SQL> r1* select owner,name,rowner,rname,refgroup,job,next_date from dba_refresh_childrenOWNER NAME ROWNER RNAME REFGROUP JOB NEXT_DATE------------------------------ ------------------------------ ------------------------------ ------------------------------ ---------- ---------- ------------GGS MV_MATERIALIZED_TEST GGS MV_MATERIALIZED_TEST 1 23 05-FEB-21##3、查看都有哪些物化视图SQL> r1* select owner,mview_name,MASTER_LINK,REFRESH_METHOD,LAST_REFRESH_DATE from all_mviewsOWNER MVIEW_NAME MASTER_LINK REFRESH_METHOD LAST_REFRESH------------------------------ ------------------------------------------------------------ ------------------------------ ---------------- ------------SYSMAN MGMT_ECM_MD_ALL_TBL_COLUMNS FORCE 16-JAN-21SH FWEEK_PSCAT_SALES_MV FORCE 16-JAN-21SH CAL_MONTH_SALES_MV FORCE 16-JAN-21GGS MV_MATERIALIZED_TEST FORCE 04-FEB-21##4、查看job的信息SQL> select job,log_user,last_date,next_date,broken,interval,failures,what from dba_jobs where job=41;no rows selected复制
复制
3.4.3. 查询重写的使用
#将物化视图设置为enable query rewrite(默认为disable),并执行原查询语句,查看执行计划SQL> alter MATERIALIZED VIEW MV_MATERIALIZED_TEST enable query rewrite;Materialized view altered.SQL> alter system flush buffer_cache;System altered复制
4. 表空间
4.1. 表空间的类型、作用、创建语句
4.1.1、表空间的类型:
一、按数据文件的类型,分为:
大文件表空间(bigfile tablespace)此为10g新增功能 bigfile表空间只有一个数据文件。
小文件表空间(smallfile tablespace)此为创建时默认值 smallfile表空间最多可包含1024个数据文件,
大文件表空间的优点有:
1、在一个表空间里只有一个大的数据文件,以后不需要再去管理数据文件;
2、一个大的数据文件相当于1024个小的数据文件,这样一来,在一个块大小为32K时,整个数据库可以达到(4g*32K)128TB,不过在实际环境中还是要受到操作系统的影响;
3、使用一个大的数据文件可以代替多个小数据文件,这样对数据文件的管理就少多了;
4、当打开数据库,发生检查点,执行DBWR进程时使用大文件表空间会增强性能。
大文件表空间的的需要注意有:
1、要使用在ORACLE的ASM(自动存储管理)的存储空间或者分散(striping)存储的LVM中,或者RAID阵列上;
2、不要把大文件表空间建立在不能分散(striping)存储的系统上;
3、不要把大文件表空间建立在没有空间(剩余空间少)的磁盘组上;
4、建立大文件表空间时不推荐建立在不能扩展的存储空间里;
5、大文件表空间只支持本地管理表空间(LMT)和本地段空间管理(ASSM);
6、在临时表空间与回滚段表空间,只能用手动段空间管理;
7、自动扩展数据文件必须是起用的,而且最大文件大小必须是不限制;
8、系统表空间和系统辅助(SYSAUX)表空间不能使用大文件表空间;
9、每个表空间只能包含一个数据文件。如果试图添加新的文件,则会报告 ora-32771 错误;
10、在 bft 上存储的表的 rowid 和 smallfile 表空间上的 rowid 结构有些不同的。要正确得到 rowid 信息,dbms_rowid 包增加了一个新的参数 ts_type_in 来解决这个问题。参考这个范例:
sql> select dbms_rowid.rowid_block_number (rowid, bigfile) 2 from foo;dbms_rowid.rowid_block_number(rowid,bigfile)----------------------------------------------24复制
二、按管理方式,分为:
本地管理表空间(LMT)
数据字典管理表空间(DMT)
本地管理表空间:
一种比较先进的管理扩展(extent)的方式;
是用bitmap来管理表空间里的所有的extent;
当使用本地管理表空间时是使用6个块(从第三个到第八个)来标识整个表空间里的每一个扩展(extent);
其中的每一位(bit)来表示每个扩展的状态。1为已被分配,0为可被分配。
在本地管理表空间的方式里可以选择每个extent的大小是固定(Uniform)的或是自动的:在自动管理,系统一般是刚开始一个extent8个block,然后逐渐增加;固定大小为每个extent都是固定大小的,推荐使用。
字典管理表空间:这种方式是为了与之前版本兼容而提供的。不推荐使用。
10G里是不能创建字典管理表空间的,被强制推荐,只能倒入老版本中的字典管理表空间。
三、按使用类型,分为:
永久段表空间()
临时段表空间()
回滚段表空间()
永久表空间:
一般存储数据的表空间;
系统表空间,普通用户使用的表空间都为永久表空间;
永久表空间的状态有三种:读写,只读,脱机;
只有在永久表空间,才能配置ASSM管理模式;
可以设置记录日志模式。建立选yes,以便数据库出问题后进行恢复;
以设置为系统默认表空间。这样,创建用户时,没有指定默认表空间,就自动设置为系统默认表空间;
设置默认表空间的命令:
ALTER DATABASE DEFAULT TABLESPACE
四、在永久表空间中按存储内容方式,分为:
系统表空间(SYSTEM TABLESPACE)
系统辅助表空间(SYSAUX TABLESPACE)
非系统表空间
1. 决定数据库实体的空间分配
2. 设置数据库用户的空间份额
3. 控制数据库部分数据的可用性
4. 分布数据于不同的设备之间以改善性能
5. 备份和恢复数据。
4.1.3、创建表空间复制
SQL> create tablespace test_liqi logging datafile2 '/oracle/app/orcl/liqi.dbf'3 SIZE 100M4 AUTOEXTEND ON5 NEXT 32M MAXSIZE UNLIMITED6 EXTENT MANAGEMENT LOCAL;Tablespace created.复制
复制
4.2. undo表空间
复制
#创建undo表空间SQL> create undo tablespace logging datafile2 '/oracle/app/orcl/undo_liqi.dbf'3 size 100M4 AUTOEXTEND ON5 NEXT 80M MAXSIZE UNLIMITED6 EXTENT MANAGEMENT LOCAL;Tablespace created.复制
4.2.1. undo表空间的作用
--事物回滚:当事物执行失败或用户执行回滚操作(rollback)时,Oracle会利用保存在回退段中的信息将数据恢复到原来的值;
--数据库恢复:当数据库实例运行失败,在数据库重启恢复时,Oracle先利用重做日志文件的信息对数据库进行恢复(包括已提交和未提交的事务),再利用回滚段中的信息回滚未提交的事务;
--读一致性:当一个用户对数据进行修改时,会预先将其原始值保存到回退段中,这时,如果有其它用户访问该数据,则访问回退段中的信息,使当前用户未提交的修改其他用户无法看到,保证了数据的一致性;
--闪回查询:通过保留在回退段中的信息,用户可以查询某个数据在过去某个时刻的状态
4.2.2. undo表空间相关的参数
1、_UNDDO_RETENTION在事务提交或回滚之后,因为flashback或一致读的需求,还需要将对应的UNDO数据
保存在UNDO表空间中一段时间,这个时间就是由undo_retention来设置的。根据UNDDO_RETENTION可以继续将UNDO的inactive状态划分为EXPIRED,UNEXPIRED两类,
undo中超过undo_retention时间之外的inactive undo回滚区称为expired, 还处于
unod_retention时间之内的inactive undo回滚区称为unexpired .2、RETENTION GUARANTEE
UNDO_RETENTION不是说必须达到这个时间后才能被覆盖,而只是一个期望值,比如UNDO
表空间文件设置为非自动扩展,当一个大事务需要将undo中未使用的区域及过期的undo
区域都使用完了,而UNDO空间不能自动扩展,这时保证事务顺利运行优先级比较高,UNDO
中没有过期的回滚区也会被覆盖使用(从其中使用时间越早的开始),也就是说retention
设置的时间段内的UNDO非过期数据是没有保证的。10g开始提供参数RETENTION GUARANTEE
设置在tablespace的属性中,那么未过期的UNDO数据就不会再被覆盖掉了。但是设置属性
RETENTION GUARANTEE,UNDO空间不足时很可能造成事务失败,所以一般不会设置。3、_UNDO_AUTOTUNE
从10g开始,Oracle提供了UNDO自动优化功能,就是在UNDO表空间非自动增长的情况下,
Oracle会根据UNDO表空间的大小来调整UNDO RETENTION的大小,自动调整RETENTION就是
最大限度的利用当前UNDO表空间的可用空间,尽可能的保留最多的UNDO数据,以最大化的
减少类似ORA-01555 等错误发生。在这种情况下的UNDO RETENTION就基本没有用处了。默认情况下 _UNDO_AUTOTUNE =TRUE, 开启UNDO自动优化功能。经过优化的UNDO RETENTION
可以在V$UNDOSTAT的 TUNED_UNDORETENTION 中看到, 一般oracle每10分钟写一条unod表
空间使用情况记录到V$UNDOSTAT, 包括 TUNED_UNDORETENTION 。
4.2.3. ORA-01555的由来
ORA-01555 快照过旧,是数据库中很常见的一个错误,比如当我们的事务需要使用undo来构建CR块的时候,而此时对应的undo 已经不存在了, 这个时候就会报ORA-01555的错误。
1. 出现ORA-01555错误,通常有2种情况:
(1)SQL语句执行时间太长,或者UNDO表空间过小,或者事务量过大,或者过于频繁的提交,导致执行SQL过程中进行一致性读时,SQL执行后修改的前镜像(即UNDO数据)在UNDO表空间中已经被覆盖,不能构造一致性读块(CR blocks)。 这种情况最多。
(2)SQL语句执行过程中,访问到的块,在进行延迟块清除时,不能确定该块的事务提交时间与SQL执行开始时间的先后次序。 这种情况很少。
2. 第1种情况解决的办法:
(1)增加UNDO表空间大小
(2)增加undo_retention 时间,默认只有15分钟
(3)优化出错的SQL,减少查询的时间,首选方法
(4)避免频繁的提交.
4.2.4. undo表空间相关的动态性能视图、数据字典
| 数据字典 | 解释 |
| v$undostat | 包含所有undo表空间的统计信息,用于对undo表空间进行监控和调整。 通过该视图,可以估计当前undo表空间的大小,Oracle利用该视图完成对回退信息的自动管理,该视图数据是有最近4天内,每10分钟产生一条统计记录构成的。 |
| v$rollstat | 包含undo表空间中回退段的性能统计信息 |
| v$transaction | 包含事务所使用的回退段信息 |
| dba_undo_extents | 包含undo表空间中区的大小与状态信息 |
| dba_hist_undostat | 包含v$undostat的快照,主要是4天前的统计信息 |
SQL> desc v$undostatName Null? Type----------------------------------------- -------- ----------------------------BEGIN_TIME DATEEND_TIME DATEUNDOTSN NUMBERUNDOBLKS NUMBERTXNCOUNT NUMBERMAXQUERYLEN NUMBERMAXQUERYID VARCHAR2(13)MAXCONCURRENCY NUMBERUNXPSTEALCNT NUMBERUNXPBLKRELCNT NUMBERUNXPBLKREUCNT NUMBEREXPSTEALCNT NUMBEREXPBLKRELCNT NUMBEREXPBLKREUCNT NUMBERSSOLDERRCNT NUMBERNOSPACEERRCNT NUMBERACTIVEBLKS NUMBERUNEXPIREDBLKS NUMBEREXPIREDBLKS NUMBERTUNED_UNDORETENTION NUMBERSQL> desc v$rollstatName Null? Type----------------------------------------- -------- ----------------------------USN NUMBERLATCH NUMBEREXTENTS NUMBERRSSIZE NUMBERWRITES NUMBERXACTS NUMBERGETS NUMBERWAITS NUMBEROPTSIZE NUMBERHWMSIZE NUMBERSHRINKS NUMBERWRAPS NUMBEREXTENDS NUMBERAVESHRINK NUMBERAVEACTIVE NUMBERSTATUS VARCHAR2(15)CUREXT NUMBERCURBLK NUMBER复制
复制
4.3. temp表空间
临时表的创建如下复制
SQL> CREATE TEMPORARY TABLESPACE tmp_liqi2 TEMPFILE '/oracle/app/orcl/tmp_lq.dbf'3 size 100M4 AUTOEXTEND OFF;Tablespace created.复制
复制
4.3.1. temp表空间的作用
1、临时表空间用来管理数据库排序操作以及用于存储临时表、中间排序结果等临时对象,当ORACLE里需要用到SORT的时候,并且当PGA中sort_area_size大小不够时,将会把数据放入临时表空间里进行排序。像数据库中一些操作:CREATE INDEX、 ANALYZE、SELECT DISTINCT、ORDER BY、GROUP BY、 UNION ALL、 INTERSECT、MINUS、SORT-MERGE JOINS、HASH JOIN等都可能会用到临时表空间。当操作完成后,系统会自动清理临时表空间中的临时对象,自动释放临时段。这里的释放只是标记为空闲、可以重用,其实实质占用的磁盘空间并没有真正释放。这也是临时表空间有时会不断增大的原因。
2、临时表空间存储大规模排序操作(小规模排序操作会直接在RAM里完成,大规模排序才需要磁盘排序Disk Sort)和散列操作的中间结果.它跟永久表空间不同的地方在于它由临时数据文件(temporary files)组成的,而不是永久数据文件(datafiles)。临时表空间不会存储永久类型的对象,所以它不会也不需要备份。另外,对临时数据文件的操作不产生redo日志,不过会生成undo日志。
3、创建临时表空间或临时表空间添加临时数据文件时,即使临时数据文件很大,添加过程也相当快。这是因为ORACLE的临时数据文件是一类特殊的数据文件:稀疏文件(Sparse File),当临时表空间文件创建时,它只会写入文件头部和最后块信息(only writes to the header and last block of the file)。它的空间是延后分配的.这就是你创建临时表空间或给临时表空间添加数据文件飞快的原因。
4、另外,临时表空间是NOLOGGING模式以及它不保存永久类型对象,因此即使数据库损毁,做Recovery也不需要恢复Temporary Tablespace。
4.3.2. ORA-1652:问题处理
1、查看数据库的表空间的大小
SQL> r1* select file_name,file_id,bytes/1024/1024,status,autoextensible tmp_liqi from DBA_TEMP_FILESFILE_NAME FILE_ID BYTES/1024/1024 STATUS TMP_LI------------------------------ ---------- --------------- -------------- ------/oracle/app/orcl/temp01.dbf 1 20 ONLINE YES/oracle/app/orcl/tmp_lq.dbf 2 100 ONLINE NO复制
- 3、 V$SORT_SEGMENT:显示给定实例的每个排序段的信息,只有发生在临时表空间的操作才会更新该视图。这里不仅仅记载排序动作,只要在临时表空间操作就会记录;而排序发生在内存,也不会更新该视图的。
复制
2、通过文件大小初步判断出增长是否异常。然后具体看错误日志处理。
4.3.3. temp表空间相关的动态性能视图、数据字典
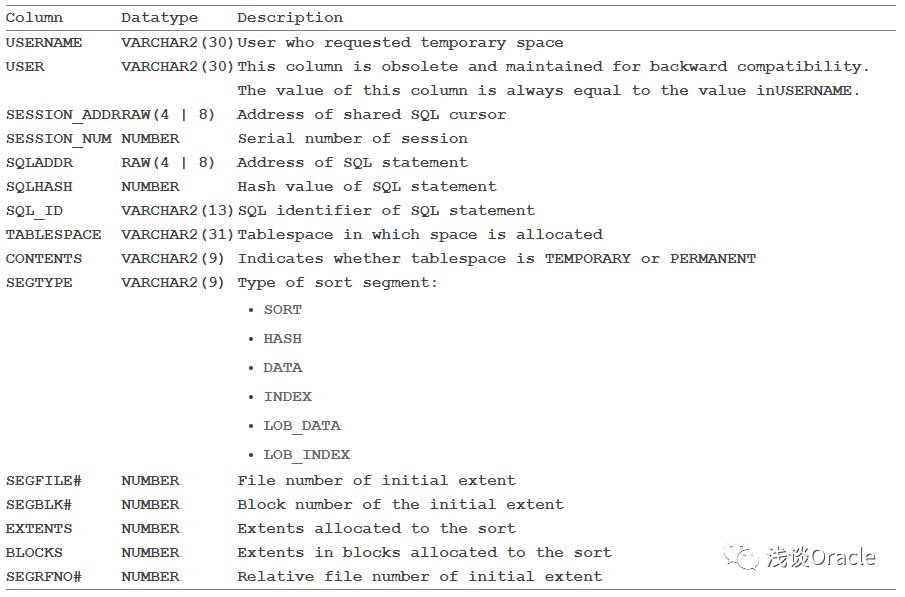
1、V$TEMPSEG_USAGE:显示了临时段的使用
2、DBA_TEMP_FREE_SPACE:描述了表空间级别的临时表空间使用的信息