




一、说明
在Java中默认都是用utf-8进行编码的,所以它的每个中文字符都是三字节,但char也能存中文,不过char只有两字节,它是怎么存的中文呢?
二、实验
首先我们用代码先验证几个事情
a) char只有两字节,但能存中文
b) 中文的utf-8编码是三字节
代码:
public class MyFirst { public static void main (String[] args) { charToInt(65535); charToInt(65536); charToInt(65537); char ch1 = '中'; System.out.println(ch1); String s1 = "中"; getStringBytes(s1); } static void charToInt(int num) { char c1 = (char) num; int i2 = (int) c1; System.out.println(i2); } static void getStringBytes (String s) { byte[] s1Bytes = s.getBytes(StandardCharsets.UTF_8); for (int i = 0; i < s1Bytes.length; i++) { System.out.println(("中的utf-8第" + (i + 1) + "位编码为:" + s1Bytes[i])); } } }复制
结果:
65535 0 1 中 中的utf-8第1位编码为:-28 中的utf-8第2位编码为:-72 中的utf-8第3位编码为:-83复制
可以看到当把一个int类型的数字传给char,然后再将这个char转为int类型,当数字大于65535的时候,结果就与传入的值不一样了。这是由于char实际是两字节的无符号整数,而两字节无符号的整数的最大值是2的16次方-1=65535,当传入的字节数大于两字节的时候,高比特位会丢弃。举例:65536(二进制为:10000000000000000),其中"1"在第17位,被丢弃,所以最后出来的值就是0。而从getStringBytes方法中可以看到一个汉字的确是三字节编码,那么char只有两字节是怎么存的汉字呢?
想要搞清楚char是怎么存的汉字,我们可以将程序改一下,直接打印这个char的整数值,以及String的16进制编码。
代码:
public class MyFirst { public static void main (String[] args) { char ch1 = '中'; System.out.println((int) ch1); System.out.println(Integer.toHexString(ch1)); String s1 = "中"; getHexStringBytes(s1); } static void getHexStringBytes (String s) { StringBuilder sb = new StringBuilder(); byte[] s1Bytes = s.getBytes(StandardCharsets.UTF_8); for (int i = 0; i < s1Bytes.length; i++) { sb.append(Integer.toHexString(s1Bytes[i]), 6, 8); } System.out.println(sb); } }复制
结果:
20013 4e2d e4b8ad复制
可以看到,"中"的char里面存的是整数20013,转成16进制为4e2d,而"中"用utf-8编码的16进制则是e4b8ad。那么有两个问题,这个4e2d是什么?4e2d又跟e4b8ad有什么联系呢?
查询unicode字符百科
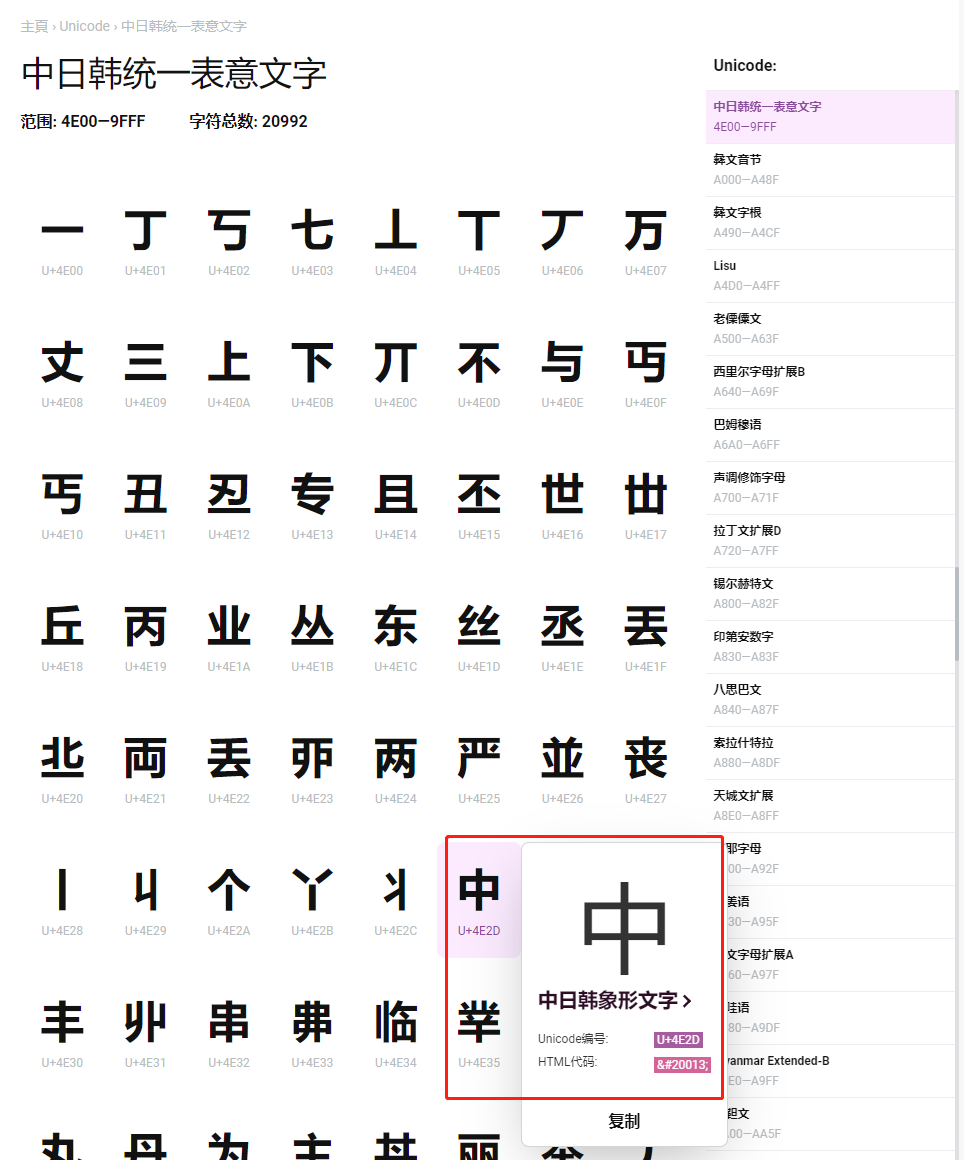
可以看到4e2d是汉字"中"的unicode编号,那么我们现在就弄懂第一个问题了,char中存的是unicode编号,从下图中也可以看到,目前各个国家的文字的unicode编号基本上都在FFFF以下,也就是两字节的char也足够表达所有国家的常用字符了。我们中文在4E00—9FFF之间。
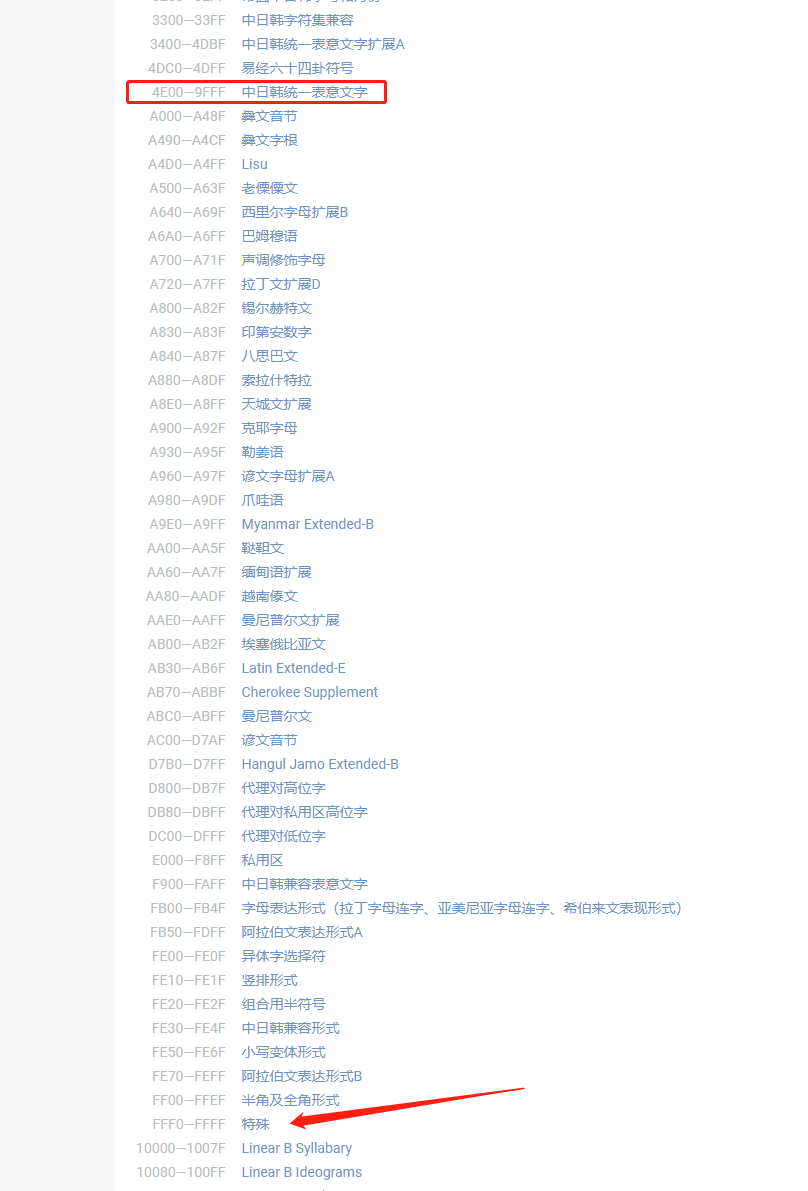
那么现在开始研究第二个问题,unicode编号跟utf-8编码有什么联系呢?通过百度百科我们查到utf-8的编码格式如下
| 字节 | 格式 | 实际编码位 | 码点范围 |
|---|---|---|---|
| 1字节 | 0xxxxxxx | 7 | 0 ~ 127 |
| 2字节 | 110xxxxx 10xxxxxx | 11 | 128 ~ 2047 |
| 3字节 | 1110xxxx 10xxxxxx 10xxxxxx | 16 | 2048 ~ 65535 |
| 4字节 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 21 | 65536 ~ 2097151 |
其中表格中xxx的部分就是unicode编号的二进制替换,还是拿"中"作例子,"中"的unicode编号是20013,也就是说它的码点范围是2048~65535,所以它采用三字节编码,其实我们前面提到过,中文在4E00—9FFF之间,对应的十进制是19968-40959,所以中文的utf-8编码全部都是三字节。
20013的二进制为:0100 1110 0010 1101,把这个二进制代入到1110xxxx 10xxxxxx 10xxxxxx中,将xxx替换,则是11100100 10111000 10101101,换成16进制则是:e4b8ad,正好就是"中"的utf-8编码。现在我们懂了只要我们知道了unicode编号,那么我们就能通过这个unicode编号转成对应的utf-8编码。
'中'的二进制 0100 111000 101101 三字节模板 1110xxxx 10xxxxxx 10xxxxxx ------------------------------------------------ 合并后的二进制 11100100 10111000 10101101 ------------------------------------------------ 转成16进制 e 4 b 8 a d复制
三、补充
- unicode编号并不等价于unicode编码,unicode编码并不是只有utf-8,只是我们最常用的是utf-8,所以本文仅讨论了utf-8。
- 另一中常用的编码格式gbk,中文编码是两字节。这个编码格式是我们国家自己定义的,跟unicode编号就一点关系都没有了。
