




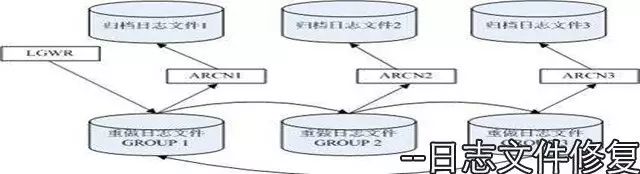
1. 状态为active日志组损坏
2. 状态为current日志组损坏(归档模式,有备份)
3.状态为current日志组损坏(非归档,无备份)
状态为active日志组损坏 先查看日志组的状态
SQL> select GROUP# ,SEQUENCE# ,MEMBERS, ARCHIVED , STATUS from v$log;
GROUP# SEQUENCE# MEMBERS ARC STATUS
---------- ---------- ---------- --- ----------------
1 9 2 NO CURRENT
2 8 2 YES ACTIVE 是active 表示该组的日志信息要用户实例恢复
3 6 2 YES INACTIVE
如果损坏的是active日志组
修复思路:
立即执行一次:alter system checkpoint ; #该命令只能在open状态下执行
将active状态转换为inactive
i. 转换成功:变为inactive 就去按照inactive的方法去修复
ii. 转换失败:只能做不完全恢复(日志记录数据丢失) 恢复到有日志的那一个时刻
修复案例
把第四组设置为活动组
SQL> select GROUP# ,SEQUENCE# ,MEMBERS, ARCHIVED , STATUS
from v$log;
GROUP# SEQUENCE# MEMBERS ARC STATUS
---------- ---------- ---------- --- ----------------
1 19 2 NO CURRENT
2 16 2 YES INACTIVE
3 17 3 YES ACTIVE
4 18 2 YES ACTIVE
模拟故障 删除active日志组的所有成会员
SQL> select member from v$logfile where group#=4;
MEMBER
---------------------------------------------
/u01/app/oracle/redo401.log
/u01/app/oracle/redo402.log
删除日志文件
rm -rf u01/app/oracle/redo401.log
rm -rf u01/app/oracle/redo402.log
假设知道日志组4故障
SQL> select GROUP# ,SEQUENCE# ,MEMBERS, ARCHIVED , STATUS
from v$log;
GROUP# SEQUENCE# MEMBERS ARC STATUS
---------- ---------- ---------- --- ----------------
1 9 2 YES ACTIVE
2 8 2 YES INACTIVE
3 11 2 NO CURRENT
4 10 2 YES ACTIVE 活动组
走active修复流程
alter system checkpoint;
SQL> select GROUP# ,SEQUENCE# ,MEMBERS, ARCHIVED , STATUS
from v$log;
GROUP# SEQUENCE# MEMBERS ARC STATUS
---------- ---------- ---------- --- ----------------
1 9 2 YES INACTIVE
2 8 2 YES INACTIVE
3 11 2 NO CURRENT
4 10 2 YES INACTIVE 变为inactive
SQL> alter database clear logfile group 4;
SQL> select GROUP# ,SEQUENCE# ,MEMBERS, ARCHIVED , STATUS
from v$log;
GROUP# SEQUENCE# MEMBERS ARC STATUS
---------- ---------- ---------- --- ----------------
1 9 2 YES INACTIVE
2 8 2 YES INACTIVE
3 11 2 NO CURRENT
4 0 2 YES UNUSED
SQL> alter system switch logfile ;
SQL> select GROUP# ,SEQUENCE# ,MEMBERS, ARCHIVED , STATUS
from v$log;
GROUP# SEQUENCE# MEMBERS ARC STATUS
---------- ---------- ---------- --- ----------------
1 9 2 YES INACTIVE
2 8 2 YES INACTIVE
3 11 2 YES ACTIVE
4 12 2 NO CURRENT

虚
状态current日志组损坏 当前日志组损坏,而且数据库实例宕掉
前提:归档模式,有备份
SQL> select GROUP# ,SEQUENCE# ,MEMBERS, ARCHIVED , STATUS
from v$log;
GROUP# SEQUENCE# MEMBERS ARC STATUS
---------- ---------- ---------- --- ----------------
1 19 2 YES ACTIVE
2 17 2 YES ACTIVE
3 18 2 YES ACTIVE
4 20 2 NO CURRENT
SQL> insert into scott.emp (empno,ename ,sal) values(3,'bob',1000);
SQL> insert into scott.emp (empno,ename ,sal) values(4,'jim',1000);
SQL> commit;
SQL> select empno ,ename ,sal from scott.emp ;
EMPNO ENAME SAL
---------- ---------- ----------
1 tom 1000
2 mary 1000
3 bob 1000 ----日志在日志组4
4 jim 1000
select GROUP# ,SEQUENCE# ,MEMBERS, ARCHIVED , STATUS
from v$log;
GROUP# SEQUENCE# MEMBERS ARC STATUS
---------- ---------- ---------- --- ----------------
1 19 2 YES ACTIVE
2 17 2 YES ACTIVE
3 18 2 YES ACTIVE
4 20 2 NO CURRENT 当前日志组还是4
删除当前日志组4的所有日志文件
SQL> select member from v$logfile where group#=4;
MEMBER
--------------------------------------------------------------------------------
/u01/app/oracle/redo401.log
/u01/app/oracle/redo402.log
SQL> shutdown immediate
rm -rf u01/app/oracle/redo401.log
rm -rf u01/app/oracle/redo402.log
启动数据库报错:
SQL> startup
ORA-00313: open failed for members of log group 4 of thread 1
ORA-00312: online log 4 thread 1: '/u01/app/oracle/redo402.log'
ORA-27037: unable to obtain file status
Linux-x86_64 Error: 2: No such file or directory
Additional information: 3
ORA-00312: online log 4 thread 1: '/u01/app/oracle/redo401.log'
ORA-27037: unable to obtain file status
Linux-x86_64 Error: 2: No such file or directory
Additional information: 3
启动数据库到mount
SQL> startup mount;
SQL> select status from v$instance;
STATUS
------------
MOUNTED
通过提示确定日志文件的问题:
cd u01/app/oracle/diag/rdbms/orcl/orcl/trace
vi alert_orcl.log
ORA-00313: open failed for members of log group 4 of thread
online log 4 thread 1: '/u01/app/oracle/redo402.log'
online log 4 thread 1: '/u01/app/oracle/redo401.log'
去看日志组的状态
SQL> select GROUP# ,SEQUENCE# ,MEMBERS, ARCHIVED , STATUS
from v$log;
GROUP# SEQUENCE# MEMBERS ARC STATUS
---------- ---------- ---------- --- ----------------
1 19 2 YES INACTIVE
4 22 2 NO CURRENT 2个成员,第四组当前组全挂 实例倒掉
3 17 3 YES INACTIVE
2 21 2 YES INACTIVE
alter system switch logfile #该命令只能在open下输入,切换日志失败
*
ERROR at line 1:
ORA-01109: database not open
SQL> alter database clear logfile group 4 ; #失败
alter database clear logfile group 4
*
ERROR at line 1:
ORA-01624: log 4 needed for crash recovery of instance orcl (thread 1)
ORA-00312: online log 4 thread 1: '/u01/app/oracle/red401.log'
ORA-00312: online log 4 thread 1: '/u01/app/oracle/red402.log'
#该日志的信息要用于实例恢复,必须在
SQL> alter database drop logfile group 4 ;
alter database drop logfile group 4
*
ERROR at line 1:
ORA-01623: log 4 is current log for instance orcl (thread 1) - cannot drop
ORA-00312: online log 4 thread 1: '/u01/app/oracle/redo401.log'
ORA-00312: online log 4 thread 1: '/u01/app/oracle/redo402.log'
结论:只能做不完全恢复
就是恢复数据库到有日志的地方
查看数据库现在还有日志结束点在哪里?
SQL> select GROUP#,SEQUENCE# , STATUS , ARCHIVED, FIRST_CHANGE#,NEXT_CHANGE# from v$log;
GROUP# SEQUENCE# STATUS ARC FIRST_CHANGE# NEXT_CHANGE#
---------- ---------- ---------------- --- ------------- ------------
1 19 INACTIVE YES 3848618 3848814
4 22 CURRENT NO 3850056 2.8147E+14
3 17 INACTIVE YES 3848597 3848600
2 21 INACTIVE YES 3849537 3850056
日志组4没有了 ,找日志组4之前 日志组是的序列是22 找序列21
可以恢复到序列21
可以恢复到scn 3850056
或者 recover database until cancel ; (自动搜寻可以用于恢复的日志,没有了结束)
$ rman target # 必须有备份
RMAN> restore database ;
操作:
$ sqlplus as sysdba
SQL> recover database until cancel ;
Media recovery complete.
SQL> alter database open resetlogs;
Database altered.
检查一下
SQL> select GROUP#,SEQUENCE# , STATUS , ARCHIVED, FIRST_CHANGE#,NEXT_CHANGE#
from v$log;
2
GROUP# SEQUENCE# STATUS ARC FIRST_CHANGE# NEXT_CHANGE#
---------- ---------- ---------------- --- ------------- ------------
1 1 CURRENT NO 1027005 2.8147E+14
2 0 UNUSED YES 0 0
3 0 UNUSED YES 0 0
4 0 UNUSED YES 0 0
检查备份后做的操作,也就是日志组4中记录的事务的操作,全部丢失
SQL> select empno ,ename ,sal from scott.emp ;
EMPNO ENAME SAL
---------- ---------- ----------
1 tom 1000
2 mary 1000
3 4都丢失了
证明:当前日志组丢失,则100%丢失数据!
建议做一次全备
delete backup ;
backup database ;
状态current日志组损坏 当前日志组损坏,而且数据库实例宕掉
非归档模式,没有备份
SQL> archive log list ;
Database log mode No Archive Mode
Automatic archival Disabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 4
Current log sequence 6
没有备份,没有归档.
1. 添加一个日志组
SQL> alter database add logfile group 4 ('/u01/app/oracle/redo401.log','/u01/app/oracle/redo402.log') size 50M;
SQL> select GROUP#, SEQUENCE# ,STATUS ,ARCHIVED from v$log;
GROUP# SEQUENCE# STATUS ARC
---------- ---------- ---------------- ---
1 4 INACTIVE NO
2 5 INACTIVE NO
3 6 CURRENT NO
4 0 UNUSED YES
2. 切换一次,为当前日志组
SQL> alter system switch logfile ;
SQL> select GROUP#, SEQUENCE# ,STATUS ,ARCHIVED from v$log;
GROUP# SEQUENCE# STATUS ARC
---------- ---------- ---------------- ---
1 4 INACTIVE NO
2 5 INACTIVE NO
3 6 ACTIVE NO
4 7 CURRENT NO
3. 执行DML 生成日志 写入日志组4
SQL> select count(*) from scott.emp ;
COUNT(*)
----------
14
SQL> delete from scott.emp ;
14 rows deleted.
SQL> commit;
SQL> select count(*) from scott.emp ;
COUNT(*)
----------
0
再次查看日志组
SQL> select GROUP#, SEQUENCE# ,STATUS ,ARCHIVED from v$log;
GROUP# SEQUENCE# STATUS ARC
---------- ---------- ---------------- ---
1 4 INACTIVE NO
2 5 INACTIVE NO
3 6 ACTIVE NO
4 7 CURRENT NO
4. 删除所有当期日志组成员
SQL> select member from v$logfile where group#=4;
MEMBER
--------------------------------------------------------------------------------
/u01/app/oracle/redo401.log
/u01/app/oracle/redo402.log
rm -rf u01/app/oracle/redo401.log
rm -rf u01/app/oracle/redo402.log
5. 强制关闭数据库
shutdown abort;
6. 启动数据库
SQL> startup
ORACLE instance started.
Total System Global Area 534462464 bytes
Fixed Size 2215064 bytes
Variable Size 369099624 bytes
Database Buffers 159383552 bytes
Redo Buffers 3764224 bytes
Database mounted.
ORA-00313: open failed for members of log group 4 of thread 1
ORA-00312: online log 4 thread 1: '/u01/app/oracle/redo402.log'
ORA-27037: unable to obtain file status
Linux-x86_64 Error: 2: No such file or directory
Additional information: 3
ORA-00312: online log 4 thread 1: '/u01/app/oracle/redo401.log'
ORA-27037: unable to obtain file status
Linux-x86_64 Error: 2: No such file or directory
Additional information: 3
log 4 thread 1: '/u01/app/oracle/redo401.log'
log 4 thread 1: '/u01/app/oracle/redo402.log'
两个日志文件 也就是第4组全部损坏
select GROUP#, SEQUENCE# ,STATUS ,ARCHIVED from v$log;
GROUP# SEQUENCE# STATUS ARC
---------- ---------- ---------------- ---
1 4 INACTIVE NO
4 7 CURRENT NO # 第4组是current状态
3 6 ACTIVE NO
2 5 INACTIVE NO
第4组是current状态,所以按照恢复流程要做不完恢复
该数据库是测试库,没有任何备份,不处于归档模式 ,不能做不完全恢复
7. 恢复
只有设置隐含参数强制启动数据库,启动后要用exp/imp把数据库全库导出,删除数据库,重建库,再导入。
强制恢复, 这种方法可能会导致数据不一致
SQL> alter system set "_allow_resetlogs_corruption" =true scope=spfile;
SQL> shutdown immediate;
ORACLE instance shut down.
SQL> startup mount;
ORACLE instance started.
Total System Global Area 534462464 bytes
Fixed Size 2215064 bytes
Variable Size 369099624 bytes
Database Buffers 159383552 bytes
Redo Buffers 3764224 bytes
Database mounted.
SQL> show parameter _allow
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
_allow_resetlogs_corruption boolean TRUE
用open resetlogs打开数据库
alter database open resetlogs
*
ERROR at line 1:
ORA-01139: RESETLOGS option only valid after an incomplete database recovery
recover database until cancel;
输入cancel
SQL> alter database open resetlogs; #执行该命令把数据库打开
select count(*) from scott.emp ;
COUNT(*)
----------
14 #刚才删除的事务的操作丢失了
只要current日志丢失,保存在current日志操作的数据库全部丢失 100%
总结:生产库,测试库都应该有备份策略。
可能遇到的故障:
alter database open resetlogs
*
ERROR at line 1:
ORA-00603: ORACLE server session terminated by fatal error
ORA-00604: error occurred at recursive SQL level 1
ORA-01115: IO error reading block from file (block # )
ORA-01110: data file 1: '+DATA/orcl/datafile/system.256.822001323'
ORA-15081: failed to submit an I/O operation to a disk
ORA-00604: error occurred at recursive SQL level 1
ORA-01115: IO error reading block from file (block # )
ORA-01110: data file 1: '+DATA/orcl/datafile/system.256.822001323'
ORA-15081: failed to submit an I/O operation to a disk
ORA-01092: ORACLE instance terminated. Disconnection forced
ORA-00600: internal error code, arguments: [2662], [0], [1020720], [0],
[1028485], [12583040], [], [], [], [], [], []
Process ID: 32494
Session ID: 1 Serial number: 5
这里主要看2点:
(1)使用了_allow_resetlogs_corruption 参数
(2)这种情况下,可能会报ORA-600[2662](SCN有关)和 ORA-600[4000](回滚段有关)的错误。
错误1:ORA-600[2662](SCN有关) 解决方案
这次一开始这个库报ORA-600[2662]错误:
Mon Aug 23 09:37:00 2010
Errors in file oracle/QAS/saptrace/usertrace/qas_ora_852096.trc:
ORA-00600: internal error code, arguments: [2662], [0], [130131504], [0], [130254136], [4264285], [], []
Mon Aug 23 09:37:02 2010
Errors in file oracle/QAS/saptrace/usertrace/qas_ora_852096.trc:
ORA-00600: internal error code, arguments: [2662], [0], [130131506], [0], [130254136], [4264285], [], []
ORA-600 [2662] “Block SCN is ahead of Current SCN”错误是当数据块中的SCN领先于current SCN,由于后台进程或服务进程都会比对UGA中的dependent SCN和数据库当前的SCN,如果数据库当前SCN小于dependent SCN,那么该进程就会报ORA-600 [2662]错误,如果遭遇该错误的是服务进程,那么服务进程一般会异常终止;如果遭遇该错误的是后台进程譬如SMON,则会导致实例CRASH。
ORA-600 [2662]错误可以能由以下几种情况引起:
1.启用隐含参数_ALLOW_RESETLOGS_CORRUPTION后,以resetlogs形式打开数据库;这种情况下发生2662错误,根本原因是没有完全前滚导致控制文件中的SCN滞后于数据块中的SCN。
2.硬件故障导致数据库没法写控制文件和联机日志文件
3.错误的部分恢复数据库
4.恢复了控制文件,但是没有使用recover database using backup controlfile进行恢复
5.数据库crash后设置了_DISABLE_LOGGING隐含参数
6.在并行服务器环境中DLM存在问题
该错误的5个参数的具体含义如下:
ARGUMENTS:
Arg [a] Current SCN WRAP
Arg [b] Current SCN BASE
Arg [c] dependent SCN WRAP
Arg [d] dependent SCN BASE
Arg [e] Where present this is the DBA where the dependent SCN came from.
我们的case当中dependent SCN为130254136,而当前SCN为130131506,其差值为122630;从以上告警日志中可以看到数据库的当前SCN是在不断缓慢增长的,当我们遭遇到2662错误时,很滑稽的一点是只要不断重启数据库保持current SCN的增长,一段时间后2662错误会不药而愈。当然我们也可以不用这种笨办法,10015事件可以帮助我们调整数据库当前SCN:
/* 当数据库处于mount状态,可以使用10015事件来调整scn */
alter session set events '10015 trace name adjust_scn level 1';
* 这里可以设置level 2..10等 (level 1是在每次打开数据库时scn增加1000k)*/
总结:
ORA-00600: internal error code, arguments: [2662], [0], [130131506], [0], [130254136], [4264285], [], []
解决方法:不停的重启或者执行:alter session set events '10015 trace name adjust_scn level 1';
错误2:
ORA-600[4000](回滚段有关)的错误
ORA-00600: internal error code, arguments: [4000], [8], [], [], [], [], [], []
Wed Aug 25 07:43:53 2010
ORA-00704: bootstrap process failure
ORA-00704: bootstrap process failure
ORA-00600: internal error code, arguments: [4000], [8], [], [], [], [], [], []
Wed Aug 25 07:43:53 2010
Error 704 happened during db open, shutting down database
解决方法:
重启数据库过程中遭遇了ORA-600 [4000]错误,该错误一般当Oracle尝试读取数据字典(主要是undo$基表)中记录的USN对应的回滚段失败引起.,通过设置隐式参数_corrupted_rollback_segments可以一定程度上规避该错误,强制打开数据库,其Argument[a]代表造成读取失败的USN(undo segment number),但实际上有问题的回滚段可能不止这一个:
/* 通过strings工具从system表空间上找回各回滚段的名字 */
$strings system.dbf |grep _SYSSMU|less
_SYSSMU1$
_SYSSMU2$
_SYSSMU3$
_SYSSMU4$
_SYSSMU5$
_SYSSMU6$
_SYSSMU7$
_SYSSMU8$
_SYSSMU9$
.........
alter system set "_corrupted_rollback_segments"='(_SYSSMU1$, _SYSSMU2$, _SYSSMU3$, _SYSSMU4$, _SYSSMU5$, _SYSSMU6$, _SYSSMU7$, _SYSSMU8$, _SYSSMU9$, _SYSSMU10$, _SYSSMU11$, _SYSSMU12$)' scope=spfile;
System altered.
/* 即便设置了_corrupted_rollback_segments隐式参数,也还有一定概率遭遇4000错误,尝试加上10513事件,并多次重启数据库 */
SQL> alter system set event='10513 trace name context forever,level 2' scope=spfile;
System altered.
/* 再次重启后发现4000错误不再出现 *
或者:undo_management 这是manual
alter system set undo_management=manual ;
错误3
SQL> recover database until cancel;
ORA-00283: recovery session canceled due to errors
ORA-16433: The database must be opened in read/write mode.
[oracle@yutianedu oracle]$ oerr ora 16433
16433, 00000, "The database must be opened in read/write mode."
// *Cause: An attempt was made to open the database in read-only mode after an
// operation that requires that the database be opened in read/write
// mode.
// *Action: Open the database in read/write mode. The database can then be
// opened in read-only mode.
解决:重建控制文件
SQL> select name from v$datafile
NAME
--------------------------------------------------------------------------------
+DATA/orcl/datafile/system.256.853023133
+DATA/orcl/datafile/sysaux.257.853023133
+DATA/orcl/datafile/undotbs1.258.853023133
+DATA/orcl/datafile/users.259.853023133
+DATA/orcl/datafile/example.265.853023375
SQL> select group#,member from v$logfile
GROUP# MEMBER
---------- ---------------------------------------------
3 +DATA/orcl/onlinelog/group_3.263.853024583
3 +FRA/orcl/onlinelog/group_3.259.853024593
2 +DATA/orcl/onlinelog/group_2.262.853024563
2 +FRA/orcl/onlinelog/group_2.258.853024575
1 +DATA/orcl/onlinelog/group_1.261.853024541
1 +FRA/orcl/onlinelog/group_1.257.853024555
4 u01/app/oracle/redo401.log
4 u01/app/oracle/redo402.log
8 rows selected.
重建控制文件语法:
SQL> select userenv('language') from dual;
USERENV('LANGUAGE')
----------------------------------------------------
AMERICAN_AMERICA.ZHS16GBK
cd home/oracle
vim c.sql
CREATE CONTROLFILE REUSE DATABASE "ORCL" RESETLOGS NOARCHIVELOG
MAXLOGFILES 16
MAXLOGMEMBERS 3
MAXDATAFILES 100
MAXINSTANCES 8
MAXLOGHISTORY 292
LOGFILE
GROUP 1 ( '+DATA/orcl/onlinelog/group_1.261.853024541','+FRA/orcl/onlinelog/group_1.257.853024555') SIZE 50M BLOCKSIZE 512,
GROUP 2 ('+DATA/orcl/onlinelog/group_2.262.853024563','+FRA/orcl/onlinelog/group_2.258.853024575') SIZE 50M BLOCKSIZE 512,
GROUP 3 ('+DATA/orcl/onlinelog/group_3.263.853024583','+FRA/orcl/onlinelog/group_3.259.853024593') SIZE 50M BLOCKSIZE 512,
GROUP 4
('/u01/app/oracle/redo401.log','/u01/app/oracle/redo402.log') SIZE 50M BLOCKSIZE 512
DATAFILE
'+DATA/orcl/datafile/system.256.853023133',
'+DATA/orcl/datafile/sysaux.257.853023133',
'+DATA/orcl/datafile/undotbs1.258.853023133',
'+DATA/orcl/datafile/users.259.853023133',
'+DATA/orcl/datafile/example.265.853023375'
CHARACTER SET ZHS16GBK
;
查出所有的控制文件
SQL> select name from v$controlfile;
NAME
--------------------------------------------------------------------------------
+DATA/orcl/controlfile/current.260.853023315
+FRA/orcl/controlfile/current.256.853023315
shutdown immediate;
删除所有控制文件
su - grid
asmcmd
rm +DATA/orcl/controlfile/current.260.853023315
rm +FRA/orcl/controlfile/current.256.853023315
重建控制文件
sqlplus / as sysdba
startup nomount
@/home/oracle/c.sql
SQL> select status from v$instance;
STATUS
------------
MOUNTED
开始开始进行recover:
recover database until cancel; #报错
recover database until cancel using backup controlfile ;
cancel
alter database open resetlogs; #打开数据库
ORA-00603: ORACLE server session terminated by fatal error
ORA-00604: error occurred at recursive SQL level 1
ORA-01115: IO error reading block from file (block # )
ORA-01110: data file 1: '+DATA/orcl/datafile/system.256.822001323'
ORA-15081: failed to submit an I/O operation to a disk
ORA-00604: error occurred at recursive SQL level 1
ORA-01115: IO error reading block from file (block # )
ORA-01110: data file 1: '+DATA/orcl/datafile/system.256.822001323'
ORA-15081: failed to submit an I/O operation to a disk
ORA-01092: ORACLE instance terminated. Disconnection forced
ORA-00600: internal error code, arguments: [2662], [0], [1020724], [0],
[1025973], [12583040], [], [], [], [], [], []
Process ID: 29788
Session ID: 1 Serial number: 3
----------------------------------------------------------------------
exit
sqlplus / as sysdba
startup mount ;
alter session set events '10015 trace name adjust_scn level 2';
shutdown immediate;
startup mount ;
alter database open ;
alter database open
*
ERROR at line 1:
ORA-01113: file 1 needs media recovery
ORA-01110: data file 1: '+DATA/orcl/datafile/system.256.822001323'
系统核心文件
没有备份 没归档,打不开数据库的
要用工具au bbed 直接从数据文件中提取数据
最后alter database open resetlogs;
一定要备份(注意:系统表空间)

