




Table of Contents
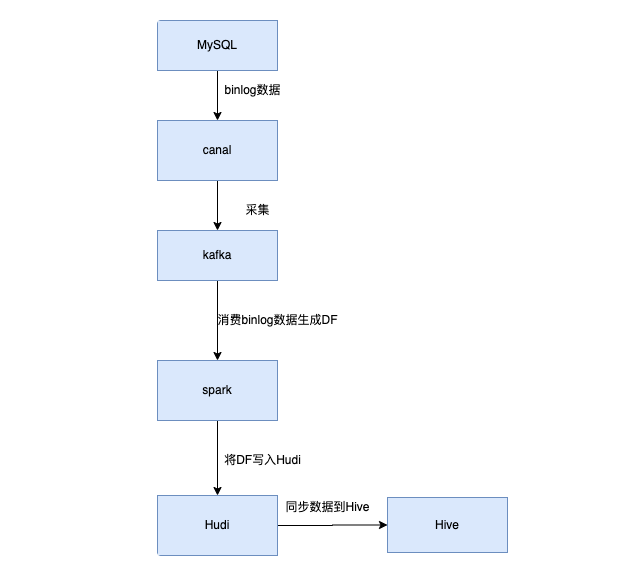
一. Spark操作Huid概述
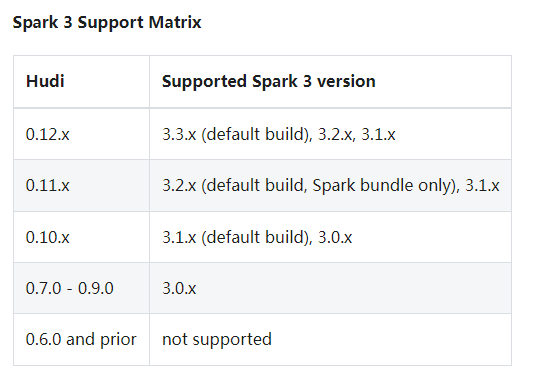
Hudi各个版本支持Spark版本情况:
将hudi集成spark的jar包,放到spark的jars目录
-- 同步到其它节点
cd /home/hudi-0.12.0/packaging/hudi-spark-bundle/target
cp ./hudi-spark3.3-bundle_2.12-0.12.0.jar /home/spark-3.3.1-bin-hadoop3/jars/
Hudi支持Scala(Spark-Shell)、pyspark、SparkSQL三种方式来操作Hudi。
| 软件 | 版本 |
|---|---|
| Python | 3.8 |
| Hadoop | 3.3.2 |
| Spark | 3.3.1 |
| Hudi | 0.12.0 |
二. Spark-Shell方式
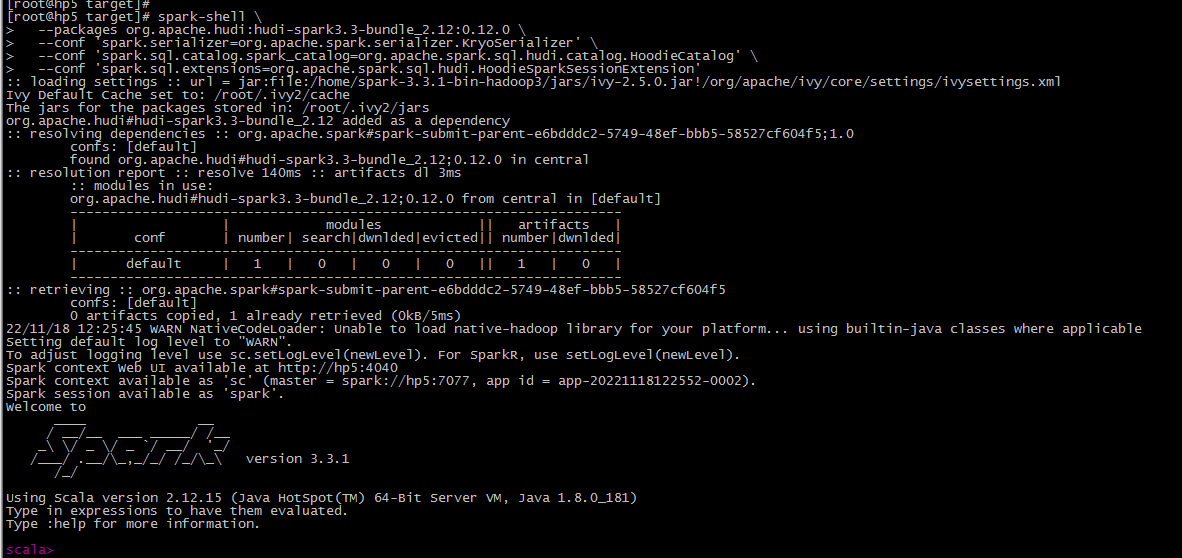
# Spark 3.3
spark-shell \
--packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
备注:
官网提供的是:
–packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.1
因为hudi最新的版本是0.12.1,但是我测试过,建表有问题,会报错,把hudi的版本改回0.12.0即可
–packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.0
下同。
三. pyspark方式
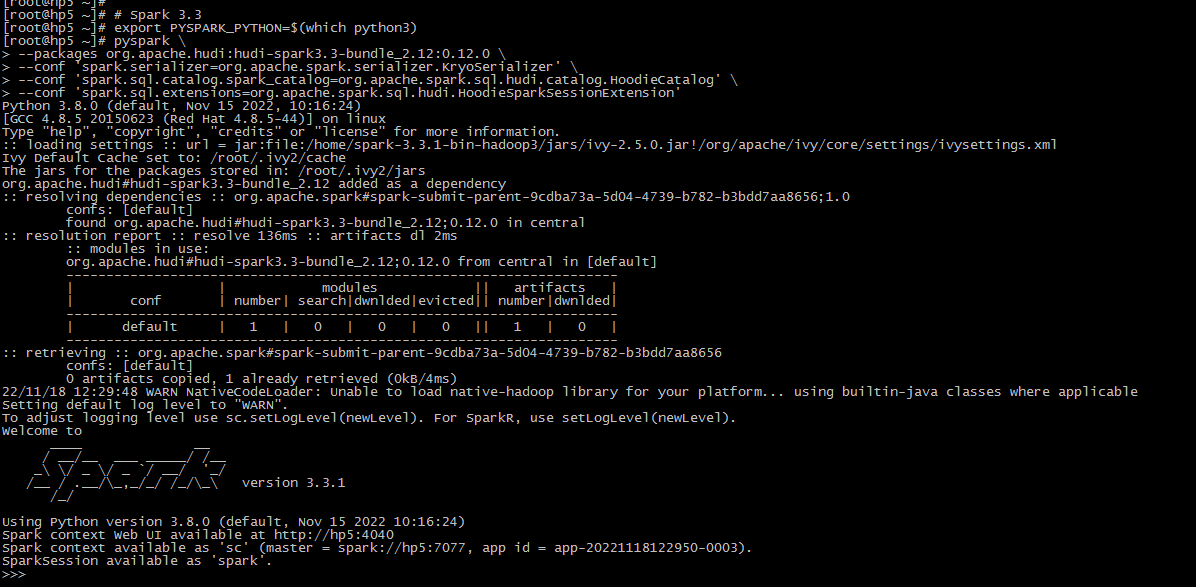
# Spark 3.3
export PYSPARK_PYTHON=$(which python3)
pyspark \
--packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
四. SparkSQL方式
# Spark 3.3
spark-sql --packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
参考:
- https://hudi.apache.org/docs/quick-start-guide/
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
