distinct测试环境
SQL> drop table t purge;
SQL> create table t as select * from dba_objects;
SQL> update t set object_id=rownum;
SQL> alter table t modify object_id not null;
SQL> update t set object_id=2;
SQL> update t set object_id=3 where rownum<=25000;
SQL> commit;
DISTINCT由于其 HASH UNIQUE的算法导致其不会产生排序
SQL> set linesize 1000
SQL> set autotrace traceonly
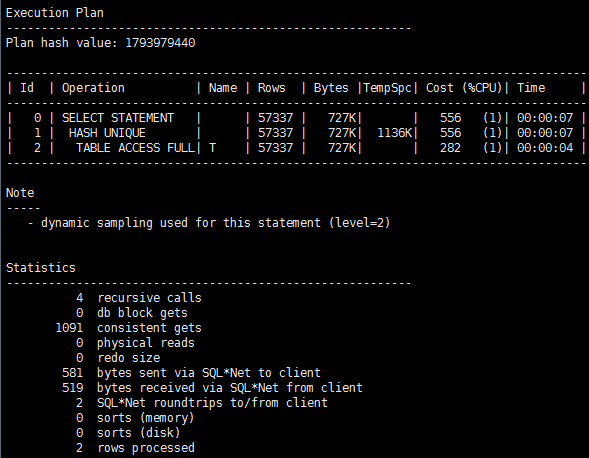
SQL> select distinct object_id from t;
虽然没有排序,通过观察TempSpc可知distinct消耗PGA内存进行HASH UNIQUE运算。
再在t表object_id列建立索引的测试
为T表的object_id列建索引:
SQL> create index idx_t_object_id on t(object_id);
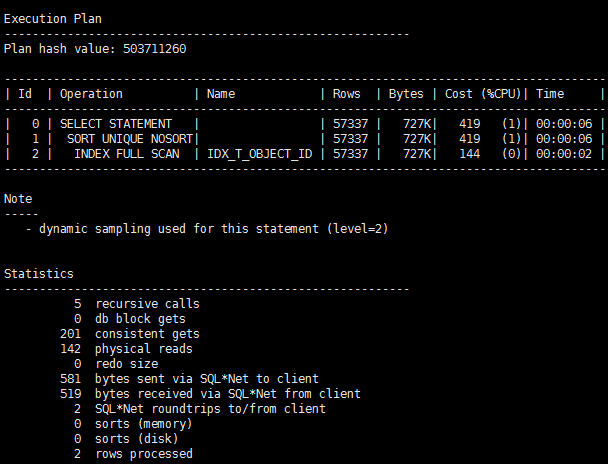
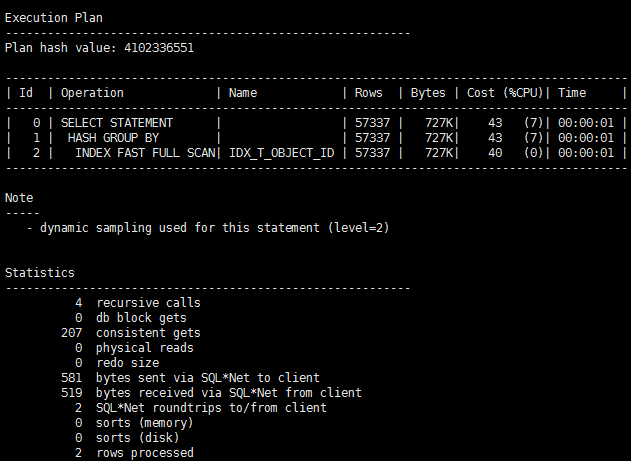
SQL> select /*+index(t)*/ distinct object_id from t ;
TempSpc关键字消失,COST也立即下降许多。
体会另外一种写法(更高效)
SQL> select object_id from t group by object_id;
DISTINCT和GROUP BY这两者本质上应该没有可比性,distinct 取出唯一列,group by 是分组,但有时在优化的时候,在没有聚合函数的时候,他们查出来的结果也一样。
exists代替distinct的优化
例:
distinct的写法:
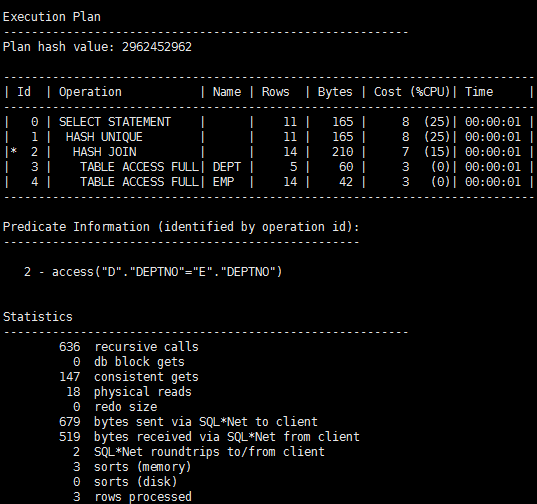
SQL> select distinct d.deptno,d.dname from dept d,emp e where d.deptno = e.deptno;
下面是换成exists的写法:
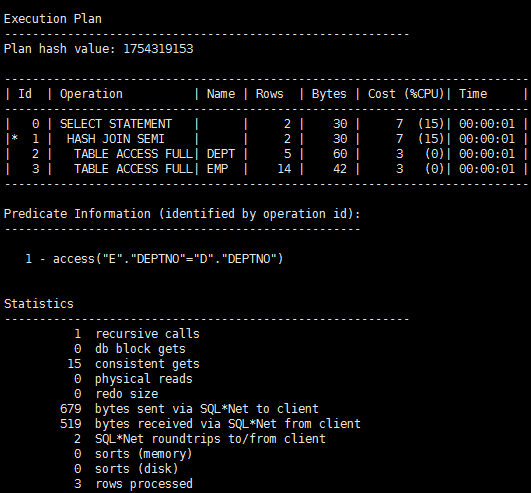
SQL> select d.deptno,d.dname from dept d where exists(select 'x' from emp e where e.deptno = d.deptno);
可见exists消耗的Cost更少,效率更高。