




2023 年 1 月 25 日 ,AWS宣布全面推出Amazon OpenSearch Serverless,这是 Amazon OpenSearch Service 的无服务器选项,可以更轻松地运行搜索和分析工作负载,甚至无需考虑基础设施管理。

自我管理的OpenSearch和托管的 OpenSearch 服务广泛用于搜索和分析 PB 级数据。这两种选择都使客户能够完全控制集群中计算、内存和存储资源的配置,从而使他们能够优化其应用程序的成本和性能。
但是,客户可能经常运行高度可变的应用程序,其使用情况并不总是为人所知。此类应用程序可能会遇到摄入数据的突然爆发或不规则且不可预测的查询请求。为了保持一致的性能,客户必须不断地调整和调整集群的大小,或者为高峰需求过度配置,这会导致成本过高。许多人希望获得更简单的体验来运行搜索和分析工作负载,从而使他们能够专注于业务应用程序,而不必担心后端基础架构和数据管理。
更简单是什么意思?这意味着客户不想担心这些任务:
- 选择和配置实例。
- 管理分片或索引大小。
- 用于规模调整和运营目的的索引和数据管理。
- 持续监控或调整设置以满足工作负载需求。
- 计划系统故障和资源阈值违规。
- 安全更新和服务软件更新。
AWS 将此清单转化为以下产品主题下的要求和目标:
- 简单安全
- 自动缩放、容错和持久性
- 成本效益
- 生态系统整合
在深入研究 OpenSearch Serverless 如何满足这些需求之前,让我们回顾一下 OpenSearch Serverless 的目标用例,因为它们的独特特征在很大程度上影响了设计方法和架构。
目标用例
OpenSearch Serverless 的目标用例与 OpenSearch 相同:
- 时间序列分析(通常也称为日志分析)侧重于实时分析大量机器生成的半结构化数据,以获取操作、安全和用户行为洞察。
- 搜索为客户的内部网络应用程序(应用程序搜索、内容管理系统、法律文件)和面向互联网的应用程序(如电子商务网站搜索和内容搜索)提供支持。
让我们了解典型时间序列和搜索工作负载之间的差异(例外情况可能会有所不同):
- 时间序列工作负载是写入密集型的,而搜索工作负载是读取密集型的。
- 与时间序列相比,搜索工作负载的数据语料库较小。
- 搜索工作负载对延迟更敏感,需要比时间序列更快的响应时间。工作量。
- 时间序列的查询是在最近的数据上运行的,而搜索查询则扫描整个语料库。
这些特征严重影响了我们处理和管理工作负载的分片、索引和数据的方法。在下一节中,我们将回顾 OpenSearch Serverless 如何在有效迎合这些独特的工作负载特征的同时应对客户挑战的广泛主题。
简单安全
要开始使用 OpenSearch Serverless,客户需要创建一个集合。集合是索引数据的逻辑分组,它们协同工作以支持工作负载,而物理资源在后端自动管理。客户无需声明需要多少计算或存储,也无需监控系统以确保其运行良好。
为了巧妙地处理这两种主要工作负载,OpenSearch Serverless 应用了不同的分片和索引策略。因此,在创建集合的工作流程中,必须定义集合类型——时间序列或搜索。客户不必担心索引的重新索引或翻转以支持他们不断增长的数据大小,因为它由系统自动处理。
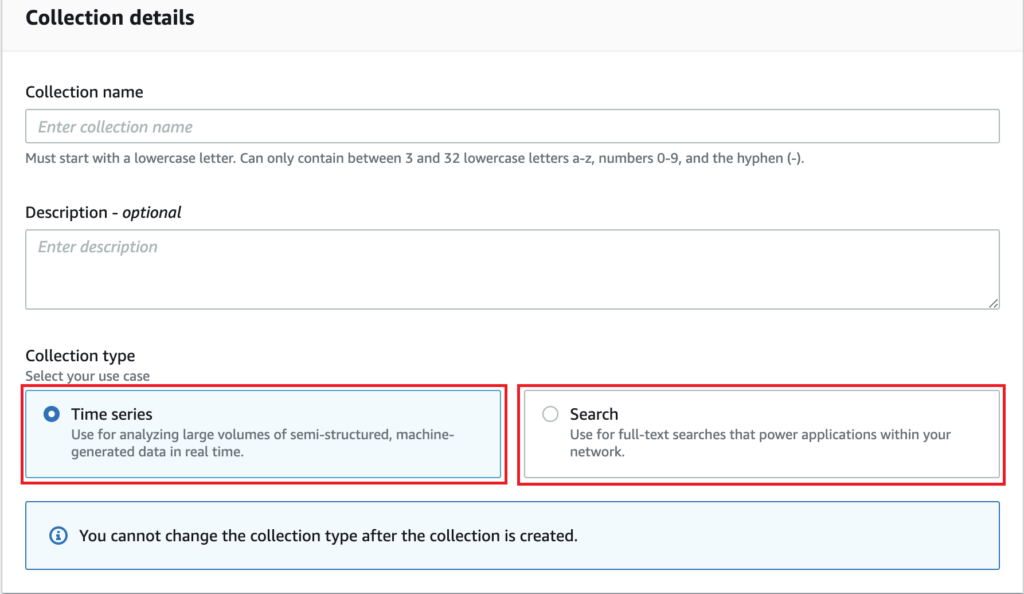
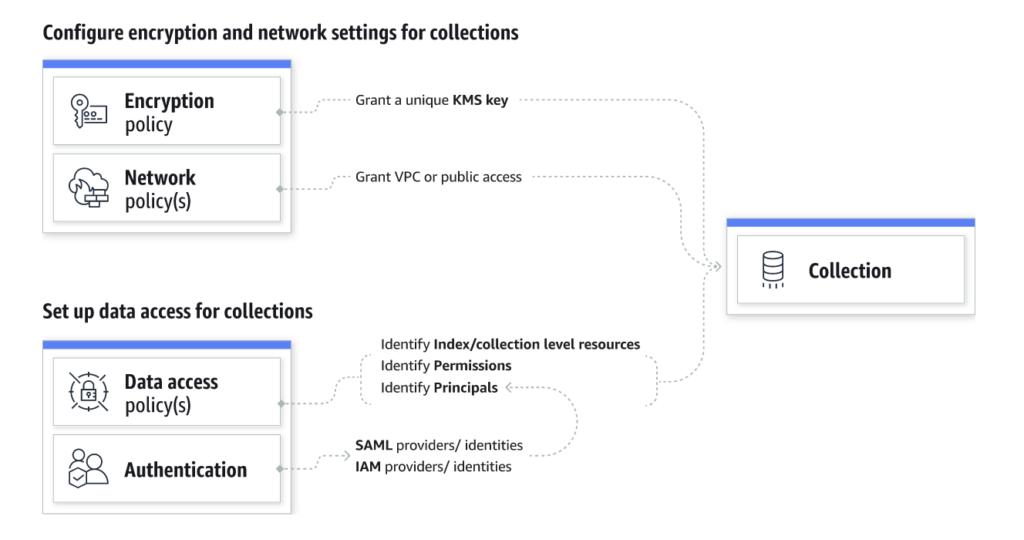
接下来,客户就要使用的加密密钥、对其集合的网络访问(公共端点或 VPC)以及应该访问集合的人员进行配置选择。OpenSearch Serverless 具有易于使用且高效的安全模型,支持集合和索引的分层策略。客户可以为其所有馆藏和索引创建细粒度的馆藏级和帐户级安全策略。集中的帐户级策略为他们提供了全面的可见性和控制,并使大规模保护集合的操作变得简单。
对于加密策略,客户可以使用通配符匹配模式为单个集合、所有集合或集合子集指定AWS Key Management Service (AWS KMS) 密钥。如果来自多个策略的规则与一个集合匹配,则最接近完全限定名称的规则优先。客户还可以在网络和数据访问策略中指定通配符匹配模式。多个网络和数据访问策略可以应用于单个集合,并且权限是相加的。客户还可以随时更新其收藏的网络和数据访问策略。
现在可以使用 SAML 和AWS Identity and Access Management (IAM) 凭证访问 OpenSearch Dashboards。OpenSearch Serverless 还支持细粒度的 IAM 权限,以便客户可以定义谁可以创建、更新和删除加密、网络和数据访问策略,从而实现组织一致性。默认情况下,OpenSearch Serverless 中的所有数据在传输过程中和静态时均已加密。
自动缩放、容错和持久性
OpenSearch Serverless将存储和计算分离,允许每一层根据工作负载需求独立扩展。这种解耦还允许隔离索引和查询计算节点,因此队列可以同时运行而不会出现任何资源争用。
CPU、磁盘利用率、内存和热分片状态等计算资源由该服务监控和管理。当这些系统阈值被突破时,该服务会调整容量,这样客户就不必担心扩展资源。例如,当应用程序监控工作负载在可用性事件期间收到突然爆发的日志记录活动时,OpenSearch Serverless 将扩展索引计算节点。当这些日志记录活动减少并且计算节点中的资源消耗低于某个阈值时,OpenSearch Serverless 会缩减节点。同样,当网站搜索引擎在新闻事件后收到突然的查询高峰时,OpenSearch Serverless 会自动缩放节点查询计算节点以在不影响数据摄取性能的情况下处理查询。
下图说明了这种高级架构:
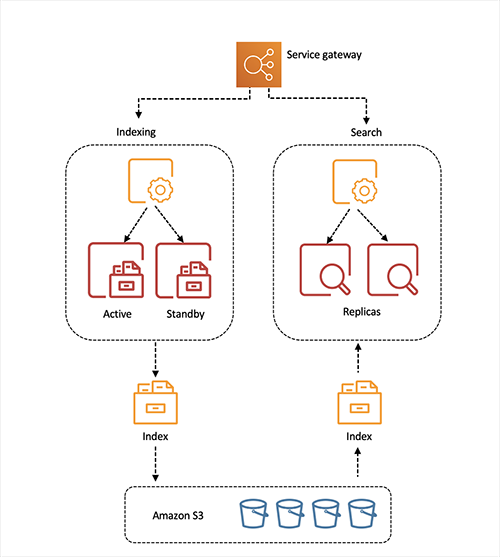
OpenSearch Serverless 专为生产工作负载而设计,具有针对可用区中断和基础设施故障的冗余。默认情况下,OpenSearch Serverless 将跨可用区复制索引。索引计算节点以主备模式运行。服务控制平面也构建了冗余和自动故障恢复。
所有索引数据都存储在 Amazon Simple Storage Service ( Amazon S3 ) 中,以提供与 Amazon S3 相同的数据持久性(11 个九)。查询计算实例直接从 Amazon S3 下载索引数据,运行搜索操作,并执行聚合。冗余查询计算以主动-主动模式跨可用区部署,以在故障期间保持可用性。刷新间隔(从 OpenSearch Serverless 摄取文档到可用于搜索的时间)目前不到 15 秒。
成本和成本效率
借助 OpenSearch Serverless,客户无需预先调整或配置资源,也无需为生产环境中的峰值负载过度配置。他们只需为其工作负载消耗的计算和存储资源付费。用于数据摄取、搜索和查询的计算容量以 OpenSearch 计算单元 (OCU) 衡量。OCU的数量直接对应CPU、内存、Amazon Elastic Block Store(Amazon EBS) 存储,以及摄取数据或运行查询所需的 I/O 资源。一个 OCU 包括 6 GB 的 RAM、相应的 vCPU、120 GB 的 GP3 存储(用于提供对最常访问的数据的快速访问)以及到 Amazon S3 的数据传输。提取数据后,索引数据存储在 Amazon S3 中。然后,客户可以使用 API 控制数据的保留和删除。
当客户在帐户中创建第一个收集端点时,OpenSearch Serverless 会提供 4 个 OCU(2 个摄取包括主要和备用,2 个搜索包括两个副本以实现高可用性)。即使无服务器端点上没有活动,这些 OCU 也会被实例化,以避免任何冷启动延迟。该帐户中使用相同 KMS 密钥的所有后续集合共享这些 OCU。
在自动缩放期间,OpenSearch Serverless 将添加更多 OCU 以支持集合所需的计算。这些 OCU 在开始响应索引或查询请求之前从 Amazon S3 复制索引数据。同样,OpenSearch Serverless 控制平面持续监控 OCU 的资源消耗。当索引或搜索请求率降低并且 OCU 消耗低于某个阈值时,OpenSearch Serverless 会将 OCU 计数减少到工作负载所需的最小容量。最小 OCU 可防止冷启动延迟。
OpenSearch Serverless 还为时间序列工作负载提供内置缓存层,以提供更好的性价比。OpenSearch Serverless 在临时磁盘上缓存最近的日志数据,通常是前 24 小时。对于超过 24 小时的数据,OpenSearch Serverless 仅缓存元数据并根据查询访问从 Amazon S3 获取必要的数据块。该模型还有助于在控制成本的同时打包更多数据。对于搜索集合,查询计算节点将整个数据语料库本地缓存在临时磁盘上,以提供快速、毫秒级的查询响应。
生态系统整合
大多数适用于 OpenSearch 的工具也适用于 OpenSearch Serverless。客户不必重写现有的管道和应用程序。OpenSearch Serverless 具有与 OpenSearch 相同的逻辑数据模型和查询引擎,因此客户可以使用您熟悉的相同摄取和查询 API,并使用无服务器 OpenSearch Dashboards 进行交互式数据分析和可视化。
由于其兼容接口,OpenSearch Serverless 还支持现有丰富的高级客户端和流摄取管道的 OpenSearch 生态系统——Amazon Kinesis Data Firehose、FluentD、FluentBit、Logstash、Apache Kafka 和 Amazon Managed Streaming for Apache Kafka (Amazon MSK) . 有关更多信息,请参阅将数据提取到 Amazon OpenSearch 无服务器集合中。AWS 客户还可以使用 AWS CloudFormation 和 AWS CDK 自动执行集合创建过程。通过Amazon CloudWatch集成,他们可以监控关键的 OpenSearch Serverless 指标并设置警报以通知您任何阈值违规。
在托管集群和 OpenSearch 无服务器之间进行选择
托管集群和 OpenSearch Serverless 都是 OpenSearch Service 下的部署选项,并由开源 OpenSearch 项目提供支持。OpenSearch Serverless 可以更轻松地运行周期性、间歇性或不可预测的工作负载,而无需考虑调整、监控和调整 OpenSearch 集群。但是,客户可能更愿意在需要严格控制集群配置或特定自定义的情况下使用托管集群。
借助托管集群,AWS 客户可以选择他们喜欢的实例和版本,并且可以更好地控制配置,例如较低的刷新间隔或数据分片策略,这对于不属于 OpenSearch Serverless 支持的典型模式的用例可能至关重要。此外,OpenSearch Serverless 目前不支持所有高级 OpenSearch 功能和插件,例如警报、异常检测和 k-NN。在 OpenSearch Serverless 添加对这些功能的支持之前,客户可以将托管集群用于这些功能。
自预览版以来的更新
随着公开发布版本的发布,OpenSearch Serverless 现在将向外扩展和向内扩展以支持工作负载所需的最少资源。对于索引和查询,每个帐户的最大 OCU 限制已从 20 增加到 50。此外,客户现在可以使用高级 OpenSearch 客户端来摄取和查询您的数据,还可以使用 Logstash 从 OpenSearch 集群迁移数据。
AWS 还增加了对另外三个区域的支持。OpenSearch Serverless 现已在全球八个区域推出:美国东部(俄亥俄)、美国东部(弗吉尼亚北部)、美国西部(俄勒冈)、亚太地区(新加坡)、亚太地区(悉尼)、亚太地区(东京)、欧洲(法兰克福)和欧洲(爱尔兰)。
文章来源:https://www.datanami.com/this-just-in/aws-announces-general-availability-of-amazon-opensearch-serverless/
