




在企业努力处理非结构化数据的环境中,向量数据库是一个令人兴奋的概念,可以从您收集的数据中最大化价值。
非结构化数据是一个复杂的挑战,但在任何组织追求数据卓越的过程中都是一个巨大的机会。不幸的是,由于分类、管理和组织负载的复杂性,它仍然没有受到影响。有趣的是,OpenAI 计划ChatGPT已成为将非结构化数据处理为结构化格式的赢家。然而,ChatGPT 并不是唯一一个在简化非结构化数据分析方面取得进展的公司:进入向量数据库。
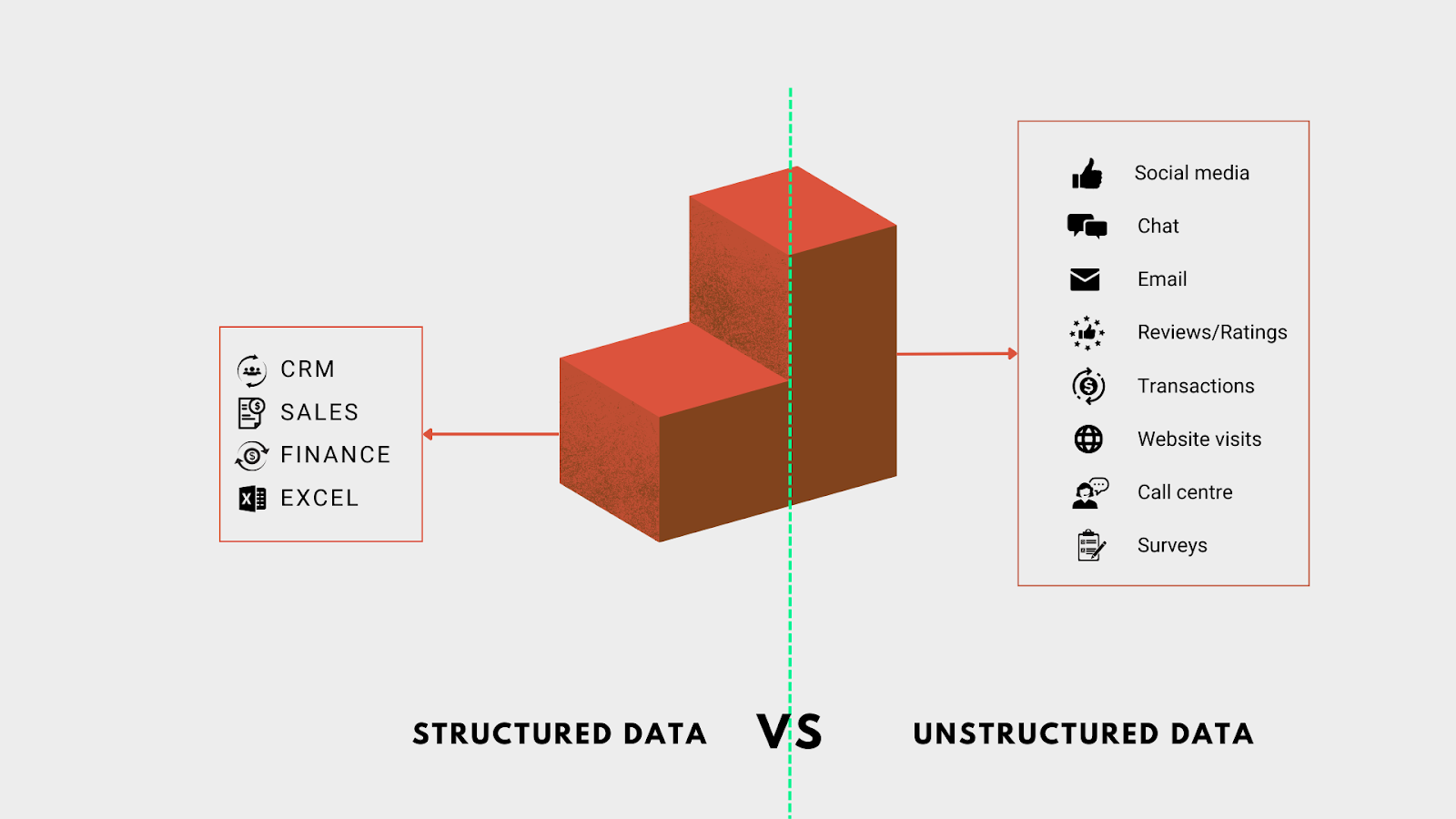
结构化数据和非结构化数据之间的差异
向量数据库引入了一种新的数据库管理方法,使您能够充分利用未触及的非结构化数据。他们具有对非结构化数据进行分类和搜索的出色能力。
在深入研究向量数据库之前,让我们先了解一下当前与非结构化数据相关的数据分析场景。
非结构化数据分析的系统架构
重要部件清单
收藏
数据来自不同的地方,包括社交媒体、物联网设备、电子邮件和其他设备或平台。但是,确保您收集的所有数据都是可靠且相关的至关重要。此外,您可以使用数据湖将多个位置的数据整理到一个存储单元中。
贮存
由于非结构化数据不能存储在列和行的表中,因此无法从数据中得出统计数据。因此,它需要一个独特的数据存储模型,称为文件系统。
元数据
元数据是一组字符,每个数据片段都与之相关联,以帮助您访问和管理数据。它类似于您添加到博客的标题和类别标签。使用 NLP(自然语言处理)等 ML 方法,您可以分析非结构化数据以供您理解
可视化
一旦数据通过分析被解码,它就可以在称为数据可视化的阶段中以图形、图表或其他视觉效果表示。它有助于轻松理解数据,因为它揭示了隐藏的细节。
用于存储非结构化数据的文件系统
在计算机中存储电子数据可以有多种方式,一种可行的方式是文件系统。它将数据安排为文件,然后保存在目录结构中。
由于文件系统允许存储不同的文件类型,因此它是管理非结构化数据的理想方式。它还允许您通过有效地获得洞察力来跨环境和应用程序利用这些数据。
文件系统的类型
分散式
分布式文件系统 (DFS) 允许您跨多个文件服务器或位置存储数据,同时允许您从任何地方访问这些数据。
对象存储
对象存储是一种文件系统,其中数据块存储为单个块,同时将数据与元数据保存在一起。
横向扩展 NAS
横向扩展网络附加存储 (NAS) 是一种系统,其中可以通过添加形成集群存储阵列的其他设备来扩展存储空间(磁盘)。
云原生
云原生文件系统 (CNFS) 是一种写时复制文件系统,可根据您的要求在云存储单元之间移动数据。
网络附加存储
网络附加存储 (NAS) 是一种基于网络的存储设备,允许您通过中央网络以文件的形式访问您的数据。
数据库
数据库是一种数据集合,可以根据需要轻松存储、访问和更新。数据可以是文件、图像、视频或其他记录。组织将所有数据存储在一个地方,以便对其进行处理和分析以促进重要的业务流程。通常,数据库使用 SQL(结构化查询语言)来写入和查询数据。
数据库类型
文档
以类 JSON 格式存储数据的数据库称为文档数据库。这些非关系数据库帮助开发人员在其应用程序代码中使用单一格式来管理数据。
图形
图形数据库是一种以图形结构而不是表格或文档的形式以节点和关系的形式存储数据的数据库。
列族
列族数据库将数据存储在行内的列部分中,列与行键相关联。
核心价值
也称为键值存储,键值数据库以键值格式存储数据。这意味着数据被表示为通过链接两个数据项形成的唯一标识符或键。
面向对象
面向对象数据库 (OOD) 应用面向对象编程的原理以对象的形式存储数据。
数据库的新选择:向量数据库
向量数据库的定义
简而言之,向量数据库是一种数据存储系统,您可以在其中将复杂数据转换为向量以有效地组织数据并促进顺畅搜索。要完全掌握这个概念,我们应该熟悉“向量嵌入”。
向量嵌入是一种将复杂数据对象表示为数值的做法,以便您可以应用 ML(机器学习)算法进行数据管理。应用向量嵌入允许您将文本、数字、图像、音频甚至视频块转换为向量,以便于操作。向量数据库明确设计用于在索引向量时管理向量嵌入,从而使搜索和提取请求或类似数据变得容易。它具有 CRUD 操作、水平缩放、元数据过滤和相似性搜索功能。
增删改查操作
向量数据库支持 CRUD 功能,即创建、读取、更新和删除向量嵌入,因为它们的组织方式使您可以轻松地将向量相互比较或搜索查询。
相似性搜索
也称为向量搜索,它是一种使您即使不知道关键字或分配给对象的元数据也能查找数据的功能。相反,它将返回与您的搜索查询相似的对象。
元数据过滤
除了相似性搜索,向量数据库还允许您应用各种过滤器来生成所需的结果。
向量数据库有何不同?
结构化数据通常相互链接;因此,使用传统数据库进行管理变得很容易。这些数据库称为关系数据库,以表格格式存储数据,便于搜索和处理。但是,由于非结构化数据的复杂性,就不能这样说了。这就是向量数据库通过提供搜索和挖掘转换为向量嵌入的非结构化数据的能力来增加重要价值的地方。
当您输入搜索查询时,传统数据库会返回完全匹配,而向量数据库的结果大多是接近匹配。向量数据库的这种独特功能已在商业世界中找到了巨大的应用。
Qdrant
Qdrant是一种自托管或托管的相似性搜索引擎和向量数据库,可通过 API 提供存储、搜索和管理向量等服务。Qdrant 基于 Rust 构建,可以快速实现动态查询计划和有效负载数据索引。它还提供扩展的过滤支持。
Vertex
Vertex AI Machine Engine 是 Google 的大规模、低延迟向量数据库,可提供完全托管的相似性搜索。它根据向量嵌入的独特方面有效地索引向量嵌入,以促进简单和可扩展的搜索。
NucliaDB
NucliaDB是一个开源向量数据库和分布式搜索引擎,允许您将数据存储在其云基础架构上。云原生数据库是用 Rust 编写的,提供高读取性能以提供快速的可扩展性。
虽然上面提到的所有名称都提供相似性搜索,但 Qdrant 更进一步。它的HSNW(分层导航小世界图)算法有一个自定义实现选项。这使您可以通过向查询添加额外的过滤器来提供更好的搜索结果。
为您的组织选择正确的选项
向量数据库在技术上和组织上都是一个重要的范式转变。考虑到计算、人工智能和机器学习的规模和依赖性,管理向量数据库可能成为一个持续的过程。
此外,创建向量索引需要专业知识才能轻松规范向量数据库的使用。但是,您需要的数据库类型取决于您的业务需求。例如,如果您的数据是结构化的并使用SQL存储在行和列中,您可以选择传统的数据库设置,如关系数据库。
下面我们将快速浏览关系数据库和向量数据库各自的一个用例。
关系数据库的用例
您的 OTT 服务(包括 Netflix、Prime Video 和 Hulu)会维护数据库以存储其各自平台上可用的内容。例如,每当您搜索电影或电视节目时,它们都会返回准确的标题。另一个用例是体育行业的梦幻联赛。公司筛选 PB 级数据,例如玩家表现、统计数据和游戏结果。
向量数据库用例
如果我们以流媒体服务为例,你一定见过这些平台根据你的观看历史推荐电影或电视剧。向量数据库为这个推荐引擎提供动力。您可以使用它们来推荐类似于过去的图像、视频和购买的对象。
结论
非结构化数据拥有更深入的洞察力,可让您更好地了解您的企业所拥有的机会和弱点。这是因为它是您没有在明确定义的字段中捕获的数据。另一方面,所收集数据格式的不一致使组织难以破解。在企业努力处理非结构化数据的环境中,向量数据库是一个令人兴奋的概念,可以从您收集的数据中最大化价值。此外,开源向量搜索数据库将通过相似性搜索等功能为下一代 AI 应用程序提供动力,提供具有便捷 API 的生产就绪服务。
原文标题:Vector Databases Are Reinventing How Unstructured Data Is Analyzed
原文作者:Twain Taylor
原文链接:https://dzone.com/articles/vector-databases-are-reinventing-how-unstructured
