




2023年1月30日,Artie Transfer 首个版本发布,旨在提供事务数据库与数据仓库之间的实时数据传输。此版本附带从 Snowflake 同步到 PostgreSQL 和 MongoDB。
在幕后,Artie Transfer 利用 Postgres WAL 记录变更数据捕获事件,以将它们重播到下游数据仓库(Transfer 依赖于 Debezium)。除此之外,Artie Transfer 还通过提供我们自己的类型库在 CDC 之上构建了 DDL 支持,该类型库比 Go Reflect 快 2 倍。
作为一个担任各种角色的狂热数据仓库 (DWH) 用户,我总是发现我们的 DWH 和位于在线事务 (OLTP) 数据库中的数据之间的数据延迟存在局限性(和挫败感!)。根据我工作的地方,延迟跨越数小时到数天,而较大的公司往往处于较慢的一端。
Artie Transfer 介绍
这种复制滞后阻碍了哪些用例?
鉴于 DWH 是一个平台,可以通过缩短数据滞后时间来启用或加强大量用例。我将在下面举一些例子——
操作重的公司
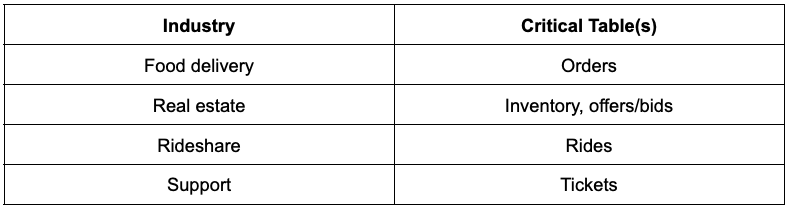
Ops 繁重的公司通常具有不断变化的需求和业务流程。因此,工程团队通常难以跟上 - 因此 Zapier、Typeform、Retool、Tinybird 和其他无代码解决方案等解决方案已成为这些类型公司的标准工具包的一部分。
这些工具可以相互叠加并引用DWH数据,其功效由数据复制滞后决定。也就是说,没有必要让每张桌子都非常快。拥有那会很好……但是,大多数公司通常确实有一些必要的关键表。
例如,一家食品配送公司可以将 Retool 应用程序设置为自定义 Zendesk 应用程序,以便它可以拉取客户最近的订单和交互。
除了前面的示例之外,在这些行业中运营的公司还会注意减少下表(我们称之为“关键表”)中的数据滞后:
生命周期和付费营销用例
在生命周期营销中,购买Iterable、Braze 和 Intercom 等营销自动化工具是很常见的。这些工具中的每一个都有自己的用户模型和事件应该是什么样子的版本,这样营销人员就可以创建电子邮件模板,例如:Hi {{first_name}}!
要发送的其他用户属性示例:
付费营销:一旦客户要求乘车,我们希望将尽可能多的客户特征发送到谷歌和 Facebook 等目的地,以便他们优化算法并找到更多相似的人。
培养活动:当客户在我们的网站上注册时,我们希望将他们放入有效欢迎和引导客户的滴灌活动中。我们想引用动态字段,例如产品交互(他们是否不仅仅是注册?他们是否已经看过一篇文章?他们是否已请求乘车?)和其他客户属性。
那么我们今天如何发送这些数据呢?
通常,团队将使用不同的管道来构建自定义模式以发送到不同的目的地。使用这种类型的设置,有各种缺点:
工程阻止了更改。
用户字段几乎从不在一项服务中。因此,我们需要调用其他服务(现在我们需要错误处理和重试)。回填也可能产生过多的流量和DDOS内部服务无法处理负载。
需要维护和持续支持。如果错误地添加了一个字段并且没有引用索引字段,则可能会导致整个管道变慢。
数据通常不在 DWH 中。因此,很难进行细分和报告。
这可以通过构建物化视图来解决,特别是如果我们可以使用 dbt(一种更具表现力的框架)来创建这些视图。但是,这些解决方案还不够成熟,无法处理大多数营销用例。
为什么 dbt 或物化视图不够用?
在创建物化视图时,我们需要通过指定时间表(例如: Snowflake tasks )来指定这些视图重新生成的频率。为了可视化这方面的延迟,我们可以得出以下等式:
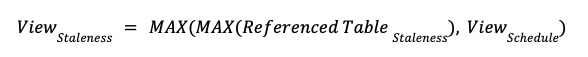
例如:我们可以让物化视图每 5 分钟运行一次,但如果引用表每 6 小时更新一次,这并不重要。结果视图仍然落后 6 小时。
这就是我们建立 Artie Transfer 的原因。Artie Transfer能够缓解等式的第一部分:MAX(Referenced Table Staleness)通过消除原始 OLTP 表延迟。这样,为了更快的视图,我们可以增加视图生成的频率。
公司如何解决当今的数据滞后问题,为什么它不是一个很好的解决方案?
更新 DWH 数据的传统过程如下所示:
通过pg_dump拍摄 Postgres 表的快照(CSV 格式)
解析输出并格式化数据以供 DWH 使用
将此数据上传到 DWH
重复一遍……不过,您每天可以多久运行一次?
对于正在经历这种痛苦的精明公司,他们通常会购买Fivetran for Databases或Fivetran Teleport。然而,由于成本、缺少功能/集成等各种原因,这对公司来说并不总是一个可行的选择。
工程团队可以并且已经尝试自己构建它,但解决方案很棘手且难以扩展。为什么?
更改数据捕获(CDC) 不支持数据定义语言 (DDL),例如添加或删除列
公司通常使用多种数据库类型,每种类型都需要不同的解析器,并且可能需要新的管道
可靠性是零特征。更快的数据复制很好,但前提是结果可靠。如果内部流程错过了 CDC 事件或乱序处理行,则生成的数据不再最终一致,我们最终会得到错误的视图
DWH 旨在处理 COPY 命令的高 QPS(每秒查询数),这将需要一种解决方法来处理数据突变(更新和删除)
输入 Artie Transfer
Artie Transfer 连续流式传输 OLTP 数据(通过 CDC)并将它们重播到指定的 DWH,并将复制延迟从几小时/几天缩短到几秒。我们相信这将使整个生态系统产生更好的洞察力并解锁以前由于此限制而无法实现的其他用例。
为了提供这个承诺,这就是 Artie Transfer 在后台的配置方式——

Artie Transfer端端可视化
端到端流程分为两部分:
#1 - 捕获 CDC 事件
我们将运行一个连接器来读取数据库日志并将它们发布到 Kafka 上。我们的首选是在可用时运行 Debezium。
每个表将有一个主题,因此我们可以根据表吞吐量独立扩展下游工作负载。
Kafka 消息的分区键将是表的主键,每个表一个主题。
#2 - 阿蒂转移
然后 Artie Transfer 订阅 Kafka 主题,并将开始构建一个内存数据库,记录主题的外观(一个 Artie Transfer 消费者可以订阅一个或多个 Kafka 主题)。Artie Transfer 将在刷新间隔结束(默认为 10 秒)或内存数据库已满时刷新,以先到者为准。当 Artie Transfer 刷新时,它将对下游数据仓库进行优化查询并合并微批更改数据。
为了支持这种工作负载,Artie Transfer 具有以下功能:
自动重试和幂等性。我们非常重视可靠性,它是特性 0。减少延迟很好,但如果数据有误则无关紧要。我们提供自动重试和幂等性,以便我们始终实现最终一致性。
自动创建表。如果表不存在,Transfer 将在指定的数据库中创建表。
报错。提供您的 Sentry API 密钥,数据处理错误将出现在您的 Sentry 项目中。
模式检测。Transfer 将自动检测列更改并将它们应用到目的地。
可扩展的架构。无论我们处理 1GB 还是 100+ TB 的数据,Transfer 的架构都保持不变。
亚分钟延迟。Transfer 是用消费者框架构建的,并在后台不断地传输消息。与调度器说再见!
除了此产品之外,我们还将提供付费托管版本,其中包括:
设置数据库以启用 CDC 并提供连接器以读取消息并将消息发布到 Kafka
提供托管版本的 Artie Transfer
最后,我们认为 OLTP 和 OLAP 数据库之间接近零复制滞后应该成为常态,并且应该可以广泛访问。因此,我们有开源的Artie Transfer!
Artie Transfer Github开源地址:https://github.com/artie-labs/transfer
文章来源:https://www.postgresql.org/about/news/artie-transfer-release-sub-minute-data-transfer-from-postgres-to-snowflake-2581/
