





大家好, 继上一篇为大家介绍了如何查看PG的SQL历史和实时计划之后,本篇继续介绍一下如何固定SQL的执行计划。
对于维护生产数据库的小伙伴来说,80%的数据库故障源于运行项目中的SQL本身,如果SQL能够拥有稳定合理的执行计划,那么生产数据库就能保持稳定运行。
熟悉ORACLE的小伙伴都知道,无论从五环八门的hint 种类来说, 还是ORACLE从最早的9i 中的 Store Outline, 到10g的SQL profile 再到11g的 SPM (SQL plan management)
可见业内RDBMS旗舰产品一直在进化自己固定执行计划的功能。
PG 作为功能最强大的开源数据库,虽然原生PG并不支持,但是背后依托强大的插件机制和PG系数据库定制,你依然可以找到类似于替换的方案:
Oracle hint -> PG extension pg_hint_plan
Oracle Outline -> PG extension pg_plan_guarantee
Oracle SPM -> AWS Aurora PostgreSQL 的 Query Plan Management (QPM)
我们先来看一下PG官方是否打算开发hint 功能, PG的学院派官方并不打算在原生的代码中加入hint 的功能: 理由是在其他数据库中(oracle和mysql) 中已经实现了, 我们对此并不感兴趣了。
很real 的答案。

虽然官方不支持,幸好还有强大第三方插件 pg_hint_plan :
Github 的首页地址: https://github.com/ossc-db/pg_hint_plan 来自于一家日本的公司(NTT)
下载的时候需要注意版本的问题: 我们测试的版本是 PG15 , 对应的兼容版本是 pg_hint_plan15 1.5。
每个PG版本都需要下载独立的pg_hint_plan: 比如 PG13 需要 pg_hint_plan13 1.3.8, PG14 需要 pg_hint_plan14 1.4.1
下载版本: pg_hint_plan15 1.5
INFRA [postgres@wqdcsrv3352 postgreSQL]# wget https://github.com/ossc-db/pg_hint_plan/archive/refs/tags/REL15_1_5_0.tar.gz
下载后的压缩包很小,只有196KB
INFRA [postgres@wqdcsrv3352 postgreSQL]# ls -lhtr | grep REL15_1_5_0.tar.gz
-rw------- 1 postgres postgres 196K Jan 30 17:09 REL15_1_5_0.tar.gz
我们来解压安装一下:
INFRA [postgres@wqdcsrv3352 postgreSQL]# tar -xvf REL15_1_5_0.tar.gz
INFRA [postgres@wqdcsrv3352 postgreSQL]# cd pg_hint_plan-REL15_1_5_0
INFRA [postgres@wqdcsrv3352 pg_hint_plan-REL15_1_5_0]# make
gcc -std=gnu99 -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -O2 -fPIC -I. -I./ -I/opt/postgreSQL/pg15/include/postgresql/server -I/opt/postgreSQL/pg15/include/postgresql/internal -D_GNU_SOURCE -c -o pg_hint_plan.o pg_hint_plan.c
gcc -std=gnu99 -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -O2 -fPIC pg_hint_plan.o -L/opt/postgreSQL/pg15/lib -Wl,--as-needed -Wl,-rpath,'/opt/postgreSQL/pg15/lib',--enable-new-dtags -shared -o pg_hint_plan.so
INFRA [postgres@wqdcsrv3352 pg_hint_plan-REL15_1_5_0]# make install
/bin/mkdir -p '/opt/postgreSQL/pg15/share/postgresql/extension'
/bin/mkdir -p '/opt/postgreSQL/pg15/share/postgresql/extension'
/bin/mkdir -p '/opt/postgreSQL/pg15/lib/postgresql'
/bin/install -c -m 644 .//pg_hint_plan.control '/opt/postgreSQL/pg15/share/postgresql/extension/'
/bin/install -c -m 644 .//pg_hint_plan--1.3.0.sql .//pg_hint_plan--1.3.0--1.3.1.sql .//pg_hint_plan--1.3.1--1.3.2.sql .//pg_hint_plan--1.3.2--1.3.3.sql .//pg_hint_plan--1.3.3--1.3.4.sql .//pg_hint_plan--1.3.5--1.3.6.sql .//pg_hint_plan--1.3.4--1.3.5.sql .//pg_hint_plan--1.3.6--1.3.7.sql .//pg_hint_plan--1.3.7--1.3.8.sql .//pg_hint_plan--1.3.8--1.4.sql .//pg_hint_plan--1.4--1.4.1.sql .//pg_hint_plan--1.4.1--1.5.sql '/opt/postgreSQL/pg15/share/postgresql/extension/'
/bin/install -c -m 755 pg_hint_plan.so '/opt/postgreSQL/pg15/lib/postgresql/'
下面我们执行一个SQL: 我们可以看到执行计划中 表之间的连接方式是Nested Loop ,表的访问方式是 Index Scan
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
pgbench@[local:/tmp]:1992=#8511 load 'auto_explain';
LOAD
pgbench@[local:/tmp]:1992=#8511 set auto_explain.log_min_duration = 0;
SET
pgbench@[local:/tmp]:1992=#8511 set client_min_messages = log;
SET
pgbench@[local:/tmp]:1992=#8511 SELECT *
pgbench-# FROM pgbench_branches b
pgbench-# JOIN pgbench_accounts a ON b.bid = a.bid
pgbench-# ORDER BY a.aid;
LOG: duration: 1428.874 ms plan:
Query Text: SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
Nested Loop (cost=0.57..118918.94 rows=1600826 width=461)
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts a (cost=0.43..80219.93 rows=1600826 width=97)
-> Memoize (cost=0.15..0.16 rows=1 width=364)
Cache Key: a.bid
Cache Mode: logical
-> Index Scan using pgbench_branches_pkey on pgbench_branches b (cost=0.14..0.15 rows=1 width=364)
Index Cond: (bid = a.bid)
下面我们使用 hint 修改表连接方式为HashJoin, 表的访问方式为 Seq Scan
这里注意与ORACLE的HINT 所在位置不一样,PG的HINT的位置是 SQL语句的最前面,一个注释的代码块里面:
/+ HashJoin(a b) SeqScan(a) SeqScan(b)/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
pgbench@[local:/tmp]:1992=#14342 /*+ HashJoin(a b) SeqScan(a) SeqScan(b)*/
pgbench-# SELECT *
pgbench-# FROM pgbench_branches b
pgbench-# JOIN pgbench_accounts a ON b.bid = a.bid
pgbench-# ORDER BY a.aid;
LOG: temporary file: path "base/pgsql_tmp/pgsql_tmp15324.0", size 58384384
LOG: temporary file: path "base/pgsql_tmp/pgsql_tmp15323.0", size 59637760
LOG: duration: 1517.595 ms plan:
Query Text: /*+ HashJoin(a b) SeqScan(a) SeqScan(b)*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
Gather Merge (cost=403460.65..559107.41 rows=1334022 width=461)
Workers Planned: 2
-> Sort (cost=402460.62..404128.15 rows=667011 width=461)
Sort Key: a.aid
-> Hash Join (cost=31.36..43115.87 rows=667011 width=461)
Hash Cond: (a.bid = b.bid)
-> Parallel Seq Scan on pgbench_accounts a (cost=0.00..33913.11 rows=667011 width=97)
-> Hash (cost=31.16..31.16 rows=16 width=364)
-> Seq Scan on pgbench_branches b (cost=0.00..31.16 rows=16 width=364)
LOG: temporary file: path "base/pgsql_tmp/pgsql_tmp14342.0", size 66461696
LOG: duration: 1523.931 ms statement: /*+ HashJoin(a b) SeqScan(a) SeqScan(b)*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
pg_hint_plan 这个插件,不需要 执行create extension 这个命令。 (create extension 的情况下有另外一种使用场景,最后我们会介绍一下)
同样支持 session 生效的方式 load 和 global 生效的方式 修改参数 shared_preload_libraries(重启生效)
如何知道 pg_hint_plan 支持多少种类型的hint 呢?
Github 上下载的源码压缩包中有具体说明的网页 : pg_hint_plan-REL15_1_5_0/doc/hint_list.html
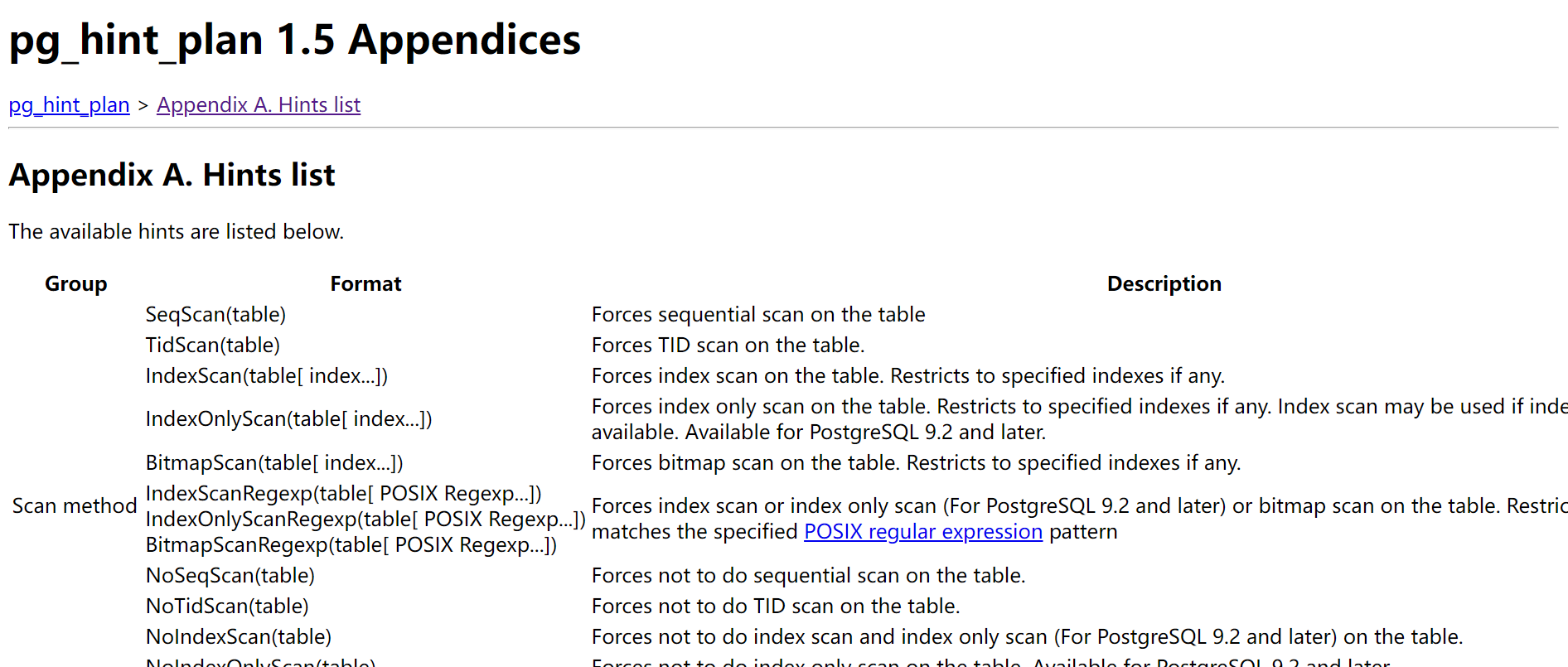
总结起来有如下几大类:
扫描方式相关的 (Scan method)
表连接方式相关的(Join method)
表连接顺序相关的( Join order)
表的基数相关的,类似于oracle中的 cardinality(Row number correction)
并行查询参数相关的( Parallel query configuration)
参数设置相关 Set(GUC-param value)
内存化连接的inner table (Behavior control on Join)
我们来分别体验一下:
扫描方式相关的 (Scan method): 测试 SeqScan, NoIndexOnlyScan
原始SQL:
pgbench@[local:/tmp]:1992=#97268 select * from pgbench_branches where bid = 1;
LOG: duration: 0.036 ms plan:
Query Text: select * from pgbench_branches where bid = 1;
Index Scan using pgbench_branches_pkey on pgbench_branches (cost=0.14..8.17 rows=1 width=364)
Index Cond: (bid = 1)
添加hint : SeqScan
pgbench@[local:/tmp]:1992=#97268 /*+ SeqScan(a)*/
pgbench-# select * from pgbench_branches a where bid = 1;
LOG: duration: 0.057 ms plan:
Query Text: /*+ SeqScan(a)*/
select * from pgbench_branches a where bid = 1;
Seq Scan on pgbench_branches a (cost=0.00..31.20 rows=1 width=364)
Filter: (bid = 1)
原始SQL:
pgbench@[local:/tmp]:1992=#97268 select bid from pgbench_branches a where bid > 0;
LOG: duration: 0.026 ms plan:
Query Text: select bid from pgbench_branches a where bid > 0;
Index Only Scan using pgbench_branches_pkey on pgbench_branches a (cost=0.14..8.41 rows=16 width=4)
Index Cond: (bid > 0)
添加hint : NoIndexOnlyScan
pgbench@[local:/tmp]:1992=#97268 /*+ NoIndexOnlyScan(a)*/
pgbench-# select bid from pgbench_branches a where bid > 0;
LOG: duration: 0.092 ms plan:
Query Text: /*+ NoIndexOnlyScan(a)*/
select bid from pgbench_branches a where bid > 0;
Seq Scan on pgbench_branches a (cost=0.00..31.20 rows=16 width=4)
Filter: (bid > 0)
表连接方式相关的(Join method): 这里涵盖了PG主要的几种连接方式 NestLoop, HashJoin, MergeJoin
添加 hint (NestLoop) : pgbench_branches 作为inner 的内部表 cache到内存中(只有16条记录的小表),与outer table pgbench_accounts (1600000条记录)进行嵌套连接
pgbench@[local:/tmp]:1992=#97268 /*+ NestLoop(a b)*/
pgbench-# SELECT *
pgbench-# FROM pgbench_branches b
pgbench-# JOIN pgbench_accounts a ON b.bid = a.bid
pgbench-# ORDER BY a.aid;
LOG: duration: 1447.723 ms plan:
Query Text: /*+ NestLoop(a b)*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
Nested Loop (cost=0.57..118918.94 rows=1600826 width=461)
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts a (cost=0.43..80219.93 rows=1600826 width=97)
-> Memoize (cost=0.15..0.16 rows=1 width=364)
Cache Key: a.bid
Cache Mode: logical
-> Index Scan using pgbench_branches_pkey on pgbench_branches b (cost=0.14..0.15 rows=1 width=364)
Index Cond: (bid = a.bid)
LOG: duration: 1448.326 ms statement: /*+ NestLoop(a b)*/
添加 hint HashJoin: 同样是小表的 pgbench_branches 作为hash join 的驱动表
pgbench@[local:/tmp]:1992=#97268 /*+ HashJoin(a b)*/
pgbench-# SELECT *
pgbench-# FROM pgbench_branches b
pgbench-# JOIN pgbench_accounts a ON b.bid = a.bid
pgbench-# ORDER BY a.aid;
LOG: duration: 2037.850 ms plan:
Query Text: /*+ HashJoin(a b)*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
Sort (cost=921120.72..925122.78 rows=1600826 width=461)
Sort Key: a.aid
-> Hash Join (cost=31.36..48597.87 rows=1600826 width=461)
Hash Cond: (a.bid = b.bid)
-> Seq Scan on pgbench_accounts a (cost=0.00..43251.26 rows=1600826 width=97)
-> Hash (cost=31.16..31.16 rows=16 width=364)
-> Seq Scan on pgbench_branches b (cost=0.00..31.16 rows=16 width=364)
LOG: temporary file: path "base/pgsql_tmp/pgsql_tmp97268.2", size 184451072
LOG: duration: 2052.505 ms statement: /*+ HashJoin(a b)*/
添加 hint MergeJoin : merge join 一般作用于2个表连接条件的列上均存在索引,或者连接条件的列上最后返回的结果集需要进行排序
pgbench@[local:/tmp]:1992=#97268 /*+ MergeJoin(a b)*/
pgbench-# SELECT *
pgbench-# FROM pgbench_branches b
pgbench-# JOIN pgbench_accounts a ON b.bid = a.bid
pgbench-# ORDER BY a.bid,b.bid;
LOG: duration: 1583.642 ms plan:
Query Text: /*+ MergeJoin(a b)*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.bid,b.bid;
Merge Join (cost=290411.31..314423.78 rows=1600826 width=461)
Merge Cond: (a.bid = b.bid)
-> Sort (cost=383310.46..387312.53 rows=1600826 width=97)
Sort Key: a.bid
-> Seq Scan on pgbench_accounts a (cost=0.00..43251.26 rows=1600826 width=97)
-> Sort (cost=31.48..31.52 rows=16 width=364)
Sort Key: b.bid
-> Seq Scan on pgbench_branches b (cost=0.00..31.16 rows=16 width=364)
LOG: temporary file: path "base/pgsql_tmp/pgsql_tmp97268.3", size 171589632
表连接顺序相关的( Join order): Leading
这个hint需要注意一下,当表的连接个数查过2个的时候,比如 Leading (a b c) 这个的含义 并不等于 a->b->c
正确的写法是 Leading (((a b) c)): 需要用小括号来固定一下:
原始SQL: 表的连接顺序是 b-> c-> a 优化器选择一张最小的表 b 作为驱动表
Query Text: SELECT count(1)
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
JOIN pgbench_tellers c ON b.bid = c.bid;
Aggregate (cost=267421.73..267421.74 rows=1 width=8)
-> Hash Join (cost=54.83..227401.08 rows=16008260 width=0)
Hash Cond: (a.bid = b.bid)
-> Seq Scan on pgbench_accounts a (cost=0.00..43251.26 rows=1600826 width=4)
-> Hash (cost=52.83..52.83 rows=160 width=8)
-> Nested Loop (cost=0.15..52.83 rows=160 width=8)
-> Seq Scan on pgbench_tellers c (cost=0.00..45.60 rows=160 width=4)
-> Memoize (cost=0.15..0.21 rows=1 width=4)
Cache Key: c.bid
Cache Mode: logical
-> Index Only Scan using pgbench_branches_pkey on pgbench_branches b (cost=0.14..0.20 rows=1 width=4)
Index Cond: (bid = c.bid)
我们使用HINT修改一下表的连接顺序:Leading(((c a) b)): c-> a-> b
Query Text: /*+ Leading(((c a) b))*/
SELECT count(1)
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
JOIN pgbench_tellers c ON b.bid = c.bid;
Aggregate (cost=349860.63..349860.64 rows=1 width=8)
-> Hash Join (cost=69524.16..309839.98 rows=16008260 width=0)
Hash Cond: (a.bid = b.bid)
-> Hash Join (cost=69515.59..256678.99 rows=16008260 width=8)
Hash Cond: (c.bid = a.bid)
-> Seq Scan on pgbench_tellers c (cost=0.00..45.60 rows=160 width=4)
-> Hash (cost=43251.26..43251.26 rows=1600826 width=4)
-> Seq Scan on pgbench_accounts a (cost=0.00..43251.26 rows=1600826 width=4)
-> Hash (cost=8.38..8.38 rows=16 width=4)
-> Index Only Scan using pgbench_branches_pkey on pgbench_branches b (cost=0.14..8.38 rows=16 width=4)
表的基数相关的,类似于oracle中的 cardinality(Row number correction):
修改表的cardinality, Cardinality 是个十分重要的因素,可以直接影响到执行计划。 之前很多ORACLE的SQL优化都是基于cardinality 的优化
原始SQL: 连接方式是 Nested loop, 因为表 pgbench_branches b 是个只有16行的小表
Query Text: SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
Nested Loop (cost=0.57..118918.94 rows=1600826 width=461)
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts a (cost=0.43..80219.93 rows=1600826 width=97)
-> Memoize (cost=0.15..0.16 rows=1 width=364)
Cache Key: a.bid
Cache Mode: logical
-> Index Scan using pgbench_branches_pkey on pgbench_branches b (cost=0.14..0.15 rows=1 width=364)
Index Cond: (bid = a.bid)
我们现在 添加hint 把pgbench_accounts a 这个的rows 设置为 1: (之前是1600826 )
我们看到表的连接当时变成了hash join , pgbench_accounts a 也变成了 Seq scan 的方式
pgbench@[local:/tmp]:1992=#20579 /*+ Rows(b a #1)*/
pgbench-# SELECT *
pgbench-# FROM pgbench_branches b
pgbench-# JOIN pgbench_accounts a ON b.bid = a.bid
pgbench-# ORDER BY a.aid;
LOG: duration: 2015.260 ms plan:
Query Text: /*+ Rows(b a #1)*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
Sort (cost=48597.93..48597.93 rows=1 width=461)
Sort Key: a.aid
-> Hash Join (cost=31.36..48597.87 rows=1 width=461)
Hash Cond: (a.bid = b.bid)
-> Seq Scan on pgbench_accounts a (cost=0.00..43251.26 rows=1600826 width=97)
-> Hash (cost=31.16..31.16 rows=16 width=364)
-> Seq Scan on pgbench_branches b (cost=0.00..31.16 rows=16 width=364)
并行查询参数相关的( Parallel query configuration): Parallel(a 8 soft|hard)
soft 选项是 相当于设置了参数 max_parallel_worker_per_gather, 然后去让优化器去实际的分配 worker的数量
hard 选项是 强制分配worker的数量
Parallel(a 8 soft) --》 Workers Planned: 3
Query Text: /*+ HashJoin(a b) Parallel(a 8 soft)*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
Gather Merge (cost=279990.89..463311.12 rows=1549185 width=461)
Workers Planned: 3
-> Sort (cost=278990.85..280281.84 rows=516395 width=461)
Sort Key: a.aid
-> Hash Join (cost=31.36..1745.96 rows=516395 width=461)
Hash Cond: (a.bid = b.bid)
-> Parallel Seq Scan on pgbench_accounts a (cost=0.00..0.00 rows=516395 width=97)
-> Hash (cost=31.16..31.16 rows=16 width=364)
-> Seq Scan on pgbench_branches b (cost=0.00..31.16 rows=16 width=364)
Parallel(a 8 hard) --》Workers Planned: 8
Query Text: /*+ HashJoin(a b) parallel(a 8 hard)*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
Gather Merge (cost=107764.93..305726.23 rows=1600824 width=461)
Workers Planned: 8
-> Sort (cost=106764.79..107265.04 rows=200103 width=461)
Sort Key: a.aid
-> Hash Join (cost=31.36..695.76 rows=200103 width=461)
Hash Cond: (a.bid = b.bid)
-> Parallel Seq Scan on pgbench_accounts a (cost=0.00..0.00 rows=200103 width=97)
-> Hash (cost=31.16..31.16 rows=16 width=364)
-> Seq Scan on pgbench_branches b (cost=0.00..31.16 rows=16 width=364)
参数设置相关 Set(GUC-param value):
相当于session 级别修改了参数的默认值
缩小 work_mem和 temp_buffers 为2MB: 我们可以看到产生了临时文件:
LOG: temporary file: path “base/pgsql_tmp/pgsql_tmp63027.0”, size 55083008
LOG: temporary file: path “base/pgsql_tmp/pgsql_tmp63028.0”, size 51871744
pgbench@[local:/tmp]:1992=#54795 /*+ Set(work_mem 2MB)
pgbench*# Set(temp_buffers 2MB)*/
pgbench-# SELECT *
pgbench-# FROM
pgbench-# pgbench_accounts a order by a.bid;
LOG: temporary file: path "base/pgsql_tmp/pgsql_tmp63027.0", size 55083008
LOG: temporary file: path "base/pgsql_tmp/pgsql_tmp63028.0", size 51871744
LOG: duration: 1051.854 ms plan:
Query Text: /*+ Set(work_mem 2MB)
Set(temp_buffers 2MB)*/
SELECT *
FROM
pgbench_accounts a order by a.bid;
Gather Merge (cost=137889.63..293536.39 rows=1334022 width=97)
Workers Planned: 2
-> Sort (cost=136889.60..138557.13 rows=667011 width=97)
Sort Key: bid
-> Parallel Seq Scan on pgbench_accounts a (cost=0.00..33913.11 rows=667011 width=97)
hint 设置参数 为 64MB: Set(temp_buffers 64MB)Set(work_mem 64MB)
我们看到无需临时文件的产生。
pgbench@[local:/tmp]:1992=#54795 /*+ Set(work_mem 64MB)
pgbench*# Set(temp_buffers 64MB)*/
pgbench-# SELECT *
pgbench-# FROM
pgbench-# pgbench_accounts a order by a.bid;
LOG: duration: 1343.024 ms plan:
Query Text: /*+ Set(work_mem 64MB)
Set(temp_buffers 64MB)*/
SELECT *
FROM
pgbench_accounts a order by a.bid;
Sort (cost=202833.93..206836.00 rows=1600826 width=97)
Sort Key: bid
-> Seq Scan on pgbench_accounts a (cost=0.00..43251.26 rows=1600826 width=97)
内存化连接的inner table (Behavior control on Join):
原始SQL: 观察执行计划中
-> Memoize (cost=0.15…0.16 rows=1 width=364)
Cache Key: a.bid
Cache Mode: logical
缓存了inner table (pgbench_branches) 的结果集, 加快了 Nested loop的速度。
pgbench@[local:/tmp]:1992=#54795 SELECT *
pgbench-# FROM pgbench_branches b
pgbench-# JOIN pgbench_accounts a ON b.bid = a.bid
pgbench-# ORDER BY a.aid;
LOG: duration: 1471.256 ms plan:
Query Text: SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
Nested Loop (cost=0.57..118918.94 rows=1600826 width=461)
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts a (cost=0.43..80219.93 rows=1600826 width=97)
-> Memoize (cost=0.15..0.16 rows=1 width=364)
Cache Key: a.bid
Cache Mode: logical
-> Index Scan using pgbench_branches_pkey on pgbench_branches b (cost=0.14..0.15 rows=1 width=364)
Index Cond: (bid = a.bid)
我们使用hint 去掉 缓存inner table (pgbench_branches) 的结果集: /+ NoMemoize(a b)/
我们看到由于没有缓存小表的结果集, 这个 NESTED LOOP 就变成了每一条都去loop 一下, 执行效率会慢很多。
inner table pgbench_branches 仅仅只有16 条的数据情况下,对比还是很明显的:
Memoize Innner table : duration: 1471.256 ms
NoMemoize Innner table : duration: 2124.444 ms
pgbench@[local:/tmp]:1992=#54795 /*+ NoMemoize(a b)*/
pgbench-# SELECT *
pgbench-# FROM pgbench_branches b
pgbench-# JOIN pgbench_accounts a ON b.bid = a.bid
pgbench-# ORDER BY a.aid;
LOG: duration: 2124.444 ms plan:
Query Text: /*+ NoMemoize(a b)*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
Nested Loop (cost=0.56..323043.40 rows=1600826 width=461)
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts a (cost=0.43..80219.93 rows=1600826 width=97)
-> Index Scan using pgbench_branches_pkey on pgbench_branches b (cost=0.14..0.15 rows=1 width=364)
Index Cond: (bid = a.bid)
我们再来看一下pg_hint_plan 对于 subquery 的支持:
对于子查询的语句块:hint中必须要使用别名 ANY_subquery
IN (SELECT … {LIMIT | OFFSET …} …)
= ANY (SELECT … {LIMIT | OFFSET …} …)
= SOME (SELECT … {LIMIT | OFFSET …} …)
原始SQL的语句:
pgbench@[local:/tmp]:1992=#130849 SELECT *
pgbench-# FROM pgbench_accounts a1
pgbench-# WHERE aid IN (SELECT bid FROM pgbench_accounts a2 LIMIT 10);
LOG: duration: 0.068 ms plan:
Query Text: SELECT *
FROM pgbench_accounts a1
WHERE aid IN (SELECT bid FROM pgbench_accounts a2 LIMIT 10);
Merge Semi Join (cost=1.25..2.15 rows=10 width=97)
Merge Cond: (a1.aid = a2.bid)
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts a1 (cost=0.43..80219.93 rows=1600826 width=97)
-> Sort (cost=0.54..0.56 rows=10 width=4)
Sort Key: a2.bid
-> Limit (cost=0.00..0.27 rows=10 width=4)
-> Seq Scan on pgbench_accounts a2 (cost=0.00..43251.26 rows=1600826 width=4)
我们在hint 中指定 子查询的语句的别名 ANY_subquery:
pgbench@[local:/tmp]:1992=#130849 /*+HashJoin(a1 ANY_subquery)*/
pgbench-# SELECT *
pgbench-# FROM pgbench_accounts a1
pgbench-# WHERE aid IN (SELECT bid FROM pgbench_accounts a2 LIMIT 10);
LOG: duration: 192.251 ms plan:
Query Text: /*+HashJoin(a1 ANY_subquery)*/
SELECT *
FROM pgbench_accounts a1
WHERE aid IN (SELECT bid FROM pgbench_accounts a2 LIMIT 10);
Hash Semi Join (cost=0.50..47454.03 rows=10 width=97)
Hash Cond: (a1.aid = a2.bid)
-> Seq Scan on pgbench_accounts a1 (cost=0.00..43251.26 rows=1600826 width=97)
-> Hash (cost=0.37..0.37 rows=10 width=4)
-> Limit (cost=0.00..0.27 rows=10 width=4)
-> Seq Scan on pgbench_accounts a2 (cost=0.00..43251.26 rows=1600826 width=4)
Okay, 上面我们介绍了pg_hint_plan的基本使用方式。
添加这些hint, 都是需要修改SQL语句的, 有没有一种方法可以在不修改SQL的情况下, 为正在运行的SQL 添加hint 来改变执行计划?
答案是肯定的。
下面我们来看一个例子: 我们需要创建 extension : 目的是创建表 hint_plan.hints
--创建表 hint_plan.hints
pgbench@[local:/tmp]:1992=#54795 CREATE EXTENSION pg_hint_plan;
CREATE EXTENSION
-- 打开此功能
pgbench@[local:/tmp]:1992=#54795 SET pg_hint_plan.enable_hint_table = on;
SET
pgbench@[local:/tmp]:1992=#54795 \d hint_plan.hints
Table "hint_plan.hints"
Column | Type | Collation | Nullable | Default
-------------------+---------+-----------+----------+---------------------------------------------
id | integer | | not null | nextval('hint_plan.hints_id_seq'::regclass)
norm_query_string | text | | not null |
application_name | text | | not null |
hints | text | | not null |
Indexes:
"hints_pkey" PRIMARY KEY, btree (id)
"hints_norm_and_app" UNIQUE, btree (norm_query_string, application_name)
我们把一条简单的SQL语句: 原本是触发索引访问的SQL ‘select * from pgbench_branches a where bid = ?;’ 插入到 hint_plan.hints中,使其使用hint 文本: SeqScan(a)
Query Text: INSERT INTO hint_plan.hints
(norm_query_string,
application_name,
hints)
VALUES
('select * from pgbench_branches a where bid = ?;',
'',
'SeqScan(a)');
INSERT 0 1
我们再次执行一下这个SQL: select * from pgbench_branches a where bid = 100;
我们发现 开启pg_hint_plan.enable_hint_table = on; 这个功能后, SQL会首先访问表 hint_plan.hints: 查看是否有绑定的hint
SELECT hints FROM hint_plan.hints WHERE norm_query_string = $1 AND ( application_name = $2 OR application_name = ‘’ ) ORDER BY application_name DESC
如果存在的话,则使用该hint, 返回的执行计划是 Seq Scan on pgbench_branches a , 符合预期。
pgbench@[local:/tmp]:1992=#54795 select * from pgbench_branches a where bid = 100;
LOG: duration: 0.036 ms plan:
Query Text: SELECT hints FROM hint_plan.hints WHERE norm_query_string = $1 AND ( application_name = $2 OR application_name = '' ) ORDER BY application_name DESC
Sort (cost=11.35..11.35 rows=1 width=64)
Sort Key: application_name DESC
-> Bitmap Heap Scan on hints (cost=4.17..11.30 rows=1 width=64)
Recheck Cond: (norm_query_string = $1)
Filter: ((application_name = $2) OR (application_name = ''::text))
-> Bitmap Index Scan on hints_norm_and_app (cost=0.00..4.17 rows=3 width=0)
Index Cond: (norm_query_string = $1)
LOG: duration: 0.033 ms plan:
Query Text: select * from pgbench_branches a where bid = 100;
Seq Scan on pgbench_branches a (cost=0.00..31.20 rows=1 width=364)
Filter: (bid = 100)
bid | bbalance | filler
-----+----------+--------
(0 rows)
如果不想使用该功能,关闭即可:
pgbench@[local:/tmp]:1992=#54795 SET pg_hint_plan.enable_hint_table = off;
SET
pgbench@[local:/tmp]:1992=#54795 select * from pgbench_branches a where bid = 100;
LOG: duration: 0.016 ms plan:
Query Text: select * from pgbench_branches a where bid = 100;
Index Scan using pgbench_branches_pkey on pgbench_branches a (cost=0.14..8.17 rows=1 width=364)
最后我们总结一下:
1)PG的第三方插件pg_hint_plan 的支持hint 的类型主要有如下几大类:
扫描方式相关的 (Scan method)
表连接方式相关的(Join method)
表连接顺序相关的( Join order)
表的基数相关的,类似于oracle中的 cardinality(Row number correction)
并行查询参数相关的( Parallel query configuration)
参数设置相关 Set(GUC-param value)
内存化连接的inner table (Behavior control on Join)
2)PG 的pg_hint_plan 插件中 hint 的一些写法 与 ORACLE是不同的:
a) 需要写在代码块的第一行
/*+ hint statement */
SQL statement
b) Hint Leading 的写法 需要里面用小括号再次包装一层: 比如 a->b : Leading ((a b)) , a->b->c : Leading(((a b) c))
c)Hint 中指定表的别名之大小写敏感的, 比如SQL语句中表的别名 Tbl 与 hint 中的别名TBL 是不匹配的
3)我们可以在不修改SQL语句的情况下,为SQL预计绑定hint , 从而达到改变SQL执行计划的目的。
这个对于生产库运维的小伙伴来说,在十万火急的情况下, 是一种快速解决问题的方式。
先解决问题,才能有更多的时间分析SQL执行不正确的根本原因: 到底是统计信息不准确? 修改/禁用了某些参数? 优化器的BUG?
如果你能联系到相关开发人员,改写合理的SQL才是解决问题的根本途径。
Have a fun 🙂 !
