




如果你已经运行过PostgreSQL,你一定就听说过autovacuum。是的,autovacuum,一个每个人都教你不要关掉,一个被用来保持数据库干净并自动减少膨胀的东西。
可是-想象一下:晴朗的一天,你看到数据库的大小比你期望的要大,数据库的IO负载已经增长,负载上没有任何调整,速度也变慢了。你开始调查发生了什么。你运行优秀的膨胀查询语句。然后你发现你有很多膨胀。那么在你的postgres数据库,你手动运行VACCUM来清除膨胀。 这很棒!
随后,你对房间的大象讲道:为什么Postgres的autovacuum没有第一时间清理膨胀?上面的故事听起来很熟悉,是不是?好,你不是一个人。
Autovacuum和Vacuum提供了一串设置参数去调整,以适应你的负载,但挑战在于确定要调整哪些。在这篇文章-基于我的optimizing autovacuum中谈了Citus Con:An Event for Postgres-你将学会找出问题所在,以及如何调整以使其更好。
更具体地说,你会学着怎么排查-怎么修复这三个常见的autovacuum问题:
问题1:Autovacuum没有足够地触发vacuum
问题2:Vacuum太慢了
问题3:Vacuum没有清查失效行
autovacuum另一个常见的问题是关于事务ID回卷相关的,对postgres来说,本来就是一个很重要的话题。未来,我打处写一篇单独写一篇关于那个话题的后续文章。
纵观这篇博文的13个autovacuum贴士
这个autovacuum贴士的备忘录能让你看到这篇博文中postgres的所有autovacuum问题修复的概览。
调试postgres Autovacuum的备忘录
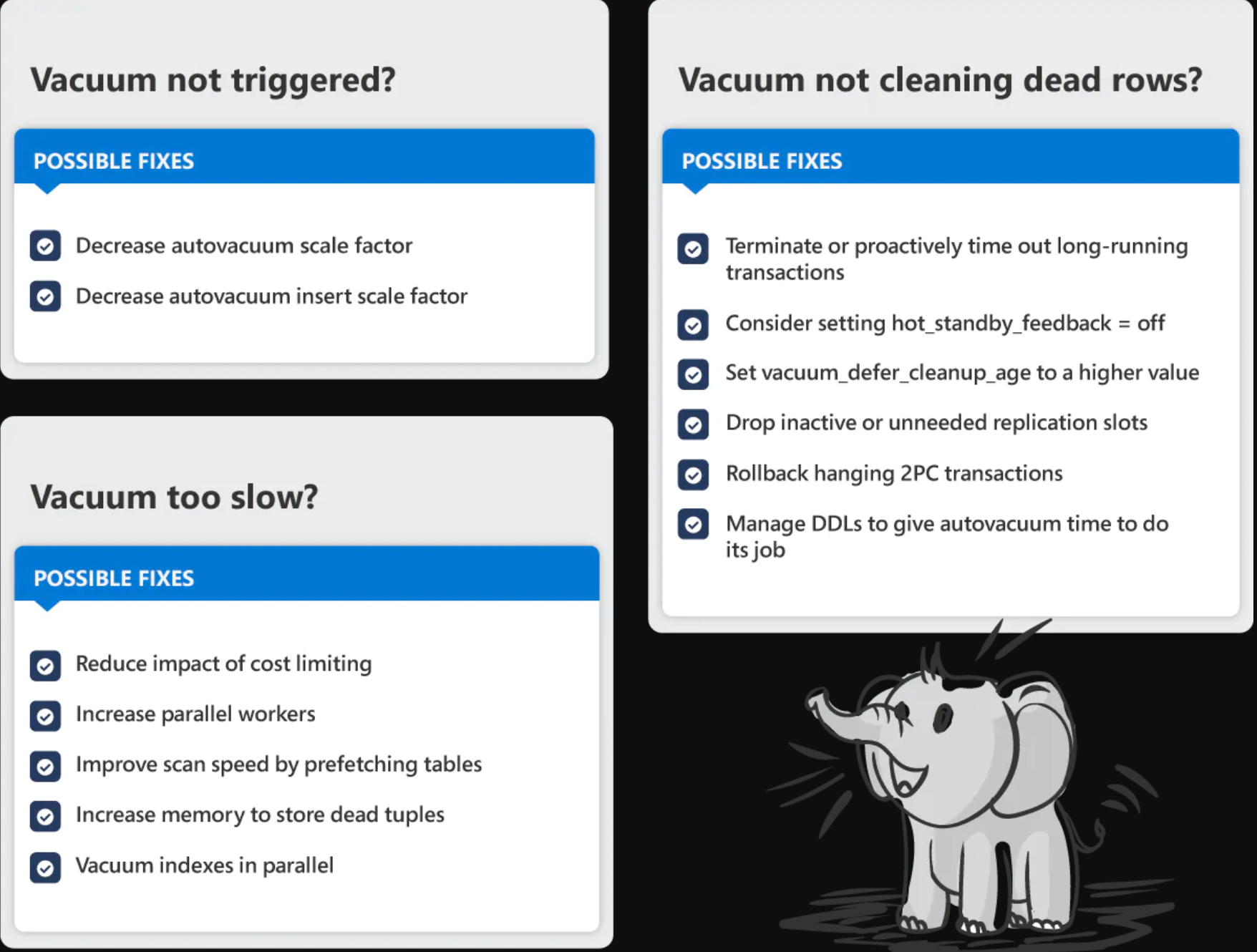
图1: Postgres中3种最常见的autovacuum问题的13种不同类型的autovacuum修复方法示意图
Autovacuum介绍
如果你还不熟悉,当并发访问数据时,Postgres使用多路并发控制(MVCC)事保障隔离性。这也意味着在数据库中会同时存在一行多个版本。所以,当行被删除时,旧版本仍然保留着,以防旧事务还会访问这些版本。
一旦所有需要这一行的事务完成,这些行就会被移除。这就是VACUUM做的事。现在,VACUUM可以手动运行而不需要你去监控,也不需要对各类的事做决定,如:什么时候运行vacuum,哪一张表需要vacuum,vacuum多久跑一次等。
为了让你的生活更简单,PostgreSQL有一个autovacuum工具:
每autovacuum_naptime秒唤醒
检查那些已经"显著修改"的表
在这些表上开启更多的worker进程去进行VACUUM和ANALYZE工作。
总体来说,从 Joe Nelson不错的博文"为什么Autovacuum不是敌人"中,你能学到更多关于autovacuum的知识。
现在,在上面提到的第2项“显著修改”的定义—并行时需要VACUUM的数量—很大程度上取决于你的工作负载,事务频率和硬件。我们从最平常一个autovacuum问题着手研究调试autovacuum—autovacuum未“显著修改”vacumm的表。
问题1:Autovacuum不会经常触发vacuum
对表来说,如果非事务id回卷相关,Vacuum通常会被触发
过期的元组>
autovacuum_vacuum_threshold+autovacuum_vacuum_scale_factor* 元组数量或插入元组的数> autovacuum_vacuum_insert_threshold
+autovacuum_vacuum_insert_scale_factor* 元组数量
如果你发现膨胀增长远远超过所期望的且你需要手动运行VACUUM清理膨胀,这其实是一种暗示,autovacuum没有经常对表vacuum。
你可通过通过表pg_stat_user_tables检查表何时被vacuum过,vacuum的频率是多少。如果你的大表以低自动vacuum数量显示,并且以前last_autovacuum运行的很好,那是另一种迹象,表明autovacuum并没有在正确的时间vacuum你的表。
SELECT last_autovacuum, autovacuum_count, vacuum_count FROM
pg_stat_user_tables;复制
为了vacuum表以正确的频率,你该基于表大小和表的增长速率来调整autovacuum_vacuum_scale_factor 和autovacuum_vacuum_insert_scale_factor。
作为一个示例,一张表有1B的行,默认的比例因子会在表的行数变化至200M时触发vacuum,这是相当大的膨胀了。
为了使其达到更合理的值,根据变化率和大小,将其设置为0.02甚至0.002可能更明智。
问题2:Vacuum太慢
你也许会遇到第2个问题,vacuum的表太慢。这表明膨胀的增长是因为你清理膨胀的速度慢于你的事务速度。或者,你在系统里检查pg_stat_activity时会发现vacuum进程一直在运行。
有许多方法可以加快vacuum:这些建议可以用在自动vacuum和手动触发VACUUM.
减少cost limiting的影响
首先你该检查你是否设置允许cost liming。当vacuum在运行时,系统维护一个计数器,跟踪不同I/O操作的估计成本。当成本超过autovacuum_vacuum_cost_limit (或者 vacuum_cost_limit),进程会休眠 autovacuum_vacuum_cost_delay (或者vacuum_cost_delay) 毫秒。这称为cost limiting,用来减少vacuum在其他进程的影响。
如果你注意到vacuum正在下降,你可以disable cost limiting(设autovacuum_vacuum_cost_delay为0),要么通过减小autovacuum_vacuum_cost_delay或要么增加autovacuum_vacuum_cost_limit到一个更高值(如10000)来降低影响。
提高并行worker的数量
自动vacuum只能并行vacuum autovacuum_max_workers个表。所以,如果有数百个表正在被主动写入(并且需要vacuum),那么一次vacuum 3个表可能需要一段时间(3是autovacuum_max_workers的默认值)。
因此,在有大量的主动表的情况下,增加autovacuum_max_workers 到一个更高值也许是值得的-假设你有足够的预算来运行更多的自动vacuum worker。
在增加自动vacuum worker前,确认不会被cost limiting限制。Cost limit被所有活动的自动vacuum worker共享,所以只增加长并行worker的数量也许没有帮助,会使他们每个worker开始做更少的工作。
在怎么调试上想要更多的办法,也许有必要研究一下pg_stat_progressvacuum,以了解您正在进行的vaccum处理处于什么阶段,以及如何改进它们的性能。我们看一些例子,它也许会提供一些有用的见解。
通过预存和缓存提高扫描速度
要看到正在进行的vaccum有多快,你可以比较heap_blks_scanned和heap_blks_total在pg_stat_progress_vacuum表中的耗时。如果你看到进程缓慢并且phase是正在进行scanning heap,这意味着vacuum需要扫描大量堆块才能完成。
在这个例子里,你可以通过使用像pg_prewarm或者增加shared_buffers在内存中预取更大的表以便更快的扫描堆。
增加内存来存储更多的死元组
扫描堆时,vacuum在内存中收集死元组。死元组数量的收集取决于maintenance_work_mem(或者autovacuum_work_mem,如课设置了)。一旦元组的最大数量被收集,vacuum必定切换去vacuum索引,然后在索引和堆被vacuum后,再返回扫描堆(即在索引vacuum周期之后)。
所以,如果你注意到pg_stat_progress_vacuum表中的index_vacuum_count非常高,这意味着vacuum必须经历许多这样的索引清理周期。
为了减少清空周期需要使它更快,你可以增大autovacuum_work_mem以便在每个周期vacuum可以存储更多的死元组。
并行清理索引
如果看到pg_stat_progress_vacuum表的phase在vacuuming indexes很长时间,你该检查表上是否有很多索引被清理过。
如果有很多索引,你可通过增加max_parallel_maintenance_workers 并行处理索引使清理更快。注意,这个设置的改置只在你手动运行vaccum命令时有用(不幸地是,并行清理目前不支持自动清理)。
有了以上这些建议,你可以显著地加快清理的速度。但是,如果你的清理及时完成,你仍然注意到死元组没有降下来呢?在接下来的章节,我们将这新一类的问题尝试发现原因及解决办法:清理已经完成,但是没成清干净死行。
问题3:Vacuum没有清除掉死行
Vacuum只清除不再被事务需要的行版本。但是,如果Postgres认为确认的行仍然被“需要”,他们就不会被清除。
我们来探索4个vacuum不会清理行的常规场景(以及这些场景要怎么办)
长时间运行的事务
在备库上hot_standby_feedback = on长时间运行的事务
无用的复制槽
没有提交的预备事务
长时间运行的事务
如果有一个事务已经运行了好几个小时或好几天,这个事务也许保留了行,不允许vcuum清理这些行。你可通过运行以下SQL找到长运行事务:
SELECT pid, datname, usename,
state, backend_xmin
FROM pg_stat_activity
WHERE backend_xmin IS NOT NULL
ORDER BY age(backend_xmin) DESC;复制
为了阻止长运行事务阻塞vcuum运行,需要通过在PID上运行pg_terminate_backend() 来中断他们。
以积极主动的方式来处理长运行事务,可以
设置一个大的statement_timeout来自动过期长查询,或者
设置idle_in_transaction_session_timeout来过期那些在一个开放事务中空闲的会话,或者
设置log_min_duration_statement至少记录长时间运行查询以便可以在这些查询中设置预警并能手动kill他们。
在设置了 hot_standby_feedback = on的备库上的长运行查询
典型地,Postgres会尽快清理一个行版本在它对其他事务不可见时。如果你运行Postgres 在一主一备节点上,有可能在主节点上vacuum要清理的行正是备库查询需要的。这种情形称为"复制冲突"-并且当它被发现时,在备节点上的查询会被取消。
为防止在备库上的查询因为“复制冲突”被取消,可设置hot_standby_feedback = on,它会让备库通知主库最老的事务还在备库上运行。因此,主库可避免清理事务还正在备库上使用的行。
不管怎么说,设置hot_standby_feedback = on也意味着备库上长运行查询能阻塞在主库上清理的行。
获取所有备库的xmin范围,可运行:
SELECT pid, client_hostname,
state, backend_xmin
FROM pg_stat_replication
WHERE backend_xmin IS NOT NULL
ORDER BY age(backend_xmin) DESC;复制
为了避免主库因为备库上长运行事务导致的额外膨胀,可采取以下途径的其中一种:
继续处理“复制冲突”并且设置hot_standby_feedback = off。
设置vacuum_defer_cleanup_age 到更高值-为的是延迟主库上的行清理,直到vacuum_defer_cleanup_age事务过去,给备库更多的时间完成查询而不会遇到复制冲突。
最后,可追踪并中断备库上的长运行查询,就像我们上面讨论的主库在长运行事务的章节一样。
未用的复制槽
Postgres 的复制槽存储了副本追赶主库所需的信息。如果副本宕了,或者严重滞后,复制槽中的行无法在主库被清理。
当设置了hot_standby_feedback = on,额外的膨胀只会发生物理复制上。对于逻辑复制来说,你会看到膨胀只在目录表上。
你可以运行以下SQL来发现复制槽上仍保留的旧事务。
SELECT slot_name, slot_type,
database, xmin, catalog_xmin
FROM pg_replication_slots
ORDER BY age(xmin),
age(catalog_xmin) DESC;复制
一旦发现了它们,你可以运行pg_drop_replication_slot()删除不活动的或者不需要复制槽。你也可以应用在“在物理复制上如何管理hot_standby_feedback”部分学到的知识。
未提交的预备事务
Postgres支持两阶段提交(2PC),两阶段提交有两个不同的步骤。第一,事务通过PREPARE TRANSACTION 准备。第二,事务通过COMMIT PREPARED提交。
2PC是灵活的事务,意味着它允许服务重新启动。所以,如果你因为一些原因导致任何PREPARED事务遗留,他们也许会在行上锁住。可通过运行以下SQL发现旧的预备事务:
SELECT gid, prepared, owner,
database, transaction AS xmin
FROM pg_prepared_xacts
ORDER BY age(transaction) DESC;复制
可通过手动运行ROLLBACK PREPARED来移除hang住的2PC事务。
另一种可能性:重复Vacuum获得中断
Autovacuum知道它是一个系统进程并且它的优先级低于用户的查询。所以,如果一个进程被autovacuum触发,它是不可能获得它需要的锁来vacuum,进程会结束自己。这意味着,如果一个特定的表几乎一直有DDL在其上运行,vacuum也许不能获得需要的锁,因此过期的行不会被清除。
你是否注意到不能获得正确的锁导致膨胀增加,你必须做以下两件事中的其中一件:
手动VACUUM表(好消息是手动VACUUM不会自动结束进程自己)或者
管理好在那张表上的DDL任务,给autovacuum时间来清除过期行
在这个主题上你能发现的另一个有用的资源是 Laurenz Albe’s 的博客文章
[为什么不能从一张表上清除过期行的四个原因] https://www.cybertec-postgresql.com/en/reasons-why-vacuum-wont-remove-dead-rows/
Postgres autovacuum速查表
现在你已经了解了原因并且知道了在调试Postgres autovacuum问题上的13个提示,你就能处理这些问题:(1)autovacuum不是足够频繁触发Vacuum
或 (2)vacuum太慢
或 (3)vacuum没有清理过期行。
如果你已经试过了这些,autovacuum仍然没有跟上你的事务速度,那是时候升级你的Postgres服务到更大的硬件—或者用Citus扩展你的数据库到多节点。
下面,我纳入了一张参考表,这张表总结了我们在这篇文章提过的优化 autovacuum的不同的Postgres配置。
调试Postgres Autovacuum的配置参数

更改此配置可能会影响autovacuum以外的查询。要了解更多的含义,请参阅Postgres文档.
对超时的这些更改将应用于所有事务,而不仅仅是保留过期行的事务。
备注:你也许会遇到另一种类型的autovacuum问题和事务id回卷vacuum相关。这些是基于不同的标准触发的,其行为与常规vacuum不同。因此,他们也需要自己的一篇博文。不久我将在这篇文章的第2部分,主要聚集于什么是事务ID回卷autovacuum,是什么导致他们不同,并且当遇到他们在运行时,如何处理遇到的常规问题。继续优化!
我在Citus Con:An Event for Postgres上讲的Postgres都是关于优化autovacuum的。如果你有问题或反馈,你可以随时在Twitter上@samay_sharma联系我。
原文标题:Debugging Postgres autovacuum problems: 13 tips
原文作者:Samay Sharma
原文链接:https://www.citusdata.com/blog/2022/07/28/debugging-postgres-autovacuum-problems-13-tips/复制
