




在现实的生产环境中,有可能遇到高并发insert的应用.在此应用时由于堆表(Heap)和聚集表的结构不同导致在高并发的情形下insert效率不尽相同.接下来我会简单的以测试用例来简要说明.并举例说明如果提高聚集表下高并发插入效率.
在测试前我们先简单了解下堆表和聚集表都是如何完成插入操作的.
堆表Insert
方式1 a获得第一个IAM页
b 获取与之相关的PFS页,从中找到第一个能容纳Insert数据行大小的数据页
c 如果没有找到相应数据页则转到下一个IAM页然后重复b操作
d 如果到最后的IAM页还是没有找到可容纳的数据页则分配新的扩展区(extent)
e Insert指定行
方式2 a 获取所有IAM页
b 获取与之相关的PFS页(s)找到能容纳数据行(s)的数据页(s)
c 如果没有相关数据页,或者没有足够的相关数据页,分配新扩展区(extent)
d 插入相应的行(s)
聚集表Insert
由于聚集表本身的特性,插入数据的时的数据行必须在叶子节点的特定位置.
a 获取root页
b 通过B-tree需找到指定插入行的数据页的位置
c 如果此时数据页中空间可以容纳此行,则insert,如果不能则分配新数据页或者页分裂.然后insert
注:页分裂相对于页内的DML操作(insert,update)消耗巨大,页分裂的频率上升会明显影响实例的性能
测试用例
测试工具: sqlquerystress
测试环境:sql2008R2,3台不同服务器上分别安装运行sqlquerystress,100 threads/server
2000times/thread
注意:如要模拟高并发需多台机器共同执行,单台即便多threads测试,测试结果也不能合理反应高并发情况.
测试脚本
我们在相应的机器上sqlquerystress中运行insert into tempdb.dbo.tx(str1) select 'aa'测试
--------heaptable
create table t1
(
id int identity(1,1),
str1 char(5)
)
go
DBCC SQLPERF("sys.dm_os_wait_stats", CLEAR)with NO_INFOMSGS
-----run thesqlquerystress at three servers
-----100threads per server
-----2000times thread
select * from sys.dm_os_wait_stats order by waiting_tasks_count desc
---clustered table
checkpoint
dbcc dropcleanbuffers
create table t2
(
id int identity(1,1) primary key,---clustered index default
str1 char(5)
)
DBCC SQLPERF("sys.dm_os_wait_stats", CLEAR)with NO_INFOMSGS
-----run thesqlquerystress at three servers
-----100threads per server
-----2000times thread
select * from sys.dm_os_wait_stats order by waiting_tasks_count desc
测试结果
执行时的吞吐量Batch requests/sec
可以看出在我们的测试环境下堆表的吞吐量几乎是聚集表的2倍左右图1-1
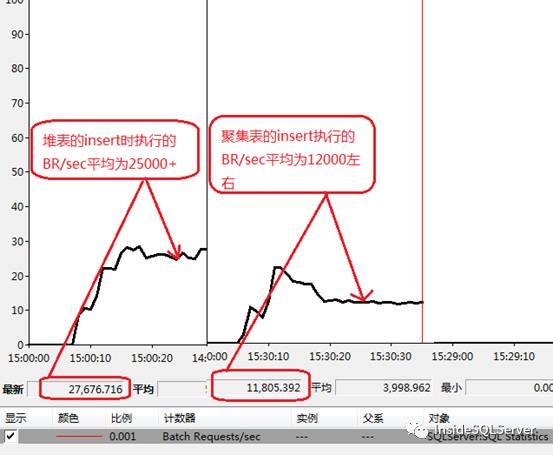
图1-1
执行时间 elapsed time
可以看出在我们的测试环境中执行时间堆表为45s,聚集表为85s
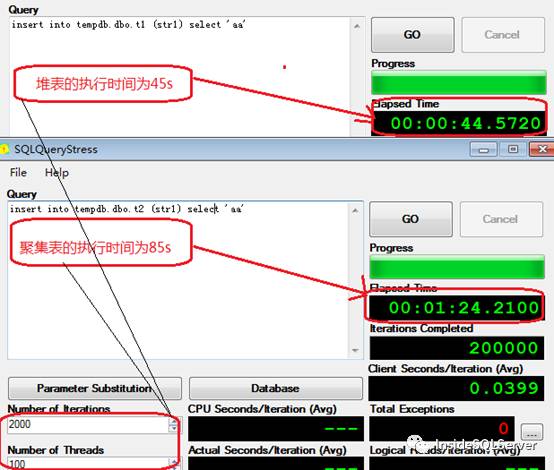
图1-2
等待事件sys.dm_os_wait_stats
可以看出我们的测试环境中,相比堆表中我们的聚集表操作产生了大量的等待图1-3
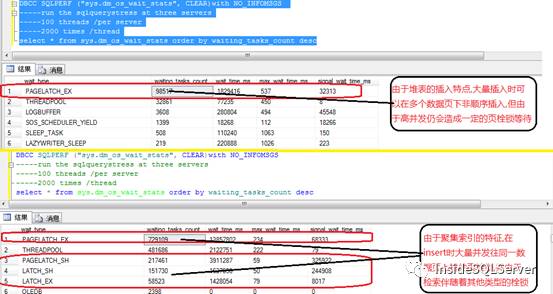
图1-3
由上面的实例我们可以看出,由于聚集表和堆表的insert方式差异,导致了在高并发下聚集表的insert效率低于堆表,在实际的项目中可能由于要求使用聚集表的情况下有大量并发插入请求,此时聚集表的insert操作就有可能出现瓶颈.此时我们可以根据sql server的一些知识来解决此瓶颈.
瓶颈分析
由于聚集表的数据组织特性,insert操作时数据只能逐行按序插入.图1-4
我们来看下聚集表数据页数据的具体情况.
dbcc traceon(3604)
dbcc ind(tempdb,t2,1) -----find a datapage pageid 114
dbcc page('tempdb',1,114,3) WITH TABLERESULTS-----view thedatapage 114
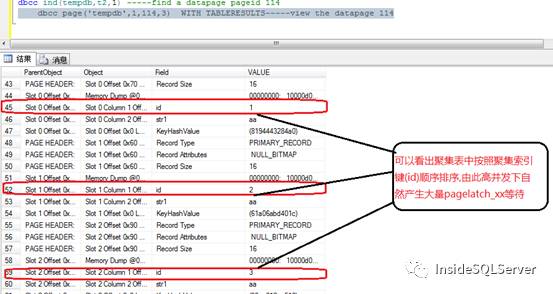
图1-4
解决思路
看了数据页的结构,数据行id 1,2,3…也就是顺序插入时大量并发只能集中在一个数据页中排队插入.看到这我们应该已经有了相应的思路,能否聚集表中同时往多个数据页中插入数据?
改变不了数据页的结构,我们可以改变数据的组织结构---分区.关于分区我就不做介绍了
不了解的朋友自行查询相关概念.
哈希分区.Sql Server中不提供哈希分区,虽然2014中内存数据库中已经提供了hash index.
我们可以以其他方式变向地实现sql server中的hash分区.
这里我采用id/2取模的形式实现奇偶分区(odd-even)
创建完成后我们再执行上面的insert测试.
use tempdb
CREATE PARTITION FUNCTION f_hash(int) AS
RANGE LEFT FOR VALUES (0,1)----------Dim PARTITIONFUNC
CREATE PARTITION SCHEME OE_f_hash AS PARTITION f_hash all TO ([PRIMARY])-------Dim PARTITIONarchitecture
create table t3
(
id int identity (1,1),
str1 varchar(2),
hashid as id%2 PERSISTED ------hashidodd/even PERSISTED
)-----create common table
CREATE CLUSTERED INDEX [inx_1] ON t3
(
[hashid] ASC,
[id] ASC
)ON [OE_f_hash]([hashid])-------Dim PARTITION table
DBCC SQLPERF("sys.dm_os_wait_stats", CLEAR)with NO_INFOMSGS
-----run thesqlquerystress at three servers
-----100threads /per server
-----2000times /thread
select * from sys.dm_os_wait_stats order by waiting_tasks_count desc
我们先来看下奇偶分区后的数据页数据行的组织结构
dbcc ind(tempdb,t3,1) -----find a datapage pageid 94 partition number
dbcc page('tempdb',1,94,3) WITH TABLERESULTS---view the datapage 94
分区1(偶数区)的数据页图2-1
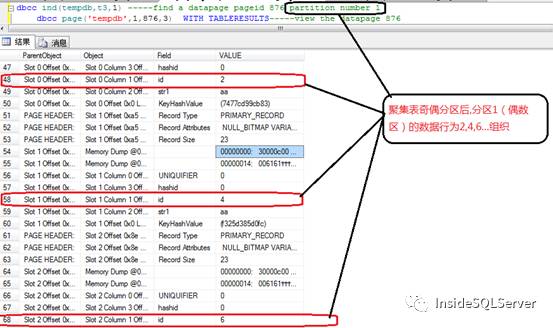
图2-1
分区2(奇数区)数据页图2-2
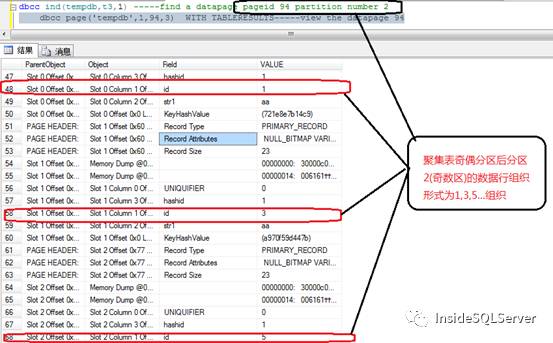
图2-2
由上面截图中可以看出分区后的id按奇偶不同在不同的分区数据页中组织.这时实际就可以进行同时往多个数据页中insert数据(2个,奇偶)
这时我们再看下奇偶分区的实现下截取与堆表,聚集表相同的相关性能计数截图2-3,2-4,2-5
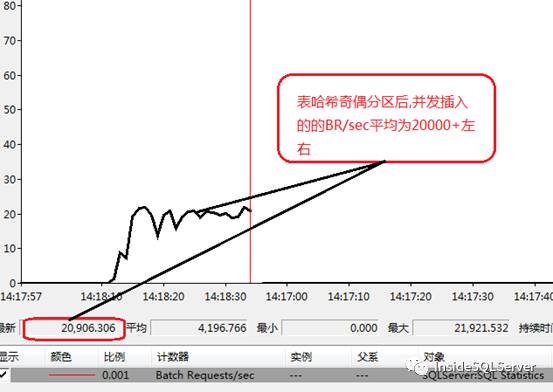
图2-3
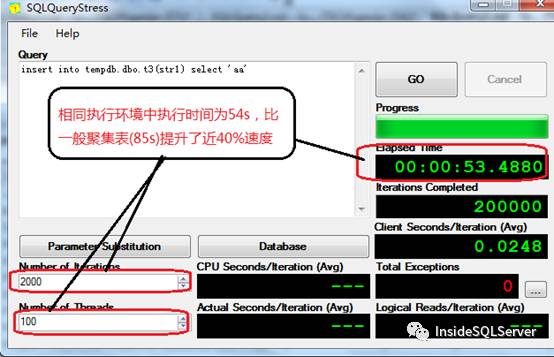
图2-4
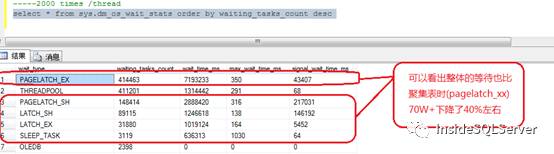
图2-5
可以看出无论从吞吐量Batch Requests/sec,还是执行时间,还是等待事件中相关计数都有了明显的改善.由于上面的哈希分区只是奇偶分区,如果按照其他hash分区(如除3取模),性能可能还会有一定的提升.感兴趣的朋友可以自行测试
