




每隔一段时间,网上就会出现一篇关于有人使用 GPU 执行常见空间分析任务的帖子,我突然对技术产生了浓厚的兴趣。也许这才是真正的新方式!
本周, 一篇关于 GPU 辅助空间连接的帖子 引起了我的注意。综上所述,作者从费城取了一个 9M 的违章 停车数据记录集, 并将其加入到 费城街区的 150 个记录集。该过程涉及在 Python 中构建一个小型执行引擎。这是非常手动的,但肯定很快。
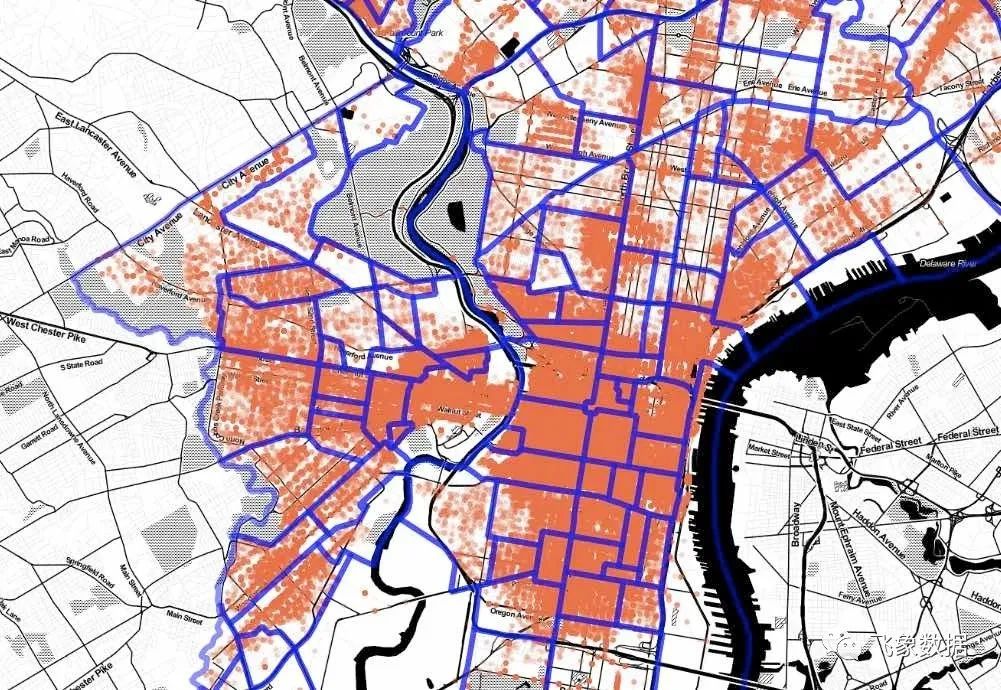
我想知道:相比之下,在像 PostGIS 这样的传统环境中执行会有多糟糕?
服务器设置
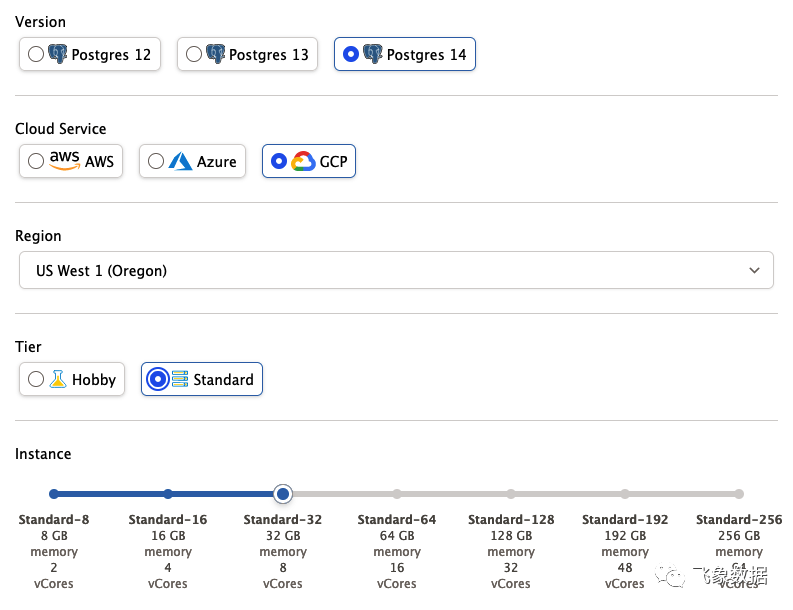
我从Crunchy Bridge DBaaS(https://crunchybridge.com/?CrunchyAnonId=lcdipiubvylbjsdevvbldohhvposqrnibetwhilfedhl)获取了一个带有 PostgreSQL 14 和 PostGIS 3 的 8 核云服务器 ,如下所示:
资料下载
## Download Philadelphia parking infraction data#curl "https://phl.carto.com/api/v2/sql?filename=parking_violations&format=csv&skipfields=cartodb_id,the_geom,the_geom_webmercator&q=SELECT%20*%20FROM%20parking_violations%20WHERE%20issue_datetime%20%3E=%20%272012-01-01%27%20AND%20issue_datetime%20%3C%20%272017-12-31%27" > phl_parking.csv## Download Philadelphia neighborhoods#wget https://github.com/azavea/geo-data/raw/master/Neighborhoods_Philadelphia/Neighborhoods_Philadelphia.zip## Convert neighborhoods file to SQL#unzip Neighborhoods_Philadelphia.zipshp2pgsql -s 102729 -D Neighborhoods_Philadelphia phl_hoods > phl_hoods.sql# Connect to databasepsql -d postgres
数据加载和准备
然后我将 CSV 和 SQL 数据文件加载到数据库中。
-- Set up PostGISCREATE EXTENSION postgis;-- Read in the neighborhoods SQL file\i phl_hoods.sql-- Reproject the neighborhoods to EPSG:4326 to match the-- parking dataALTER TABLE phl_hoodsALTER COLUMN geomTYPE Geometry(multipolygon, 4326)USING st_transform(geom, 4326);-- Create parking infractions tableCREATE TABLE phl_parking (anon_ticket_number integer,issue_datetime timestamptz,state text,anon_plate_id integer,division text,location text,violation_desc text,fine float8,issuing_agency text,lat float8,lon float8,gps boolean,zip_code text);-- Read in the parking data\copy phl_parking FROM 'phl_parking.csv' WITH (FORMAT csv, HEADER true);
这是需要任何时间的第一步。从 CSV 中读取 9M 记录大约需要 29 秒。
因为停车数据缺少几何列,所以我创建了第二个有几何列的表,然后对其进行索引。
CREATE TABLE phl_parking_geom ASSELECT anon_ticket_number,ST_SetSRID(ST_MakePoint(lon, lat), 4326) AS geomFROM phl_parking ;ANALYZE phl_parking_geom;
在创建几何列时制作第二个副本大约需要 24 秒。
最后,为了进行空间连接,我需要停车点的空间索引。在这种情况下,我遵循我关于 何时使用不同空间索引 并在几何上构建“spgist”索引的建议。
CREATE INDEX phl_parking_geom_spgist_xON phl_parking_geom USING spgist (geom);
这是最长的过程,大约需要60 秒。
运行查询
空间连接查询是使用 ST_Intersects(https://postgis.net/docs/ST_Intersects.html)作为连接条件的简单内部连接。
SELECT h.name, count(*)FROM phl_hoods hJOIN phl_parking_geom pON ST_Intersects(h.geom, p.geom)GROUP BY h.name;
不过,在运行它之前,我查看EXPLAIN
了查询的输出,就是这样。
HashAggregate (cost=4031774.83..4031776.41 rows=158 width=20)Group Key: h.name-> Nested Loop (cost=0.42..4024339.19 rows=1487128 width=12)-> Seq Scan on phl_hoods h (cost=0.00..30.58 rows=158 width=44)-> Index Scan using phl_parking_geom_spgist_x on phl_parking_geom p(cost=0.42..25460.90 rows=941 width=32)Index Cond: (geom && h.geom)Filter: st_intersects(h.geom, geom)
这一切都非常好,一个嵌套循环在较小的邻域表上与大型索引停车表相对,除了一件事:我启动了一个 8 核服务器并且我的计划没有并行性!
怎么了?
SHOW max_worker_processes; -- 8SHOW max_parallel_workers; -- 8SHOW max_parallel_workers_per_gather; -- 2SHOW min_parallel_table_scan_size; -- 8MB
啊哈!与我们的 neighborhoods 表相比,并行扫描的最小表大小似乎很大。
select pg_relation_size('phl_hoods');-- 237568
是的!所以,首先我们将设置min_parallel_table_scan_size为 1kb,然后将其max_parallel_workers_per_gather增加到 8,看看会发生什么。
SET max_parallel_workers_per_gather = 8;SET min_parallel_table_scan_size = '1kB';
EXPLAIN
空间连接的输出现在是并行的,但不幸的是只有 4 进程。
Finalize GroupAggregate (cost=1319424.81..1319505.22 rows=158 width=20)Group Key: h.name-> Gather Merge (cost=1319424.81..1319500.48 rows=632 width=20)Workers Planned: 4-> Sort (cost=1318424.75..1318425.14 rows=158 width=20)Sort Key: h.name-> Partial HashAggregate(cost=1318417.40..1318418.98 rows=158 width=20)Group Key: h.name-> Nested Loop(cost=0.42..1018842.71 rows=59914937 width=12)-> Parallel Seq Scan on phl_hoods h(cost=0.00..29.39 rows=40 width=1548)-> Index Scan using phl_parking_geom_spgist_xon phl_parking_geom p(cost=0.42..25460.92 rows=941 width=32)Index Cond: (geom && h.geom)Filter: st_intersects(h.geom, geom)
现在我们仍然在邻域上进行嵌套循环连接,但是这次规划器认识到它可以并行扫描表。由于空间连接基本上是 CPU 绑定而不是 I/O 绑定,因此这是一个更好的计划选择。
SELECT h.name, count(*)FROM phl_hoods hJOIN phl_parking_geom pON ST_Intersects(h.geom, p.geom)GROUP BY h.name;
4 个进程一起运行的最终查询需要 24 秒来执行 900 万次停车违规与 150 个社区的连接。
非常好!
它比 GPU 快吗?不,GPU 帖子说他的自定义 python/GPU 解决方案执行仅需 8 秒。尽管如此,环境的差异仍然很重要:
PostgreSQL 中的数据可由多个用户和应用程序完全编辑。
PostgreSQL 中的执行计划是自动优化的。如果下一个查询涉及社区名称和车牌号,它将同样快速并且不涉及额外的自定义代码。
PostGIS 引擎能够回答数百个关于数据库的其他空间问题。
使用像 pg_tileserv或 pg_featureserv这样的网络服务,数据可以立即发布并且可以远程查询。
结论
基本上,很难用通用工具击败定制的性能解决方案。然而,PostgreSQL/PostGIS 在高端 GPU 解决方案的“足够好”范围内,所以这对我来说算作“胜利”。
喜欢这篇文章吗?
