




(点击上方公众号,可快速关注)
每次经历数据库性能调优,都是对性能优化的再次认识、对自己知识不足的有力验证,只有不断总结、学习才能少走弯路。
一、性能问题描述
应用端反应系统查询缓慢,长时间出不来结果。SQLServer数据库服务器吞吐量不足,CPU资源不足,经常飙到100%…….
二、监测分析
收集性能数据采用二种方式:连续一段时间收集和高峰期实时收集
连续一天收集性能指标(以下简称“连续监测”)
目的: 通过此方式得到CPU/内存/磁盘/SQLServer总体情况,宏观上分析当前服务器的主要的性能瓶颈。
工具: 性能计数器 Perfmon+PAL日志分析器
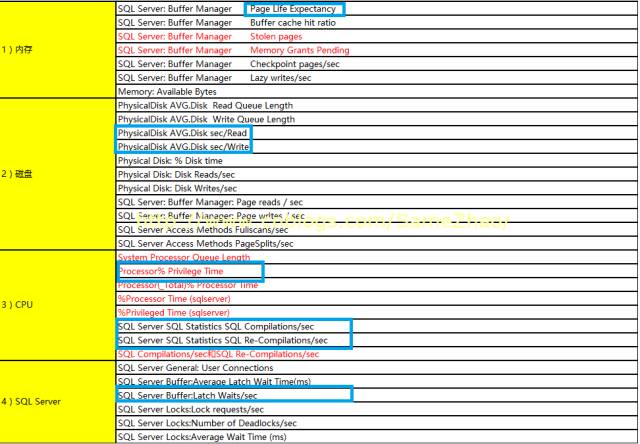
配置:
Perfmon配置主要性能计数器内容具体如下表
Perfmon收集的时间间隔:15秒 (不宜过短,否则会对服务器性能造成额外压力)
收集时间: 8:00~20:00业务时间,收集一天
分析监测结果
收集完成后,通过PAL工具自动分析出结果,显示主要性能问题:
业务高峰期CPU接近100%,并伴随较多的Latch(闩锁)等待,查询时有大量的扫表操作。这些只是宏观上得到的“现象级“的性能问题表现,并不能一定说明是CPU资源不够导致的,需要进一步找证据分析。
PAL分析得出几个突出性能问题
1. 业务高峰期CPU接近瓶颈:CPU平均在60%左右,高峰在80%以上,极端达到100%
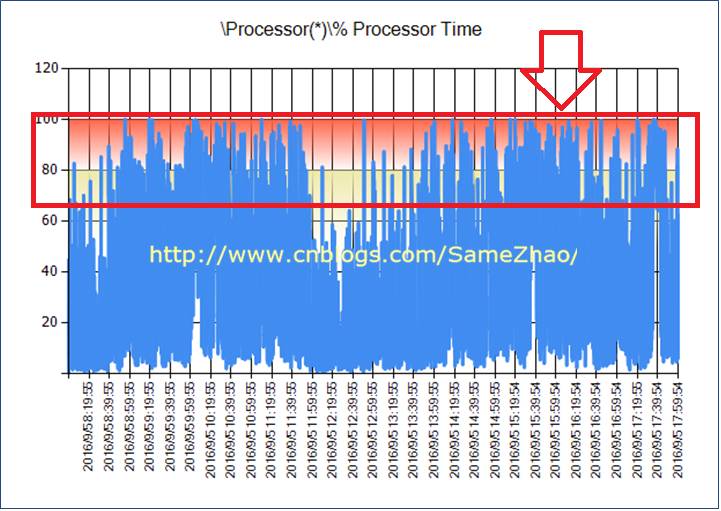
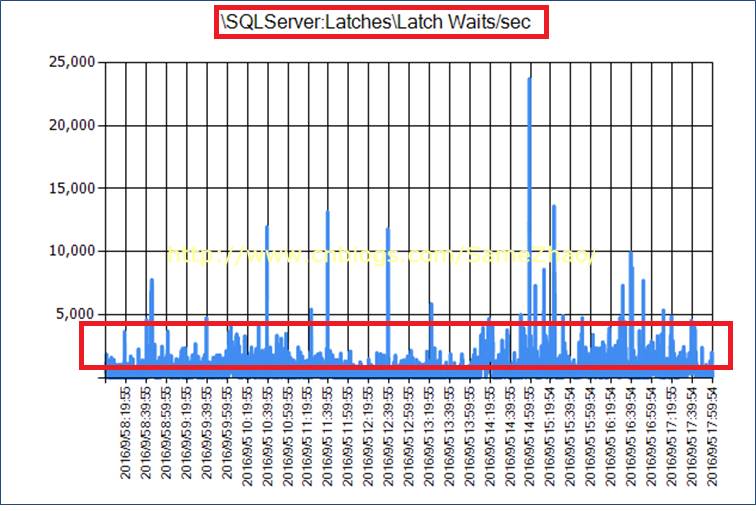
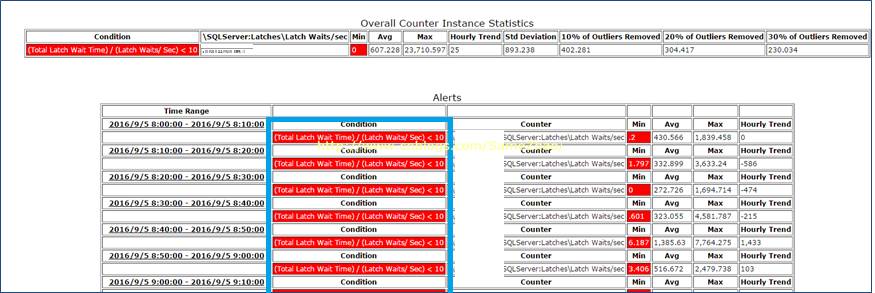
2. Latch等待一直持续存在,平均在>500。Non-Page Latch等待严重
3. 业务高峰期有大量的表扫描
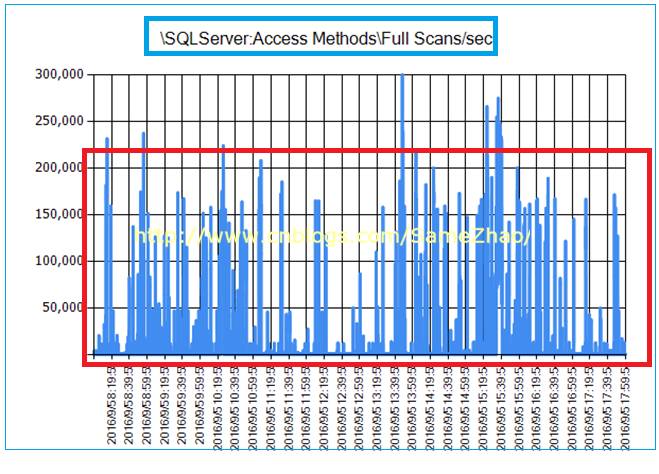
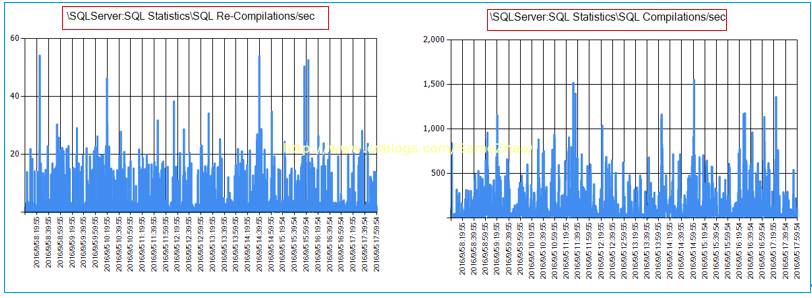
4. SQL编译和反编译参数高于正常
5.PLE即页在内存中的生命周期,其数量从某个时间点出现断崖式下降
其数量从早上某个时间点下降后直持续到下午4点,说明这段时间内存中页面切换比较频繁,出现从磁盘读取大量页数据到内存,很可能是大面积扫表导致。

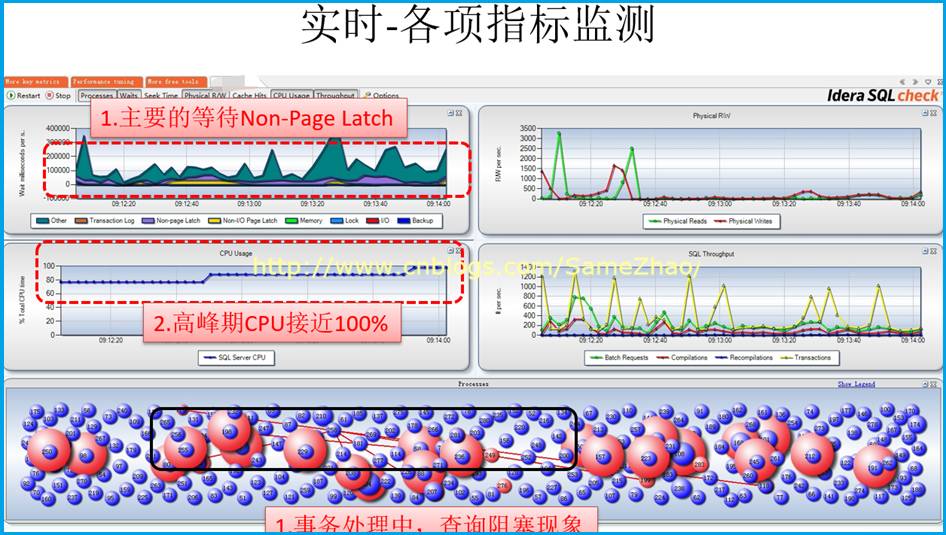
实时监测性能指标
目的: 根据“连续监测“已知的业务高峰期PeakTime主要发生时段,接下来通过实时监测重点关注这段时间各项指标,进一步确认问题。
工具: SQLCheck
配置: 客户端连接到SQLCheck配置
小贴士:建议不要在当前服务器运行,可选择另外一台机器运行SQLCheck
分析监测结果
实时监测显示Non-Page Latch等待严重,这点与上面“连续监测”得到结果一直
Session之间阻塞现象时常发生,经分析是大的结果集查询阻塞了别的查询、更新、删除操作导致
详细分析
数据库存存在大量表扫描操作,导致缓存中数据不能满足查询,需要从磁盘中读取数据,产生IO等待导致阻塞。
1. Non-Page Latch等待时间长
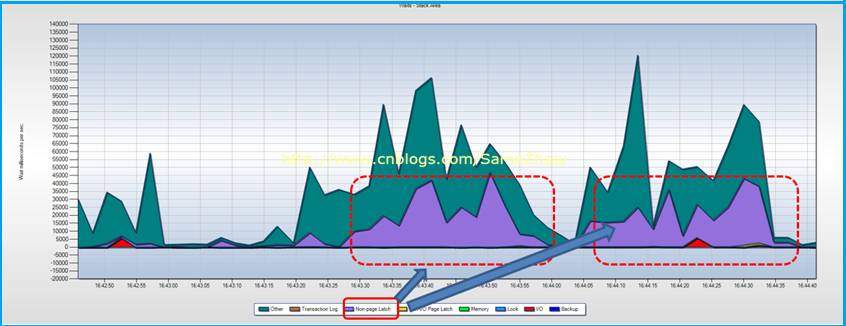
2. 当 Non-Page Latch等待发生时候,实时监测显示正在执行大的查询操作
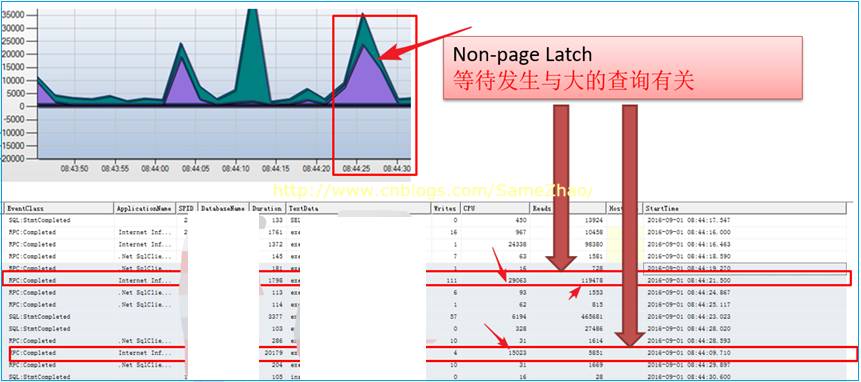
3. 伴有session之间阻塞现象,在大的查询时发生阻塞现象,CPU也随之飙到95%以上
解决方案
找到问题语句,创建基于条件的索引来减少扫描,并更新统计信息。
上面方法还无法解决,考虑将受影响的数据转移到更快的IO子系统,考虑增加内存。
三、等待类型分析
通过等待类型,换个角度进一步分析到底时哪些资源出现瓶颈
工具: DMV/DMO
操作:
1. 先清除历史等待数据
选择早上8点左右执行下面语句
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
2. 晚上8点左右执行,执行下面语句收集Top 10的等待类型信息统计。
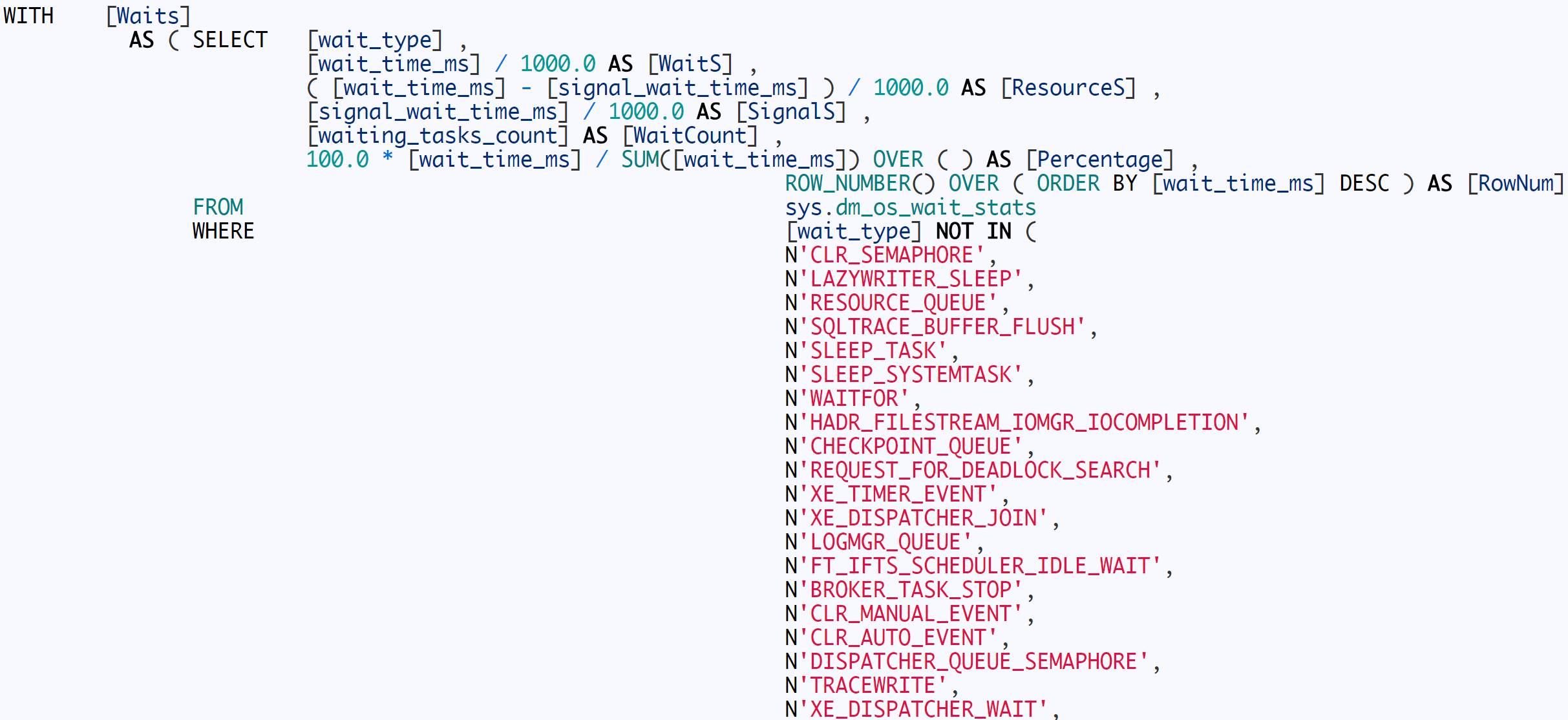
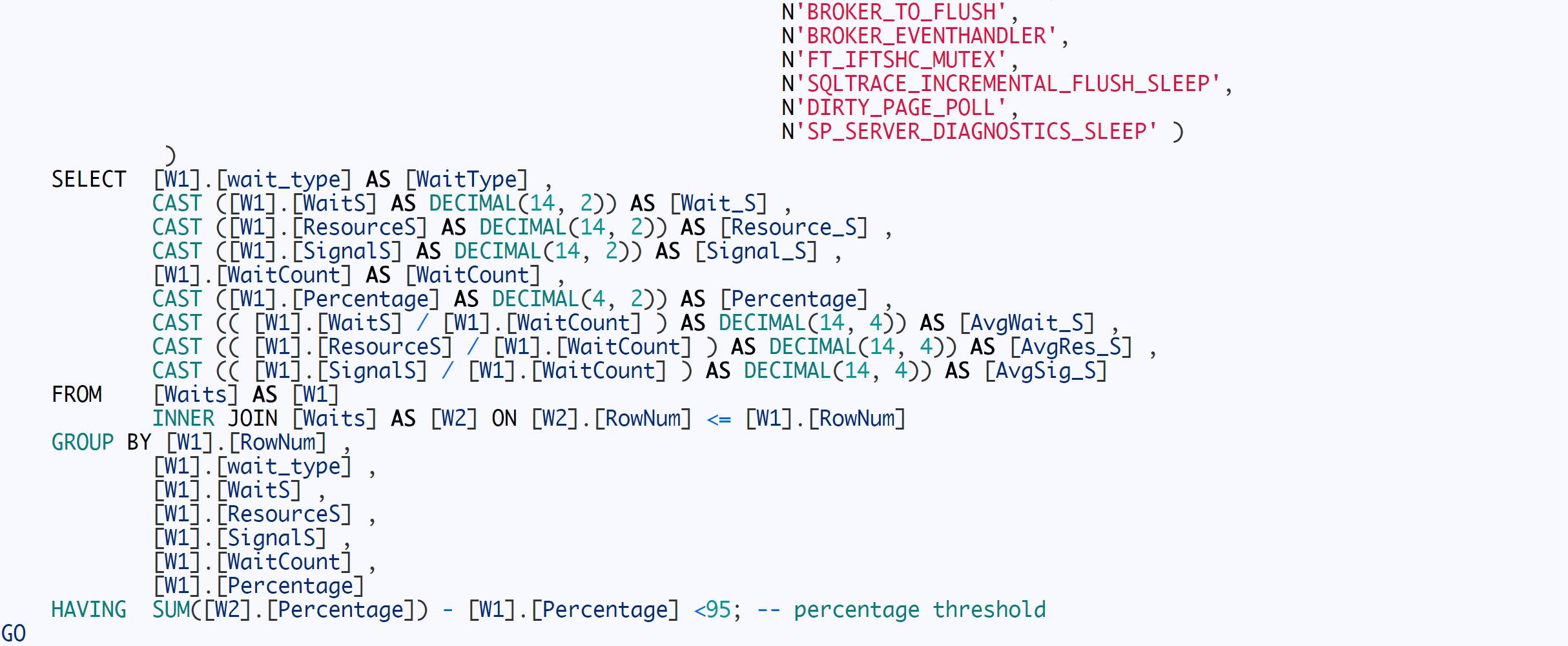
3.提取信息
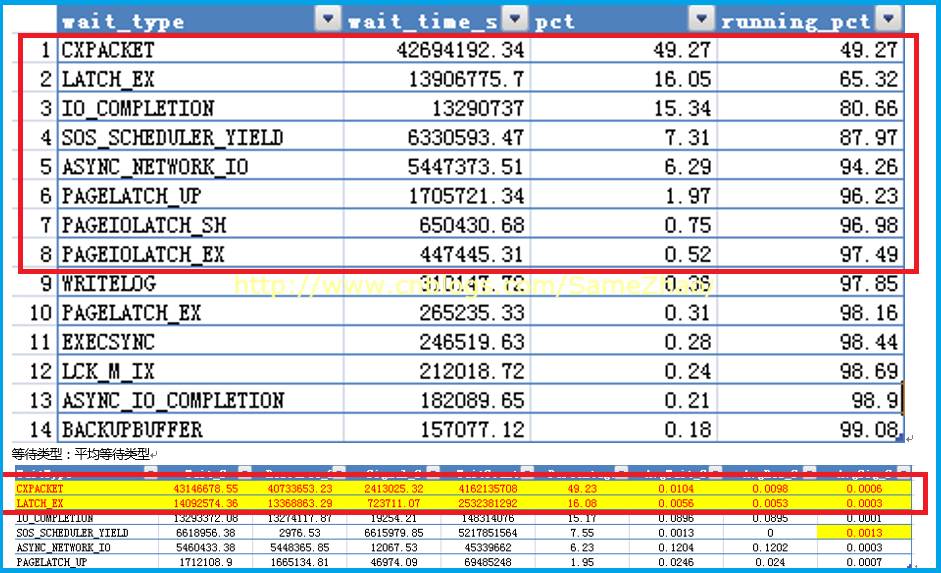
查询结果得出排名:
1:CXPACKET
2:LATCH_X
3:IO_COMPITION
4:SOS_SCHEDULER_YIELD
5: ASYNC_NETWORK_IO
6. PAGELATCH_XX
7/8.PAGEIOLATCH_XX
跟主要资源相关的等待方阵如下:
CPU相关:CXPACKET 和SOS_SCHEDULER_YIELD
IO相关: PAGEIOLATCH_XXIO_COMPLETION
Memory相关: PAGELATCH_XX、LATCH_X
进一步分析前几名等待类型
当前排前三位:CXPACKET、LATCH_EX、IO_COMPLETION等待,开始一个个分析其产生等待背后原因
CXPACKET等待分析
CXPACKET等待排第1位, SOS_SCHEDULER_YIELD排在4位,伴有第7、8位的PAGEIOLATCH_XX等待。发生了并行操作worker被阻塞
说明:
1. 存在大范围的表Scan
2. 某些并行线程执行时间过长,这个要将PAGEIOLATCH_XX和非页闩锁Latch_XX的ACCESS_METHODS_DATASET_PARENT Latch结合起来看,后面会给到相关信息
3. 执行计划不合理的可能
分析:
1. 首先看一下花在执行等待和资源等待的时间
2. PAGEIOLATCH_XX是否存在,PAGEIOLATCH_SH等待,这意味着大范围SCAN
3. 是否同时有ACCESS_METHODS_DATASET_PARENT Latch或ACCESS_METHODS_SCAN_RANGE_GENERATOR LATCH等待
4. 执行计划是否合理
信提取息:
获取CPU的执行等待和资源等待的时间所占比重
执行下面语句:
--CPU Wait Queue (threshold:<=6)
select scheduler_id,idle_switches_count,context_switches_count,current_tasks_count, active_workers_count from sys.dm_os_schedulers
where scheduler_id<255
SELECT sum(signal_wait_time_ms) as total_signal_wait_time_ms,
sum(wait_time_ms-signal_wait_time_ms) as resource_wait_time_percent,
sum(signal_wait_time_ms)*1.0/sum(wait_time_ms)*100 as signal_wait_percent,
sum(wait_time_ms-signal_wait_time_ms)*1.0/sum(wait_time_ms)*100 asresource_wait_percent FROM SYS.dm_os_wait_stats
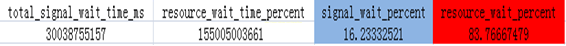
结论:从下表收集到信息CPU主要花在资源等待上,而执行时候等待占比率小,所以不能武断认为CPU资源不够。
造成原因:
缺少聚集索引、不准确的执行计划、并行线程执行时间过长、是否存在隐式转换、TempDB资源争用
解决方案:
主要从如何减少CPU花在资源等待的时间
1. 设置查询的MAXDOP,根据CPU核数设置合适的值(解决多CPU并行处理出现水桶短板现象)
2. 检查”cost threshold parallelism”的值,设置为更合理的值
3. 减少全表扫描:建立合适的聚集索引、非聚集索引,减少全表扫描
4. 不精确的执行计划:选用更优化执行计划
5. 统计信息:确保统计信息是最新的
6. 建议添加多个Temp DB 数据文件,减少Latch争用,最佳实践:>8核数,建议添加4个或8个等大小的数据文件
LATCH_EX等待分析
LATCH_EX等待排第2位。
说明:
有大量的非页闩锁等待,首先确认是哪一个闩锁等待时间过长,是否同时发生CXPACKET等待类型。
分析:
查询所有闩锁等待信息,发现ACCESS_METHODS_DATASET_PARENT等待最长,查询相关资料显示因从磁盘->IO读取大量的数据到缓存,结合与之前Perfmon结果做综合分析判断,判断存在大量扫描。
运行脚本
SELECT * FROM sys.dm_os_latch_stats
信提取息:
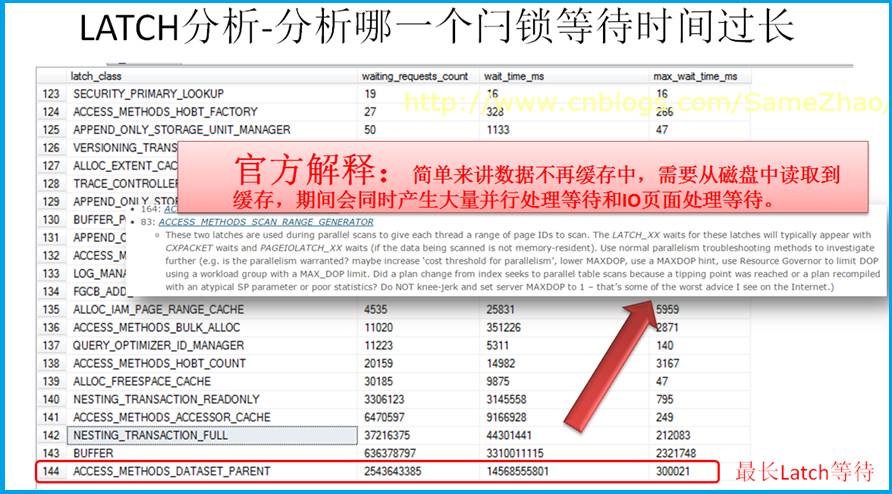
造成原因:
有大量的并行处理等待、IO页面处理等待,这进一步推定存在大范围的扫描表操作。
与开发人员确认存储过程中使用大量的临时表,并监测到业务中处理用频繁使用临时表、标量值函数,不断创建用户对象等,TEMPDB 处理内存相关PFSGAMSGAM时,有很多内部资源申请征用的Latch等待现象。
解决方案:
1. 优化TempDB
2. 创建非聚集索引来减少扫描
3. 更新统计信息
4. 在上面方法仍然无法解决,可将受影响的数据转移到更快的IO子系统,考虑增加内存
IO_COMPLETION等待分析
现象:
IO_COMPLETION等待排第3位
说明:
IO延迟问题,数据从磁盘到内存等待时间长
分析:
从数据库的文件读写效率分析哪个比较慢,再与“CXPACKET等待分析”的结果合起来分析。
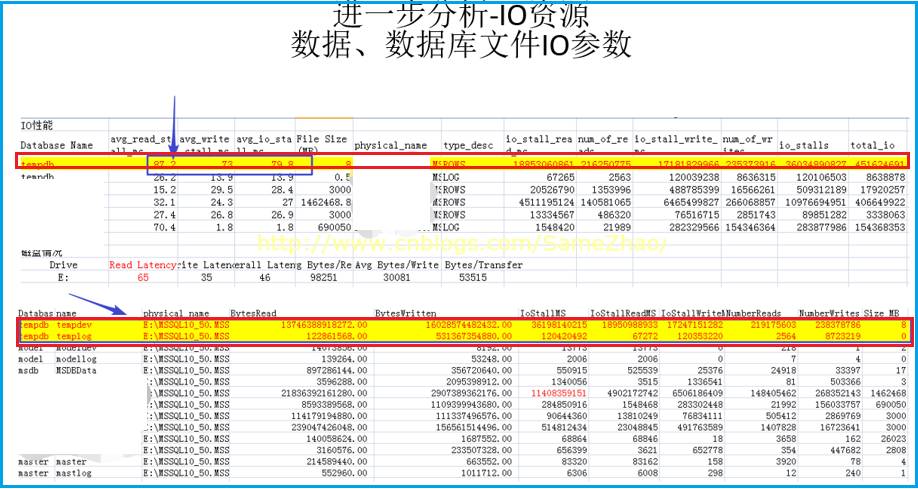
Temp IO读/写资源效率
1. TempDB的数据文件的平均IO在80左右,这个超出一般值,TempDB存在严重的延迟。
2. TempDB所在磁盘的Read latency为65,也比一般值偏高。
运行脚本:
--数据库文件读写IO性能
SELECT DB_NAME(fs.database_id) AS [Database Name], CAST(fs.io_stall_read_ms/(1.0 + fs.num_of_reads) ASNUMERIC(10,1)) AS [avg_read_stall_ms],
CAST(fs.io_stall_write_ms/(1.0 + fs.num_of_writes) AS NUMERIC(10,1)) AS [avg_write_stall_ms],
CAST((fs.io_stall_read_ms + fs.io_stall_write_ms)/(1.0 + fs.num_of_reads + fs.num_of_writes) AS NUMERIC(10,1)) AS[avg_io_stall_ms],
CONVERT(DECIMAL(18,2), mf.size/128.0) AS [File Size (MB)], mf.physical_name, mf.type_desc, fs.io_stall_read_ms,fs.num_of_reads,
fs.io_stall_write_ms, fs.num_of_writes, fs.io_stall_read_ms + fs.io_stall_write_ms AS [io_stalls], fs.num_of_reads +fs.num_of_writes AS [total_io]
FROM sys.dm_io_virtual_file_stats(null,null) AS fs
INNER JOIN sys.master_files AS mf WITH (NOLOCK)
ON fs.database_id = mf.database_id
AND fs.[file_id] = mf.[file_id]
ORDER BY avg_io_stall_ms DESC OPTION (RECOMPILE);
--驱动磁盘-IO文件情况
SELECT [Drive],
CASE
WHEN num_of_reads = 0 THEN 0
ELSE (io_stall_read_ms/num_of_reads)
END AS [Read Latency],
CASE
WHEN io_stall_write_ms = 0 THEN 0
ELSE (io_stall_write_ms/num_of_writes)
END AS [Write Latency],
CASE
WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0
ELSE (io_stall/(num_of_reads + num_of_writes))
END AS [Overall Latency],
CASE
WHEN num_of_reads = 0 THEN 0
ELSE (num_of_bytes_read/num_of_reads)
END AS [Avg Bytes/Read],
CASE
WHEN io_stall_write_ms = 0 THEN 0
ELSE (num_of_bytes_written/num_of_writes)
END AS [Avg Bytes/Write],
CASE
WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0
ELSE ((num_of_bytes_read + num_of_bytes_written)/(num_of_reads + num_of_writes))
END AS [Avg Bytes/Transfer]
FROM (SELECT LEFT(mf.physical_name, 2) AS Drive, SUM(num_of_reads) AS num_of_reads,
SUM(io_stall_read_ms) AS io_stall_read_ms, SUM(num_of_writes) AS num_of_writes,
SUM(io_stall_write_ms) AS io_stall_write_ms, SUM(num_of_bytes_read) AS num_of_bytes_read,
SUM(num_of_bytes_written) AS num_of_bytes_written, SUM(io_stall) AS io_stall
FROM sys.dm_io_virtual_file_stats(NULL, NULL) AS vfs
INNER JOIN sys.master_files AS mf WITH (NOLOCK)
ON vfs.database_id = mf.database_id AND vfs.file_id = mf.file_id
GROUP BY LEFT(mf.physical_name, 2)) AS tab
ORDER BY [Overall Latency] OPTION (RECOMPILE);
信息提取:
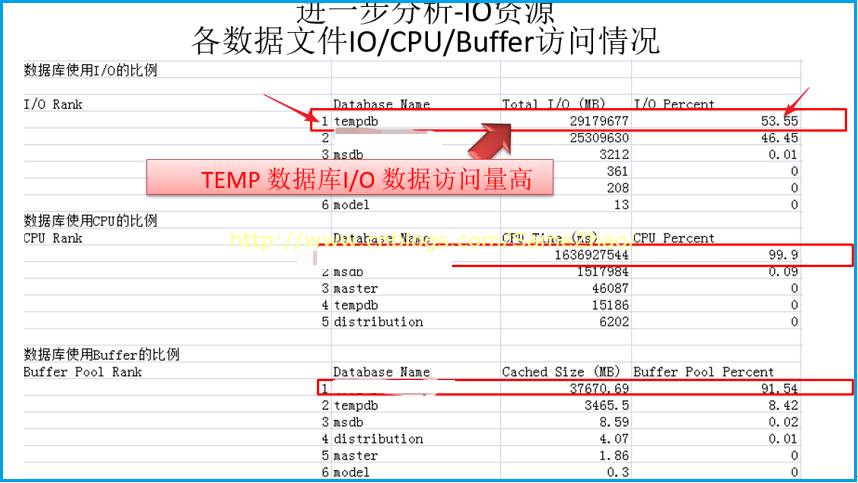
各数据文件IO/CPU/Buffer访问情况,Temp DB的IO Rank达到53%以上
解决方案:
添加多个Temp DB 数据文件,减少Latch争用。最佳实践:>8核数,建议添加4个或8个等大小的数据文件。
其他等待
分析:
通过等待类型发现与IO相关 的PAGEIOLATCH_XX 值非常高,数据库存存在大量表扫描操作,导致缓存中数据不能满足查询,需要从磁盘中读取数据,产生IO等待。
解决方案:
创建合理非聚集索引来减少扫描,更新统计信息
上面方法还无法解决,考虑将受影响的数据转移到更快的IO子系统,考虑增加内存。
未完待续(后面将继续讲解优化方案)
本文转自博客园:
www.cnblogs.com/SameZhao/p/6238997.html
长按下方二维码可以加关注

