




我们经常会被网址中的%以及各种不明含义的字符搞迷糊,不明白这些字符代表的是什么意思,比如以下链接:
http://etop.com/WebReport/ReportServer?reportlet=fine/it/%E7%A7%91%E5%AE%A4%E7%94%B5%E8%AF%9D.cpt复制
在URL后面一段以%开头的字符串,它代表什么意思?
%E7%A7%91%E5%AE%A4%E7%94%B5%E8%AF%9D复制
它实际上是一串中文的编码,使用的是utf-8编码,一个中文字符用utf-8编码需要3个字节,每字节的编码前用%隔开。所以将上述编码进行decode,可以看到真实的中文字符。
我们使用 python 来演示这个过程:
>>> b'\xE7\xA7\x91'.decode('utf-8')'科'>>> v = b'\xE7\xA7\x91\xE5\xAE\xA4\xE7\x94\xB5\xE8\xAF\x9D'>>> v.decode('utf-8')'科室电话'复制
在 python 中16进制数用 \x 表示,三个字节表示一个中文字符。对二进制进解码后可以生成utf-8编码的字符串,同样字符串也可以编码成utf-8的二进制表示。
以上有点绕,实际上'E7A791'就是utf-8的实际编码,通过解码可以得到中文字符。那为什么URL中不能含中文呢?不是域名都可以是中文的吗,比如新华网.cn
首先中文域名用的并不多,以新华网为例,它的页面上的其它链接全都是英文链接,只有首页是中文域名。其次 URL 要怎么表示是有规范的,它的规范就要求只能用英文,不能用其它特殊字符,包括中文或其它国家的字符。
但我们平时在浏览器中可以看到中文,难道我们看错了?比如以下截图:
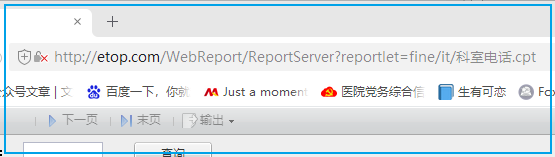
URL中的中文只是停留在页面显示上,如果我们把URL拷贝并粘贴到写字板里,就会发现它变成带%的编码了。
我们从原理出发,URL实际上会被两个程序用到,一个是浏览器即客户端服务,另一个服务器端,即http服务器。它们之间是用http协议在通讯,其中浏览器向web服务器发起http请求,而这个请求的包头就含URL。
我们通过浏览器自带的开发者工具查看 http request 的 header,即标头。在浏览器上敲F12进入到开发者工具,查看“网络”标签下的标头:
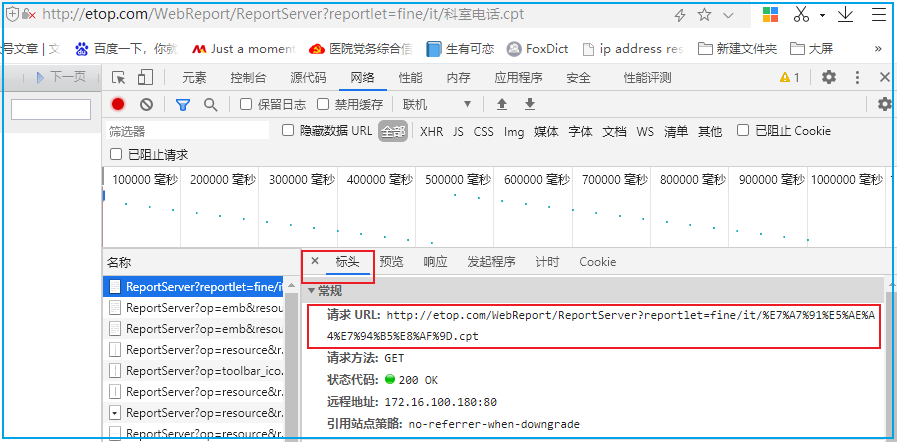
虽然浏览器的地址栏里显示的是中文,但在浏览器发起的请求中还是将中文字符做了编码,这里使用的是utf-8编码。不同的浏览器所使用的编码不一定一样 ,这是浏览器的个人行为,并不是行业标准。因为很多软件都可以发起http请求,比如 curl 工具,python 的 requests 库。
浏览器发出 http 请求了,服务端还要接受。如果服务端不知道你发来的是什么编码,那么就会报错。比如 tomcat 在接受中文编码的 URL 时,有可能会就报错:
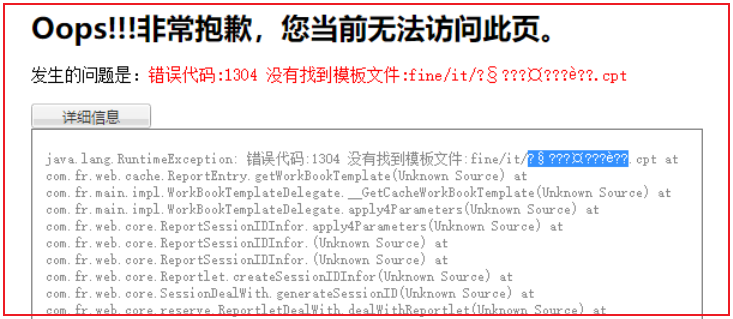
这里就是 tomcat 的配置没有指定默认的编码,当接受到来自浏览器的utf-8的URL请求时就会解析错误,显示乱码。此时调整 tomcat 的 conf/server.xml 即可支持 utf-8 编码的请求。
<Connector port="80" protocol="HTTP/1.1"connectionTimeout="20000"redirectPort="8443"minSpareThreads="50"enableLookups="false"URIEncoding="UTF-8"/>复制
增加了一行 URIEncoding="UTF-8",让服务端接受 utf-8 编码的请求。
因为最终的服务端的处理过程是由服务端程序来处理,所以当URL编码中出现无法理解的部分有可能是服务端程序自己在处理编解码,而非标准流程。比如以下编码:
fine%2Fit%2F%5B79d1%5D%5B5ba4%5D%5B7535%5D%5B8bdd%5D.cpt复制
从结构上看它还是一个以%分隔的编码格式,这个编码过程实际上是通过 javascript进行编码的,它有4个函数来处理编解码:
encodeURI()encodeURIComponent()decodeURI()decodeURIComponent()复制
我们在 node.js 中对其进行验证:
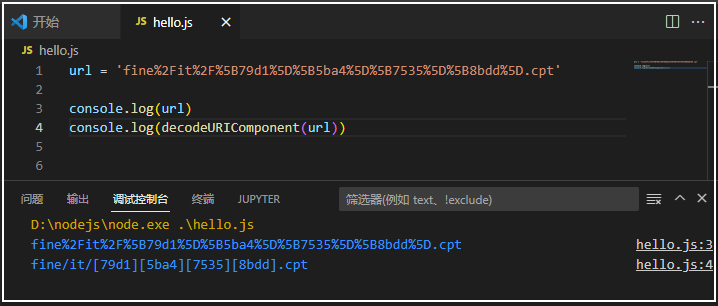
最终通过 javascript 解码后的字符串为:
fine/it/[79d1][5ba4][7535][8bdd].cpt复制
它实际上并不是一个正常的字符串,因为被[ ] 括起来的部分还是编码。但这个编码是由服务端自己解析,并不是标准的URL编码。这一串编码实际用于帆软的报表,它自己会对其进行编解码。
它的编码过程大概如下:
s = 'fine/it/科室电话.cpt'function cjkEncode(text) {if (text == null) {return "";}var newText = "";for (var i = 0; i < text.length; i++) {var code = text.charCodeAt(i);if (code >= 128 || code == 91 || code == 93) {//91 is "[", 93 is "]".newText += "[" + code.toString(16) + "]";} else {newText += text.charAt(i);}}return newText;}console.log(cjkEncode(s))复制
从输出看,其编码出来的URL,与我们通过 javascript 解码出来的一样:
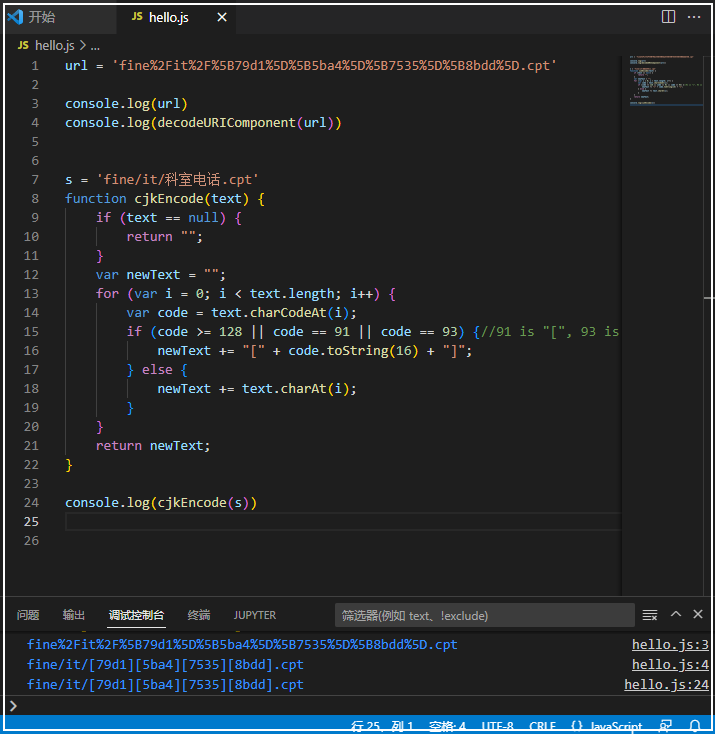
而这个方括号中间的内容实际上是unicode,我们在 python 可以验证:
>>> s = '\u79d1\u5ba4\u7535\u8bdd'>>> s'科室电话'>>>复制
最后做一下总结:
URL中的中文编码是通过javascript的两个encode函数生成的,它们的特点就是以%分隔。这两个函数 encodeURI(),encodeURIComponent() 在使用上有点小差异,主要体现在是否对 进行编码。但编码后的 URL 都能通过解码函数还原。
如果URL中还含有其它不明含义的编码,比如帆软的 [xxxx] 中间以 unicode 编码的字符串,这个是它自家的编解码,不是标准流程,由它自家的后台程序解析,当然如果了解它的含义后也可以自己写函数解析。
浏览器中的中文只是显示为中文,在后台 http 请求中还是以编码后的为准,可以通过抓包来查看 http 的请求包的包头来查真实的URL。
目前业界的标准URL编码规范是使用 javascript 的那两函数来编码,其它语言也有支持,可以理解为是一种行业规范。早期的浏览器对URL中文的编码比较混乱,目前现代浏览器都是使用 javascript 的那一套,以 % 分隔很好识别,%后面接的是编码,一般是 utf-8 编码,当然也支持其它编码,但需要服务器端解析时支持。
参考
# 如何查 http 头https://blog.csdn.net/jiang7701037/article/details/94741670# python 对 URL 的编码https://blog.csdn.net/u014663232/article/details/103501574# tomcat 中文 URLhttps://blog.51cto.com/u_15338211/3561247# javascript url编码函数用法https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/decodeURIComponent# 阮一峰 《关于URL编码》https://www.ruanyifeng.com/blog/2010/02/url_encoding.html复制
全文完。
如果转发本文,文末务必注明:“转自微信公众号:生有可恋”。



