




General expressions语法规则定义在src/backend/parser/gram.y文件中,其是表达式语法的核心。有两种表达式类型:a_expr
是不受限制的类型,b_expr
是必须在某些地方使用的子集,以避免移位/减少冲突。例如,我们不能将BETWEEN
作为BETWEEN a_expr AND a_exp
,因为AND
的使用与AND
作为布尔运算符冲突。因此,b_expr
在BETWEEN
中使用,我们从b_expr
中删除布尔关键字。请注意,( a_expr )
是b_expr
,因此始终可以使用无限制表达式,方法是用括号将其括起来。c_expr
是a_expr
和b_expr
共同的所有乘积;它被分解出来只是为了消除冗余编码。注意涉及多个terminal token的产出productions。默认情况下,bison将为此类productions分配其最后一个terminal的优先级,但在几乎所有情况下,您都希望它是第一个terminal的优先权;否则你不会得到你期望的行为!因此,我们可以自由使用%prec
注释来设置优先级。
productions expression
c_expr
是a_expr
和b_expr
所共有的规则,递归引用a_expr
或b_expr
的productions通常不能出现在c_expr
规则中。但是,可以引用出现在括号内的a_exprs
,例如函数参数;这不会给b_expr
语法带来歧义。productions that refer recursively to a_expr or b_expr mostly cannot appear here. However, it’s OK to refer to a_exprs that occur inside parentheses, such as function arguments; that cannot introduce ambiguity to the b_expr syntax.
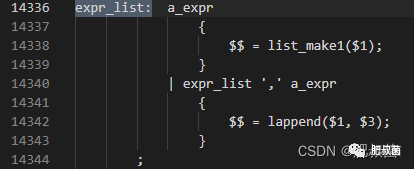
规则十:GROUPING '(' expr_list ')'
GroupingFunc是GROUPING()表达式的节点结构体,其行为在许多方面类似于聚合函数(例如,它“属于”一个特定的查询级别,可能不是直接包含它的查询级别),但在一个重要方面也有所不同:它从不计算其参数,它们只从它所属的查询级别的GROUP BY子句中指定表达式。该规范纯粹通过语法替换来定义GROUPING()的求值,但为了优化目的,我们将其作为一个实际表达式,以便一个Agg节点可以同时处理多个分组集。评估结果只需要列位置来对照投影的分组集进行检查。然而,为了使EXPLAIN产生有意义的输出,我们必须保留原始表达式,因为expression deparse没有给我们任何可行的方法来获取GROUP BY子句。此外,我们将两个GroupingFunc节点视为相等,如果它们具有相等的参数列表和agglevelsup,而不比较refs和cols注释。在原始解析输出中,我们只有参数列表;parse analysis填充refs列表,而planner填充cols列表。A GroupingFunc is a GROUPING(…) expression, which behaves in many ways like an aggregate function (e.g. it “belongs” to a specific query level, which might not be the one immediately containing it), but also differs in an important respect: it never evaluates its arguments, they merely designate expressions from the GROUP BY clause of the query level to which it belongs. The spec defines the evaluation of GROUPING() purely by syntactic replacement, but we make it a real expression for optimization purposes so that one Agg node can handle multiple grouping sets at once. Evaluating the result only needs the column positions to check against the grouping set being projected. However, for EXPLAIN to produce meaningful output, we have to keep the original expressions around, since expression deparse does not give us any feasible way to get at the GROUP BY clause. Also, we treat two GroupingFunc nodes as equal if they have equal arguments lists and agglevelsup, without comparing the refs and cols annotations.In raw parse output we have only the args list; parse analysis fills in the refs list, and the planner fills in the cols list.
| GROUPING '(' expr_list ')'{GroupingFunc *g = makeNode(GroupingFunc);g->args = $3;g->location = @1;$$ = (Node *)g;}typedef struct GroupingFunc{Expr xpr;List *args; /* arguments, not evaluated but kept for benefit of EXPLAIN etc. */List *refs; /* ressortgrouprefs of arguments */List *cols; /* actual column positions set by planner */Index agglevelsup; /* same as Aggref.agglevelsup */int location; /* token location */} GroupingFunc;
Node *transformGroupingFunc(ParseState *pstate, GroupingFunc *p)
函数定义在src/backend/parser/parse_agg.c文件中,用于转换GROUPING表达式。调用transformExpr处理GroupingFunc的args列表成员。
Node *transformGroupingFunc(ParseState *pstate, GroupingFunc *p){ListCell *lc;List *args = p->args;GroupingFunc *result = makeNode(GroupingFunc);if (list_length(args) > 31) ereport(ERROR, (errcode(ERRCODE_TOO_MANY_ARGUMENTS), errmsg("GROUPING must have fewer than 32 arguments"), parser_errposition(pstate, p->location)));List *result_list = NIL;foreach(lc, args){Node *current_result = transformExpr(pstate, (Node *) lfirst(lc), pstate->p_expr_kind);result_list = lappend(result_list, current_result); /* acceptability of expressions is checked later */}result->args = result_list; result->location = p->location;check_agglevels_and_constraints(pstate, (Node *) result);return (Node *) result;}
欢迎关注微信公众号肥叔菌PostgreSQL数据库专栏:
PostgreSQL数据库守护进程——Postmaster总体流程
PostgreSQL数据库守护进程——读取控制文件
PostgreSQL数据库守护进程——RemovePgTempFiles删除临时文件
PostgreSQL数据库守护进程——RemovePromoteSignalFiles
PostgreSQL数据库信号处理——kill backend
PostgreSQL数据库PMsignal——后端进程\Postmaster信号通信
PostgreSQL数据库后端进程——inter-process latch
PostgreSQL数据库后端进程——监视postmaster death
PostgreSQL数据库后台进程——一等公民
PostgreSQL数据库后台进程——后台一等公民进程保活
PostgreSQL数据库头胎——后台一等公民进程StartupDataBase启动
PostgreSQL数据库头胎——后台一等公民进程StartupDataBase信号通知
PostgreSQL数据库头胎——StarupXLOG函数恢复模式和目标
PostgreSQL数据库状态pmState——PM_STARTUP状态
PostgreSQL数据库复制——Setting Up Asynchronous Replication
PostgreSQL数据库复制——后台一等公民进程WalReceiver启动函数
PostgreSQL数据库复制——后台一等公民进程WalReceiver获知连接
PostgreSQL数据库复制——后台一等公民进程WalReceiver&startup交互
PostgreSQL数据库复制——后台一等公民进程WalReceiver ready_to_display
PostgreSQL数据库复制——后台一等公民进程WalReceiver提取信息
PostgreSQL数据库复制——后台一等公民进程WalReceiver收发逻辑
PostgreSQL数据库复制——后台一等公民进程WalReceiver pg_stat_wal_receiver视图
PostgreSQL数据库复制——walsender后端启动
PostgreSQL数据库守护进程——后台二等公民进程第一波启动maybe_start_bgworkers
PostgreSQL数据库参数——简述GUC
PostgreSQL数据库网络层——libpq连接参数
PostgreSQL数据库动态共享内存管理器——dynamic shared memory segment
PostgreSQL数据库WAL——资源管理器RMGR
PostgreSQL数据库WAL——备机回放checkpoint WAL
PostgreSQL数据库事务系统——phenomena
PostgreSQL数据库统计信息——analyze命令
PostgreSQL数据库统计信息——analyze大致流程
PostgreSQL数据库统计信息——analyze执行函数
PostgreSQL数据库统计信息——查找继承子表find_all_inheritors
PostgreSQL数据库统计信息——analyze流程对不同表的处理
PostgreSQL数据库统计信息——examine_attribute单列预分析
PostgreSQL数据库统计信息——acquire_sample_rows采样函数
PostgreSQL数据库统计信息——acquire_inherited_sample_rows采样函数
PostgreSQL数据库统计信息——计算统计数据
PostgreSQL数据库统计信息——compute_scalar_stats计算统计数
PostgreSQL数据库统计信息——analyze统计信息收集
PostgreSQL数据库统计信息——统计信息系统表
PostgreSQL守护进程(Postmaster)——辅助进程PgStat主流程
PostgreSQL守护进程(Postmaster)——辅助进程PgStat统计消息
PostgreSQL数据库查询监控技术——pg_stat_activity简介
PostgreSQL查询引擎——编译调试
PostgreSQL查询引擎——select * from where = transform流程
PostgreSQL查询引擎——General Expressions Grammar之columnref
PostgreSQL查询引擎——Transform Expressions之columnref
PostgreSQL查询引擎——General Expressions Grammar之CaseExpr
PostgreSQL查询引擎——General Expressions Grammar之AexprConst
PostgreSQL查询引擎——Transform Expressions之const
PostgreSQL查询引擎——General Expressions Grammar之GROUPING
PostgreSQL查询引擎——create table xxx(...)基础建表流程
PostgreSQL查询引擎——create table xxx(...)基础建表transformCreateStmt
PostgreSQL数据库查询执行——T_VariableSetStmt
PostgreSQL数据库查询执行——T_TransactionStmt
PostgreSQL数据库查询执行——Parallel Query
PostgreSQL数据库查询执行——SeqScan节点执行
PostgreSQL数据库查询执行——Using GDB To Trace Into a Parallel Worker Spawned By Postmaster During a Large Query
PostgreSQL数据库查询执行——Parallel SeqScan节点执行
PostgreSQL数据库可插拔存储引擎——pg_am系统表
PostgreSQL数据库可插拔存储引擎——Table Access Manager
PostgreSQL数据库可插拔存储引擎——GetTableAmRoutine函数
PostgreSQL数据库可插拔存储引擎——Table scan callbacks
PostgreSQL数据库HeapAM——TupleTableSlot类型
PostgreSQL数据库HeapAM——HeapAM Scan
PostgreSQL数据库HeapAM——HeapAM Parallel table scan
PostgreSQL数据库HeapAM——synchronized scan machinery
PostgreSQL数据库缓冲区管理器——概述
PostgreSQL数据库缓冲区管理器——本地缓冲区管理
PostgreSQL数据库缓冲区管理器——Shared Buffer Pool初始化
PostgreSQL数据库存储介质管理器——SMGR
PostgreSQL数据库存储介质管理器——磁盘管理器
PostgreSQL数据库目录——目录操作封装
PostgreSQL虚拟文件描述符VFD机制——FD LRU池
PostgreSQL虚拟文件描述符VFD机制——FD LRU池其他函数
PostgreSQL数据库FDW——The Internals of PostgreSQL
PostgreSQL数据库FDW——WIP PostgreSQL Sharding
PostgreSQL数据库FDW——Parquet S3 Foreign Data Wrapper
PostgreSQL数据库FDW——Parquet S3 ParquetReader类
PostgreSQL数据库FDW——Parquet S3 ReaderCacheEntry
PostgreSQL数据库FDW——Parquet S3 ParallelCoordinator
PostgreSQL数据库FDW——Parquet S3 DefaultParquetReader类
PostgreSQL数据库FDW——Parquet S3 CachingParquetReader类
PostgreSQL数据库FDW——Parquet S3 ParquetS3FdwExecutionState类
PostgreSQL数据库FDW——Parquet S3 MultifileMergeExecutionStateBaseS3类
PostgreSQL数据库FDW——Parquet S3 读取parquet文件用例
PostgreSQL数据库使用——between and以及日期的使用
PostgreSQL数据库使用——iRedMail定时备份数据库脚本
PostgreSQL数据库使用——iRedMail初始化数据库脚本
PostgreSQL数据库使用——iRedMail创建用户脚本
PostgreSQL数据库插件——定时任务pg_cron
PostgreSQL数据库故障分析——invalid byte sequence for encoding
ETCD、Zookeeper和Consul 分布式数据库的魔法银弹
PostgreSQL数据库高可用——patroni介绍[翻译]
PostgreSQL数据库高可用——patroni配置[翻译]
PostgreSQL数据库高可用——patroni REST API[翻译]
PostgreSQL数据库高可用——将独立集群转换为Patroni集群[翻译]
PostgreSQL数据库高可用——patroni源码学习
PostgreSQL数据库高可用——patroni源码学习——abstract_main
PostgreSQL数据库高可用——patroni源码AbstractPatroniDaemon类
PostgreSQL数据库高可用——patroni源码Patroni子类简介
PostgreSQL数据库高可用——patroni源码PatroniLogger类
PostgreSQL数据库高可用——patroni RestApiServer
PostgreSQL数据库高可用——patroni源码DCS类
PostgreSQL数据库高可用——patroni源码AbstractEtcd类
PostgreSQL数据库高可用——patroni源码EtcdClient类
PostgreSQL数据库高可用——patroni源码Etcd
PostgreSQL数据库高可用——patroni源码学习——Ha类概述
PostgreSQL数据库高可用——Patroni AsyncExecutor类
PostgreSQL数据库高可用——Patroni PostmasterProcess类
PostgreSQL数据库备份恢复迁移——Barman Before you start[翻译]
PostgreSQL数据库备份恢复迁移——Barman Introduction[翻译]
Postgres-XL数据库GTM——概念
Postgres-XL数据库GTM——事务管理
Postgres-XL数据库GTM——GTM and Global Transaction Management[翻译]
Postgres-XL数据库GTM——Master & Standby启动流程
Postgres-XL数据库GTM——Master & Standby子线程
Postgres-XL数据库GTM——Node管理器
Greenplum数据库统计信息——analyze命令 Greenplum数据库统计信息——分布式采样 Greenplum数据库统计信息——auto-analyze特性 Greenplum数据库Hash分布——计算哈希值和映射segment Greenplum数据库Hash分布——GUC gp_use_legacy_hashops Greenplum数据库数据分片策略Hash分布——执行器行为 Greenplum数据库过滤投影——ExecScan执行逻辑 Greenplum数据库外部表——Scan执行节点 Greenplum数据库外部表——fileam封装 Greenplum数据库外部表——external_getnext获取元组 Greenplum数据库外部表——url_curl创建销毁 Greenplum数据库外部协议——Define EXTPROTOCOL Greenplum数据库外部协议——GPHDFS实现协议 Greenplum数据库外部协议——GPHDFS gphdfs_fopen HashData数据库外部表——GPHDFS实现简介 Greenplum数据库高可用——FTS进程 Greenplum数据库高可用——FTS进程ftsConnect Greenplum数据库高可用——FTS进程触发轮询 Greenplum数据库高可用——FTS进程ftsPoll\Send\Receive Greenplum数据库高可用——FTS Pull模型 Greenplum数据库高可用——FTS HandleFtsWalRepProbe函数 Greenplum数据库高可用——FTS HandleFtsWalRepSyncRepOff函数 Greenplum数据库高可用——FTS HandleFtsWalRepPromote函数 Greenplum数据库高可用——FTS processRetry函数 Greenplum数据库高可用——FTS processResponse函数 Greenplum数据库高可用——FTS updateConfiguration更新系统表 Greenplum Python专用库gppylib学习——logging模块 Greenplum Python专用库gppylib学习——GpArray
Greenplum Python专用库gppylib学习——base.py
Greenplum Python工具库gpload学习——gpload类
Greenplum数据库源码分析——Standby Master操作工具分析
Greenplum数据库故障分析——利用GDB调试多线程core文件
Greenplum数据库故障分析——semop(id=,num=11) failed:invalid argument
Greenplum数据库故障分析——能对数据库base文件夹进行软连接嘛
Greenplum数据库故障分析——UDP Packet Lost(packet reassembles failed)
Greenplum数据库故障分析——版本升级后gpstart -a为何返回失败
Greenplum数据库故障分析——can not listen port
HAWQ数据库技术解析——内部架构
HAWQ数据库技术解析——filesystem interface
HAWQ数据库技术解析——HDFS filesystem
HAWQ数据库技术解析(一)——HAWQ简介[转载]
