




ClickHouse多盘存储配置
参考文档1 参考文档2
长期以来,ClickHouse-Server是一个访问单个存储设备上数据的进程,这样的设计提供了操作简便性,却无法将机器的磁盘硬件资源充分利用,且将用户的数据限制在同一类型的存储上,这让用户难以在成本和性能上做出抉择,尤其是对于大型集群,这个问题尤其突出。
在2019年期间,Altinity和ClickHouse社区一直在致力于将ClickHouse表存储划分为包含多个设备的卷,并在其之间自动移动数据。这种多卷存储的功能具有很多用途,其中最重要的用途是将冷热数据分别存储在不同类型的存储上,这种配置叫做分层存储(tiered storage),正确地使用分层存储可以极大地提高ClickHouse的经济性。
本文将介绍如何配置ClickHouse的多盘存储。
1 ClickHouse多卷架构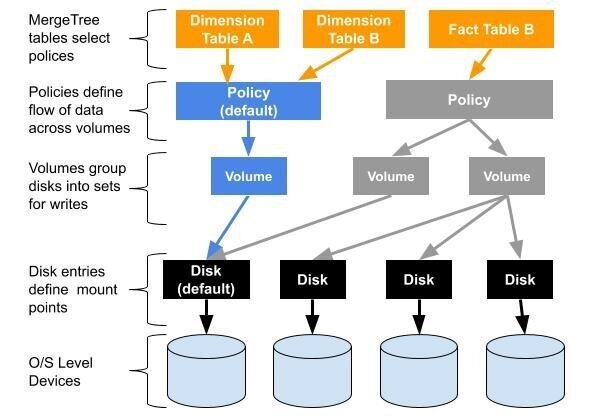
这个是Altinity给出的ClickHouse多卷架构图。每个MergeTree表都与一个存储策略相关联,策略只是用于编写MergeTree表数据的规则。存储策略将磁盘分为一个或多个卷,还定义了每个卷中磁盘的写顺序,以及数据在多个卷之间的移动方式。
存储策略与旧表向后兼容,ClickHouse始终有一个名为“default”的磁盘,该磁盘指向config.xml中的data目录路径。还有一个相应的策略称为“default”。如果MergeTree表没有存储策略,则ClickHouse将使用默认策略并写入默认磁盘。
2 配置磁盘
首先要在机器上安装ClickHouse,具体安装步骤略。
执行lsblk命令,查看本地机器的磁盘信息
我们使用ext4文件系统格式化磁盘并挂载
sudo mkfs -t ext4 /dev/sdc
sudo mkdir /data/sdc
sudo mount -o noatime,nobarrier /dev/sdc /data/sdc
lsblk
可以看到sdc盘已经被格式化并被挂载。
执行如下sql,查看ClickHouse感知到的磁盘。
SELECT
name,
path,
formatReadableSize(free_space) AS free,
formatReadableSize(total_space) AS total,
formatReadableSize(keep_free_space) AS reserved
FROM system.disks
我们要修改配置,让ClickHouse能感知到其他磁盘。新增配置文件/etc/clickhouse-server/config.d/storage.xml
<yandex>
<storage_configuration>
<disks>
<default>
<!--
You can reserve some amount of free space
on any disk (including default) by adding
keep_free_space_bytes tag
-->
<keep_free_space_bytes>1024</keep_free_space_bytes>
</default>
<sdc>
<!--
disk path must end with a slash,
folder should be writable for clickhouse user
-->
<path>/data/sdc/</path>
</sdc>
<sdd>
<path>/data/sdd/</path>
</sdd>
<sde>
<path>/data/sde/</path>
</sde>
</disks>
</storage_configuration>
</yandex>
修改路径权限,重启ClickHouse
sudo chown clickhouse:clickhouse -R /data/sdc/ /data/sdd/ /data/sde/
sudo systemctl restart clickhouse-server
sudo systemctl status clickhouse-server
重新查看,发现ClickHouse已经感知到了新增的磁盘。
3 存储策略
当ClickHouse感知到磁盘了,你以为这样就结束撒花了吗,这还远远没有结束,MergeTree表数据仍存储在默认磁盘(即/var/lib/clickhouse/)上,用下面sql来证明:
CREATE TABLE sample1 (id UInt64) Engine=MergeTree ORDER BY id;
INSERT INTO sample1 SELECT * FROM numbers(1000000);
SELECT name, data_paths FROM system.tables WHERE name = 'sample1'\G
将数据存储在不同磁盘上的规则是由存储策略来设置的,ClickHouse有一个默认的存储策略,表示将所有数据都存放在默认的磁盘上。
SELECT policy_name, volume_name, disks
FROM system.storage_policies
3.1 单磁盘策略
我们创建一个”sdc_only“的存储策略,这个策略规定将所有数据存储在sdc磁盘的sdc_volume卷上。
配置如下:
<yandex>
<storage_configuration>
<disks>
<default>
<!--
You can reserve some amount of free space
on any disk (including default) by adding
keep_free_space_bytes tag
-->
<keep_free_space_bytes>1024</keep_free_space_bytes>
</default>
<sdc>
<!--
disk path must end with a slash,
folder should be writable for clickhouse user
-->
<path>/data/sdc/</path>
</sdc>
<sdd>
<path>/data/sdd/</path>
</sdd>
<sde>
<path>/data/sde/</path>
</sde>
</disks>
<policies>
<sdc_only> <!-- name for new storage policy -->
<volumes>
<sdc_volume> <!-- name of volume -->
<!--
we have only one disk in that volume
and we reference here the name of disk
as configured above in <disks> section
-->
<disk>sdc</disk>
</sdc_volume>
</volumes>
</sdc_only>
</policies>
</storage_configuration>
</yandex>
重启ClickHouse让配置重新加载。
发现我们新增的存储策略已经成功了,下面我们看看如何使用这个新的存储策略sdc_only。只需在新表上添加一个SETTINGS storage_policy ='sdc_only'。
CREATE TABLE sample2 (id UInt64) Engine=MergeTree
ORDER BY id SETTINGS storage_policy = 'sdc_only';
INSERT INTO sample2 SELECT * FROM numbers(1000000);
SELECT name, data_paths, metadata_path, storage_policy
FROM system.tables
WHERE name LIKE 'sample%'
可以看到两个表具有不同的数据路径和不同的存储策略。请注意,表元数据保留在默认磁盘上。
我们还可以检查每个part的存储位置
3.2 多磁盘的单层卷策略
上面我们实现了如何将数据保存在单个磁盘上,那么如何能将数据保存在多个磁盘上呢?我们可以使用存储策略在一个卷中将两个或多个磁盘分组,数据将以循环方式在磁盘之间分配:每次插入(或合并)都会在卷中的下一个磁盘上创建part,part的一半存储在一个磁盘上,其余部分存储在另一个磁盘上。
现在我们尝试将sdc和sdd两块磁盘连接到一个卷中,我们将以下存储策略添加到storage.xml文件中:
<sdc_sdd_jbod> > <!-- name for new storage policy -->
<volumes>
<sdc_sdd_jbod_volume> <!-- name of volume -->
<!--
the order of listing disks inside
volume defines round-robin sequence
-->
<disk>sdc</disk>
<disk>sdd</disk>
</sdc_sdd_jbod_volume>
</volumes>
</sdc_sdd_jbod>
我们重新启动ClickHouse并检查system.storage_policies中的存储策略。
让我们用新的策略来测试一下:
CREATE TABLE sample3 (id UInt64) Engine=MergeTree ORDER BY id SETTINGS storage_policy = 'sdc_sdd_jbod';
SELECT
name,
data_paths,
metadata_path,
storage_policy
FROM system.tables
WHERE name = 'sample3'
现在我们通过添加数据来查询part的着陆位置:
insert into sample3 select * from numbers(1000000);
insert into sample3 select * from numbers(1000000);
insert into sample3 select * from numbers(1000000);
insert into sample3 select * from numbers(1000000);
select name, disk_name, path from system.parts where table = 'sample3';
通过实验结果可以看到,我们已经实现了将数据保存在多个磁盘上的功能。
3.3 多层存储:具有不同优先级的卷
CLickHouse中的数据有冷数据和热数据之分,我们可以通过实现不同优先级的卷来实现数据存储的冷热分离。
首先,我们使用以下存储策略配置分层存储:
<hot_and_cold>
<volumes>
<hot_volume>
<disk>sdc</disk>
<max_data_part_size_bytes>200000000</max_data_part_size_bytes>
</hot_volume>
<cold_volume>
<disk>sdd</disk>
</cold_volume>
</volumes>
</hot_and_cold>
策略中的卷顺序非常重要。将新part存储在磁盘上时,ClickHouse首先尝试将其放置在第一个卷中,然后放置在第二个卷中,依此类推。
我们创建一个使用新的分层存储配置的表。
CREATE TABLE sample4 (id UInt64) Engine=MergeTree ORDER BY id SETTINGS storage_policy = 'hot_and_cold';
INSERT INTO sample4 SELECT rand() FROM numbers(10000000);
重复执行10次
SELECT
disk_name,
formatReadableSize(bytes_on_disk) AS size
FROM system.parts
WHERE (table = 'sample4') AND active
目前,所有数据都是“热”数据,并存储在快速磁盘(sdc)上。
INSERT INTO sample4 SELECT rand() FROM numbers(10000000);
重复执行8次,然后等待一会
SELECT
disk_name,
formatReadableSize(bytes_on_disk) AS size
FROM system.parts
WHERE (table = 'sample4') AND active
可以看到合并创建了一个很大的part,该part被放置在冷存储(sdd)中。
这样我们就实现了数据存储的冷热分离。
【结束】
本文介绍了如何构建ClickHouse存储策略并应用它们以不同方式分发MergeTree表数据,实现ClickHouse的多磁盘多策略存储,能够提高ClickHouse集群的性能和优化成本。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
ClickHouse 已收购 HyperDX
通讯员
187次阅读
2025-03-14 14:18:52
Oracle优化-检查Oracle数据库性能
张静懿
51次阅读
2025-03-22 13:53:22
MySQL数据库优化总结
鲁鲁
42次阅读
2025-03-25 23:06:42
oracle巡检的其他检查
听溪
41次阅读
2025-03-23 22:17:19
ORACLE数据库查看执行计划
张静懿
40次阅读
2025-03-23 22:23:04
数据库语句优化
鲁鲁
40次阅读
2025-03-16 21:53:18
Oracle数据库常用脚本(八)
hongg
39次阅读
2025-04-02 09:09:23
MySQL数据库“干货”来袭!41个常用脚本,速来领取
青年数据库学习互助会
39次阅读
2025-03-31 10:03:01
oracle检查数据库cpu、I/O、内存性能
怀念和想念
39次阅读
2025-03-23 22:06:48
oracle数据库查询与管理
芃芃
37次阅读
2025-03-18 23:52:52



