




在本文中,读者将在更短的时间内了解使用Hazelcast和StreamNative进行实时流处理,以及演示和代码。
实时流处理最有用的功能之一是结合各种技术的优势和优势,以提供独特的开发人员体验和大规模实时处理数据的有效方法。Hazelcast 是一个实时分布式计算和存储平台,用于针对实时事件流和传统数据源进行一致的低延迟查询、聚合和有状态计算。Apache Pulsar 是一个实时多租户异地复制分布式发布-订阅消息传递和流式处理平台,适用于实时工作负载,每小时处理数百万个事件。
但是,实时流处理并非易事,尤其是在将多个实时流与存储在外部数据存储中的大量数据相结合以提供上下文和即时结果时。在使用方面,Hazelcast可用于以下事情:
- 基于实时流数据的有状态数据处理。
- 静态数据。
- 静态数据和基于实时流数据的有状态数据处理的组合。
- 查询流式处理。
- 直接使用 SQL 对数据源进行批处理。
- 微服务的分布式协调。
- 将数据从一个区域复制到另一个区域。
- 在同一区域的数据中心之间复制数据。
虽然Apache Pulsar可用于消息传递和流媒体,但用例取代了多个产品,并提供了其功能的超集。Apache Pulsar是一个云原生多租户统一消息传递平台,可取代Apache Kafka,RabbitMQ,MQTT和传统消息传递平台。Apache Pulsar为Hazelcast提供了一个无限的消息总线,作为任何和所有数据源的即时源和接收器。
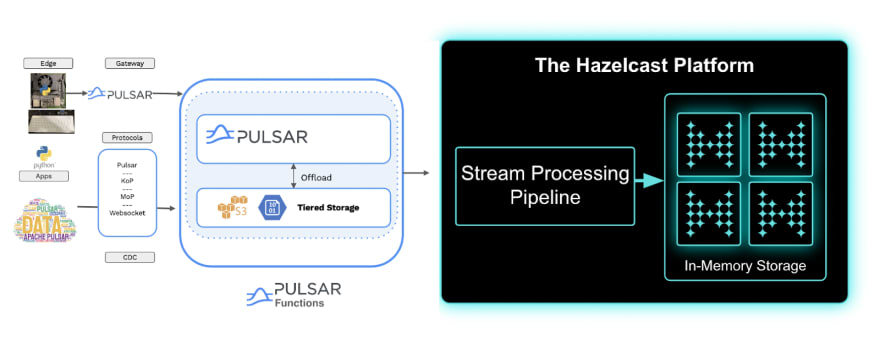
先决条件
我们正在构建一个应用程序,我们将Apache Pulsar的数据摄取到Hazelcast中,然后实时处理它。要运行此应用程序,请确保您的系统具有以下组件:
- 您的系统上安装了 Hazelcast:我们正在使用 CLI。
- Pulsar 安装在您的系统上:我们正在使用 Docker。
如果您有macOS和Homebrew,则可以使用以下命令安装Hazelcast:
壳
1
brew tap hazelcast/hz
2
3
brew install hazelcast@5.2.1
检查是否安装了 Hazelcast:
hz -V
然后启动本地群集:
hz start
您应该在控制台中看到以下内容:
壳
1
INFO: [192.168.1.164]:5701 [dev] [5.2.1]
2
3
4
5
Members {size:1, ver:1} [6
7
Member [192.168.1.164]:5701 - 4221d540-e34e-4ff2-8ad3-41e060b895ce this
8
9
]
您可以使用以下命令在 Docker 中启动 Pulsar:
壳
1
docker run -it -p 6650:6650 -p 8080:8080 \
2
3
--mount source=pulsardata,target=/pulsar/data \
4
5
--mount source=pulsarconf,target=/pulsar/conf \
6
7
apachepulsar/pulsar:2.11.0 bin/pulsar standalone
若要安装管理中心,请使用下列方法之一,具体取决于您的操作系统:
壳
1
brew tap hazelcast/hz
2
3
brew install hazelcast-management-center@5.2.1
检查是否已安装管理中心:
hz-mc -V
数据采集
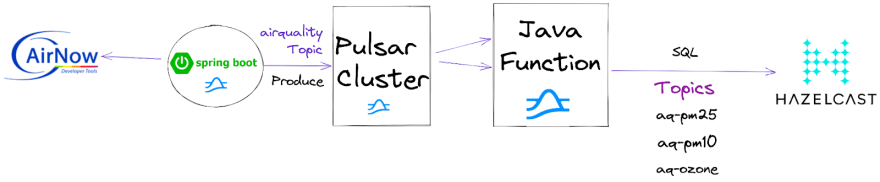
对于我们的应用程序,我们希望通过 AirNow 数据提供商从美国各地摄取空气质量读数。
来源:AirNow API
通过一个简单的Java应用程序,我们对AirNow API进行REST调用,该API为美国各地的主要邮政编码提供空气质量读数。Java 应用程序将 JSON 编码的 AirNow 数据发送到“空气质量”脉冲星主题。从这一点开始,Hazelcast应用程序可以读取它。
来源: GitHub
我们还有一个Java Pulsar函数,从“空气质量”主题接收每个事件,并根据空气质量读数的类型将其解析为不同的主题。这包括PM2.5,PM10和臭氧。
来源: GitHub
空气质量数据示例
杰伦
1
{"dateObserved":"2023-01-19 ","hourObserved":12,"localTimeZone":"EST","reportingArea":"Philadelphia","stateCode":"PA","latitude":39.95,"longitude":-75.151,"parameterName":"PM10","aqi":19,"category":{"number":1,"name":"Good","additionalProperties":{}},"additionalProperties":{}}臭氧数据示例
杰伦
1
{"dateObserved":"2023-01-19 ","hourObserved":12,"localTimeZone":"EST","reportingArea":"Philadelphia","stateCode":"PA","parameterName":"O3","latitude":39.95,"longitude":-75.151,"aqi":8}PM10 数据示例
杰伦
1
{"dateObserved":"2023-01-19 ","hourObserved":12,"localTimeZone":"EST","reportingArea":"Philadelphia","stateCode":"PA","parameterName":"PM10","latitude":39.95,"longitude":-75.151,"aqi":19}PM2.5数据示例
杰伦
1
{"dateObserved":"2023-01-19 ","hourObserved":12,"localTimeZone":"EST","reportingArea":"Philadelphia","stateCode":"PA","parameterName":"PM2.5","latitude":39.95,"longitude":-75.151,"aqi":54}
数据处理
为了处理收集到的数据,我们使用 Hazelcast Pulsar 连接器模块从 Pulsar 主题中提取数据。
注意:您可以使用同一连接器写入 Pulsar 主题。
使用 Hazelcast 允许我们在指定的流项目窗口上实时计算各种聚合函数(总和、平均等)。Pulsar 连接器使用 Pulsar 客户端库,该库有两种不同的方式从 Pulsar 主题读取消息。这些是消费者 API 和读取器 API;两者都使用构建器模式(有关更多信息,请单击此处)。
在 pom 文件中,导入以下依赖项:
.XML
1
<dependency>
2
3
<groupId>com.hazelcast</groupId>
4
5
<artifactId>hazelcast</artifactId>
6
7
<version>5.1.4</version>
8
9
</dependency>
10
11
<dependency>
12
13
<groupId>com.hazelcast.jet.contrib</groupId>
14
15
<artifactId>pulsar</artifactId>
16
17
<version>0.1</version>
18
19
</dependency>
20
21
<dependency>
22
23
<groupId>org.apache.pulsar</groupId>
24
25
<artifactId>pulsar-client</artifactId>
26
27
<version>2.10.1</version>
28
29
</dependency>
我们创建一个实例来连接到之前启动的 Pulsar 集群,该集群位于 。PulsarSources.pulsarReaderBuilderpulsar://localhost:6650
爪哇岛
1
StreamSource<Event>source = PulsarSources.pulsarReaderBuilder(
2
3
topicName,
4
5
() -> PulsarClient.builder().serviceUrl("pulsar://localhost:6650").build(),6
7
() -> Schema.JSON(Event.class),
8
9
Message::getValue).build();
然后,我们创建一个管道,在写入记录器之前,使用滑动窗口和聚合计数从源中读取:
爪哇岛
1
Pipeline p = Pipeline.create();
2
3
p.readFrom(source)
4
5
.withNativeTimestamps(0)
6
7
.groupingKey(Event::getUser)
8
9
.window(sliding(SECONDS.toMillis(60), SECONDS.toMillis(30)))
10
11
.aggregate(counting())
12
13
.writeTo(Sinks.logger(wr -> String.format(
14
15
"At %s Pulsar got %,d messages in the previous minute from %s.",
16
17
TIME_FORMATTER.format(LocalDateTime.ofInstant(
18
19
Instant.ofEpochMilli(wr.end()), ZoneId.systemDefault())),
20
21
wr.result(), wr.key())));
22
23
JobConfig cfg = new JobConfig()
24
25
.setProcessingGuarantee(ProcessingGuarantee.EXACTLY_ONCE)
26
27
.setSnapshotIntervalMillis(SECONDS.toMillis(1))
28
29
.setName("pulsar-airquality-counter");30
31
HazelcastInstance hz = Hazelcast.bootstrappedInstance();
32
33
hz.getJet().newJob(p, cfg);
您可以从 IDE 运行前面的代码(在这种情况下,它将创建自己的 Hazelcast 成员并在其上运行作业),也可以在之前启动的 Hazelcast 成员上运行此代码(在这种情况下,您需要创建一个可运行的 JAR,包括运行它所需的所有依赖项):
壳
1
mvn package
2
3
bin/hz-cli submit target/pulsar-example-1.0-SNAPSHOT.jar
4
要取消作业并关闭 Hazelcast 群集,请执行以下操作:
壳
1
bin/hz-cli cancel pulsar-message-counter
2
3
hz-stop
结论
在本文中,我们演示了如何结合各种技术的优势和优势,以提供独特的开发人员体验和大规模实时处理数据的高效方法。我们将空气质量数据从Apache Pulsar流式传输到Hazelcast,在那里我们实时处理数据。云技术的上升趋势、对实时智能应用程序的需求以及大规模处理数据的紧迫性,将我们带入了实时流处理的新篇章,其中延迟的测量不是以分钟为单位,而是以毫秒和亚毫秒为单位。
Hazelcast 允许您快速构建资源高效的实时应用程序。您可以以任何规模部署它,从小型边缘设备到大型云实例集群。Hazelcast节点集群共享数据存储和计算负载,可以动态扩展和缩减。向群集添加新节点时,数据会自动在群集中重新平衡,并且当前正在运行的计算任务(称为作业)会快照其状态并使用处理保证进行缩放。Pulsar 允许您使用您选择的消息传递协议在多种类型的消费者和生产者之间快速分发事件,并充当通用消息中心。Pulsar 将计算与存储分开,允许动态扩展和高效处理快速数据。StreamNative是由Apache Pulsar和Apache BookKeeper的原始创建者组成的公司。StreamNative在云端和本地为Apache Pulsar提供了完整的企业体验。
