




一、概述
这个案例是两年前处理的一个由于OCR磁盘组磁盘头信息不一致导致的Oracle RAC集群无法启动的故障,今天做一个整理。
按照计划,春节后要对几套在Vmware虚拟环境下运行的Oracle RAC集群进行OCR磁盘组的替换操作;为了计划的顺利实施,年前就操作步骤进行了编写和测试,并成功的替换了其中一套生产环境的OCR磁盘组,因为快到春节了,所以打算节后按照既定的方案对剩余的几套环境进行替换操作。
这里我们先做一个背景介绍,这个事情的缘由是因为之前这些系统的OCR磁盘组存储链路出过故障,当时做了调整,后面又因为存储链路的问题,导致新替换的OCR磁盘组中的两块磁盘存在问题,集群一直在告警,但是并没有影响业务的正常运行;这次做调整就是为了解决OCR磁盘组告警的问题,将之前存在问题的磁盘组的磁盘头信息清除后重新添加到集群中来。本来按照年前的操作,应该是没有问题的;于是就按照之前的操作流程对这套环境进行了OCR的替换,操作后,按照流程对集群节点进行了轮流重启操作,结果在重启第一个节点的时候,就出现了无法识别votedisk磁盘的告警,导致集群无法启动的故障。接下来,咱们就一起来看看本次故障处理的整个过程;希望对大家的工作有所帮助。
二、故障现象
在替换完OCR磁盘组后,我们从节点1的集群告警信息可以清晰的看到,集群的OCR磁盘组采用High冗余模式,当前只能识别到2块votedisk磁盘,其余3块无法识别到,故而导致整个集群无法正常启动。集群在启动时,告警日志报错CRS-1637
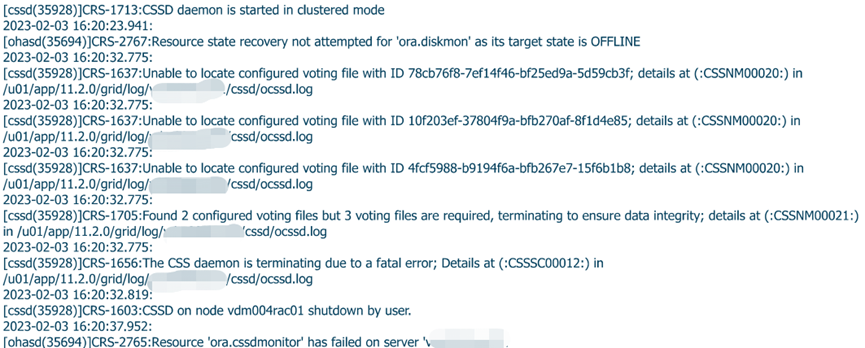
我们再来看看ocssd的日志信息,明显可以看到,目前集群只能识别到2块votedisk磁盘,其余3块无法识别。

接下来,我们继续对集群中OCR磁盘组相关的信息进行了收集,首先查看了目前集群的Votedisk信息,由于1节点已经无法正常启动集群,我们从2节点看到目前集群中的VF磁盘组的信息为新添加的OCR04磁盘组,并且能正常显示。
然后我们又在两个节点上分别对VF磁盘的磁盘头信息进行了查看,可以看到两个节点中的VF磁盘的磁盘头中的kfbh.check信息不一致 (由于篇幅问题我们将一部分磁盘头信息省略)。
node1上的VF磁盘头信息:
[root@rac01 tmp]# kfed read /dev/asm-disk-ocr001
kfbh.endian: 1 ; 0x000: 0x01
kfbh.hard: 130 ; 0x001: 0x82
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
kfbh.datfmt: 1 ; 0x003: 0x01
kfbh.block.blk: 0 ; 0x004: blk=0
kfbh.block.obj: 2147483648 ; 0x008: disk=0
kfbh.check: 2965587032 ; 0x00c: 0xb0c34458
... ...
kfdhdb.dskname: OCR04_0000 ; 0x028: length=10
kfdhdb.grpname: OCR04 ; 0x048: length=5
kfdhdb.fgname: OCR04_0000 ; 0x068: length=10
... ...
[root@rac01 tmp]# kfed read /dev/asm-disk-ocr002
kfbh.endian: 1 ; 0x000: 0x01
kfbh.hard: 130 ; 0x001: 0x82
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
kfbh.datfmt: 1 ; 0x003: 0x01
kfbh.block.blk: 0 ; 0x004: blk=0
kfbh.block.obj: 2147483649 ; 0x008: disk=1
kfbh.check: 2965587298 ; 0x00c: 0xb0c34562
... ...
kfdhdb.dskname: OCR04_0001 ; 0x028: length=10
kfdhdb.grpname: OCR04 ; 0x048: length=5
kfdhdb.fgname: OCR04_0001 ; 0x068: length=10
... ...
[root@rac01 tmp]# kfed read /dev/asm-disk-ocr003
kfbh.endian: 1 ; 0x000: 0x01
kfbh.hard: 130 ; 0x001: 0x82
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
kfbh.datfmt: 1 ; 0x003: 0x01
kfbh.block.blk: 0 ; 0x004: blk=0
kfbh.block.obj: 2147483650 ; 0x008: disk=2
kfbh.check: 2965587298 ; 0x00c: 0xb0c34562
... ...
kfdhdb.dskname: OCR04_0002 ; 0x028: length=10
kfdhdb.grpname: OCR04 ; 0x048: length=5
kfdhdb.fgname: OCR04_0002 ; 0x068: length=10
... ...
[root@rac01 tmp]# kfed read /dev/asm-disk-ocr004
kfbh.endian: 1 ; 0x000: 0x01
kfbh.hard: 130 ; 0x001: 0x82
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
kfbh.datfmt: 1 ; 0x003: 0x01
kfbh.block.blk: 0 ; 0x004: blk=0
kfbh.block.obj: 2147483651 ; 0x008: disk=3
kfbh.check: 2965587035 ; 0x00c: 0xb0c3445b
... ...
kfdhdb.dskname: OCR04_0003 ; 0x028: length=10
kfdhdb.grpname: OCR04 ; 0x048: length=5
kfdhdb.fgname: OCR04_0003 ; 0x068: length=10
... ...
[root@rac01 tmp]# kfed read /dev/asm-disk-ocr005
kfbh.endian: 1 ; 0x000: 0x01
kfbh.hard: 130 ; 0x001: 0x82
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
kfbh.datfmt: 1 ; 0x003: 0x01
kfbh.block.blk: 0 ; 0x004: blk=0
kfbh.block.obj: 2147483652 ; 0x008: disk=4
kfbh.check: 2965587035 ; 0x00c: 0xb0c3445b
... ...
kfdhdb.dskname: OCR04_0004 ; 0x028: length=10
kfdhdb.grpname: OCR04 ; 0x048: length=5
kfdhdb.fgname: OCR04_0004 ; 0x068: length=10
... ...
node2上的VF磁盘头信息:
[root@rac02 ~]# kfed read /dev/asm-disk-ocr001
kfbh.endian: 1 ; 0x000: 0x01
kfbh.hard: 130 ; 0x001: 0x82
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
kfbh.datfmt: 1 ; 0x003: 0x01
kfbh.block.blk: 0 ; 0x004: blk=0
kfbh.block.obj: 2147483648 ; 0x008: disk=0
kfbh.check: 2965587074 ; 0x00c: 0xb0c34482
... ...
kfdhdb.dskname: OCR04_0000 ; 0x028: length=10
kfdhdb.grpname: OCR04 ; 0x048: length=5
kfdhdb.fgname: OCR04_0000 ; 0x068: length=10
... ...
[root@rac02 ~]# kfed read /dev/asm-disk-ocr002
kfbh.endian: 1 ; 0x000: 0x01
kfbh.hard: 130 ; 0x001: 0x82
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
kfbh.datfmt: 1 ; 0x003: 0x01
kfbh.block.blk: 0 ; 0x004: blk=0
kfbh.block.obj: 2147483649 ; 0x008: disk=1
kfbh.check: 2965587074 ; 0x00c: 0xb0c34482
... ...
kfdhdb.dskname: OCR04_0001 ; 0x028: length=10
kfdhdb.grpname: OCR04 ; 0x048: length=5
kfdhdb.fgname: OCR04_0001 ; 0x068: length=10
... ...
[root@rac02 ~]# kfed read /dev/asm-disk-ocr003
kfbh.endian: 1 ; 0x000: 0x01
kfbh.hard: 130 ; 0x001: 0x82
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
kfbh.datfmt: 1 ; 0x003: 0x01
kfbh.block.blk: 0 ; 0x004: blk=0
kfbh.block.obj: 2147483650 ; 0x008: disk=2
kfbh.check: 2965587074 ; 0x00c: 0xb0c34482
... ...
kfdhdb.dskname: OCR04_0002 ; 0x028: length=10
kfdhdb.grpname: OCR04 ; 0x048: length=5
kfdhdb.fgname: OCR04_0002 ; 0x068: length=10
... ...
[root@rac02 ~]# kfed read /dev/asm-disk-ocr004
kfbh.endian: 1 ; 0x000: 0x01
kfbh.hard: 130 ; 0x001: 0x82
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
kfbh.datfmt: 1 ; 0x003: 0x01
kfbh.block.blk: 0 ; 0x004: blk=0
kfbh.block.obj: 2147483651 ; 0x008: disk=3
kfbh.check: 2965587072 ; 0x00c: 0xb0c34480
... ...
kfdhdb.dskname: OCR04_0003 ; 0x028: length=10
kfdhdb.grpname: OCR04 ; 0x048: length=5
kfdhdb.fgname: OCR04_0003 ; 0x068: length=10
... ...
[root@rac02 ~]# kfed read /dev/asm-disk-ocr005
kfbh.endian: 1 ; 0x000: 0x01
kfbh.hard: 130 ; 0x001: 0x82
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
kfbh.datfmt: 1 ; 0x003: 0x01
kfbh.block.blk: 0 ; 0x004: blk=0
kfbh.block.obj: 2147483652 ; 0x008: disk=4
kfbh.check: 2965587072 ; 0x00c: 0xb0c34480
... ...
kfdhdb.dskname: OCR04_0004 ; 0x028: length=10
kfdhdb.grpname: OCR04 ; 0x048: length=5
kfdhdb.fgname: OCR04_0004 ; 0x068: length=10
... ...三、故障分析
我们通过对集群告警日志、CSS日志、磁盘头信息等内容的分析, 我们可以很明确的知道此次故障的原因是由于集群启动时无法识别到VF,导致ocssd启动失败,进而导致集群无法正常启动。
四、尝试的操作
从前面的VF磁盘头信息中我们可以明确的看到两个节点的磁盘头中的checksum信息不一致。
我们知道,在Oracle RAC环境中,ASM磁盘组中的磁盘采用共享磁盘的方式,既然是集群中所有节点共享磁盘信息,那么,磁盘组中的磁盘头信息应该是一致的。我们当时怀疑,由于替换的磁盘是之前链路出现故障的磁盘,是不是由于操作系统缓存等的影响,导致现在看到的磁盘状态不一致呢?所以,我们对节点1的操作系统进行了重启操作,但是重启后,集群任然无法正常启动,告警日志中显示的内容和之前的完全一致。由于是生产环境,目前2节点还没有进行重启操作,所以其它的操作没有进行尝试。
虽然之后我们又进一步对集群中的ASM磁盘组及磁盘信息的状态进行了查看,包括对磁盘的权限还有存储链路以及UDEV规则配置也进行了进一步的核查,一切都正常。似乎除了VF磁盘头的checksum信息不一致外,其余的状态都是正常的。似乎问题就此陷入到了僵局。
五、解决方案
综上,我们怀疑一个点有可能会导致ASM磁盘头信息不一致,那就是当时我们在清理磁盘头信息的时候写入的信息过少,导致一部分信息没有清理干净导致此次故障。但无论是什么原因导致,最终我们可以看出,此次问题的根因就是VF磁盘头的信息不一致,那么,要解决这个问题,必须要申请维护窗口,然后对损坏的VF磁盘组进行修复。为了对业务影响范围减少到最低,我们当时提出了两套解决方案。
其一,新搭建一套单机环境作为备用环境,然后对生产数据库进行备份,备份后在单机环境进行恢复;之后在集群中新加磁盘资源,然后重建OCR磁盘组。
其二,在现有的环境中,将集群启动到独占模式(当然这种方式会影响业务,需要停机操作),然后新加磁盘资源,通过恢复OCR磁盘组的方式,修复OCR和VF。
六、修复问题
通过与用户沟通后,我们选择的是第二套方案,就是通过OCR备份恢复的方式,对OCR和VF进行了修复,下面是详细的修复步骤。
1、添加新的共享磁盘资源,并对新加的磁盘进行了重新识别,权限配置以及UDEV规则的配置,这里就不详细介绍这一步骤,相信大家都已经很熟悉了。
2、对生产数据库进行一致性全备份,这一步大家可以根据自己生产库的规模以及实际情况选择对应的备份方式,我们这里采取的是数据泵的方式进行了全备份。
3、在2节点对当前的OCR磁盘组进行备份
# ocrconfig -manualbackup
# ocrconfig -showbackup4、重启2节点,在1节点将集群以独占模式启动
# crsctl start crs -excl -nocrs5、启动后,创建新的OCR磁盘组
SQL>create diskgroup OCR05 high redundancy disk '/dev/asm-disk-ocr05001','/dev/asm-disk-ocr05002','/dev/asm-disk-ocr05003',’ /dev/asm-disk-ocr05004’,’ /dev/asm-disk-ocr05005’;6、修改OCR定义文件中的OCR磁盘组信息,将其中的ocrconfig_loc信息修改为新的OCR磁盘组名称,我们这里是+OCR05
# vim /etc/oracle/ocr.loc7、通过备份的OCR信息对OCR进行恢复操作
# ocrconfig -restore /oracle/app/11.2.0/grid/cdata/xxx-cluster/backup_20230209_144236.ocr
# ocrcheck
Status of Oracle Cluster Registry is as follows :
Version : 3
Total space (kbytes) : 262120
Used space (kbytes) : 3316
Available space (kbytes) : 258804
ID : 540497475
Device/File Name : +OCR05
Device/File integrity check succeeded
Device/File not configured
Device/File not configured
Device/File not configured
Device/File not configured
Cluster registry integrity check succeeded
Logical corruption check succeeded8、对VF磁盘组进行替换操作,将VF磁盘组替换为新加的OCR05磁盘组
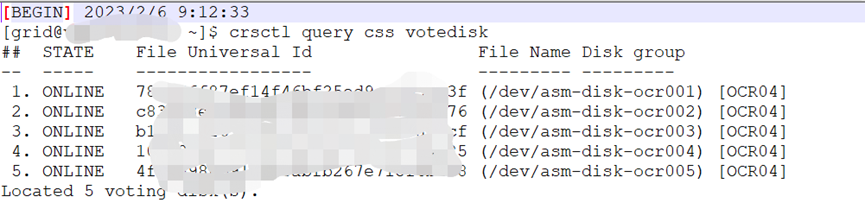
# crsctl query css votedisk
# crsctl replace votedisk +OCR05
# crsctl query css votedisk9、重启集群
# crsctl stop crs -f
# crsctl start crs
# crsctl status res –t好了,以上过程就是此次故障处理及分析的全部心路历程,希望通过对此次故障处理过程的描述和汇总,对大家的日常工作有所帮助,以上文章内容描述如有不当和纰漏之处,欢迎大家指正。




