




整库入仓的需求和挑战 基于 Flink 的实时计算平台 FlinkCDC 实时整库入仓 FlinkCDC 实时模式演变 未来展望与计划
 GitHub 地址
GitHub 地址 一、整库入仓的需求与挑战
数据入仓的需求起源
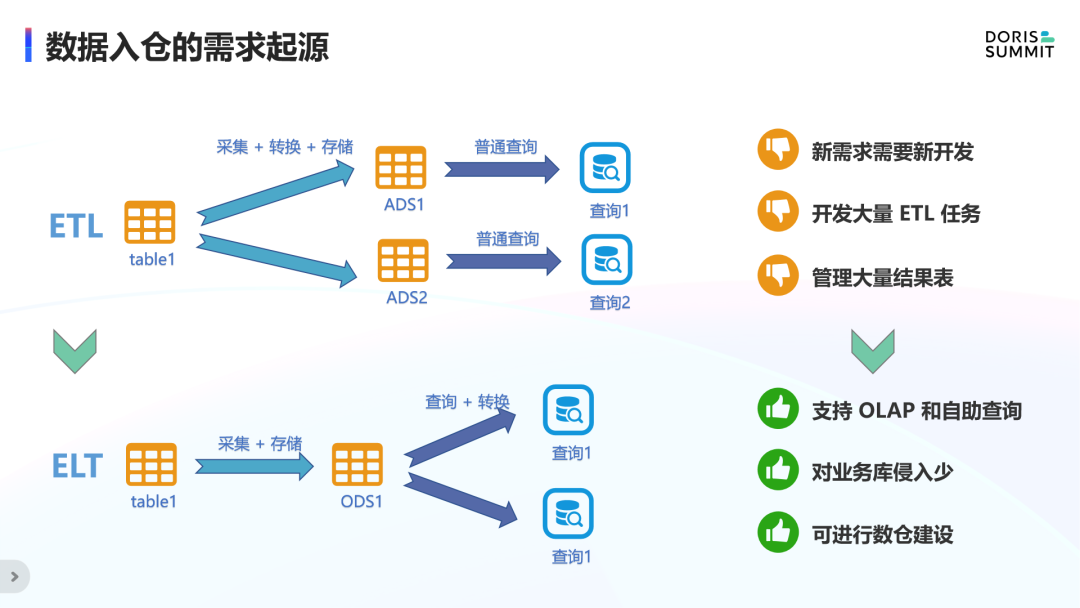
ETL 是用来描述将数据从源端经过抽取、转换、加载至目的端的过程,通常其数据处理依赖计算引擎的能力,一个ETL任务对应一个业务查询需求;ELT 则是将源端数据采集到一个具备较强运算能力的数据库,然后发挥数据库自身的并行计算能力来满足各种查询需求。
随着业务需求日益增多、计算逻辑更加复杂,通过 ETL 来处理时,需要开发大量的 ETL 任务并且管理大量的结果表,而新的业务需求则需要开发新的 ETL 任务,开发运维成本巨高,所以基于 ELT 的数据入仓建设尤为重要。除了可以降低上述的建设成本,还可以减少对业务库的侵入,提供高效的 OLAP 分析能力。
传统数据入仓架构1.0
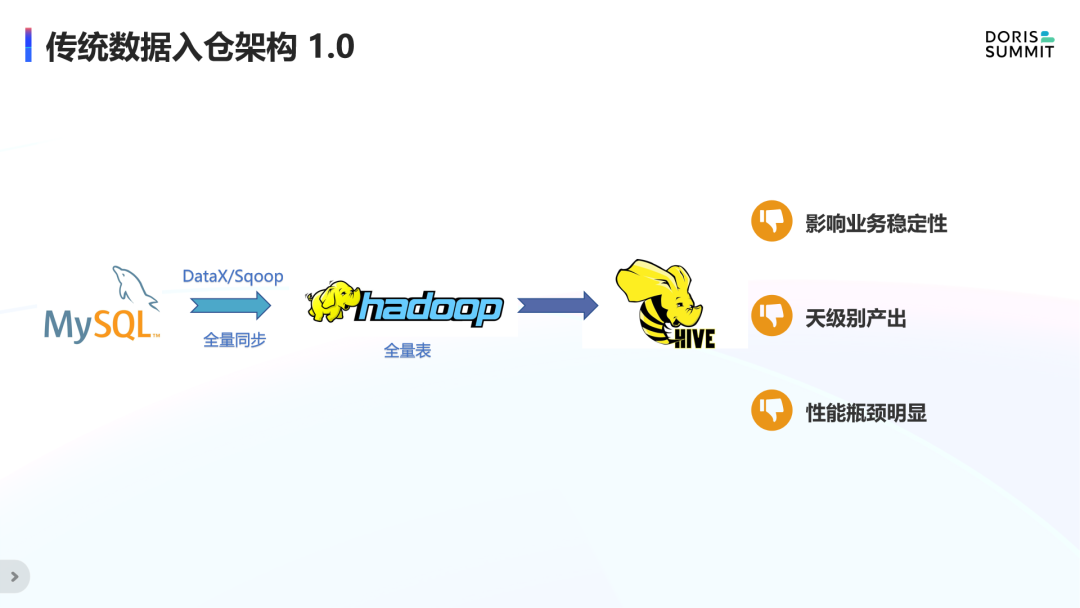
在早期的数据入仓架构中,一般会每天 SELECT 全量数据导入数仓后再做离线分析。这种架构有几个明显的缺点:
每天查询全量的业务表会影响业务自身稳定性。
离线天级别调度的方式,天级别的产出时效性差。
基于查询方式,随着数据量的不断增长,对数据库的压力也会不断增加,架构性能瓶颈明显。
传统数据入仓2.0
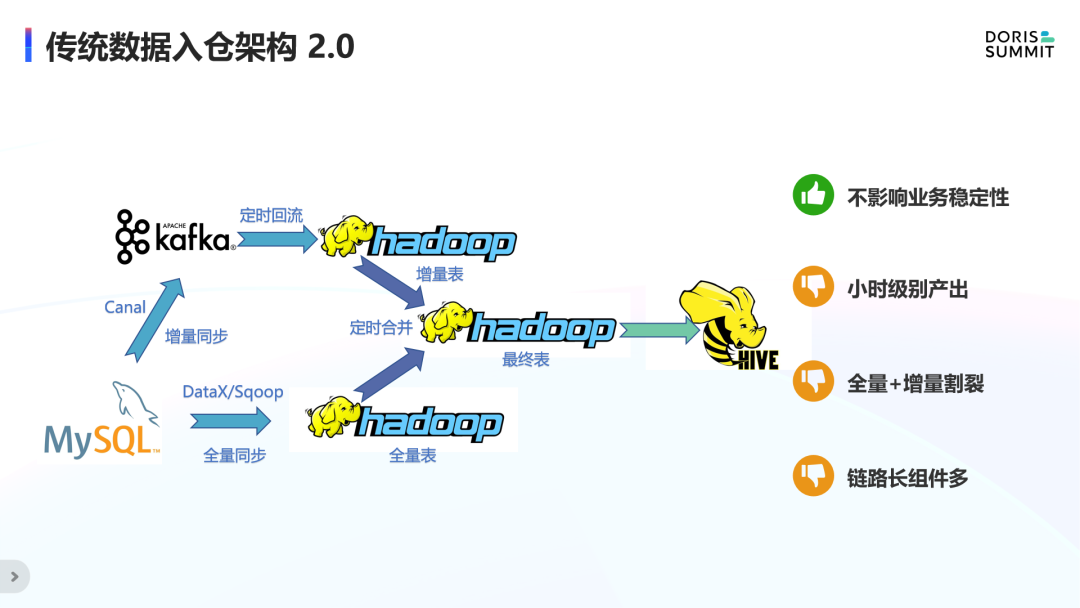
整体来说,Lambda 架构的扩展性更好,也不再影响业务的稳定性,但仍然存在一些问题:
依赖离线的定时合并,只能做到小时级产出,延时还是较大;
全量和增量是割裂的两条链路;
整个架构链路长,需要维护的组件比较多,该架构的全量链路需要维护 DataX 或 Sqoop 组件,增量链路要维护 Canal 和 Kafka 组件,同时还要维护全量和增量的定时合并链路。
CDC 入仓架构
随着计算引擎和 MPP 数据库的发展, CDC 数据入湖架构,可分为两个链路:
· 有一个全量同步 Spark 作业做一次性的全量数据拉取;
· 还有一个增量 Spark 作业通过 Canal 和处理引擎将 Binlog 数据准实时地同步到 Doris 表中。
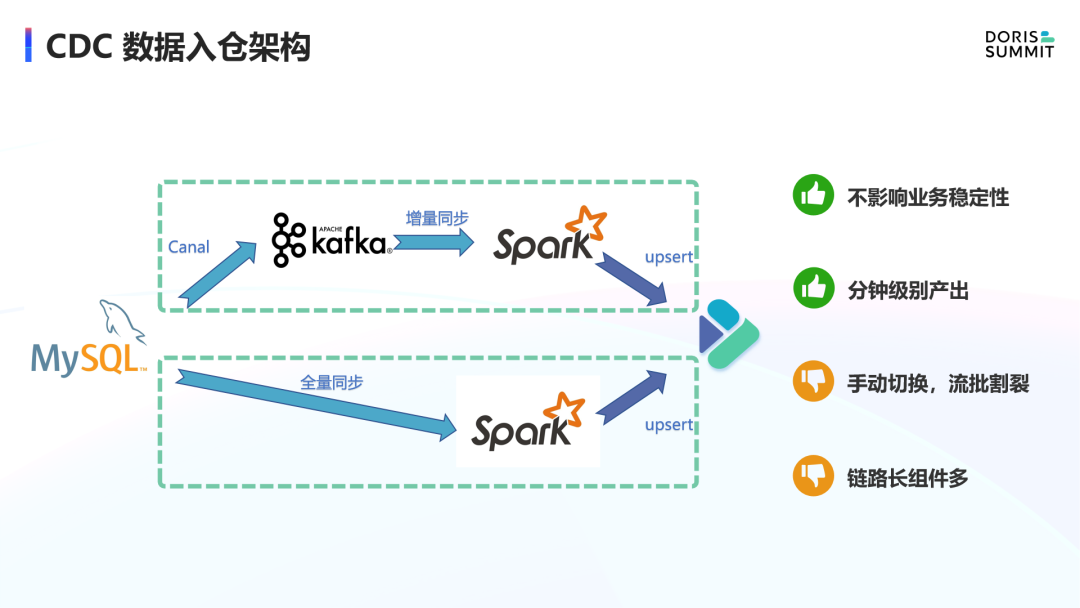
这个架构虽然利用了 Doris 的更新能力,无需周期性地调度全量合并任务,通过 Spark 能做到分钟级延迟。但是全量和增量仍是割裂的两个作业,全量和增量的切换仍需要人工的介入,并且需要指定一个准确的增量启动位点,否则的话就会有丢失数据的风险。可以看到这种架构是流批割裂的,并不是一个统一的整体。
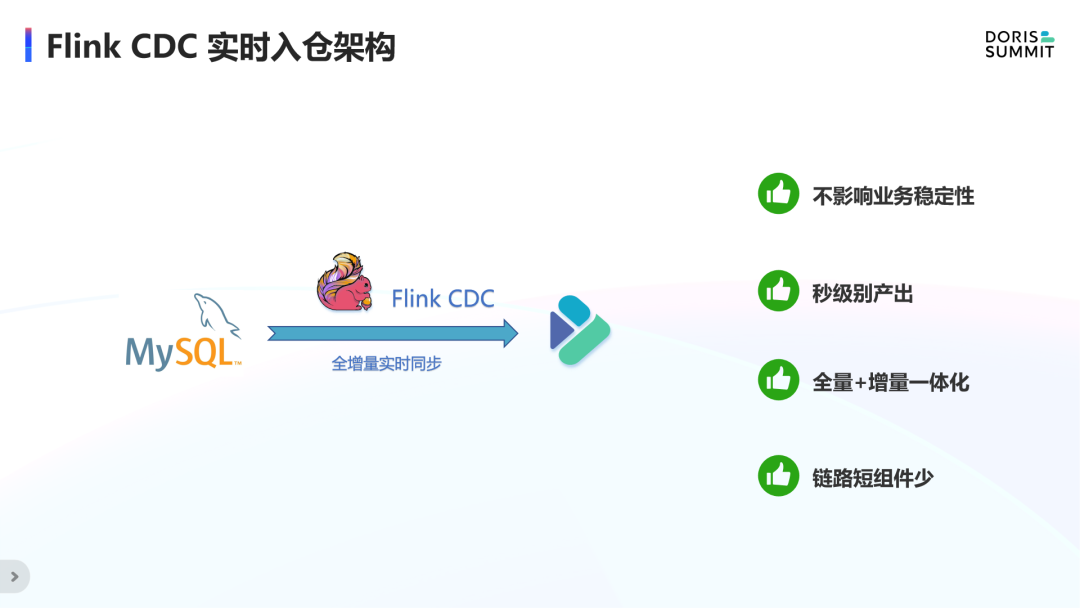
FlinkCDC 实时入仓架构
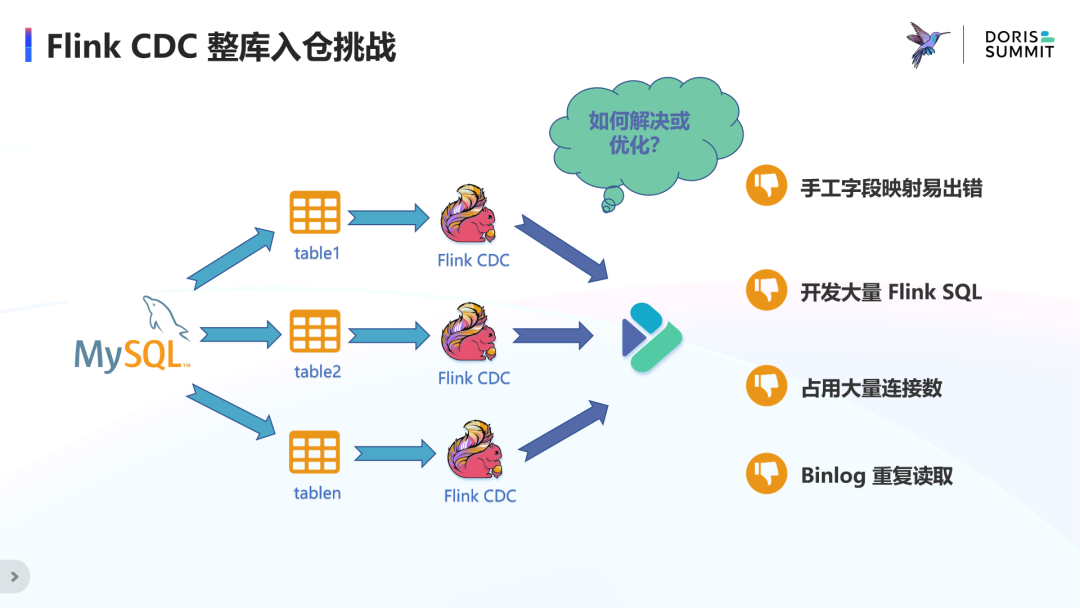
FlinkCDC 整库入仓挑战
FlinkCDC 模式演变挑战
二、基于 Flink 的实时计算平台
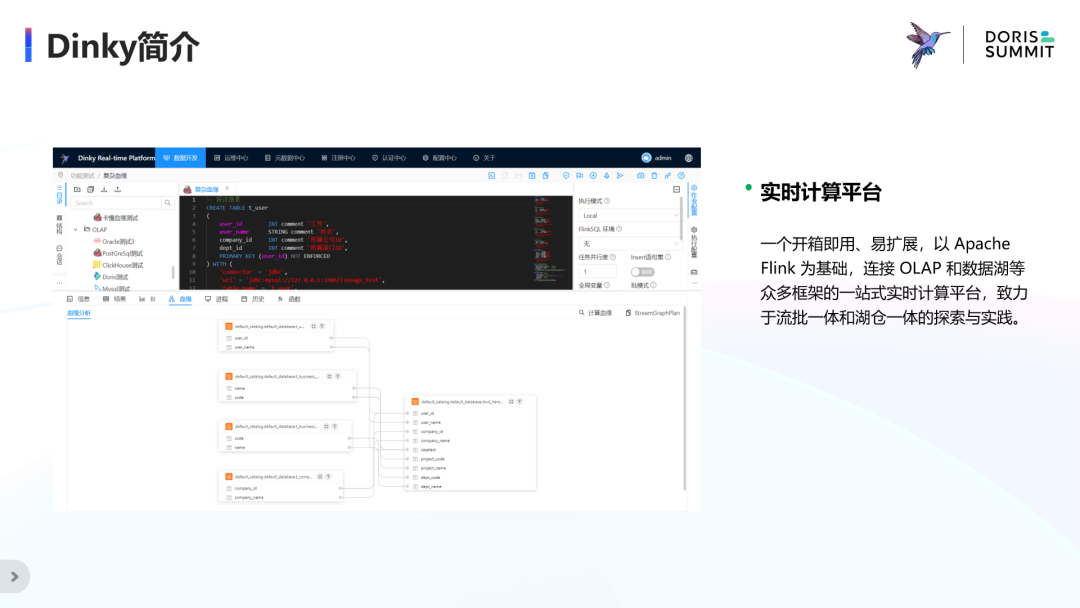
Dinky 简介
Dinky 发展历程

Dinky 主要功能

在数据开发中提供了用户在生产中常用的一些辅助功能,如 Flink SQL 自动提示与补全、语法校验、调试查询、血缘分析、Catalog 管理、Jar 任务提交、UDF 动态加载、全局变量、执行环境、语句生成和检查点托管等功能,配合资源管理来协作完成各类数据开发需求,改善用户的开发体验。
在任务运维中主要是对 Flink 任务和集群的监控与报警,同时记录各 Flink 实例的 Metrics,做到统一管理。
在最新的版本里也提供了对企业级功能的支持,如多租户、角色权限等。
Dinky 基于 Flink 的数据平台的定位,也促使其可以很好的融入各开源生态,如 Flink 各类衍生项目、海豚调度、Doris 和 Hudi 等数据库,进而来提供一站式的开源解决方案。
Dinky 核心优势
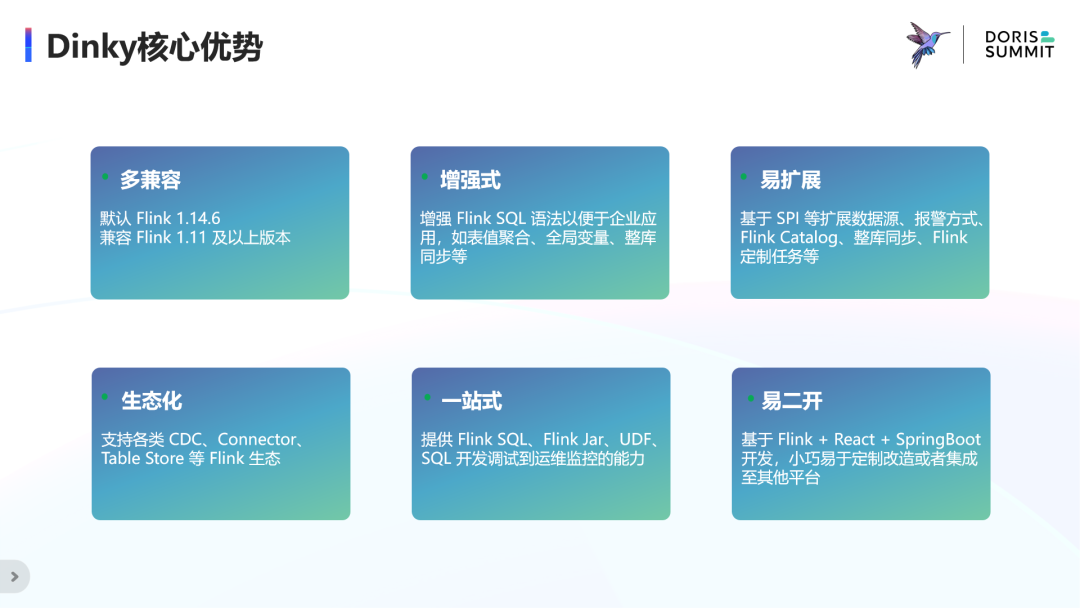
首先,它兼容 Flink 1.11 及以上版本,扩展新版本支持的成本非常低,也可以扩展用户自身二开的 Flink。
而在 FlinkSQL 方面,它扩展了 FlinkSQL 的一些额外语法以便于企业用户可以低成本使用,如全局变量、整库同步等。
在扩展性上,可以基于 SPI 等方式快速扩展 Flink 定制任务、整库同步、Catalog 管理、数据源、报警方式等功能,以让企业用户可以基于此框架来低成本实现自身业务。
在开源生态圈里,支持刚刚所提到的各类开源项目,而更多的生态项目也正逐步支持。
此外它可以通过近一站式的数据开发模式,包含 Flink SQL、Jar、UDF 等的开发调试运维,未来也将计划支持 DataStream 的在线开发运维。
最后正如其名 Dinky 一样小巧精致,基于 Flink+React+SpringBoot 开发,架构简单且部署方便,易于企业用户进行定制改造或集成到其他平台。
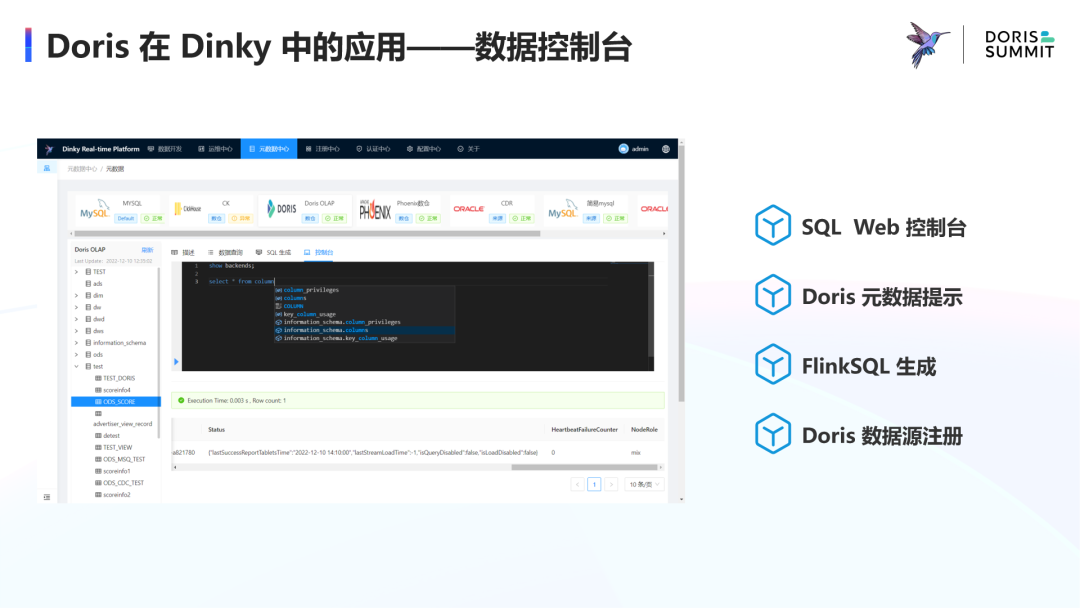
Doris 在 Dinky 中的应用——数据控制台
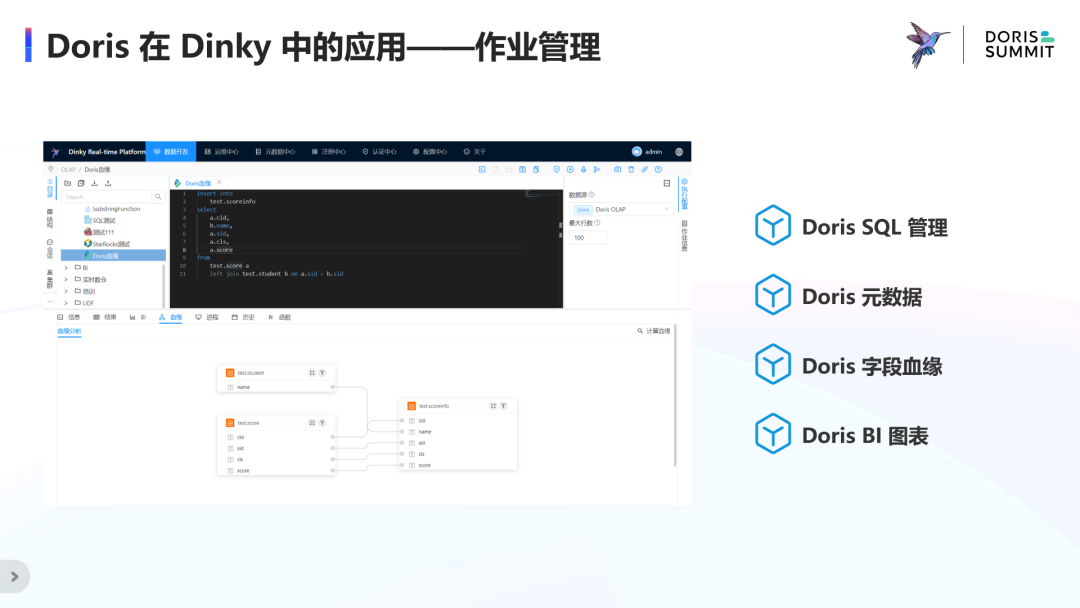
Doris 在 Dinky 中的应用——作业管理
Doris 在 Dinky 中的应用—— FlinkSQL 读写
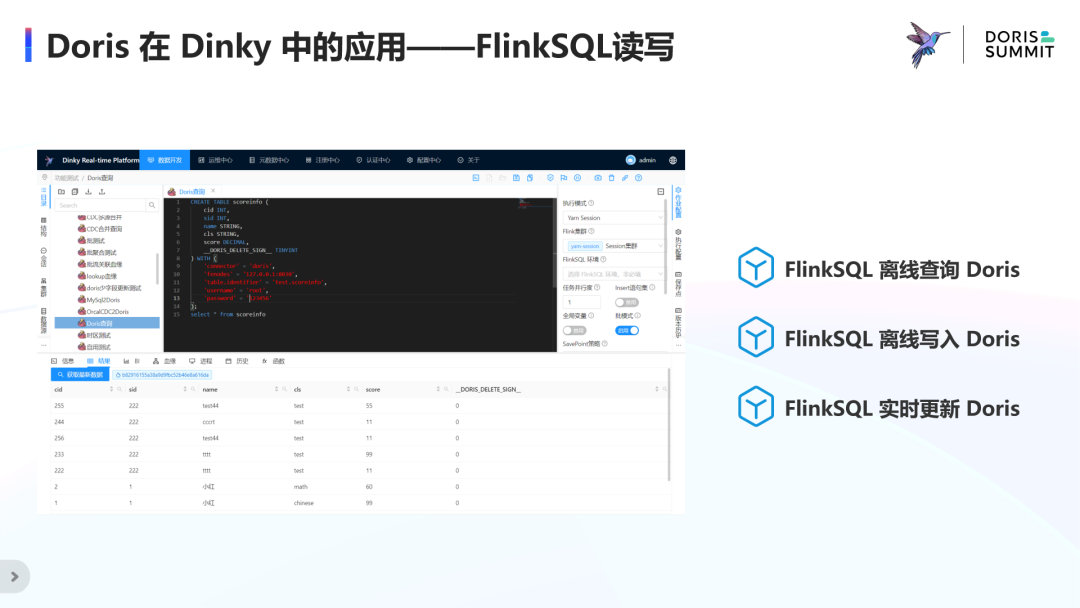
首先是离线查询,即对 Doris 进行有界的流查询或者直接使用批查询来读取 Doris 中的数据,通过 doris.filter.query 参数可以利用 Doris 自身极速的查询引擎提前过滤数据,来将两者各自的优势很好地融合在一块。
然后是离线写入,即可以使用 FlinkSQL 以离线的方式将数据按批次写入 Doris 中,写入支持数据更新。
最后是实时更新,通过 FlinkCDC 和 Flink SQL 将数据库日志或流数据实时处理并写入 Doris 数据库,支持 Exactly once 语义。
Doris 在 Dinky 中的应用—— FlinkCDC 整库入仓 Doris
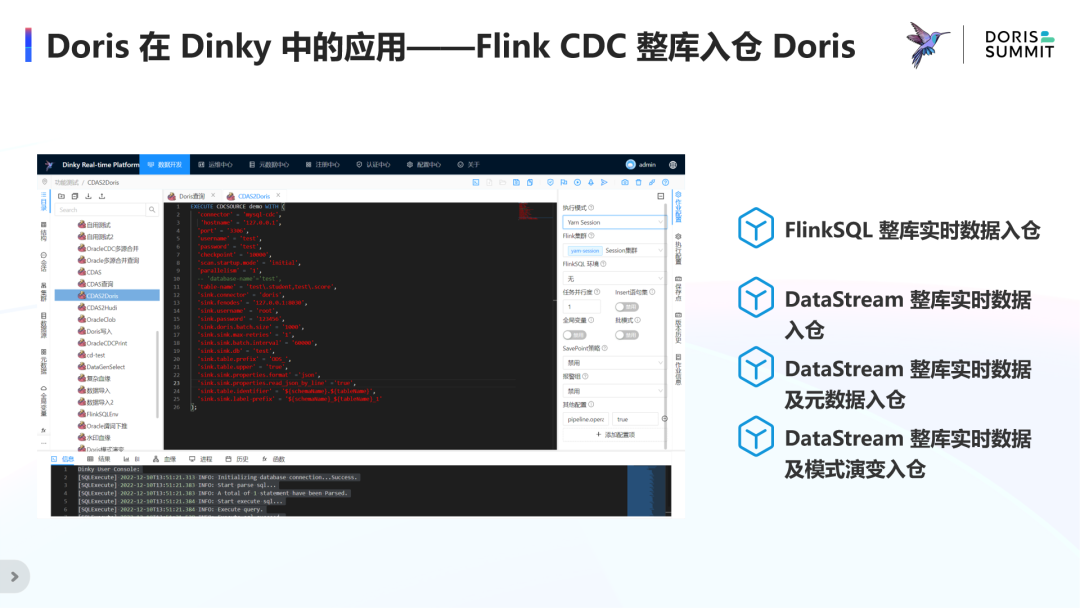
三、FlinkCDC 实时整库入仓
那接下来将重点介绍 Dinky 在 FlinkCDC 整库入仓 Doris 的实现及优化细节。
FlinkCDC 实时整库入仓挑战
用户想要什么
用户想要这些
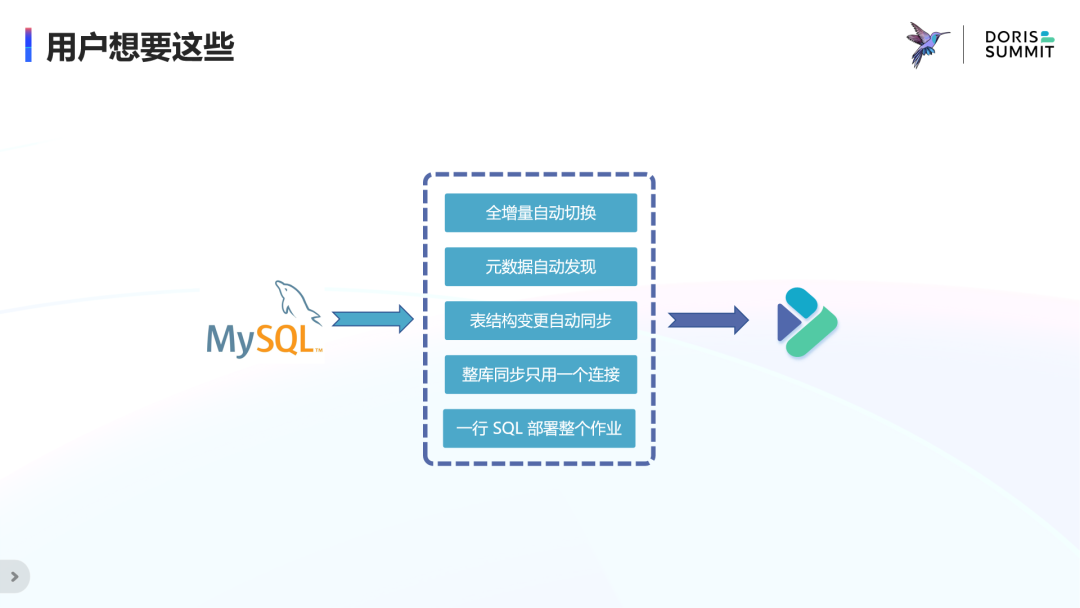
· 首先,用户肯定想把数据库中全量和增量的数据都同步过去,这就需要这个系统具有全增量一体化、全增量自动切换的能力,而不是割裂的全量链路 + 增量链路。
· 其次,用户肯定不想为每个表去手动映射 schema,这就需要系统具有元信息自动发现的能力,省去用户在 Flink 中创建 DDL 的过程,甚至帮用户自动在 Doris 中创建目标表。
· 另外,用户还希望源端表结构的变更也能自动同步过去,不管是加列减列和改列,还是加表减表和改表,都能够实时的自动的同步到目标端,从而不丢失任何在源端发生的新增数据,自动化地构建与源端数据库保持数据一致的 ODS 层。
· 更重要的是,还需要有具备生产可用的整库同步能力,不能对源端造成太大压力,影响在线业务,即只使用一个连接数。
上述四个核心功能基本组成了用户理想中所期待的数据集成系统,而这一切如果只需要一行 SQL,一个Job就能完成的话,那就更完美了。我们把中间的这个系统称为 “全自动化数据集成”,因为它全自动地完成了数据库的入仓入湖,解决了目前遇到的几个核心痛点。而且目前看来,Flink 是实现这一目标非常适合的引擎。
分析问题现状
接下来我们分析下这五点如何实现。
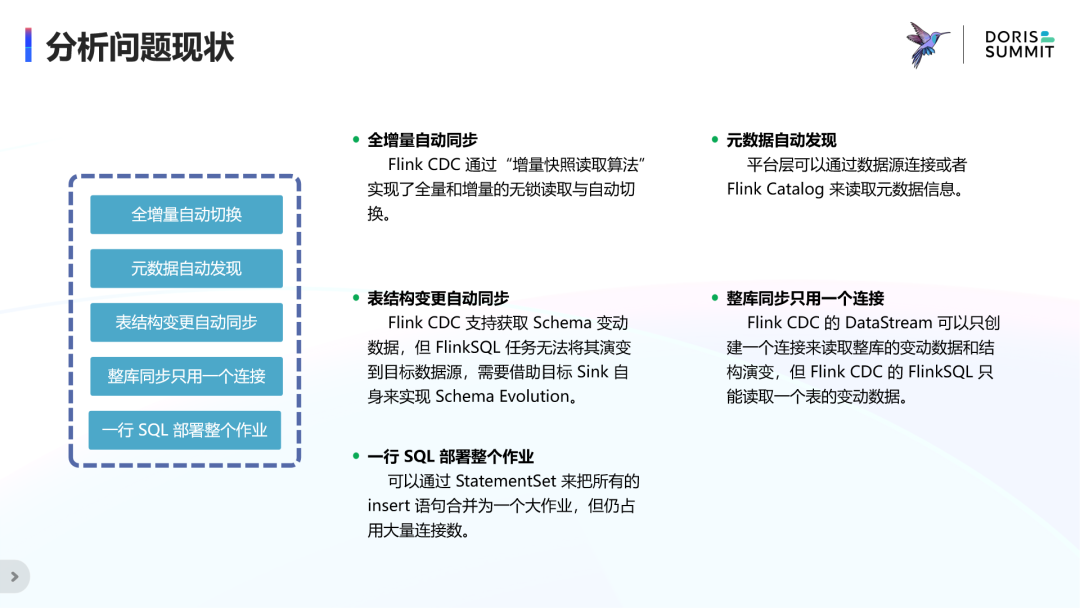
· 首先,对于全增量自动同步,Flink CDC 已经通过“增量快照读取算法”实现了全增量无锁读取和自动切换的能力,这也是 Flink CDC 的亮点之一。
· 在元数据的自动发现上,可以通过 Flink 的 Catalog 接口无缝对接上,也可以通过数据源链接来获取元数据信息,Dinky 内置了数据源注册及元数据查询功能,可以自动发现 MySQL 等数据源中的表和 schema。
· 在表结构变更的自动同步方面,FlinkCDC 支持获取 Schema 变动数据,但 FlinkSQL 任务无法将其演变到目标数据源,需要借助目标 Sink 自身来实现 Schema Evolution。
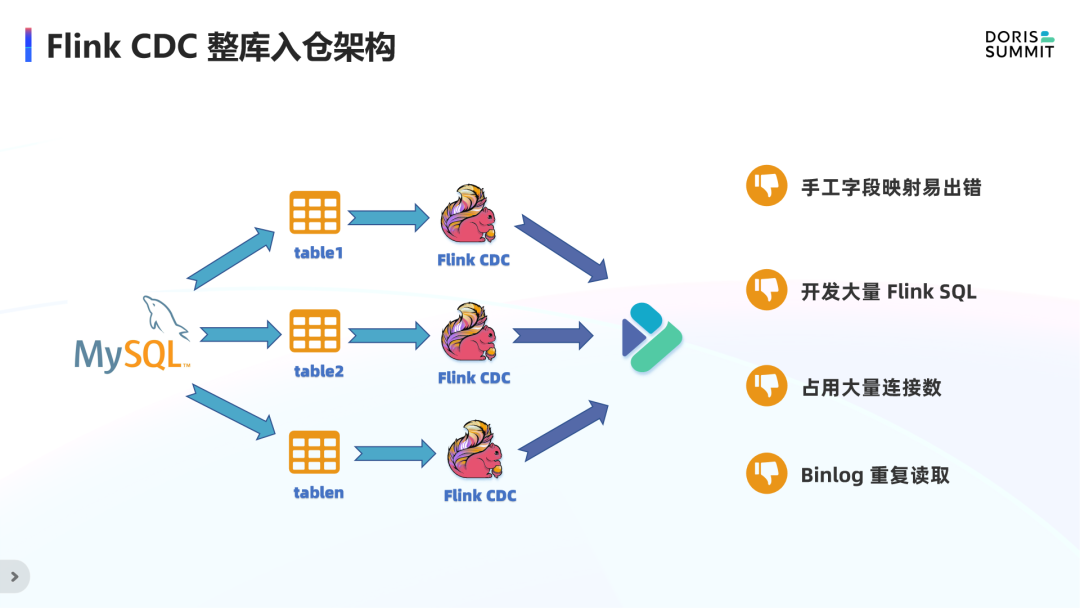
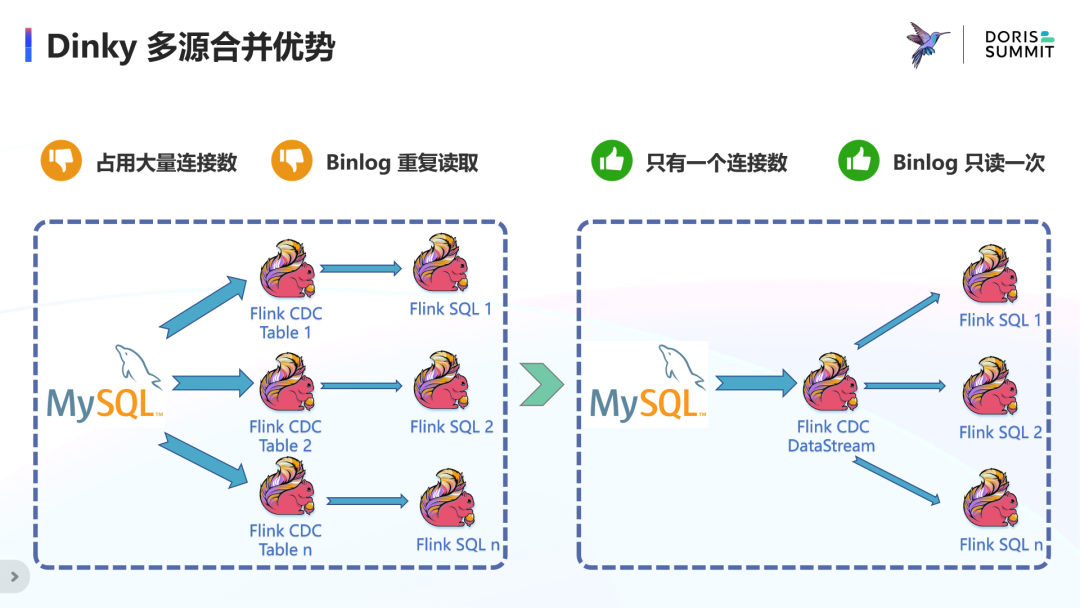
· 在整库同步只用一个连接方面,FlinkCDC 的 DataStream 可以只创建一个连接来读取整库的变动数据和结构变更,而 FlinkSQL 只能读取一个表的变动数据。
· 最后关于一行SQL部署整个作业,可以通过 StatementSet 把所有 insert 语句合并为一个大作业,但仍占用大量连接数和重复读取 Binlog。可行的一种思路是通过 DataStream 对一个 Source 进行分流,分别写入对应的 Sink。
整库入仓 Doris 思路
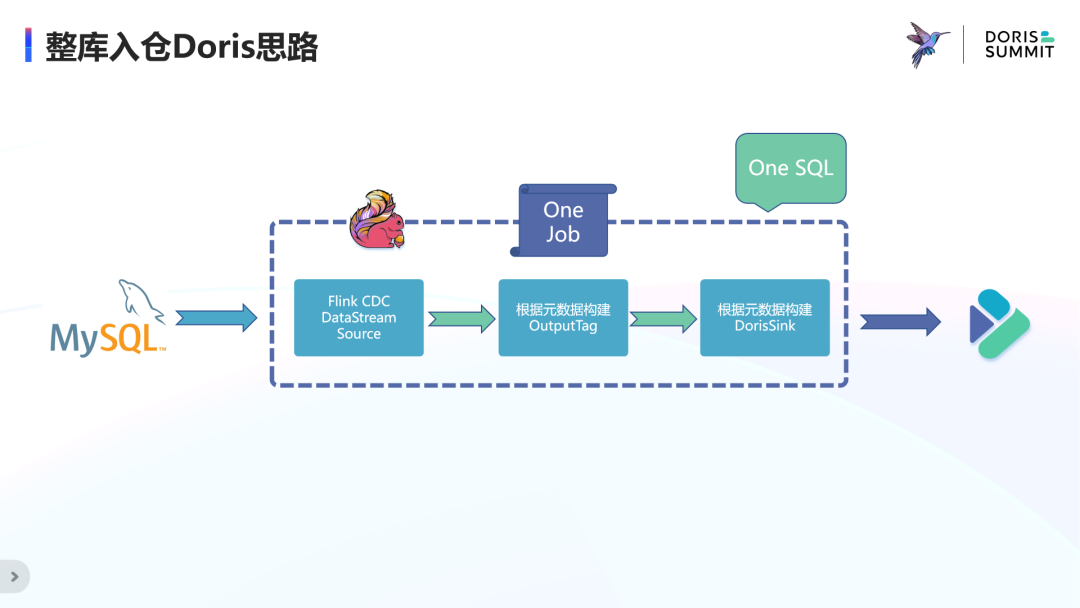
于是整库入仓 Doris 的实现思路可以总结为三步:
通过 FlinkCDC 构建库级别的 DataStream Source 来自动发现整个库的数据和结构变动;
根据元数据构建侧输出流,来进行过滤分流操作;
根据元数据构建对应的 DorisSink。
通过引入类似于 CDAS 语法,一行 SQL 语句就能完成整库同步作业的定义,并且实现了 source 合并的优化,减轻对源端数据库的压力。
Dinky CDC Source 思路
CDAS 是基于 Catalog 的语法,而 Dinky 自身实现了类似的语法——CDCSOURCE,区别于 CDAS,它无需借助 Catalog 即可使用。
CDCSOURCE 也会解析成一个 Flink 作业执行,可自动解析配置参数,将指定的一个或多个数据库的数据全量+增量同步到下游任意数据源,也支持分库分表的同步。
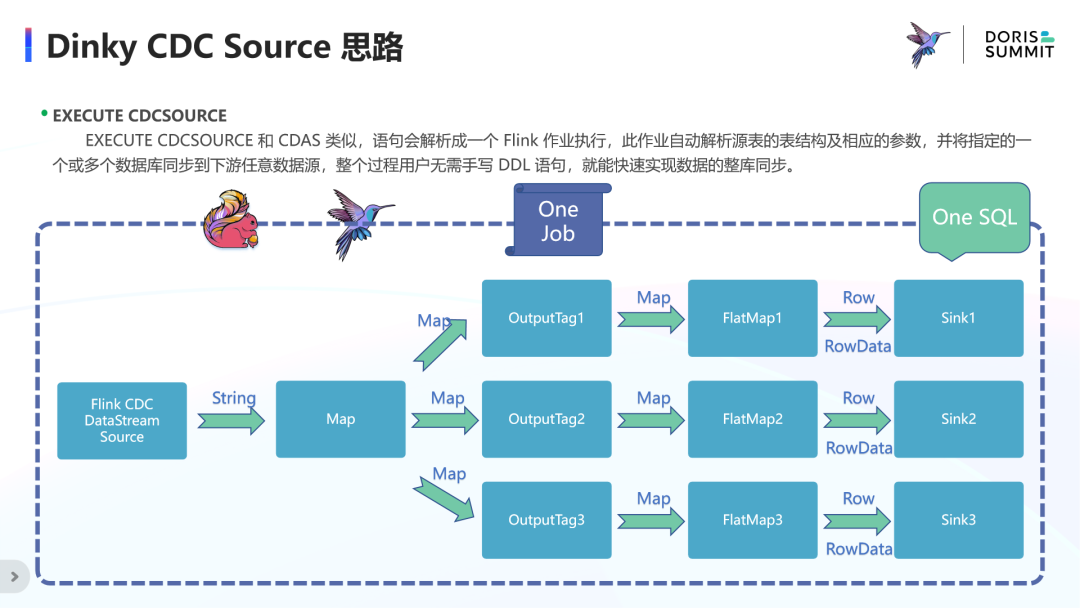
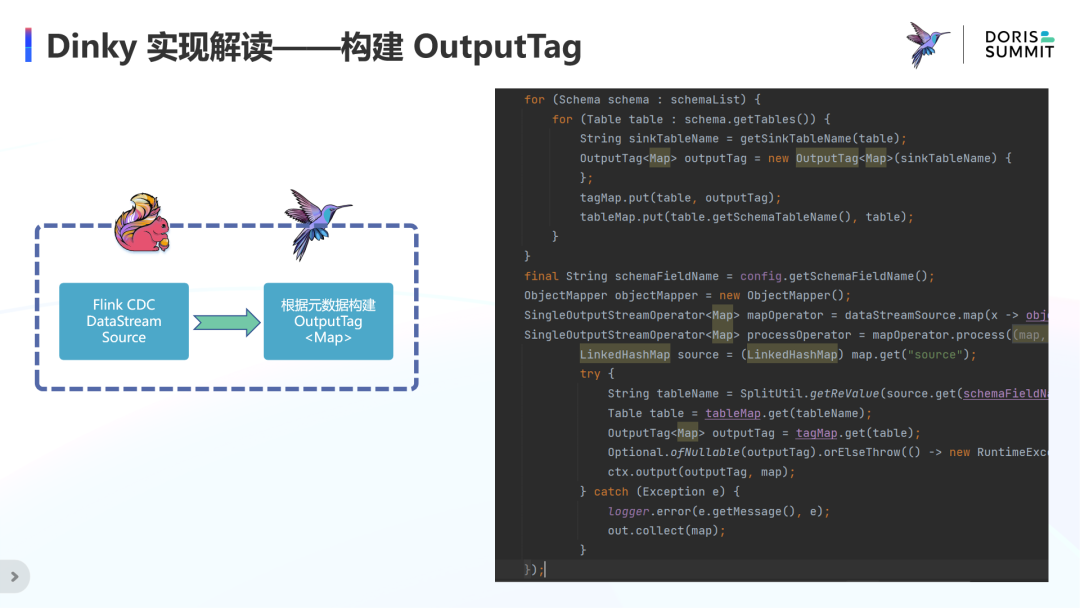
如图所示是 CDCSOURCE 的基本原理,将 FlinkCDC DataStream Source 中获取的变动数据的序列化字符串解析为 Map,根据 Map 的元数据信息将数据分发到对应的 OutputTag,之后通过 FlatMap 转换为 RowData 供 Sink 写入到目标数据源。看似非常简单,但实现的细节和难点也很多,接下来我们详细了解下 Dinky 的源码实现。
Dinky 实现解读——多源合并
Dinky 多源合并优势
Dinky 实现解读——构建 OutputTag
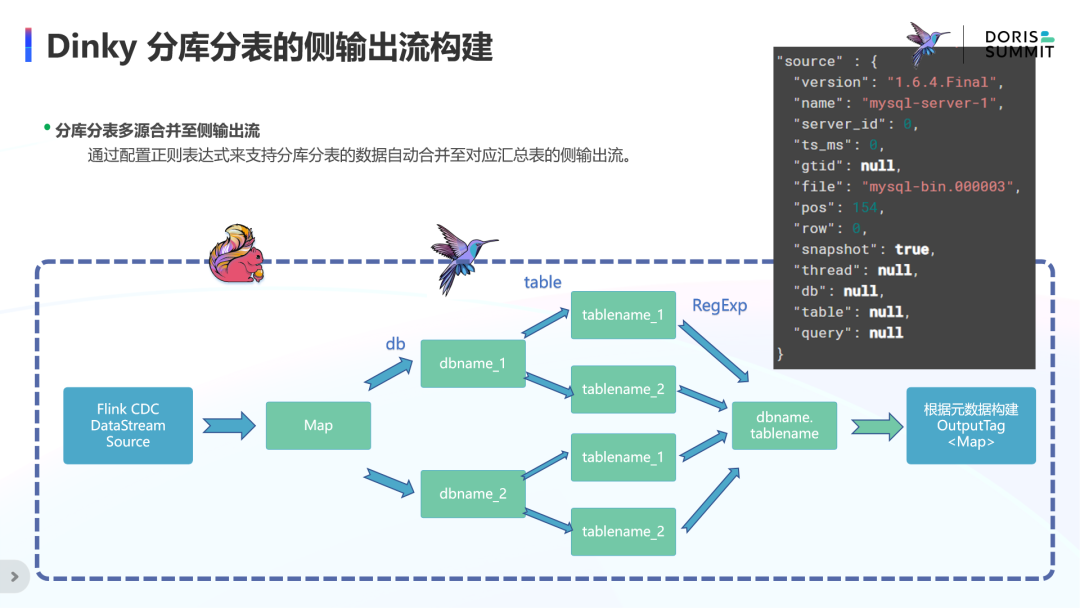
Dinky 分库分表的侧输出流构建
在构建分库分表的旁路输出时,通过正则表达式来匹配事件流中元数据信息的库表名,将符合目标表正则表达式的事件流合并到目标表的侧输出流。
Dinky 实现解读——构建 SQLSink
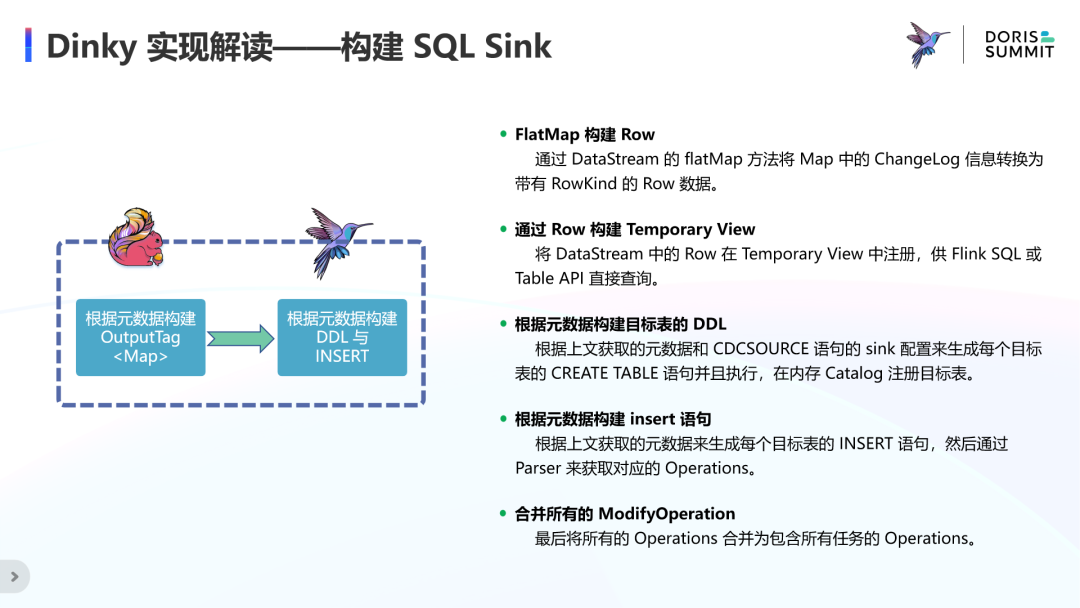
第一步,先通过 DataStream 的 flatMap 方法将 Map 中的事件流转换为带有 RowKind 的流数据;
第二步,将 DataStream 中的流数据在 Temporary View 中注册,供顶层 API 直接查询;
第三步,根据元数据信息和 CDCSOURCE 语句的 sink 配置模板来生成每个目标表的 CREATE TABLE 语句并且执行,即在内存 Catalog 中注册目标表;
第四步,根据元数据信息来生成每个目标表的 INSERT 语句,然后通过 Parser 来获取对应的 Operations;
第五步,将所有的 Operations 合并为包含整库所有任务的 Operations,进行作业提交。
Dinky FlatMap 构建 DataStream Row

在第一步将事件流转换为流数据时,是依赖如右上图 Debezium JSON 的 before 和 after 以及 op 属性。before 是变动数据的原始内容,after 为变动数据的最新内容,op 则是本次变动事件的更新状态,主要有 r、c、u、d 四种情况,分别对应全量扫描、新增、更新、删除事件。
在 FlatMap 中对不同事件进行不同的处理,全量扫描和新增事件直接取最新数据转换为 INSERT 类型的流数据;删除事件则直接取原始数据转换为 DELETE 类型的流数据;更新事件需要两步,先把原始数据转换为 UPDATE_BEFORE 类型的流数据,再把最新数据转换为 UPDATE_AFTER 类型的流数据。
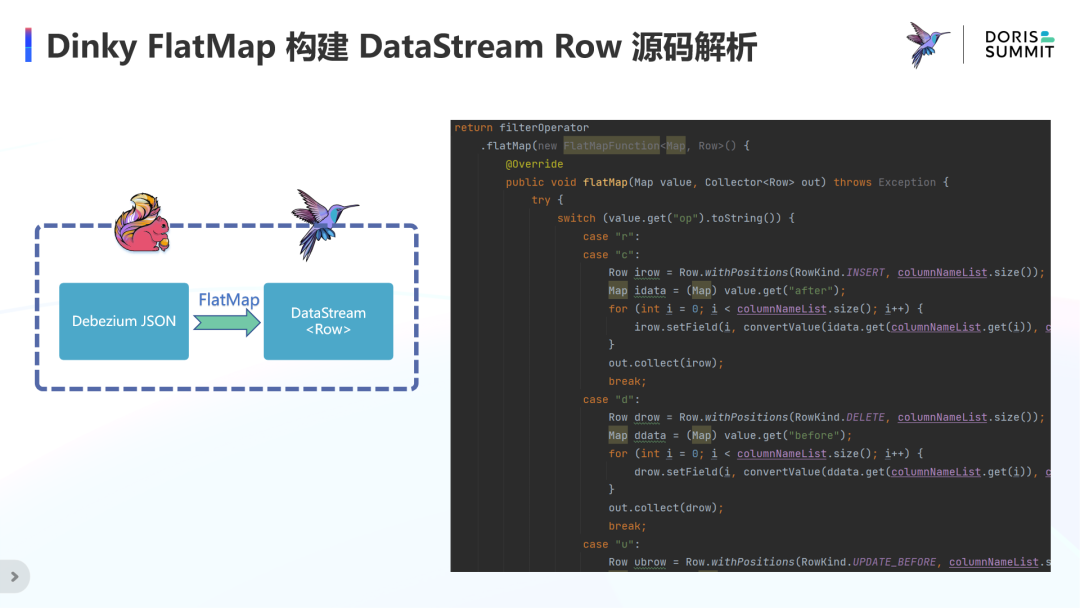
其源码实现也非常简单,主要是在 FlatMap 算子中根据 Map 中的 op 属性值进行分支处理,分别构建刚刚讲到的对应事件类型的 Row,同时进行数据类型的转换,然后写入 Collector 中即可。
Dinky 动态构建 FlinkSQL Sink

Dinky 实现解读——构建 DataStream Sink

Dinky 实现解读——构建支持元数据写入的 DataStream Sink
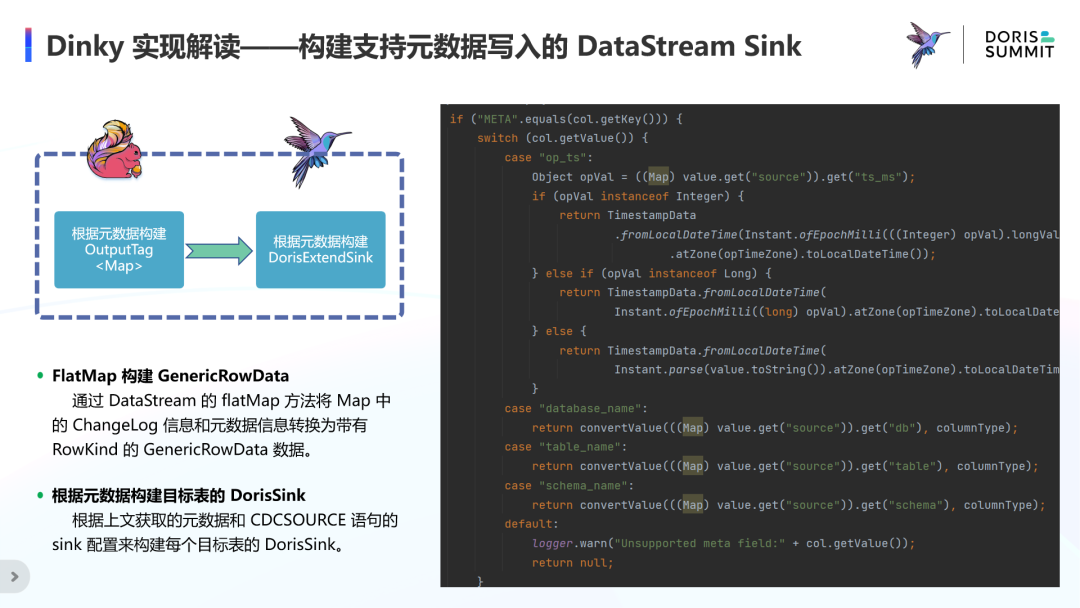
主要是 DataStream 在 FlatMap 中将事件流的业务数据与元数据信息转变为流数据,如左图所示,从事件流 Map 中的元数据信息提取对应数据然后追加到流数据里。
以上就是 Dinky 的 CDCSOURCE 实现的具体思路。
四、FlinkCDC 实时模式演变
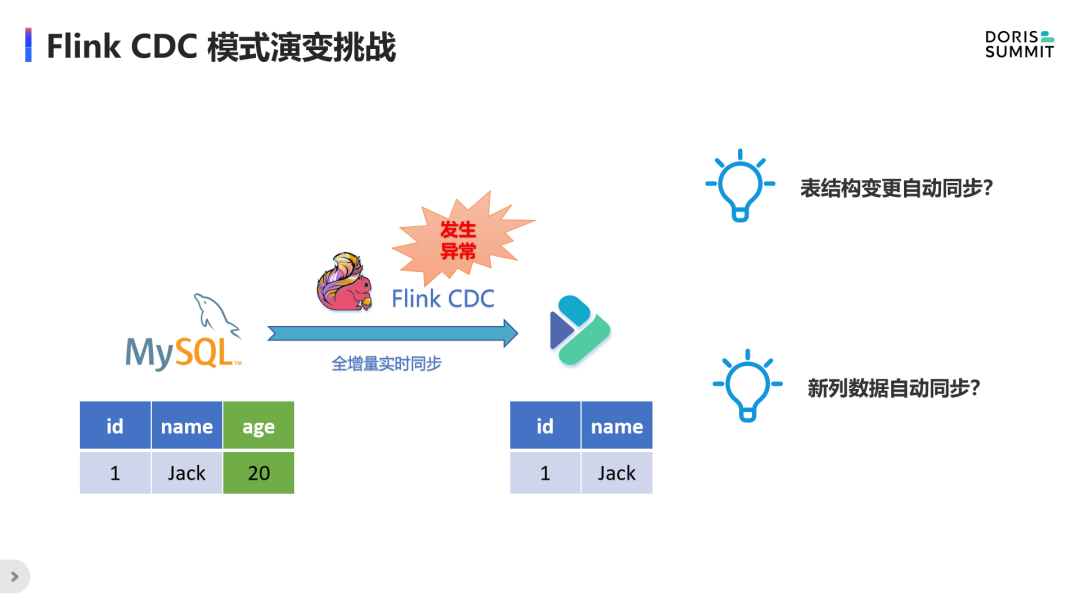
此外,还有一个用户比较关切的问题,如何在整库同步中实现自动模式演变。
FlinkCDC 模式演变挑战

我们再来回顾下模式演变的挑战,在源库表结构发生变动时,如新增列 age,但目标端无法同步新增,且 Flink 任务的计算逻辑无法变更,导致无法将新列的数据写入目标端,造成任务异常。那如何实现表结构变更自动同步及新列数据自动同步呢?接下来会分享下目前阶段我们的一些探索经验。
Doris Light Schema Change 介绍

Light Schema Change 是 Doris 最新的一种在线进行加减列或修改列的实现方案,相对于其之前支持的 3 种 Schema Change 方式,Light Schema Change 具备解决 Schema 不一致问题、全局 Schema Cache、支持物化视图、解决数据重写问题的优势,由于其只修改了 FE 的元数据,通过对 BE 读写流程进行修改来支持获取正确的 Schema 信息,性能便达到毫秒级别,这也为在实时整库同步时同步变更 Schema 提供了基础。
在 Doris 最新 1.2 版本创建表时开启 Light Schema Change 即可使用该特性。
Doris Light Schema Change 对模式演变的支撑

此前 Doris 旧版本在处理 Flink 的模式演变时,通常会由于 Doris 进行 Schema Change 的成本较高,较高的耗时期间无法写入数据,直接导致阻塞上游数据,造成数据积压。此外还需要人工解析并进行 Doris Schema 的更新维护,重启 Flink 作业来构建最新的执行计划。
当我们使用 Doris 1.2 版本,开启 FlinkCDC 的 schame.changes 参数,开启 Doris 表的 Light Schema Change 参数时,可以通过最新版本的 Doris 连接器实现自动识别 DDL 操作并毫秒级执行完成,避免双写和阻塞数据的问题,自动序列化,无需关心 Schema 变动,即无需重启 Flink 作业。
Dinky 实现解读——构建 DorisSink 模式演变

最新版本的 Doris 连接器支持直接接收 CDC 产生的 JSON 字符串数据,然后自动解析数据并写入目标表,且支持解析引起 Schema 变更的 DDL 语句并且进行自动执行来实现模式演变。这让 Dinky 实现整库同步加模式演变更加容易,只需要在构建 OutputTag 时直接将 Debezium JSON 的 Map 序列化为 String 来输出,根据 CDCSOURCE 语句的 sink 配置来构建每个目标表的 DorisSink,无需关心 Schema。如图所示为最新版本的 Doris Sink 构建过程,省去 Schema 等配置,更加简洁。
Dinky 在 Doris 的整库同步+模式演变
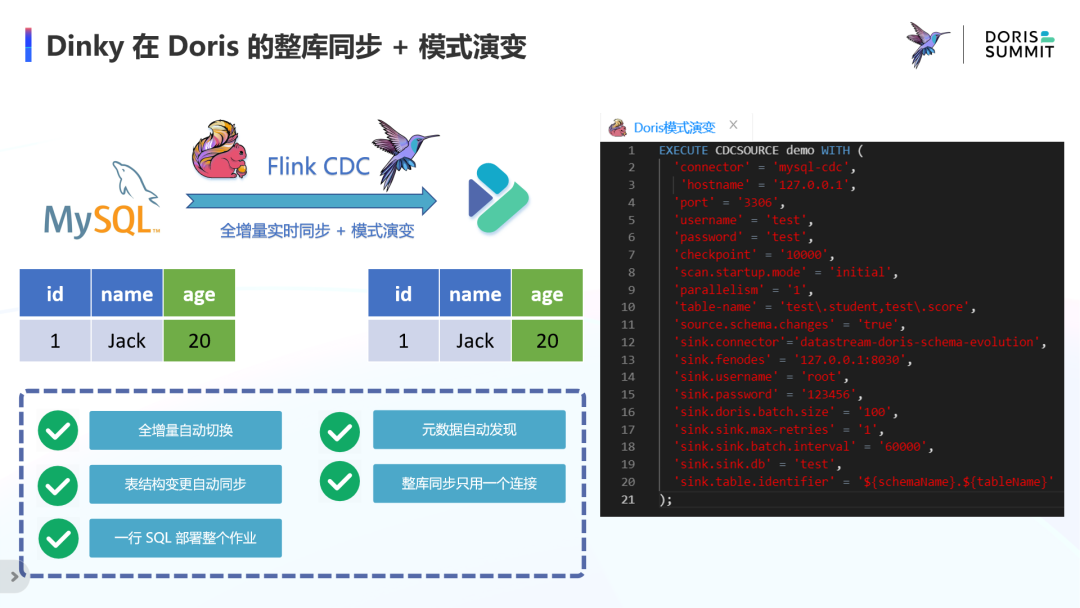
最终呢,我们通过 Dinky 的一句 CDCSOURCE 的语句,便可以完成整库实时入库 Doris,且支持一定的模式演变能力。对于之前讲到的全增量自动切换、元数据自动发现、表结构变更自动同步、整库同步只用一个连接、一行 SQL 部署整个作业这个五个用户诉求的功能基本实现。
五、未来展望与计划
目前还存在的问题
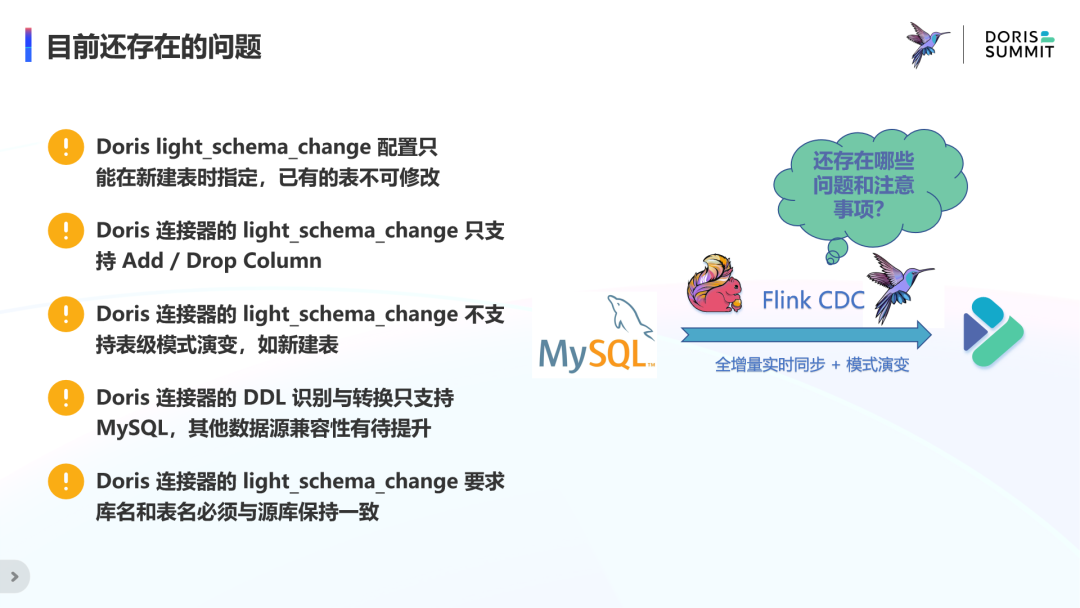
当然,目前该方案还存在一定的问题,待后续持续跟进优化。比如,
Doris light_schema_change 配置只能在新建表时指定,已有的表不能修改;
Doris 连接器只支持新增和删除列操作;
Doris 连接器不支持表级模式演变,如新建表;
Doris 连接器的 DDL 识别与转换只支持 MySQL,其他数据源兼容性有待提升;
Doris 连接器要求库名和表名必须与源库保持一致。
未来计划

未来呢,我们也将持续推进 Doris 整库同步与模式演变的探索与优化,争取可以为用户提供一个完善的解决方案。此外我们也会支持更多数据源类型的模式演变,目前发现该工作与数据源自身及其连接器能力有直接关系,
最后也会不断探索更多 Doris 在 Dinky 中的应用能力,为大家待来更多的开源实践分享。
交流
欢迎您加入社区交流分享与批评,也欢迎您为社区贡献自己的力量。
QQ社区群:543709668,申请备注 “ Dinky+企业名+职位”,不写不批。
微信官方群:添加 wenmo_ai ,申请备注“ Dinky+企业名+职位”,不写不批谢谢。
钉钉社区群(推荐):


扫描二维码获取
更多精彩
Dinky开源

