





大家好, 今天和大家分享的是 AWS Aurora RDS Postgres 的 QPM (Query Plan Mangement)功能。
之前和大家分享过一篇关于如 固定SQL 执行的文章: https://www.modb.pro/db/609428 本篇文章是继续PG 执行计划主题的一个番外篇。
熟悉ORACLE的小伙伴都知道,商业版数据库为了增强其SQL性能的稳定性,提供了管理SQL执行计划的管理功能 (SPM)SQL plan mangment 。
其目的是通过构建 SQL plan baseline 绑定合理的高效的执行计划,来替换指定 SQL 的不好的执行计划,从而使指定的SQL保持执行效率的稳定。
PG目前在开源的extension 上,能实现固定执行计划目前有 pg_hint_plan, 但是pg_hint_plan 的原理是绑定hint 来影响SQL的执行计划, 并不是真正的直接绑定
执行计划。
目前市场上AWS的 商业版 Aurora PostgreSQL rds 实现了类似的功能 QPM, 从名字上看应该是对飙了业界旗舰产品的SPM功能。
下面我们就来体验一下 全球领先的云服务厂商AWS的Aurora PostgreSQL: 目前是AWS云上有对新注册用户有免费的12月的体验涉及很多云上的产品。
过于如何注册的流程就不过多介绍了,网上有很多资料。需要你准备一张支持visa/master的协议的信用卡就行。
注册成功后,我们就可以创建我们的RDS了:我们选择轻松创建模式,使用已经为我们准备好的RDS配置的模板
一路点击下一步之后,RDS在几分钟之内就可以创建完成。
我们如果需要在客户端使用工具连接的话,还需要打开公网地址和相关的数据库端口。
上述设置完成后,我们就可以进入今天的主题: Query Plan Mangement
官方的参考文档: https://aws.amazon.com/cn/blogs/database/introduction-to-aurora-postgresql-query-plan-management/
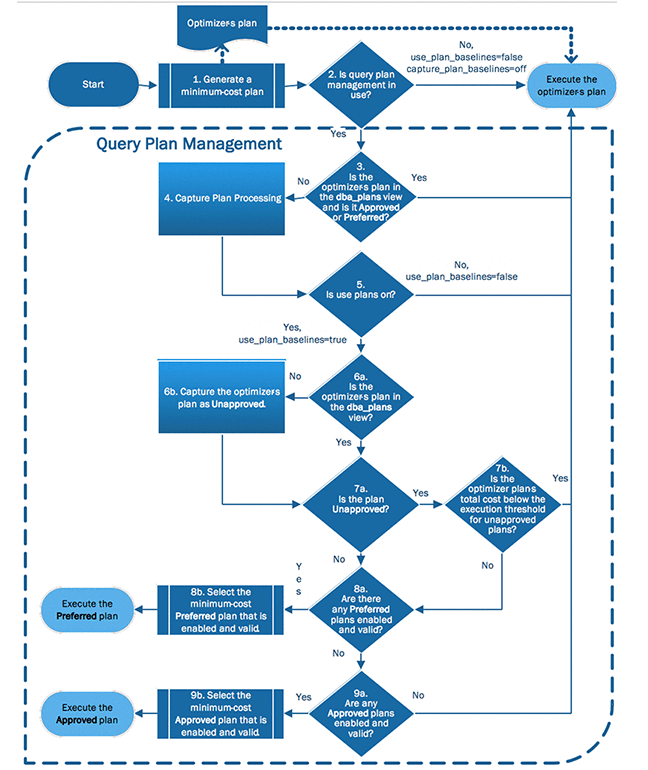
工作原理如图示:
简单的翻译成白话就是: 先看是否使用了 plan_baseline的功能,在视图 dba_plans 里面是是否有匹配的并且状态是 (preferred|approved) 状态的执行计划,
如果有的话,从他们当中选择一个 cost 值最低的作为这个SQL的最终执行计划
下面我们 step by step 实际的操作一下:
1)我们需要创建一个 instance-level 的 parameter group(参数组):
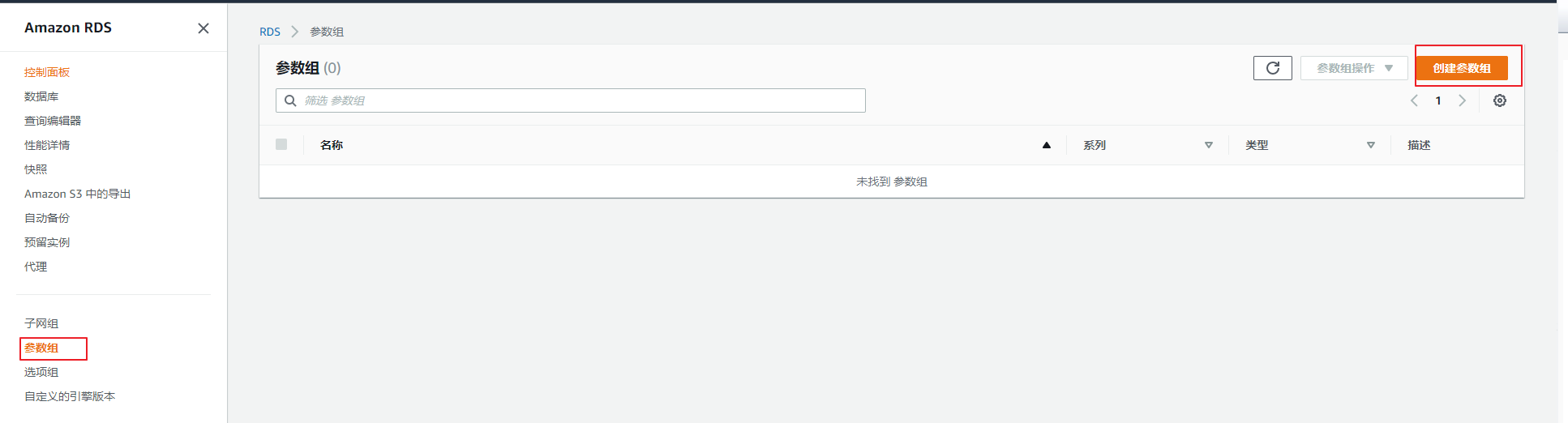
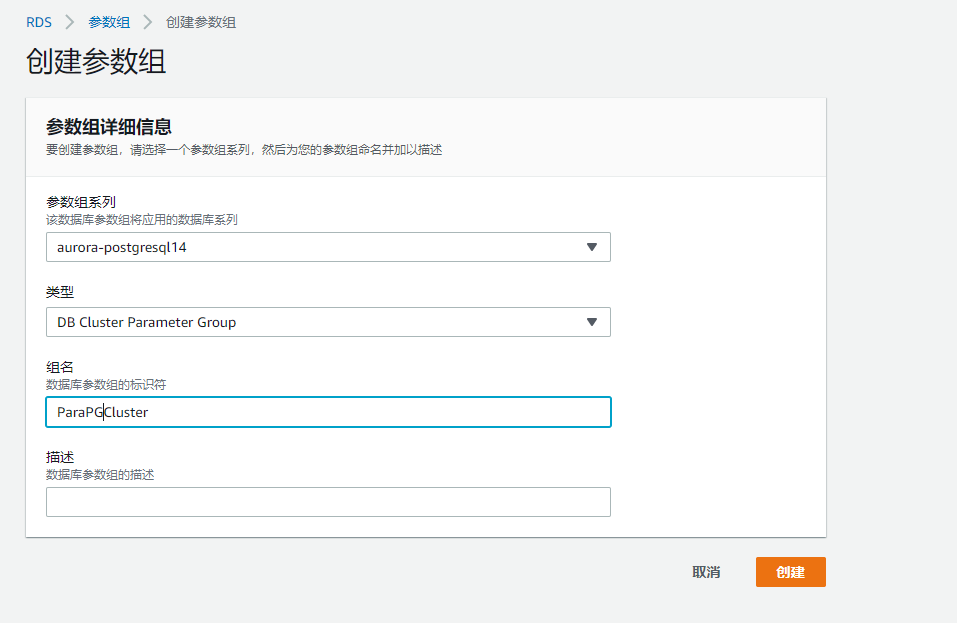
打开参数 rds.enable_plan_management 默认是0, 修改成1

创建DB级别的参数组:
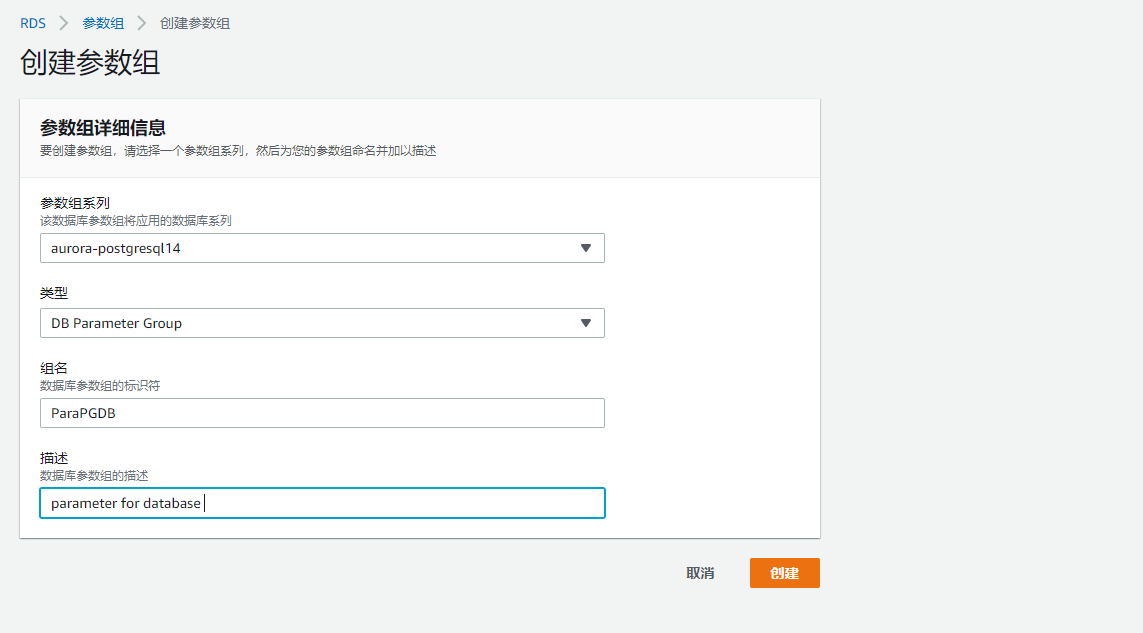
打开参数: apg_plan_mgmt.capture_plan_baselines 和 apg_plan_mgmt.use_plan_baselines
sql plan baseline 的 捕获功能 设置为 automatic 自动捕获

设置 apg_plan_mgmt.use_plan_baselines 的值为 true

修改完数据库参数之后,我们需要重启数据库,使其生效:
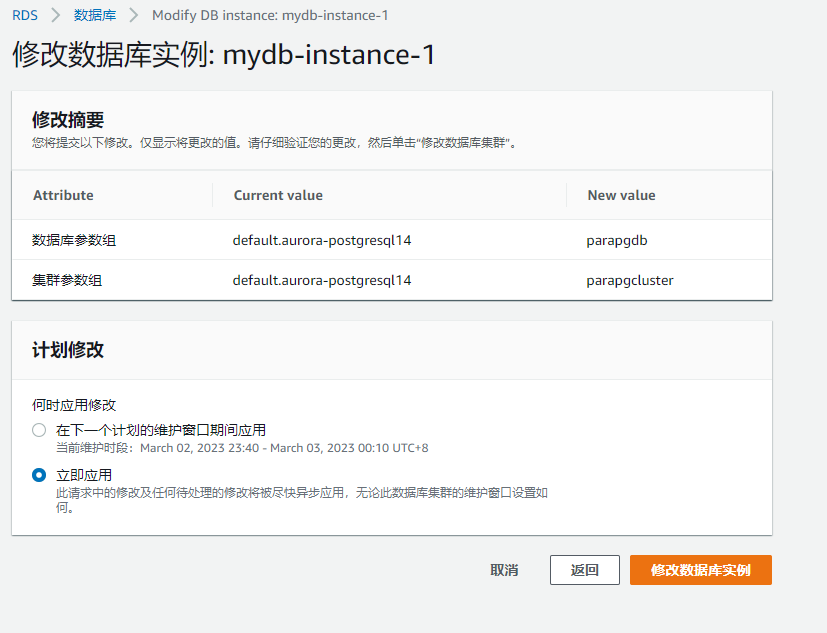
实例重启完成之后, 我们尝试登陆数据库: 查看数据库实例的版本
postgres=> select aurora_version(),version();
aurora_version | version
----------------+-------------------------------------------------------------------------------------------------------------
14.5.1 | PostgreSQL 14.5 on aarch64-unknown-linux-gnu, compiled by aarch64-unknown-linux-gnu-gcc (GCC) 7.4.0, 64-bit
(1 row)
查看一下刚才我们修改的参数:
postgres=> show rds.enable_plan_management;
rds.enable_plan_management
----------------------------
1
(1 row)
postgres=> show apg_plan_mgmt.capture_plan_baselines;
apg_plan_mgmt.capture_plan_baselines
--------------------------------------
automatic
(1 row)
postgres=> show apg_plan_mgmt.use_plan_baselines;
apg_plan_mgmt.use_plan_baselines
----------------------------------
on
(1 row)
创建extension
postgres=> CREATE EXTENSION apg_plan_mgmt;
CREATE EXTENSION
postgres=> \dx+
Objects in extension "apg_plan_mgmt"
Object description
--------------------------------------------------------------------------------------
function apg_plan_mgmt.approve_unapproved_plan_if_no_baseline()
function apg_plan_mgmt.copy_outline(integer,integer,integer,integer)
function apg_plan_mgmt.delete_plan(integer,integer)
function apg_plan_mgmt.delete_plans_not_used_since(date)
function apg_plan_mgmt.delete_plans_not_validated_since(timestamp without time zone)
function apg_plan_mgmt.evolve_plan_baselines(integer,integer,double precision,text)
function apg_plan_mgmt.explain_analyze_query(text)
function apg_plan_mgmt.explain_query(text)
function apg_plan_mgmt.get_explain_plan(integer,integer,text)
function apg_plan_mgmt.get_explain_stmt(integer,integer,text)
function apg_plan_mgmt.get_search_path(integer,integer)
function apg_plan_mgmt.param_list_to_sql(bytea,boolean)
function apg_plan_mgmt.plan_last_used(integer,integer)
function apg_plan_mgmt.pretty_outline(jsonb)
function apg_plan_mgmt.reload()
function apg_plan_mgmt.set_plan_compatibility_level(integer,integer,text)
function apg_plan_mgmt.set_plan_enabled(integer,integer,boolean)
function apg_plan_mgmt.set_plan_environment_variables(integer,integer,jsonb)
function apg_plan_mgmt.set_plan_status(integer,integer,integer)
function apg_plan_mgmt.set_plan_status(integer,integer,text)
function apg_plan_mgmt.update_plans_last_used()
function apg_plan_mgmt.validate_plans(integer,integer,text)
function apg_plan_mgmt.validate_plans(text)
table apg_plan_mgmt.plans
view apg_plan_mgmt.dba_plans
(25 rows)
我们来测试一下 自动捕获执行计划特性:
创建表: 这里我们需要注意SQL 需要执行2次,才能记录在 apg_plan_mgmt.dba_plans 这个视图之中,
status: approve 的状态表示是 接受这个执行计划
enabled: t 表示这个执行计划 绑定已经生效
origin: Automatic 表示自动获取
sql_text: SQL 文本 select * from tab1 where name = ‘jason’;
estimated_total_cost: 执行计划的预估成本 16.75
postgres=> create table tab1 (id int primary key, name varchar(50));
CREATE TABLE
postgres=> explain select * from tab1 where name = 'jason';
QUERY PLAN
-------------------------------------------------------
Seq Scan on tab1 (cost=0.00..16.75 rows=3 width=122)
Filter: ((name)::text = 'jason'::text)
(2 rows)
postgres=> SELECT sql_hash, plan_hash, status, enabled, stmt_name
postgres-> FROM apg_plan_mgmt.dba_plans;
sql_hash | plan_hash | status | enabled | stmt_name
----------+-----------+--------+---------+-----------
(0 rows)
postgres=> explain select * from tab1 where name = 'jason';
QUERY PLAN
-------------------------------------------------------
Seq Scan on tab1 (cost=0.00..16.75 rows=3 width=122)
Filter: ((name)::text = 'jason'::text)
(2 rows)
postgres=> select * from apg_plan_mgmt.dba_plans;
-[ RECORD 1 ]-------------+-----------------------------------------
sql_hash | 1184554698
plan_hash | -866554594
enabled | t
status | Approved
sql_text | select * from tab1 where name = 'jason';
stmt_name |
param_types |
param_list |
plan_outline | { +
| "Fmt": "01.00", +
| "Outl": { +
| "Op": "SScan", +
| "QB": 1, +
| "S": "public", +
| "Tbl": "tab1", +
| "Rid": 1 +
| } +
| }
environment_variables | { +
| "search_path": "\"$user\", public", +
| "effective_cache_size": "622666" +
| }
plan_created | 2023-02-27 07:19:20.014708
last_verified | 2023-02-27 07:19:20.014708
last_validated | 2023-02-27 07:19:20.014708
last_used | 2023-02-27
created_by | postgres
queryid | -7560432400566551979
compatibility_level | 03.00.00
origin | Automatic
has_side_effects | f
planning_time_ms |
execution_time_ms |
cardinality_error |
estimated_startup_cost | 0
estimated_total_cost | 16.75
total_time_benefit_ms |
execution_time_benefit_ms |
我们尝试插入一些数据,并在name 字段上创建索引,并收集统计信息
DO
$$
DECLARE
i INTEGER := 1;
BEGIN
FOR i IN 1..100 LOOP
insert into tab1 select i,'jason'||i;
END LOOP;
END;
$$ language plpgsql;
postgres=> create index concurrently idx_tab1_name on tab1(name);
CREATE INDEX
postgres=> vacuum analyze tab1;
VACUUM
再次观察 select * from tab1 where name = ‘jason’; 的执行计划:
我们可以得到一个信息: An Approved plan was used instead of the minimum cost plan.
我们当前使用的执行计划并不是成本最低的执行计划:
postgres=> explain select * from tab1 where name = 'jason';
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on tab1 (cost=0.00..180.00 rows=1 width=13)
Filter: ((name)::text = 'jason'::text)
Note: An Approved plan was used instead of the minimum cost plan.
SQL Hash: 1184554698, Plan Hash: -866554594, Minimum Cost Plan Hash: 1531858248
(4 rows)
观察一下 apg_plan_mgmt.dba_plans 视图内的变化: 多了一条记录
status: Unapproved 状态是 未批准的状态
plan_outline : 索引扫描的方式
estimated_total_cost: 成本是 8.3025 比之前的 seq scan的cost 16.75 减少了一半
postgres=> select * from apg_plan_mgmt.dba_plans;
-[ RECORD 3 ]-------------+-----------------------------------------
sql_hash | 1184554698
plan_hash | 1531858248
enabled | t
status | Unapproved
sql_text | select * from tab1 where name = 'jason';
stmt_name |
param_types |
param_list |
plan_outline | { +
| "Fmt": "01.00", +
| "Outl": { +
| "Op": "IScan", +
| "QB": 1, +
| "S": "public", +
| "Idx": "idx_tab1_name", +
| "Tbl": "tab1", +
| "Rid": 1 +
| } +
| }
environment_variables | { +
| "search_path": "\"$user\", public", +
| "effective_cache_size": "622666" +
| }
plan_created | 2023-02-27 07:48:45.20475
last_verified | 2023-02-27 07:48:45.20475
last_validated | 2023-02-27 07:48:45.20475
last_used | 2023-02-27
created_by | postgres
queryid | -7560432400566551979
compatibility_level | 03.00.00
origin | Automatic
has_side_effects | f
planning_time_ms |
execution_time_ms |
cardinality_error |
estimated_startup_cost | 0.285
estimated_total_cost | 8.3025
total_time_benefit_ms |
execution_time_benefit_ms |
我们需要approve 一下这个更好的执行计划: 调用函数 apg_plan_mgmt.evolve_plan_baselines
postgres=> SELECT apg_plan_mgmt.evolve_plan_baselines (
postgres(> sql_hash,
postgres(> plan_hash,
postgres(> min_speedup_factor := 1.0,
postgres(> action := 'approve'
postgres(> )
postgres-> FROM apg_plan_mgmt.dba_plans WHERE status = 'Unapproved' and sql_hash = 1184554698 and plan_hash = 1531858248;
NOTICE: [Unapproved] SQL Hash: 1184554698, Plan Hash: 1531858248, select * from tab1 where name = 'jason';
NOTICE: Baseline [Planning time 0.298 ms, Execution time 0.862 ms]
NOTICE: Baseline+1 [Planning time 0.163 ms, Execution time 0.02 ms]
NOTICE: Total time benefit: 0.977 ms, Execution time benefit: 0.842 ms, Estimated rows=1, Actual rows=0, Cost = 0.29..8.3
NOTICE: Unapproved -> Approved
-[ RECORD 1 ]---------+--
evolve_plan_baselines | 0
我们查看一下 baseline 中的这个执行计划的状态:
postgres=> select status from apg_plan_mgmt.dba_plans where sql_hash = 1184554698 and plan_hash = 1531858248;
-[ RECORD 1 ]----
status | Approved
再次执行SQL , 验证执行计划: 可以看到已经切换到了 索引扫描的上面
postgres=> explain select * from tab1 where name = 'jason';
QUERY PLAN
---------------------------------------------------------------------------
Index Scan using idx_tab1_name on tab1 (cost=0.29..8.30 rows=1 width=13)
Index Cond: ((name)::text = 'jason'::text)
(2 rows)
最后,我们删除掉 seq scan 的执行计划的 baseline:
postgres=> SELECT apg_plan_mgmt.delete_plan (
postgres(> sql_hash,
postgres(> plan_hash
postgres(> )
postgres-> FROM apg_plan_mgmt.dba_plans WHERE sql_hash = 1184554698 and plan_hash = -866554594;
-[ RECORD 1 ]--
delete_plan | 0
上面的案例是关于设置自动化捕获 sql plan baseline 的情况 (apg_plan_mgmt.capture_plan_baselines = automatic)
对于生产环境的话,我们很少用自动捕获的功能(基于之前oracle DBA 的经验),我们更希望做到有的放矢,针对少数有问题的SQL, 手动来生成 好的执行计划, 手动来绑定 SQL PLAN baseline
相信对于严谨的生产系统, 我们需要关闭自动捕获的功能,在实例级别 设置 apg_plan_mgmt.capture_plan_baselines = off。 这个操作需要重启实例:
我们创建一张表T2 :
postgres=> create table tab2 (id int primary key , name varchar(50));
CREATE TABLE
postgres=> insert into tab2 select generate_series(1,1000), 'jason' ;
INSERT 0 1000
我们执行一条SQL,走的是索引扫描的方式:
postgres=> explain select * from tab2 where id = 1;
QUERY PLAN
-----------------------------------------------------------------------
Index Scan using tab2_pkey on tab2 (cost=0.28..8.29 rows=1 width=10)
Index Cond: (id = 1)
(2 rows)
现在我们想让SQL语句走 seq scan的方式, 我们可以手动设置 GUC 的参数或者使用 extension pg_hint_plan 来手动干预生成执行计划:
这里我们采用手动设置 GUC 的参数的方式:
postgres=> SET enable_indexscan=off;
SET
postgres=> set enable_bitmapscan=off;
SET
postgres=> set enable_tidscan=off;
设置手动捕获执行计划:
postgres=> SET apg_plan_mgmt.capture_plan_baselines = manual;
SET
执行SQL: 我们得到了期待的 Seq scan
postgres=> explain select * from tab2 where id = 1;
QUERY PLAN
------------------------------------------------------
Seq Scan on tab2 (cost=0.00..18.51 rows=1 width=10)
Filter: (id = 1)
(2 rows)
查看视图:apg_plan_mgmt.dba_plans
-[ RECORD 7 ]-------------+----------------------------------------------------------
sql_hash | 590773255
plan_hash | -866161378
enabled | t
status | Approved
sql_text | select * from tab2 where id = 1;
stmt_name |
param_types |
param_list |
plan_outline | { +
| "Fmt": "01.00", +
| "Outl": { +
| "Op": "SScan", +
| "QB": 1, +
| "S": "public", +
| "Tbl": "tab2", +
| "Rid": 1 +
| } +
| }
environment_variables | { +
| "search_path": "\"$user\", public", +
| "enable_tidscan": "false", +
| "enable_indexscan": "false", +
| "enable_bitmapscan": "false", +
| "effective_cache_size": "622666" +
| }
plan_created | 2023-02-27 09:27:05.67872
last_verified | 2023-02-27 09:27:05.67872
last_validated | 2023-02-27 09:27:05.67872
last_used | 2023-02-27
created_by | postgres
queryid | -8802130160561392496
compatibility_level | 03.00.00
origin | Manual
has_side_effects | f
planning_time_ms |
execution_time_ms |
cardinality_error |
estimated_startup_cost | 0
estimated_total_cost | 18.5125
total_time_benefit_ms |
execution_time_benefit_ms |
我们把这条baseline 设置成为 Preferred的状态:
postgres=> SELECT apg_plan_mgmt.set_plan_status(sql_hash, plan_hash, 'preferred' )
postgres-> from apg_plan_mgmt.dba_plans WHERE sql_hash = 590773255 and plan_hash = -866161378;
-[ RECORD 1 ]---+--
set_plan_status | 0
postgres=> select status from apg_plan_mgmt.dba_plans WHERE sql_hash = 590773255 and plan_hash = -866161378;
-[ RECORD 1 ]-----
status | Preferred
最后我们需要关闭session 级别的 执行计划捕获:
postgres=> set apg_plan_mgmt.capture_plan_baselines = off;
SET
我们尝试打开一个新的客户端连接,执行SQL:符合我们预期的 Seq Scan
postgres=> \x
Expanded display is off.
postgres=> explain select * from tab2 where id = 1;
QUERY PLAN
--------------------------------------------------------------------------------
Seq Scan on tab2 (cost=0.00..18.51 rows=1 width=10)
Filter: (id = 1)
Note: An Approved plan was used instead of the minimum cost plan.
SQL Hash: 590773255, Plan Hash: -866161378, Minimum Cost Plan Hash: 1824372037
(4 rows)
关于QPM的迁移,这个和ORACLE的SPM方式几乎是一样的,也是通过创建临时表,然后dump的方式实现:
可以参考: https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraPostgreSQL.Optimize.Maintenance.html#AuroraPostgreSQL.Optimize.Maintenance.ExportingImporting
写到最后,
- 目前QPM这个功能只能在 AWS的 Aurora RDS Postgres 使用,不知道能不能出现开源版的 extension 或者 AWS 什么时候可以开源这个extension.
- 目前PG系数据库国产化的产品经理是否考虑将其纳入到新版本的功能之中,根据之前的 ORACLE DBA 经验而言, 这个功能是十分重要的,特别是当你在无法改动生产代码的情况下。
Have a fun 😃 !
