




我们在上文提到了KQL ,Elasticsearch 查询 KQL。但它只能在Kibana中使用,而且只能定义搜索条件相关的内容。接下来我们结合开发同学提出的一个ELK搜索需求来一起看看ES真正的核心查询语言Query DSL。
需求背景
需求本身很简单,针对一个应用调用的关键词的搜索,需要下载其2个月的所有相关日志,这里的难点在于这个关键词的日志量非常大,一小时大概1W+, 2个月的日志量直奔1500W条日志了,我们常用的在Kibana上使用CSV下载已经无法实现这个需求,而且由于数据量较大,查询也非常慢。参考了铭毅天下大佬的文章: Elasticsearch 8.X 导出 CSV 多种方案,一网打尽!看了一下各个方案之后,我们打算采用自己开发python的方式来实现, 这个python程序的核心就是生成Query DSL
KQL 到 Query DSL
针对前文提到的日志搜索需求,我们先在kibana discover中做一个短时间窗口的查询,借助kibana来帮助我们生成相关的query dsl。Kibana 8 中提供了一个方便功能是查看我们在Kibana discover里面写的KQL转换为具体怎样的Query DSL的Request以及其返回结果
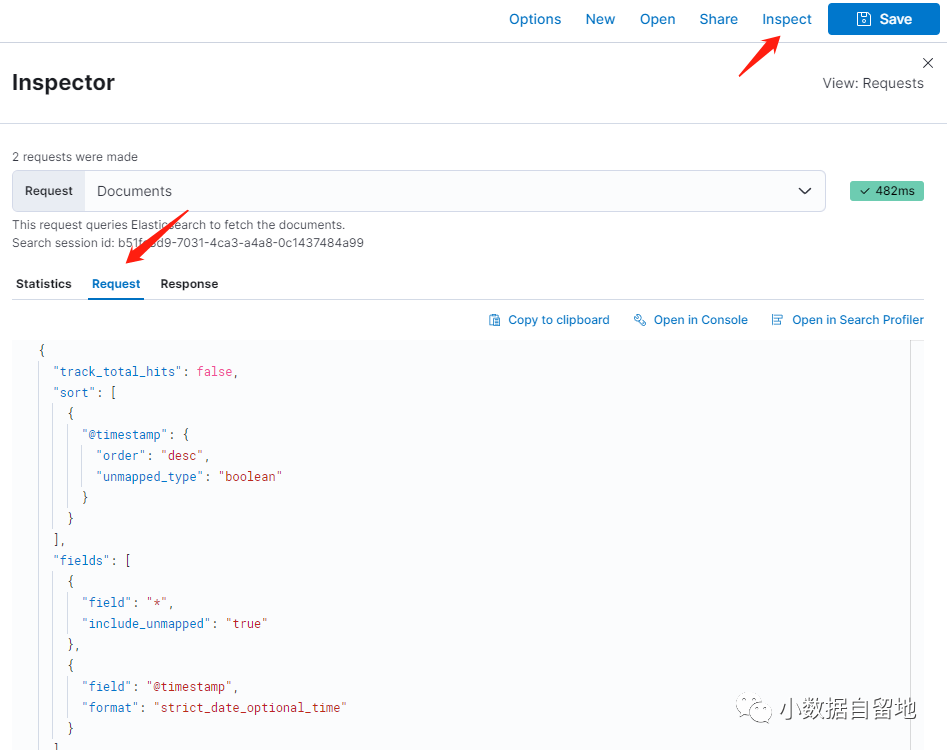
Query DSL 大致结构
在ES的Query DSL都是json格式的,我们先来看看这个Query 的大致结构:
GET logs-*-app*/_search{"track_total_hits": false,"sort": [],"_source": false,"fields": [],"size": 100,"version": true,"script_fields": {},"stored_fields": [],"runtime_mappings": {},"query": {}}复制
track_total_hits:这个参数控制是否统计命中总数,我们这里设置的false,不会有任何返回结果, 在不需要统计查询命中总数的情况,这样做会加速查询。 如果是设置为true的话,在搜索的命中总数中会在hits.total中返回:
"hits" : {"total" : {"value" : 1224,"relation" : "eq"},复制
The requests will count the total hit accurately up to 10,000 hits. It is a good trade off to speed up searches if you don’t need the accurate number of hits after a certain threshold.默认情况下10000一些都会返回准确数字,10000以上就会返回gte 10000
"hits" : {"total" : {"value" : 10000,"relation" : "gte"}复制
sort: 对命中返回结果的排序进行定义, 比如kibana discover默认是基于timestamp字段进行排序:
"sort": [{"@timestamp": {"order": "desc"}}],复制_source: 控制返回哪些字段和fields option功能类似,像我们这里直接设置为false的话就不会返回_source字段。默认情况下都是设为false, ES8中官方更建议用fields字段来控制返回字段。
"_source": false,复制
fields:控制返回哪些字段, the fields option is preferred than _source option, because it consults both the document data and index mappings. 虽然在kibana中我们可以选择需要查看的字段,但实际我测试了下,kibana并没有调整fields,始终设置的是:
"fields": [{"field": "*","include_unmapped": "true"},复制
如果我们自己在console中设置:
"fields": ["message", "tags"]复制
那么返回的fields中就只会有message和tags字段:
"fields" : {"message" : ["2023-03-10 11:41:42,624-[core] DEBUG qtp581374081-3373 B2C[8d41b0b2aa2c8480] - Search"],"tags" : ["apple-hu", "dev"]},复制
Size: the maximum number of hits to return,By default, you cannot use from and size to page through more than 10,000 hits. This limit is a safeguard set by the index.max_result_window index setting. 设置返回的最大值 ,这个值默认不能超过1万。向我们前文提到的需求,一天的数据量就有20W+, 这里就遇到了瓶颈,需要采用分页查询的方式,可以参考大佬的文章 全方位深度解读 Elasticsearch 分页查询
version
:(Optional, Boolean) If true, returns document version as part of a hit. Defaults to false.
script_fields : script_fields parameter to retrieve a script evaluation (based on different fields) for each hit. 对返回结果可以基于一个script进行再次处理,但这个功能很强大,可以对返回的字段进行再次处理,提取字段,做计算等。我们平时还没有使用到这个方法,更多的是把数据提取出来成为csv之后再进行处理。
stored_fields: 这个也是筛选返回字段的,和前面看到的_source, fields等选参数功能类似,默认是关闭的,ES官方是建议是使用Fields 参数( off by default and generally not recommended. Use source filtering instead to select subsets of the original source document to be returned.)
runtime_mappings: Defines one or more runtime fields in the search request. These fields take precedence over mapped fields with the same name. 这个也是在搜索运行时生成新字段,和scirpt_fields功能类似,但更加强大。根据官网文档,我做了个例子,加入一个获得timestamp所在的dayOfWeek
"fields": ["@timestamp", "day_of_week"],"runtime_mappings": {"day_of_week": {"type": "keyword","script": {"source": "emit(doc['@timestamp'].value.dayOfWeekEnum.getDisplayName(TextStyle.FULL, Locale.ROOT))"}}},复制在返回值中就直接可以获得这个新的字段及其结果,这个非常适合做简单的数据清洗:
"@timestamp" : ["2023-03-09T08:21:27.578Z"],"day_of_week" : ["Thursday"]复制
Query
可以看到以上提到的所有参数其实都是返回命中文档相关的,定义请求过滤条件的就是这个剩下的query参数, ES 支持如下几种query类型, 他们可以单独或者混合使用:
Boolean and other compound queries, which let you combine queries and match results based on multiple criteria
Term-level queries for filtering and finding exact matches
Full text queries, which are commonly used in search engines
Geo and spatial queries
这里面每一种query都可以写好几篇小作文了,我们还是回到我们的原始业务需求来看看我们需要具体掌握的部分, 在kibana里面搜索条件是这样设置的
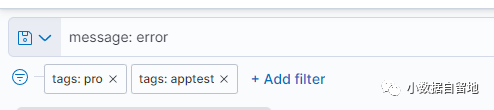
针对tags字段过滤pro和apptest,然后在message中查询包含有error的数据,最后加上一个timestamp的时间范围,我们这是个组合查询,有4个搜索条件之间都是和的关系。Kibana给我们生成了一个这样的query:
"query": {"bool": {"must": [],"filter": [{"bool": {"should": [{"match": {"message": "error"}}],"minimum_should_match": 1}},{"range": {"@timestamp": {"format": "strict_date_optional_time","gte": "2023-03-10T07:59:34.967Z","lte": "2023-03-10T08:09:34.967Z"}}},{"match_phrase": {"tags": "pro"}},{"match_phrase": {"tags": "apptest"}}],"should": [],"must_not": []}}复制
可以看到Kibana生成的查询还是有点复杂的,包含多层嵌套,包含了上文提到的前3种query类型,我们从最外向内逐步剖析,其中套在最外层的就是第一个boolean query。
bool : 布尔查询是常用的复合查询,它把多个子查询组合成一个布尔表达式,这些子查询之间的逻辑关系是“与”,即所有子查询的结果都为true时布尔查询的结果才为真。 Bool查询包含4种子查询,可以按照各个子查询的具体匹配程度对文档进行打分计算, 其中filter和must_not二种不参与查询算分:
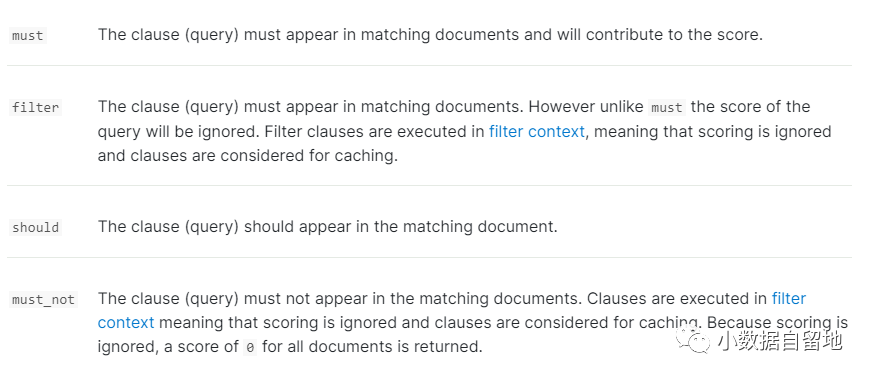
在kibana自动生成的查询中,虽然含有这4个类型的子查询,但其中只有filter子查询有内容,其他的:
Filter: filter查询关注的是查询条件和文档是否匹配,不进行相关的打分计算,可以减少不小的时间开销。
了解了最外层的bool和filter query之后,我们逐步向内部看,剩下的就是具体的查询条件了,主要分为Term-level queries 和 Full text queries。
Term-level queries: term level query简单来说就是对结构化数据进行精准查询,并不对查询字段进行分词处理。find documents based on precise values in structured data. Examples of structured data include date ranges, IP addresses, prices, or product IDs. Unlike full-text queries, term-level queries do not analyze search terms. Instead, term-level queries match the exact terms stored in a field. 在Filter包含了一个基于timestamp的range查询,这个range 属于term-level queries的一种。还有一种更常见的term 查询
term: 用于查询待查字段和查询值是否完全匹配。比如说我们前面对tags的查询,kibana给出的是match_phrase,我们完全可以用term进行替代。
{"match_phrase": {"tags": "pro"}}{"term": {"tags": "pro"}}复制
最后让我们看看剩下的3个查询条件所使用到的full text queris:
The full text queries enable you to search analyzed text fields such as the body of an email. The query string is processed using the same analyzer that was applied to the field during indexing. 不同于结构化查询,全文搜索首先对查询词进行分析,然后根据查询词的分词结果构建查询,在查询结果中根据匹配度进行打分。我们最常见的就是match query和 match_phrase query.
match query:match查询是全文搜索的主要代表。对于最基本的math搜索来说,只要分词中的一个或者多个在文档中存在即可。例如搜索"hello world es",查询词先被分词器切分为"hello", "world", "es"3个词,因此只要文档中包含这3个字中的任何一个字,都会被搜索到,可以看到他们之间是默认是"或"的关系,如果想要这3个词同时被搜索到,也就是"与", 可以采用设置operator参数为and:
GET /_search{"query": {"match": {"message": {"query": "this is a test","operator": "and"}}}}复制
在kibana中如果我们不对需要搜索的字段加引号的话就是采用的这种match查询的方式。
match_phase: 和match一样也会对输入做分词,但是需要结果中也包含所有的分词,而且顺序要求一样。以"hello world"为例,要求结果中必须包含hello和world,而且还要求他们是连着的,顺序也是固定的,hello that word不满足,world hello也不满足条件。在kibana中如果搜索字段被双引号括起来就是采用的match_phase查询,这样就进行的是字符串的精准匹配。
小结
Elasticsearch 搜索功能强大的原因就是基于它强大的query dsl,如果单纯的从文档入手,其复杂的API和各种参数很快就把人看晕头了。本文只是以一个业务需求为入口,首先结合kibana为我们自动生成的query dsl, 初步剖析了一下serach query,介绍了几个大类和我们在这个示例中遇到的最常见的查询语句。在初步了解了这些之后我们才能逐步优化kibana生成的query,提高查询性能,在遇到kibana中无法实现的功能,自己去基于query dsl进行实现。
