




eBPF实现“零”侵入的慢SQL抓取
引子
最近写了几篇eBPF结合数据库的帖子,但都是“Hello World”级别的简单例子,意在抛砖引玉,希望能够将可观测技术与数据库领域更好的结合。但有小伙伴反馈由于例子过于简单且没有什么实践性的意义,所以不太好理解eBPF技术到底能做到什么程度的可观测、怎么辅助DBA的日常运维和问题排查?因此,这篇文章通过一个完整的例子介绍我们经常遇到的一个场景“慢SQL抓取”,
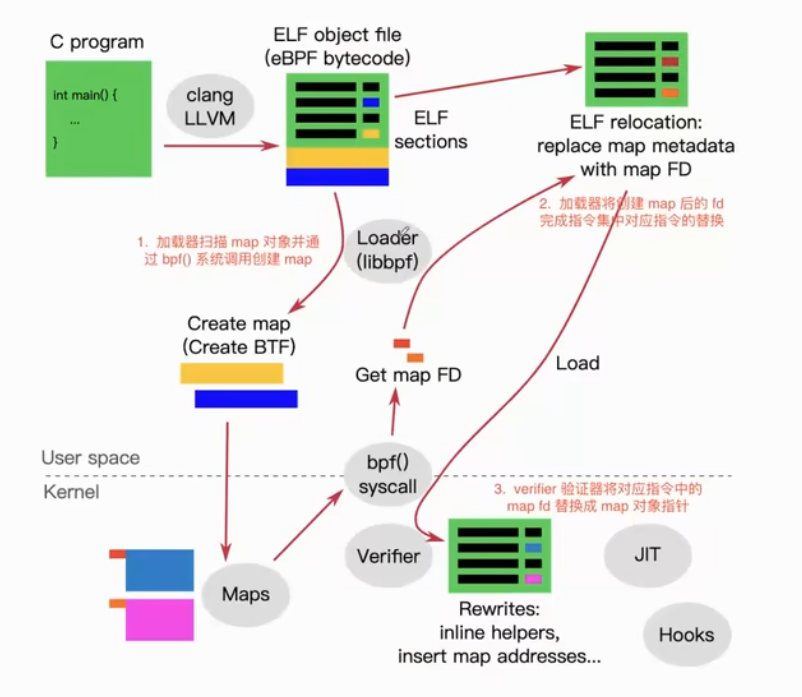
预备知识
eBPF是什么?eBPF能做什么?如何搭建eBPF环境?等等。这些内容不进行赘述了,可以参考下面几篇文章。
设计思路
PostgreSQL中的大部分探针(probe)都是成对出现的,这样我们可以方便的通过“开始”–“结束”探针被触发的时间差来计算各个阶段的耗时。这里我们用query__plan__start 和 query__plan__done 来观测SQL执行的总时长。
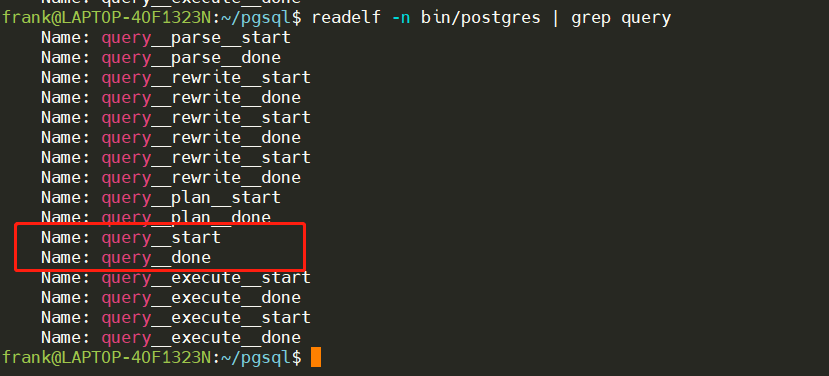
同样,可以通过__start,__done 对各阶段的耗时进行统计。
| buffer__checkpoint__start buffer__flush__start buffer__read__start buffer__sync__start buffer__write__dirty__start checkpoint__start clog__checkpoint__start lock__wait__start lwlock__wait__start multixact__checkpoint__start query__start query__execute__start query__parse__start query__plan__start query__rewrite__start smgr__md__read__start smgr__md__write__start sort__start subtrans__checkpoint__start transaction__start twophase__checkpoint__start wal__buffer__write__dirty__start |
buffer__checkpoint__done buffer__flush__done buffer__read__done buffer__sync__done buffer__write__dirty__done checkpoint__done clog__checkpoint__done lock__wait__done lwlock__wait__done multixact__checkpoint__done query__done query__execute__done query__parse__done query__plan__done query__rewrite__done smgr__md__read__done smgr__md__write__done sort__done subtrans__checkpoint__done transaction__commit twophase__checkpoint__done wal__buffer__write__dirty__done |
|---|
源码分析与实现
PostgreSQL跟踪点源码
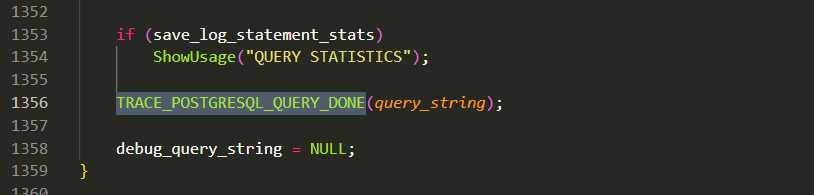
query__plan__start和query__plan__done 分别对应了PostgreSQL中的两个宏。
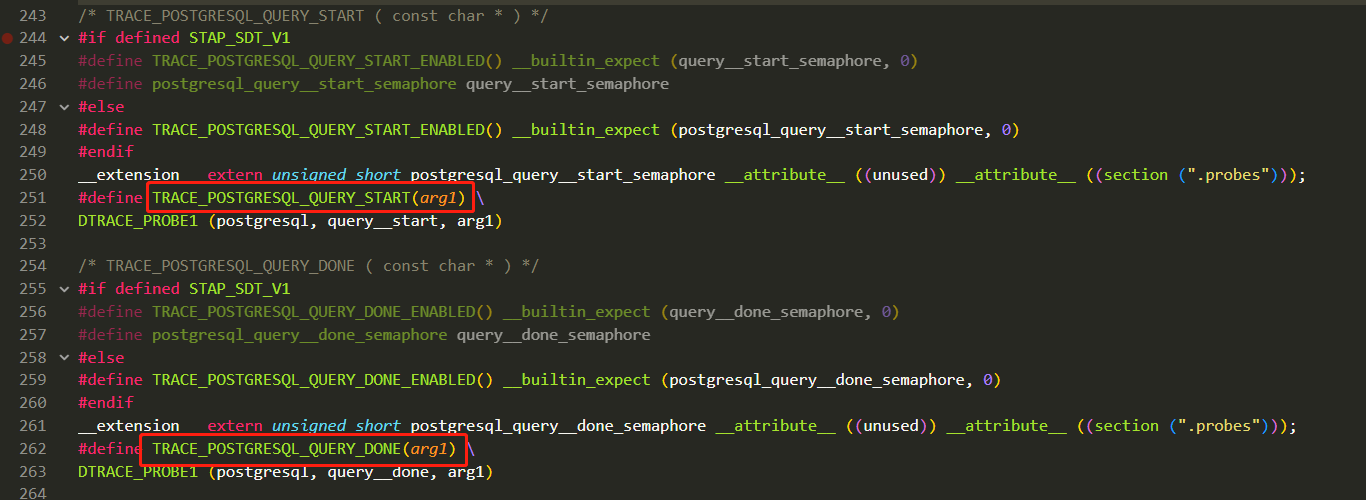
这两个探测点(probe)都埋在了exec_simple_query函数中。
query__plan__start
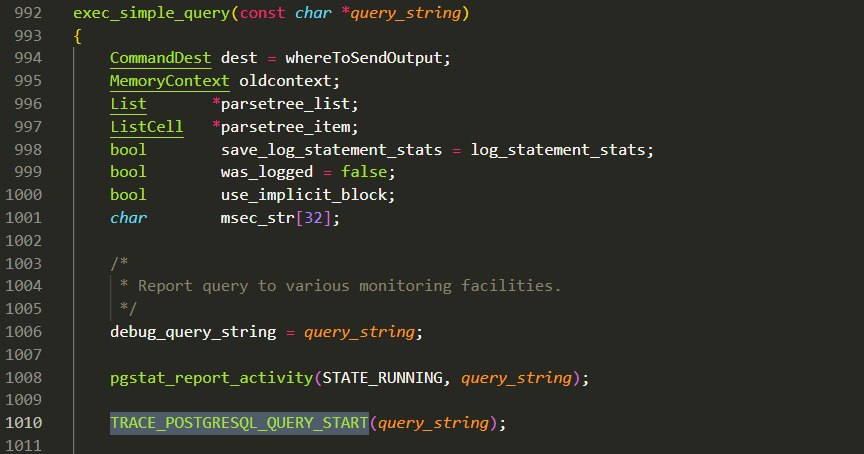
query__plan__done
eBPF编码实现
注:
bcc是一个开源项目,提供了一个高级的工具链,可以让开发者使用 eBPF 技术进行系统和应用程序的跟踪和调试。它提供了多个工具,可以监控和分析系统和应用程序的各种事件,例如系统调用、网络流量、文件系统操作、函数调用等等。bcc的核心是一个 Python 库和一个 C++ 库,它们可以与 eBPF 程序进行交互,并提供了丰富的 API 和工具,帮助开发者更方便地使用 eBPF 技术进行跟踪和调试。
from __future__ import print_function
from bcc import BPF, USDT
import sys
# arguments
def usage():
print("USAGE: pg_qslower PID [min_ms]")
exit()
if len(sys.argv) < 2:
usage()
if sys.argv[1][0:1] == "-":
usage()
pid = int(sys.argv[1])
min_ns = 1 * 1000000
min_ms_text = 1
if len(sys.argv) == 3:
min_ns = float(sys.argv[2]) * 1000000
min_ms_text = sys.argv[2]
debug = 0
QUERY_MAX = 128
# load BPF program
bpf_text = """
#include <uapi/linux/ptrace.h>
#define QUERY_MAX """ + str(QUERY_MAX) + """
struct start_t {
u64 ts;
char *query;
};
struct data_t {
u32 pid;
u64 ts;
u64 delta;
char query[QUERY_MAX];
};
BPF_HASH(start_tmp, u32, struct start_t);
BPF_PERF_OUTPUT(events);
int do_start(struct pt_regs *ctx) {
u32 tid = bpf_get_current_pid_tgid();
struct start_t start = {};
start.ts = bpf_ktime_get_ns();
bpf_usdt_readarg(1, ctx, &start.query);
start_tmp.update(&tid, &start);
return 0;
};
int do_done(struct pt_regs *ctx) {
u64 pid_tgid = bpf_get_current_pid_tgid();
u32 pid = pid_tgid >> 32;
u32 tid = (u32)pid_tgid;
struct start_t *sp;
sp = start_tmp.lookup(&tid);
if (sp == 0) {
// missed tracing start
return 0;
}
// check if query exceeded our threshold
u64 delta = bpf_ktime_get_ns() - sp->ts;
if (delta >= """ + str(min_ns) + """) {
// populate and emit data struct
struct data_t data = {.pid = pid, .ts = sp->ts, .delta = delta};
bpf_probe_read_user(&data.query, sizeof(data.query), (void *)sp->query);
events.perf_submit(ctx, &data, sizeof(data));
}
start_tmp.delete(&tid);
return 0;
};
"""
# enable USDT probe from given PID
u = USDT(pid=pid)
u.enable_probe(probe="query__start", fn_name="do_start")
u.enable_probe(probe="query__done", fn_name="do_done")
if debug:
print(u.get_text())
print(bpf_text)
# initialize BPF
b = BPF(text=bpf_text, usdt_contexts=[u])
# header
print("Tracing PostgreSQL server queries for PID %d slower than %s ms..." % (pid,
min_ms_text))
print("%-14s %-7s %8s %s" % ("TIME(s)", "PID", "MS", "QUERY"))
# process event
start = 0
def print_event(cpu, data, size):
global start
event = b["events"].event(data)
if start == 0:
start = event.ts
print("%-14.6f %-7d %8.3f %s" % (float(event.ts - start) / 1000000000,
event.pid, float(event.delta) / 1000000, event.query))
# loop with callback to print_event
b["events"].open_perf_buffer(print_event, page_cnt=64)
while 1:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()
代码注解:
- 入参共有2个参数:
- 第一个是pid:处理客户端连接的进程id,可以用ps获得,或者使用
pg_backend_pid()获取。 - 第二个参数是慢SQL的毫秒数,即只输出执行时间大于这个毫秒数的SQL,默认值为1ms。
- 第一个是pid:处理客户端连接的进程id,可以用ps获得,或者使用
- bpf_text 中的文本是C代码,也是eBPF在内核中执行的代码,会被编译层二进制流,随probe的触发被内核执行。
bpf_get_current_pid_tgid()用于获取当前进程的 PID 和 TGID。bpf_usdt_readarg()用于从 USDT 事件中读取参数。它可以用来在 eBPF 程序中访问用户空间的数据,例如函数参数、返回值等等。BPF_HASH是 eBPF 中的一种哈希表类型,它允许在 eBPF 程序中使用哈希表。哈希表是一种常见的数据结构,用于存储键值对,可以快速地进行查找、插入和删除操作。BPF_PERF_OUTPUT是 eBPF 中的一种特殊类型,它允许将数据从 eBPF 程序发送到用户空间。具体而言,它是一种用于将数据写入 perf buffer 的输出类型。- struct start_t 用于在__start被触发是保存时间和当前正在执行的SQL。
- struct data_t 用于在__done被触发时计算时间差
bpf_probe_read_user()用于从用户空间读取数据。bpf_ktime_get_ns()用于获取当前内核时间的纳秒数。它可以用来记录事件的时间戳。perf_submit()用于将数据发送到perf_event。它可以用来在 eBPF 程序中收集数据,为后续从用户空间提供数据。
- u = USDT(pid=pid),用于启用 USDT 事件。
- enable_probe,用户关联probe锚点,和eBPF内核函数,当锚点被触发后,会执行对应的eBPF内核函数。
open_perf_buffer()用于创建一个 perf_event 输出队列,并将其绑定到一个 BPF map 中。它可以在用户空间程序中使用,以便接收和处理从内核空间程序中发送的数据。perf_buffer_poll()用于轮询 perf_event 输出队列并处理其中的事件。它可以在用户空间程序中使用,以便获取和处理从内核空间程序中发送的数据。
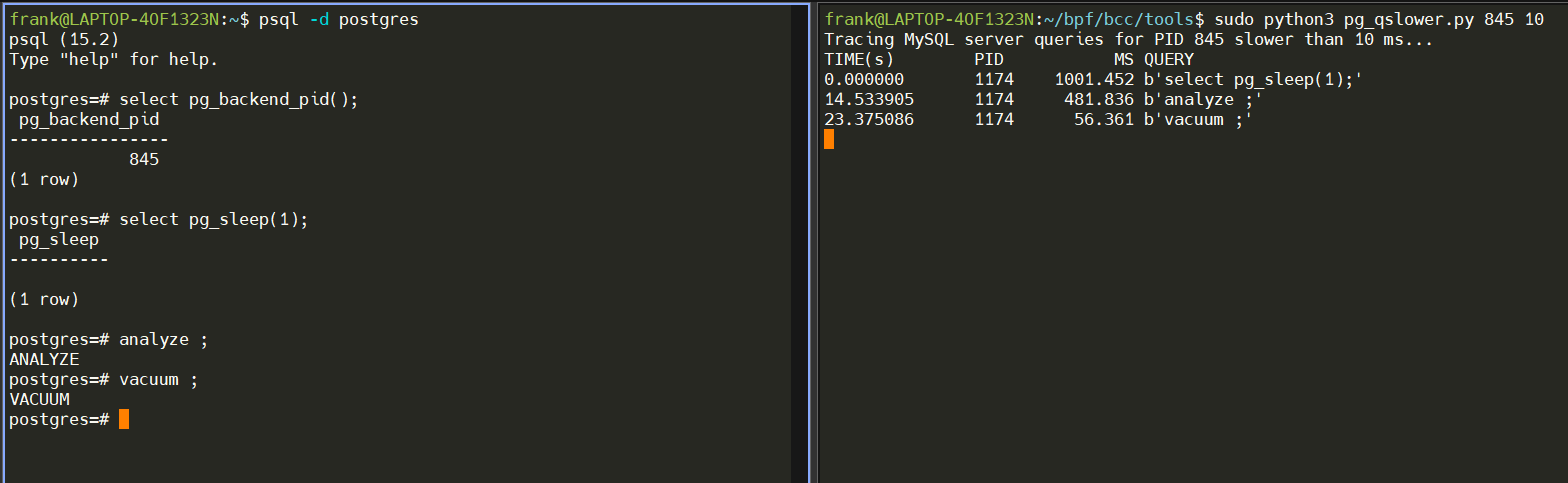
演示
- 启动PostgreSQL,并通过psql与server端建立链接,获取pid。
- 运行慢SQL观察脚本 sudo python3 pg_qslower.py 845 10,注意:要使用root权限,抓取执行时间大于10ms的sql。
- 执行几个慢SQL,并观察stdout输出。
总结
这个工具具备一定的实用性,当然,您可以根据自己的需要编写更适合您工作场景的脚本,且并不限于实用USDT,也可以观察网络流量,系统调用、I/O使用等。集合一些可视化工具、火焰图可以从另一个角度呈现一套完备且实用的PostgreSQL可观测/监控系统。
