




引子
前面几篇文章介绍了如何使用eBPF对数据库(PostgreSQL、OceanBase)进行观测,但给出的几个例子还是需要进行编码的,需要一些C/Python的基础,严格说还是需要“造轮子”的过程。因此对DBA来说并不是十分友好,这也有悖于我做这件事情的初衷。解决这个问题大概有两种思路,一是尽量开发一些通用的工具,二是寻求更简单的方法或工具,前者我试图筹划去写一套工具集(可能周期会比较长),而后者正是今天要介绍的一个更加工具——bpftrace。
摘要
eBPF有很多工具,按照封装程度由低到高分别是libbpf<bcc<bpftace,之前的例子使用BCC框架的python进行了演示,没有使用libbpf的原因是libbpf使用的开发语言是C(对比eBPF的原理学习比较适合使用libbpf),而这篇将采用封装度更高的bpftrace(类似于awk、Dtrace、SystemTap)来演示对PostgreSQL进行观测。
预备知识
eBPF是什么?eBPF能做什么?如何搭建eBPF环境?等等。这些内容不进行赘述了,可以参考下面几篇文章。
- PostgreSQL + eBPF实现数据库服务可观测
- OceanBase 4.0 改装:另一种全链路追踪的尝试
- 使用eBPF提升可观测性
- pg_lock_tracer实现数据库服务可观测
- eBPF实现“零”侵入的慢SQL抓取
什么是bpftrace
bpftrace是一个跟踪和排查Linux系统性能问题的工具,它基于eBPF技术,可以通过编写简单的脚本,实时监控内核的各种事件,如函数调用、系统调用、网络流量等。与传统的跟踪工具相比,bpftrace具有更低的性能开销和更高的灵活性,可以实时分析和优化系统性能,而无需停机或使用专门的硬件设备。同时,bpftrace提供了类似awk语法的脚本语言,使得用户可以轻松地编写和修改脚本,实现对特定问题的监控和分析。除此之外,bpftrace还支持用户自定义的探针和跟踪点,使得用户可以更加灵活地针对不同的应用场景进行监控和优化。总之,bpftrace是一个功能强大、易于使用的性能调试工具,对于Linux系统管理员和开发人员来说,是一个不可或缺的工具。
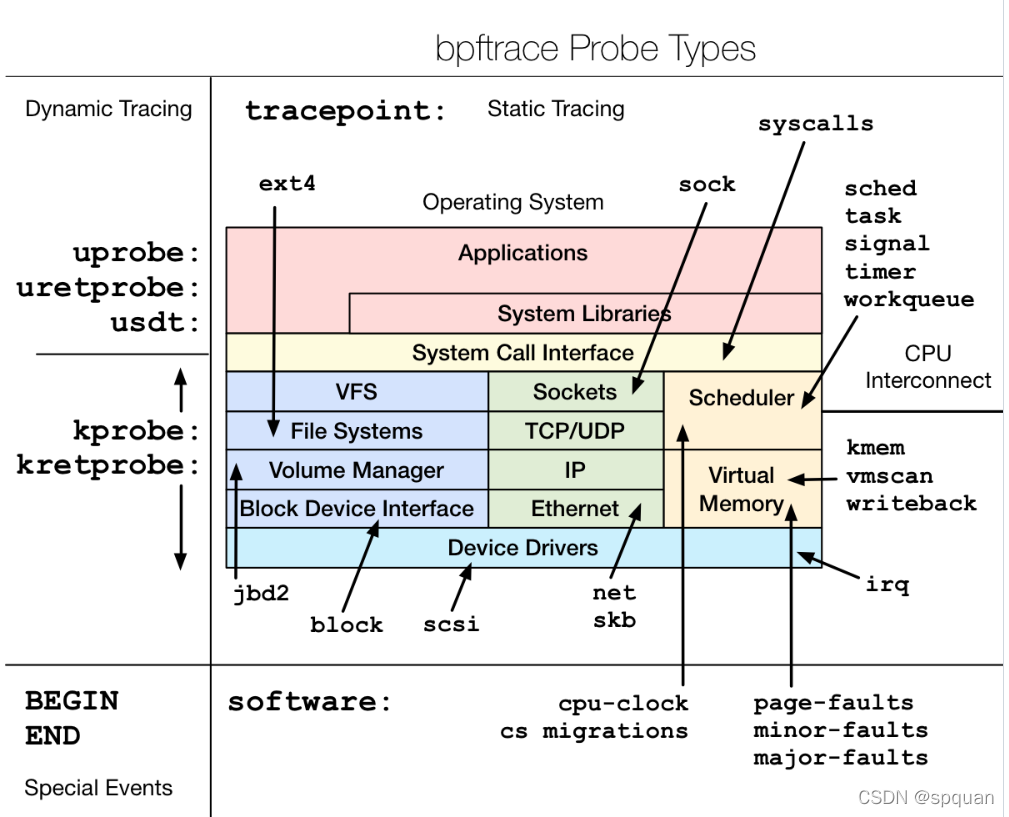
安装bpftrace
Linux内核要求
建议使用Linux 4.9或更高版本的内核。一些工具可能适用于旧版本的内核,但是这些旧版本的内核已不再维护。以下是添加主要功能的内核版本:
- 4.1 - kprobes
- 4.3 - uprobes
- 4.6 - stack traces, count and hist builtins (use PERCPU maps for accuracy and efficiency)
- 4.7 - tracepoints
- 4.9 - timers/profiling
内核还需要使用以下选项进行构建:
CONFIG_BPF=y CONFIG_BPF_SYSCALL=y CONFIG_BPF_JIT=y CONFIG_HAVE_EBPF_JIT=y CONFIG_BPF_EVENTS=y CONFIG_FTRACE_SYSCALLS=y CONFIG_FUNCTION_TRACER=y CONFIG_HAVE_DYNAMIC_FTRACE=y CONFIG_DYNAMIC_FTRACE=y CONFIG_HAVE_KPROBES=y CONFIG_KPROBES=y CONFIG_KPROBE_EVENTS=y CONFIG_ARCH_SUPPORTS_UPROBES=y CONFIG_UPROBES=y CONFIG_UPROBE_EVENTS=y CONFIG_DEBUG_FS=y
- 安装
sudo apt-get install -y bpftrace # ubuntu
or
sudo dnf install -y bpftrace #fedora
bpftrace学习路线
相对于BCC来说bpftrace的学习路线可能会相对陡峭,但学习周期比BCC要短的多,如果您有awk、Dtrace、SystemTap的基础,相信话3~5个小时就可以基本掌握bpftrace的使用方法,如果有一些C语言的底子可能这个周期会更短。
学习资料
个人推荐使用官方的文档。
bpftrace支持探针类型
kprobe- kernel function startkretprobe- kernel function returnuprobe- user-level function starturetprobe- user-level function returntracepoint- kernel static tracepointsusdt- user-level static tracepointsprofile- timed samplinginterval- timed outputsoftware- kernel software eventshardware- processor-level events
bpftrace内建变量
pid- Process ID (kernel tgid)tid- Thread ID (kernel pid)uid- User IDgid- Group IDnsecs- Nanosecond timestampelapsed- Nanoseconds since bpftrace initializationnumaid- NUMA Node IDcpu- Processor IDcomm- Process namekstack- Kernel stack traceustack- User stack tracearg0,arg1, …,argN. - Arguments to the traced function; assumed to be 64 bits widesarg0,sarg1, …,sargN. - Arguments to the traced function (for programs that store arguments on the stack); assumed to be 64 bits wideretval- Return value from traced functionfunc- Name of the traced functionprobe- Full name of the probecurtask- Current task struct as a u64rand- Random number as a u32cgroup- Cgroup ID of the current processcpid- Child pid(u32), only valid with the-c commandflag$1,$2, …,$N,$#. - Positional parameters for the bpftrace program
案例演示
SQL抓取
用一行代码体验一下如何抓取SQL
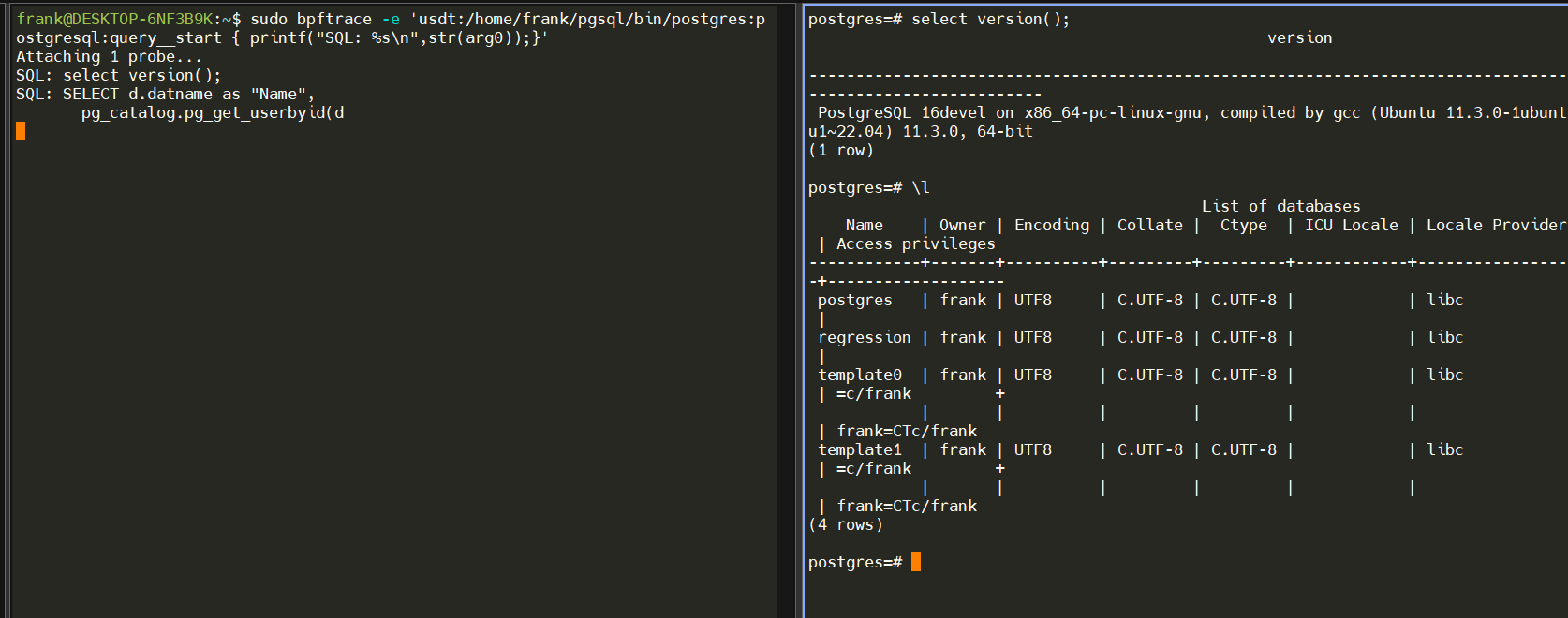
sudo bpftrace -e 'usdt:/home/frank/pgsql/bin/postgres:postgresql:query__start { printf("SQL: %s\n",str(arg0));}'
- 注解:参考官网
- 输出结果如下:
抓取慢SQL
设计思路与上一篇eBPF实现“零”侵入的慢SQL抓取 一致。“PostgreSQL中的大部分探针(probe)都是成对出现的,这样我们可以方便的通过“开始”–“结束”探针被触发的时间差来计算各个阶段的耗时。这里我们用
query__plan__start和query__plan__done来观测SQL执行的总时长。”
#!/usr/bin/bpftrace
BEGIN
{
printf("time(ms)\t sql\n");
@slow = 1
}
usdt:/home/frank/pgsql/bin/postgres:postgresql:query__start
{
@start[arg0] = nsecs;
}
usdt:/home/frank/pgsql/bin/postgres:postgresql:query__done
/@start[arg0]/
{
@slow = $1;
@usecs = ((nsecs - @start[arg0]) / 1000000);
if(@usecs > @slow) {
printf("%d(ms)\t %s\n", (@usecs), str(arg0));
}
delete(@start[arg0]);
}
END
{
clear(@start);
}
-
语法参考官方教程bpftrace Reference Guide(官方) ,这里就不多做解释了了。
-
运行效果如下:
sudo bpftrace pg.bt 1
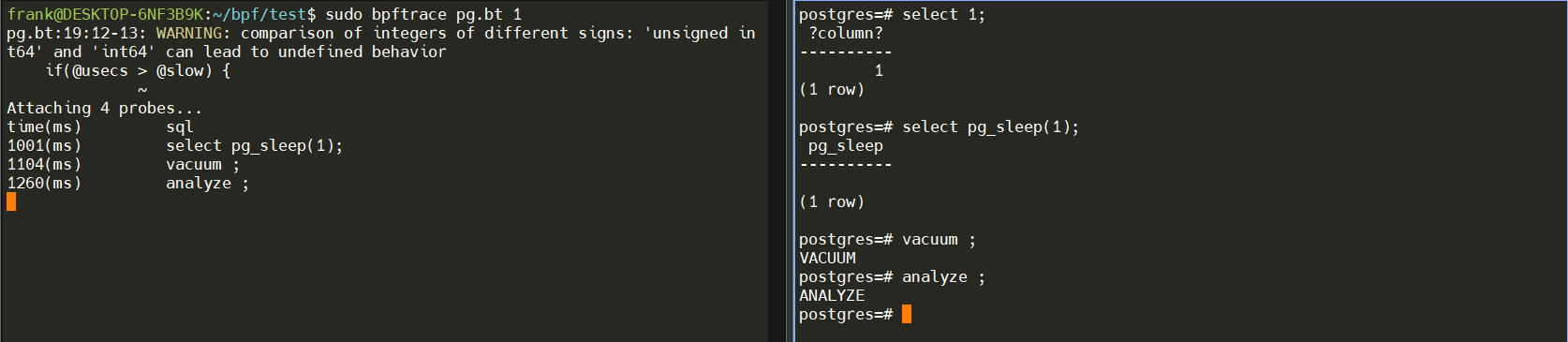
只抓取了执行时间大于1ms的SQL,而select 1;并没有被抓取。
结论
这一系列帖子围绕eBPF对数据库可观测能力的提升进行了展开,从不同的维度,不同的工具做了简单的描述。可以根据您的知识背景选择一款适合您日常运维或排障的工具。
