





字符集一个高深莫测又随处可见的东西你真的了解吗?我们最初接触这个东西的时候应该是在Jsp的时代,那个时候我们一见到乱码首先想到的是调下字符集改成GBK试试,随着时代的变迁也到了该让我们深入了解的时候了。
在解释何为字符集之间我们应该先来了解下我们日常所进行输入和输出的内容在计算机中是怎么来传输的。也许你会情不自禁的默默说声二进制,你的答案是正确的,那你知道我们人类所创造出的那么多种语言、字符又是怎么与之对应的吗?
计算机中储存信息的最小单位是字节(byte),一个字节也就是8位,如果使用00000000代表1,那最多也就能代表出2的8次方也就是256的字符(0-255),在我们大千世界中这是远远不足的。
不足了只能扩充,于是就有了后面我们经常见到的ISO-8859-1、GB2312、GBK、UTF-8、UTF-16等等
由于本文主要讲解的是MySql相关的内容,故下面我们只对UTF-8和UTF-16来展开讨论。
在说这两种编码之前我们需要先来了解一下Unicode编码,Unicode编码我们只需要知道这是一个大而全包含咱们这个位面上所有语言(亚马逊原始部落除外)的词典即可。而UTF-8和UTF-16是对Unicode编码的二次定义,他们定义了Unicode这个字典里的字符在计算机中的存取方法。
UTF-8在Mysql中采用1-4个字节来表示一个字符,也就是说一个英文字符占1一个字节,一个汉字可能占2到4个字节;
UTF-16也是一种变长的编码,它采用2-4个字节进行存储。在有些书中说UTF-16固定采用2个字节进行存取数据,这种说法是从错误的,只能说明你读那本书出版日期还停留在远古时代,在最初的确如此,但随着Unicode的不断完善已经超过了16位,UTF-16已经超过了2个字节了。
阅读到这里你可能已经注意到了,为什么我们平时进行数据存储的时候为啥总喜欢用UTF-8而不是UTF-16了,很简单,占用的空间小,能有效解决乱码以及提升系统存取性能呗。
难道UTF-16的确没有一点好处吗,现如今的确是。为什么说现如今,因为对于现在的UTF-16来说已经不再是采用定长编码了(UTF-32仍然是,采用固定4个字节),如果仍是定长编码,那它能带来的好处就是字符的快速定位。
在我们使用MySql数据库进行建库时,我们可以看到下面这张图的内容,图中我们可以看到MySql中UTF-8存在两个,那这两个编码又有何区别呢?
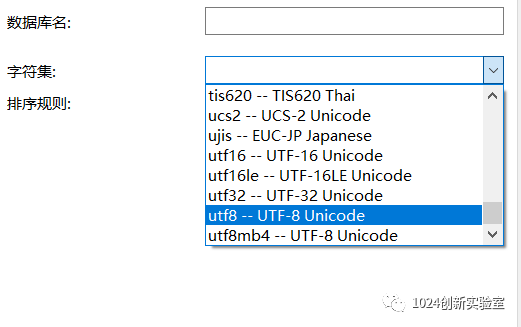
在阅读MySql官方文档(5.7)时我们可以看到这样一段话“The utf8mb3 Character Set (3-Byte UTF-8 Unicode Encoding)utf8 is an alias for utf8mb3”,从文档中我们可以看到UTF8是一种阉割过的编码集,最多占3个字节。
https://dev.mysql.com/doc/refman/5.7/en/charset-unicode-utf8mb3.html
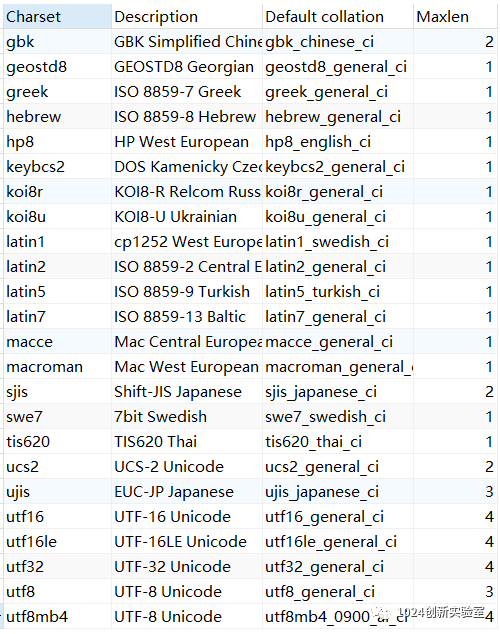
MySql支持的字符集我们可以通过输入命令“show charset”来进行查看,从查询结果我们可以清晰的看到各个字符集支持的最大长度以及默认的排序规则。
在阅读上节时有些人可能注意到了,我们在创建数据库时有一个“排序规则”选项,那这个排序规则又是何物?
所谓排序顾名思义是用来排序的,那么多排序规则我们又应该怎么选择呢?
我们先来看下utf8mb4有哪些排序规则,我们可以通过运行“show COLLATION like "utf8mb4%"”来查询具体某个字符集的排序规则(注意此图为Mysql8运行的截图):
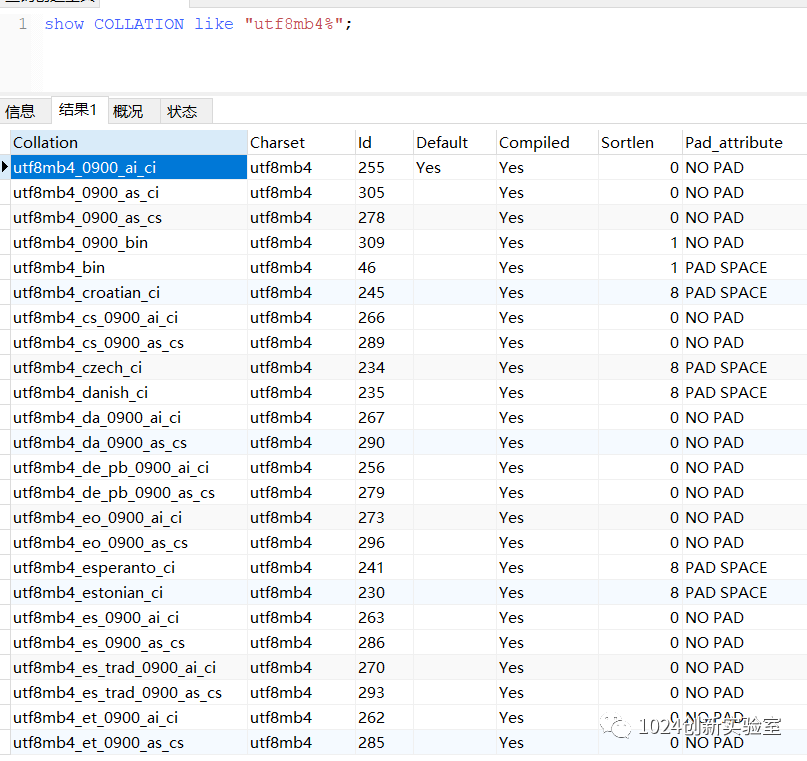
a:accent (口音)
c:case(大小写)
s:sensitive(敏感)
i:insensitive(不敏感)
bin:Binary(二进制)
0900:对应Unicode 9.0规范
下面我们通过设置一个字段的排序规则,来看下不同排序规则的运行效果。
第一次:设置name的排序规则为大小写不敏感
CREATE TABLE `t_test` (`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_as_ci DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;INSERT INTO `t_test` (`name`) VALUES ('A');INSERT INTO `t_test` (`name`) VALUES ('a');INSERT INTO `t_test` (`name`) VALUES ('b');INSERT INTO `t_test` (`name`) VALUES ('B');select * from t_test order by name desc;############输出结果为##################bBAa复制
第一次:设置name的排序规则为大小写敏感
ALTER TABLE `t_test`MODIFY COLUMN `name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_as_cs NULL DEFAULT NULL FIRST ;select * from t_test order by name desc;############输出结果为##################BbAa复制
细心的网友已经意识到了排序规则不仅可以在创建数据库时设置,也可以对表以及表中的字段进行单独设置,具体怎么来设置这里不再累述,有兴趣的同学可以自行百度。
历史文章推荐:
代码整洁
前端:
产品UI:
Java基础:
