




前言
今天在某个群里看到一个很有趣的问题
各位老师 vacuum full 表名,操作一张表后,数据文件大小没有变化,从哪里排查问题呢?
每 update 一次全表,数据增加1倍,vacuum full 表名后查看数据文件大下,还是不变
案例虽小,但是后面涉及到了不少的底层知识。让我们一起分析一下~
分析
熟悉 vacuum 的老铁肯定已经知晓原因了,vacuum 需要为那些老事务保留仍然需要的元祖,vacuum full 自然也是一样的道理,所以假如在重组的过程中,存在较老的事务,那么便会有很多死元组为了保证一致性,在重组的过程中,依旧留存在数据块中,这个便是 vacuum full 无法收缩大小的核心原理。
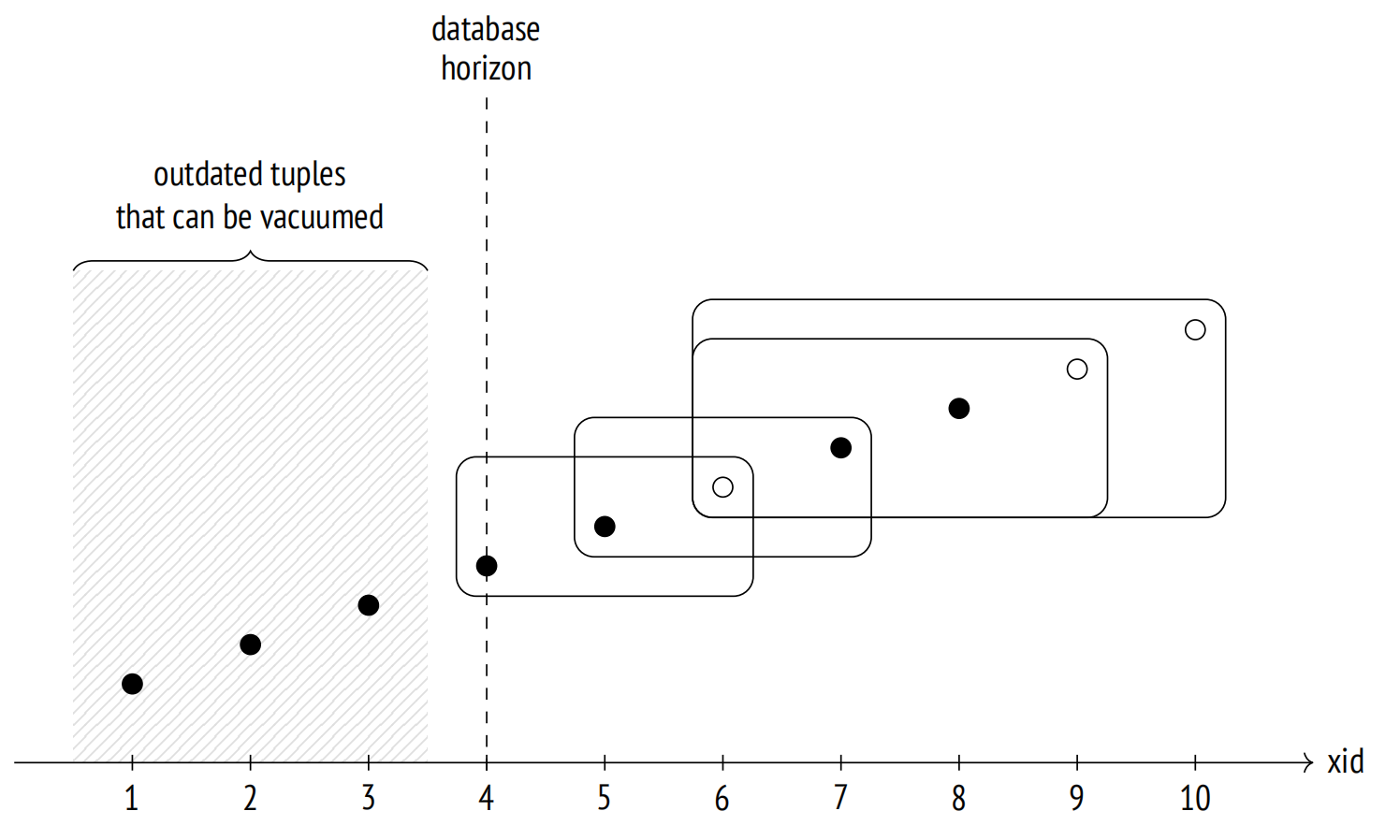
我们可以使用 vacuum full + verbose 来观测,👇🏻 是来自这个群友的截图,至于重建的进度可以观测 pg_stat_progress_cluster(Progress for VACUUM FULL commands is reported via pg_stat_progress_cluster because both VACUUM FULL and CLUSTER rewrite the table, while regular VACUUM only modifies it in place)
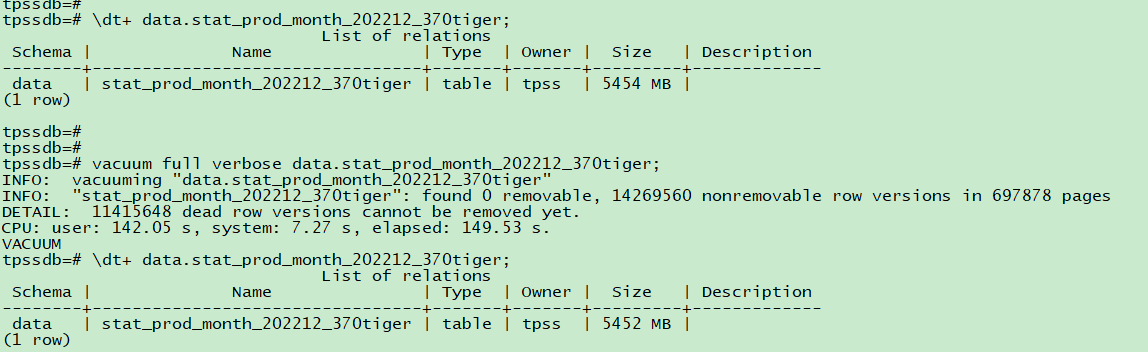
图片内容其实已经很清晰了,去找长事务/复制槽/2pc等持有事务号的对象即可。
DETAIL: 11415648 dead row versions cannot be removed yet.
那么哪些算是长事务呢?让我们看看代码逻辑,在 14 以前的代码逻辑在 GetOldestXmin 中,14 以后改到了 ComputeXidHorizons ,另外可以看到 vacuum_defer_cleanup_age 这个参数会影响到 OldestXmin 参数的计算。
/*
* Determine XID horizons.
*
* This is used by wrapper functions like GetOldestNonRemovableTransactionId()
* (for VACUUM), GetReplicationHorizons() (for hot_standby_feedback), etc as
* well as "internally" by GlobalVisUpdate() (see comment above struct
* GlobalVisState).
*
* See the definition of ComputeXidHorizonsResult for the various computed
* horizons.
...
...
*/
static void ComputeXidHorizons(ComputeXidHorizonsResult *h)
{
ProcArrayStruct *arrayP = procArray;
TransactionId kaxmin;
bool in_recovery = RecoveryInProgress();
TransactionId *other_xids = ProcGlobal->xids;
/* inferred after ProcArrayLock is released */
h->catalog_oldest_nonremovable = InvalidTransactionId;
...
...
else
{
/*
* Compute the cutoff XID by subtracting vacuum_defer_cleanup_age.
*
* vacuum_defer_cleanup_age provides some additional "slop" for the
* benefit of hot standby queries on standby servers. This is quick
* and dirty, and perhaps not all that useful unless the primary has a
* predictable transaction rate, but it offers some protection when
* there's no walsender connection. Note that we are assuming
* vacuum_defer_cleanup_age isn't large enough to cause wraparound ---
* so guc.c should limit it to no more than the xidStopLimit threshold
* in varsup.c. Also note that we intentionally don't apply
* vacuum_defer_cleanup_age on standby servers.
*/
h->oldest_considered_running =
TransactionIdRetreatedBy(h->oldest_considered_running, ---👈🏻又是这个参数
vacuum_defer_cleanup_age);
h->shared_oldest_nonremovable =
TransactionIdRetreatedBy(h->shared_oldest_nonremovable,
vacuum_defer_cleanup_age);
h->data_oldest_nonremovable =
TransactionIdRetreatedBy(h->data_oldest_nonremovable,
vacuum_defer_cleanup_age);
/* defer doesn't apply to temp relations */
}
复制整理逻辑大差不差,依旧是那么几个值
- backend_xid,所有后端进程的当前事务的最小值
- backend_xmin,所有后端进程的事务启动时的事务快照中最小事务的最小值
- replication_slot_xmin,所有复制槽中最小的 xmin
- replication_slot_catalog_xmin,所有复制槽中最小的 catalog_xmin
在 14 里面的大体优化逻辑简单来说,频繁更新 xmin,会带来较为严重的 CPU 缓存一致性(cache line)的问题,随着数据库的运行,事务提交终止都需要更新 PGXACT->xmin,在正常运行的系统中,由于 xid 是不断推进的,这个值的更新频率非常高;另一方面这个值又在循环中不断读取,不同进程遍历 PGXACT 会导致 Cache ping-pong,所以造成缓存不断失效的问题。
扯远了,回到问题,到底怎样才算是我们理解的长事务呢?没错,按照我们前面的分析,backend_xid 或者 backend_xmin 有值,所以正确写法是(自己添加其他判断条件,比如时间大于 10 分钟)
select * from pg_stat_activity where (backend_xid is not null or backend_xmin is not null) and state <> 'idle';
复制当然,这个 SQL 也不能说完全正确。为什么?比如 CIC 场景,我们知道创建索引我们一般都会用 create index concurrently,这个步骤很复杂,会涉及到很多流程,之前我曾写过一篇详细的文章来分析各个阶段,在此表过不提。
- 在系统表中插入索引的元数据,包括pg_class、pg_index,然后开启两个事务,进行两次扫描
- 开启事务1,拿到当前snapshot1。
- 扫描test1表前,等待所有修改过test1表(写入、删除、更新)的事务结束。
- 扫描test1表,并建立索引。
- 结束事务1。
- 开启事务2,拿到当前snapshot2。
- 再次扫描test1表前,等待所有修改过test1表(写入、删除、更新)的事务结束。
- 在snapshot2之后启动的事务对test1表执行的DML,会修改这个myidx的索引。
- 再次扫描test1表,更新索引。(从TUPLE中可以拿到版本号,在snapshot1到snapshot2之间变更的记录,将其合并到索引)
- 上一步更新索引结束后,等待事务2之前开启的持有snapshot的事务结束。
- 结束索引创建。索引可见。
多个步骤都会涉及到快照的获取,所以在 14 的版本里面引入了一个很重要的改进——VACUUM: ignore indexing operations with CONCURRENTLY
Avoid spurious waits in concurrent indexing In the various waiting phases of CREATE INDEX CONCURRENTLY (CIC) and REINDEX CONCURRENTLY (RC), we wait for other processes to release their snapshots; this is necessary in general for correctness. However, processes doing CIC in other tables cannot possibly affect CIC or RC done in “this” table, so we don’t need to wait for those. This commit adds a flag in MyProc->statusFlags to indicate that the current process is doing CIC, so that other processes doing CIC or RC can ignore it when waiting. Note that this logic is only valid if the index does not access other tables. For simplicity we avoid setting the flag if the index has a column that’s an expression, or has a WHERE predicate. (It is possible to have expressional or partial indexes that do not access other tables, but figuring that out would require more work.) This flag can potentially also be used by processes doing REINDEX CONCURRENTLY to be skipped; and by VACUUM to ignore processes in CIC or RC for the purposes of computing an Xmin. That’s left for future commits.
避免并发索引中的虚假等待。在 CREATE INDEX CONCURRENTLY (CIC) 和 REINDEX CONCURRENTLY (RC) 的各个等待阶段,我们等待其他进程释放他们的快照; 这通常是正确性所必需的。 但是,在其他表中执行 CIC 的进程不可能影响在“此”表中完成的 CIC 或 RC,因此我们不需要等待它们。 这个commit在MyProc->statusFlags中添加了一个flag,表示当前进程正在做CIC,这样其他做CIC或者RC的进程在等待的时候可以忽略它。请注意,此逻辑仅在索引不访问其他表时才有效。 为简单起见,如果索引的列是表达式或有 WHERE 谓词,我们将避免设置标志。 (可能有不访问其他表的表达式索引或部分索引,但弄清楚这一点需要更多工作。)这个标志也可能被执行 REINDEX CONCURRENTLY 的进程使用以被跳过; 并通过 VACUUM 忽略 CIC 或 RC 中的进程以计算 Xmin。 留给未来的提交。
VACUUM: ignore indexing operations with CONCURRENTLY As envisioned in commit c98763bf51bf, it is possible for VACUUM to ignore certain transactions that are executing CREATE INDEX CONCURRENTLY and REINDEX CONCURRENTLY for the purposes of computing Xmin; that’s because we know those transactions are not going to examine any other tables, and are not going to execute anything else in the same transaction. (Only operations on “safe” indexes can be ignored: those on indexes that are neither partial nor expressional). This is extremely useful in cases where CIC/RC can run for a very long time, because that used to be a significant headache for concurrent vacuuming of other tables.
VACUUM 有可能忽略某些正在执行 CREATE INDEX CONCURRENTLY 和 REINDEX CONCURRENTLY 的事务用于计算 Xmin; 那是因为我们知道这些事务不会检查任何其他表,也不会在同一事务中执行任何其他操作。 (只能忽略“安全”索引上的操作:那些既不是部分索引也不是表达式索引的操作)。这在 CIC/RC 可以运行很长时间的情况下非常有用,因为这曾经是其他表的并发清理的一大难题。
所以只要不是表达式索引或者部分索引,vacuum 在做清理判断的时候就会更加智能快速,跳过一些快照,避免无谓的膨胀。
分析到这里,想必读者已经十分激动了,这么多奇怪的知识,那么到这里就完了吗?没有,再接着往下看,这位群友又说道:
谢谢崔老师,我只清理了 state <>‘idle’ 的会话,可以释放空间了。
为啥 vacuum 成功了 日志还有 2023-03-27 13:35:27.784 CST [91471] ERROR: canceling autovacuum task 的记录?
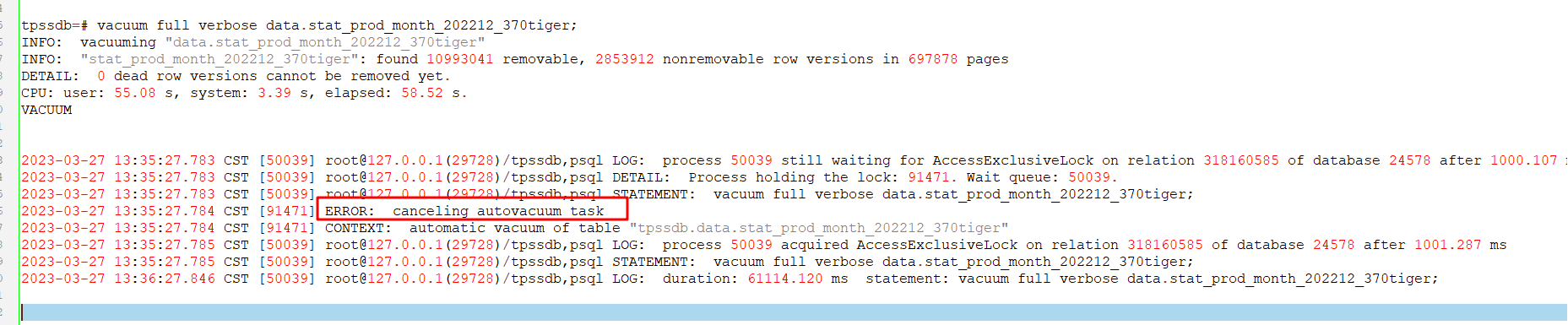
可以看到前面提示的确清理成功了
0 dead row versions cannot be removed yet.
结果这个时候来了 autovacuum,但是日志里提示被干掉了?不必惊慌,其实这个是正常的操作,该表上获取了会阻塞 autovacuum 的锁,比如上例,vacuum full 获取的 8 级锁。
很好复现,我找了个 10 版本的库,达到触发阈值之后立马开个窗口进行 lock table 即可,因为 autovacuum launcher 去读取统计信息再去 fork vacuum 是需要时间的,以前的文章分析过很多次了。
2023-03-27 18:14:08.898 CST [27236] ERROR: canceling autovacuum task 2023-03-27 18:14:08.898 CST [27236] CONTEXT: automatic analyze of table "postgres.public.big"复制
题外话
最开始我以为这个操作是因为 vacuum_truncate 这个操作,因为 vacuum 在最后一步操作会做截断页面的操作,这一步骤需要获取 AccessExclusiveLock,回收文件末尾的页,这个我印象很深刻,我在翻译 postgresql_internals-14_en 的时候特意去看了代码确认 👇🏻 autovacuum 同样会做这个操作

因为是 8 级锁,所以为了尽可能避免产生较大的阻塞,获取锁的时间不超过 5 秒,并且至少包含 1000 个页面。
/*
* Timing parameters for truncate locking heuristics.
*
* These were not exposed as user tunable GUC values because it didn't seem
* that the potential for improvement was great enough to merit the cost of
* supporting them.
*/
#define VACUUM_TRUNCATE_LOCK_CHECK_INTERVAL 20 /* ms */
#define VACUUM_TRUNCATE_LOCK_WAIT_INTERVAL 50 /* ms */
#define VACUUM_TRUNCATE_LOCK_TIMEOUT 5000 /* ms */
/*
* Space/time tradeoff parameters: do these need to be user-tunable?
*
* To consider truncating the relation, we want there to be at least
* REL_TRUNCATE_MINIMUM or (relsize / REL_TRUNCATE_FRACTION) (whichever
* is less) potentially-freeable pages.
*/
#define REL_TRUNCATE_MINIMUM 1000
#define REL_TRUNCATE_FRACTION 16
复制不过仔细想想, vacuum full 全程 8 级锁,所以是不会在做的过程中穿插一些其他操作的,是我想复杂了。🤣
小结
postgresql_internals-14_en 的确是一本不容错过的佳作呀。目前还差两章索引,初稿就完成啦。后面的大头就是复核审稿了,敬请期待…
参考
https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=c98763bf51bf
https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=d9d076222f5b94a85e0e318339cfc44b8f26022d
