




自适应哈希索引
O(1)就是最低的时空复杂度了,也就是耗时/耗空间与输入数据大小无关,无论输入数据增大多少倍,耗时/耗空间都不变。 哈希算法就是典型的O(1)时间复杂度,无论数据规模多大,都可以在一次计算后找到目标(不考虑冲突的话)。
InnodB存储引擎会监控对表上各索引页的查询。如果观察到建立哈希索引可以带来速度提升,则建立哈希索引,称之为自适应哈希索引(Adaptive Hash Index,AHI)。
AHI是通过缓冲池的B+树页构造而来,因此建立的速度很快,而且不需要对整张表构建哈希索引,只是对热点页建立hash索引。InnoDB存储引擎会自动根据访问的频率和模式来自动地为某些热点页建立哈希索引。
AHI要求对某个页的连续访问模式一样,比如对于(a,b)这样的联合索引页,存在下面两种情况:
where a = xxx;
where a = xxx and b=xxx
如果每次都查询条件一样,但是交替出现上面两种查询,那么InnoDB不会建立Hash索引,如果只出现一个查询,然后再满足下面的要求,InnoDB就会建立自适应Hash索引:
以该模式(同样的等值查询条件)访问了100次
页通过该模式访问了N次,N = 页记录/16
这种索引属于数据库的自优化,无需DBA进行人为调整。其本质是将频繁访问数据页的索引键值以“Key”放在缓存中,“Value”为该索引键值匹配完整记录所在页面(Page)的位置,通过缩短寻路路径(Search Path)从而提升MySQL查询性能的一种方式。
我们可以通过下面的命令查看当前自适应hash索引的使用情况:show engine innodb status\G
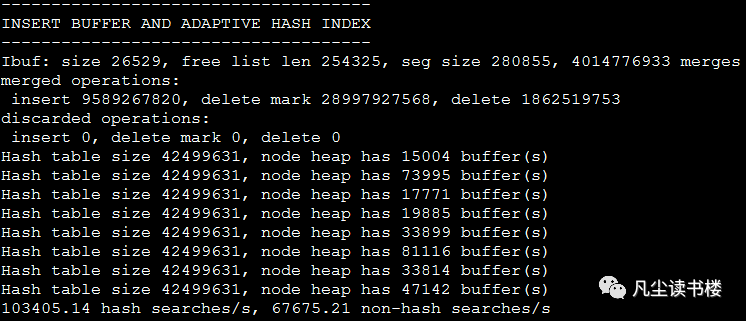
一共8个页,存储在buffer pool中的。上面的15004表示存储了15004个buffer。
自适应哈希索引可以通过参数innodb_adaptive_hash_index来禁用或启动此特性,默认为开启。
平时维护数据库,大表在DROP TABLE过程中,发现存在大量的线程处于OPENING TABLES的状态,DROP 时间非常的长。原因就是DROP TABLE时,InnoDB存储引擎还会删除表对应的AHI(自适应哈希索引)。而这个过程需要持有一把数据字典的互斥锁、读写锁。
这里的读写锁指的不是事务锁中的共享锁和排他锁,而指的是内存锁里的rwlock。MySQL中锁有着Lock和Latch的概念,Lock通常指事务锁,而Latch通常指的是内存锁。
对于这个问题,可以在DROP TABLE的时候关闭AHI功能,甚至可以永久关闭AHI功能。
优缺点
优点
1、无序,没有树高;
2、降低对二级索引树的频繁访问资源,查询消耗 O(1);
3、自适应,不用人为创建。
缺点
1、自适应hash索引会占用innodb buffer pool;
2、自适应hash索引只适合搜索等值的查询,而对于其他查找类型,如范围查找、模糊查询,是不能使用的;
3、自适应哈希索引无法对order by进行优化;
4、只有在某些负载情况下,通过哈希索引查找带来的性能提升才能远大于额外的监控索引搜索情况和保持这个哈希表结构所带来的开销,此时自适应hash索引才有比较大的意义,可以降低逻辑读。
全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
❤ 欢迎关注我的公众号【凡尘读书楼】,一起学习新知识!
————————————————————————————
公众号:凡尘读书楼
墨天轮:https://www.modb.pro/u/399450
知识星球 :凡尘dba人生有限公司
————————————————————————————
