





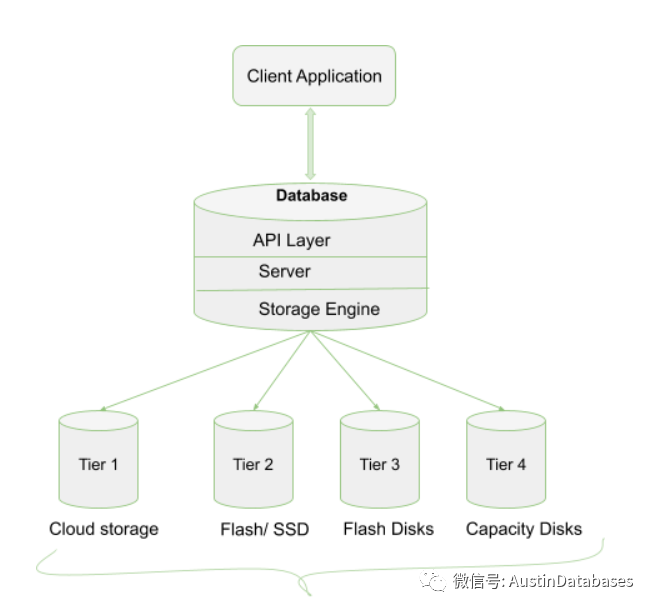
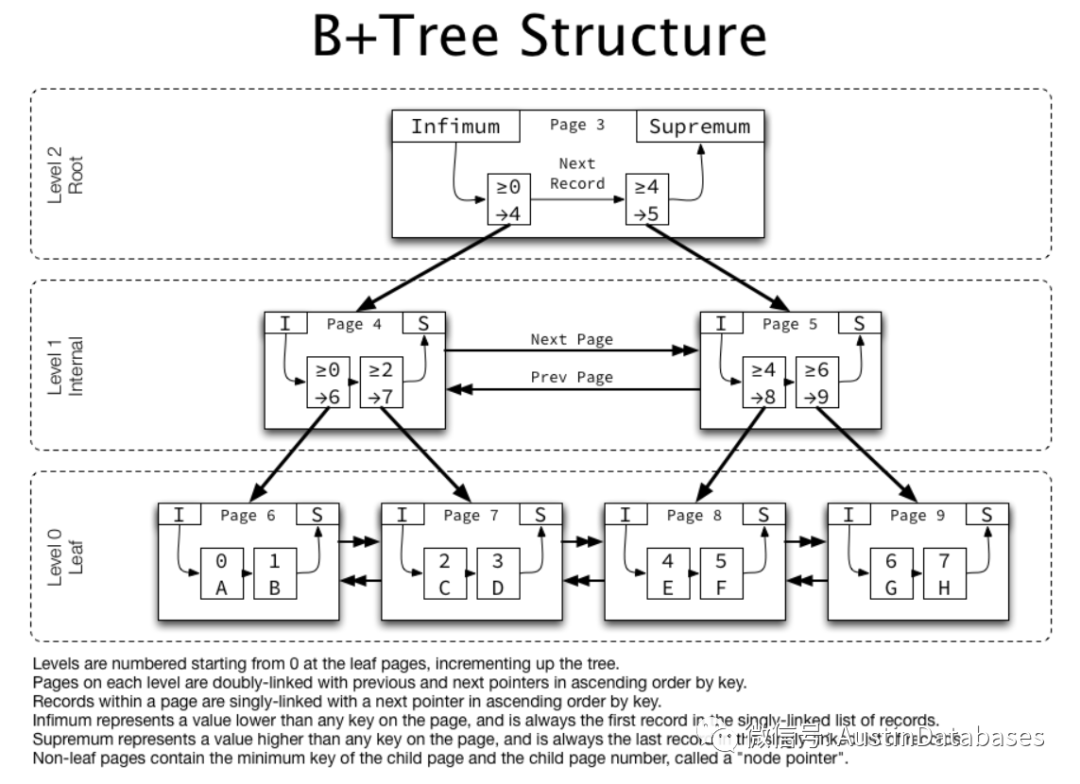
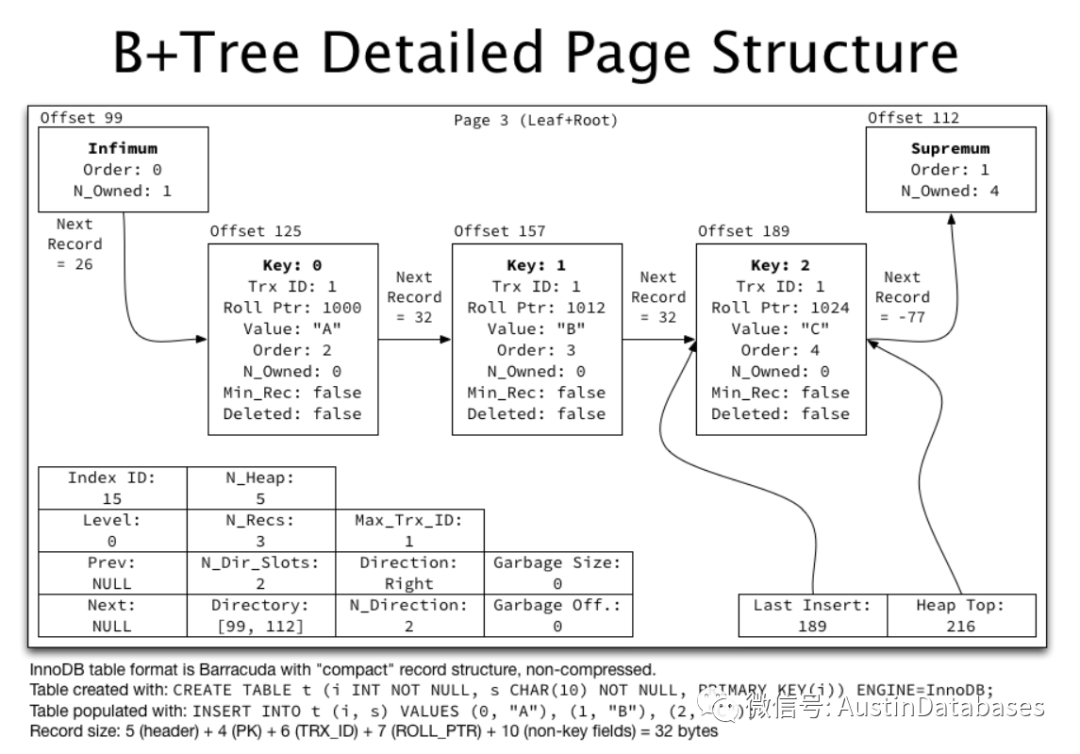
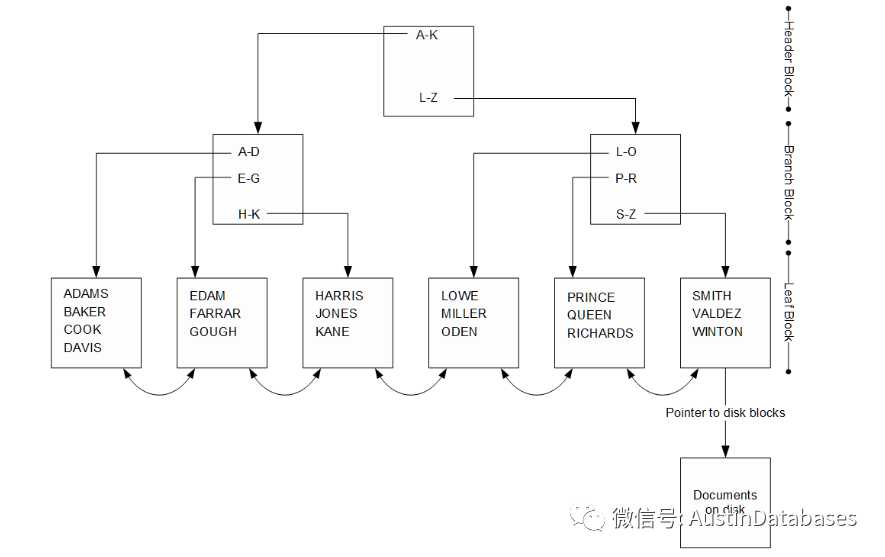
2 Mongodb的各个节点存储数据,所以数据的查询的复杂度是不固定的与键值所在树中的位置有关,所以查询的复杂度为 O(1)
3 MYSQL 叶子节点之间是连接的,之间间隔的叶子节点可以直接进行访问,对于范围查询是有利的。
4 MONOGDB 中的节点存储的是 键和值,叶子节点之间是不存在直接访问的方式
问题来了,为什么MONGODB 要使用 B-TREE 而不是 B+TREE 的方式来进行数据结构的组织。
MONGODB 不是传统关系型数据库,在MOGNODB 的使用当中主要进行的是JOSN 数据的存储,并且MOGNODB 擅长的查询方式是非范围方式的查询,MYSQL 数据查询中,数据都在叶子节点中,所有的数据访问都需要访问到叶子节点,而MONGODB 中的每个节点都包含数据,所以如果是非范围查询的方式,MONGODB的数据查询方式的访问数据的速度要快于 MYSQL。
所以MONGODB 不擅长的查询也就确定了,大量的范围方式的查询并不是MONGODB 擅长的,从MOGNODB 对于聚合操作的不擅长就有数据结构组织的“功劳”。
同时在MOGNODB 的数据页面中,还有一个问题,就是数据的更新的问题,基于B-TREE的数据存储的方式,如果这个页面中的数据UPDATE 了,那么这个页面中更新的数据已经不能继续容纳在这个页面的情况下,就会产生页面的分裂,在MONGODB中一个新的页面中是需要分配需要被页分裂页面中的数据的一半的数据的,而在基于这个页面的索引也会被迁移到另一个页面中。
所以基于数据结构的问题,MONGODB 在基于B-TREE的有利和缺陷都一目了然,那么解决这个问题的方法,按照传统的数据库的思路就是,collection中的填充因子,而MONGODB 的填充因子是自动进行修正的,这里我们称之为 paddingFactor.

文章转载自AustinDatabases,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
