




欢迎访问 OceanBase 官网获取更多信息:https://www.oceanbase.com/
分布式执行简介
OceanBase 数据库基于 Shared-Nothing 的分布式系统构建,具有分布式执行计划生成和执行能力。
由于一个关系数据表的数据会以分区的方式存放在系统里面的各个节点上,所以对于跨分区的数据查询请求,必然会要求执行计划能够对多个节点的数据进行操作。OceanBase 数据库的优化器会自动根据查询和数据的物理分布生成分布式执行计划。对于分布式执行计划,分区可以提高查询性能。如果数据库关系表比较小,则不必要进行分区,如果关系表比较大,则需要根据上层业务需求谨慎选择分区键,以保证大多数查询能够使用分区键进行分区裁剪,从而减少数据访问量。
同时,对于有关联性的表,建议使用关联键作为分区键,并采用相同分区方式,使用表组将相同的分区配置在同样的节点上,以减少跨节点的数据交互。
并行查询简介
并行查询是指通过对查询计划的并行化执行,提升对每一个查询计划的 CPU 和 IO 处理能力,从而缩短单个查询的响应时间。并行查询技术可以用于分布式执行计划,也可以用于本地查询计划。
当单个查询的访问数据不在同一个节点上时,需要通过数据重分布的方式,相关数据执行分发到相同的节点进行计算。以每一次的数据重分布节点为上下界,OceanBase 数据库的执行计划在垂直方向上被划分为多个 DFO(Data Flow Object),而每一个 DFO 可以被切分为指定并行度的任务,通过并发执行以提高执行效率。
一般来说,当并行度提高时,查询的响应时间会缩短,更多的 CPU、IO 和内存资源会被用于执行查询命令。对于支持大数据量查询处理的 DSS(Decision Support Systems)系统或者数据仓库型应用来说,查询时间的提升尤为明显。
整体来说,并行查询的总体思路和分布式执行计划有相似之处,即将执行计划分解之后,将执行计划的每个部分由多个执行线程执行,通过一定的调度的方式,实现执行计划的 DFO 之间的并发执行和 DFO 内部的并发执行。并行查询特别适用于在线交易(OLTP)场景的批量更新操作、创建索引和维护索引等操作。
当系统满足以下条件时,并行查询可以有效提升系统处理性能:
充足的 IO 带宽
系统 CPU 负载较低
充足的内存资源
如果系统没有充足的资源进行额外的并行处理,使用并行查询或者提高并行度并不能提高执行性能。相反,在系统过载的情况下,操作系统会被迫进行更多的调度,例如执行上下文切换可能会导致性能的下降。
通常在 DSS 系统中,需要访问大量数据,这时并行执行能够提升执行响应时间。对于简单的 DML 操作或者涉及数据量比较小的查询来说,使用并行查询并不能很明显的降低查询响应时间。
并行查询和分布式查询原理
OceanBase 数据库的数据以分片的形式存储于每个节点,节点之间通过千兆、万兆网络通信。一般会在每个节点上部署一个叫做 observer 的进程,它是 OceanBase 数据库对外服务的主体。如下图所示。
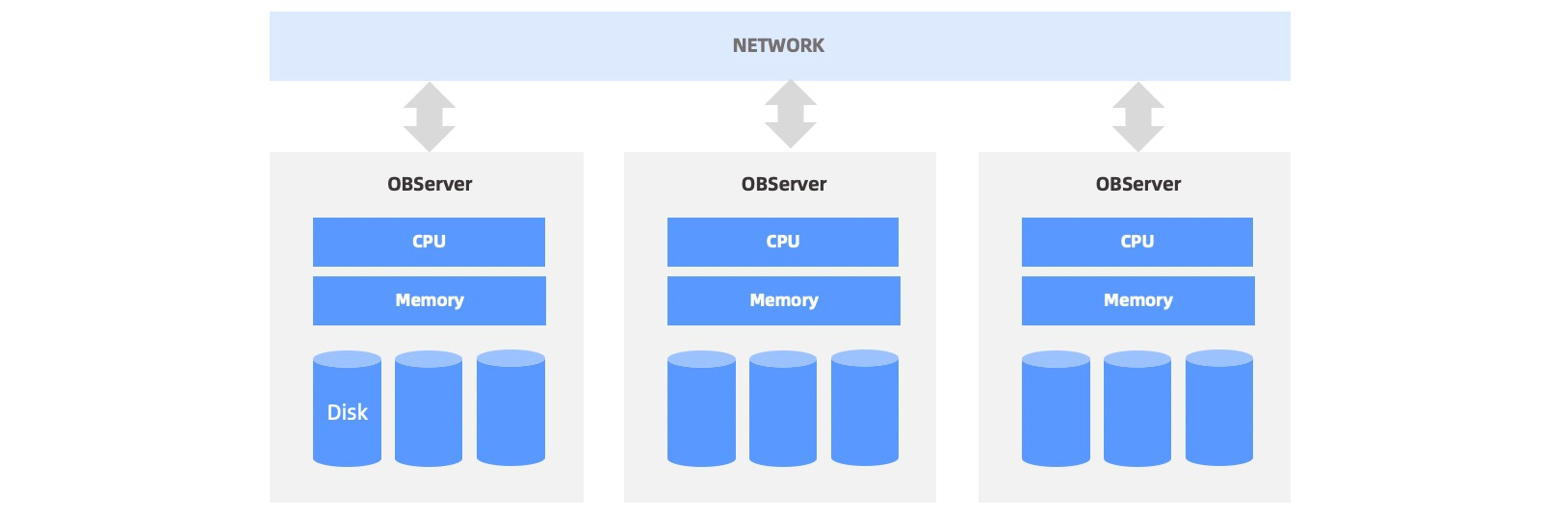
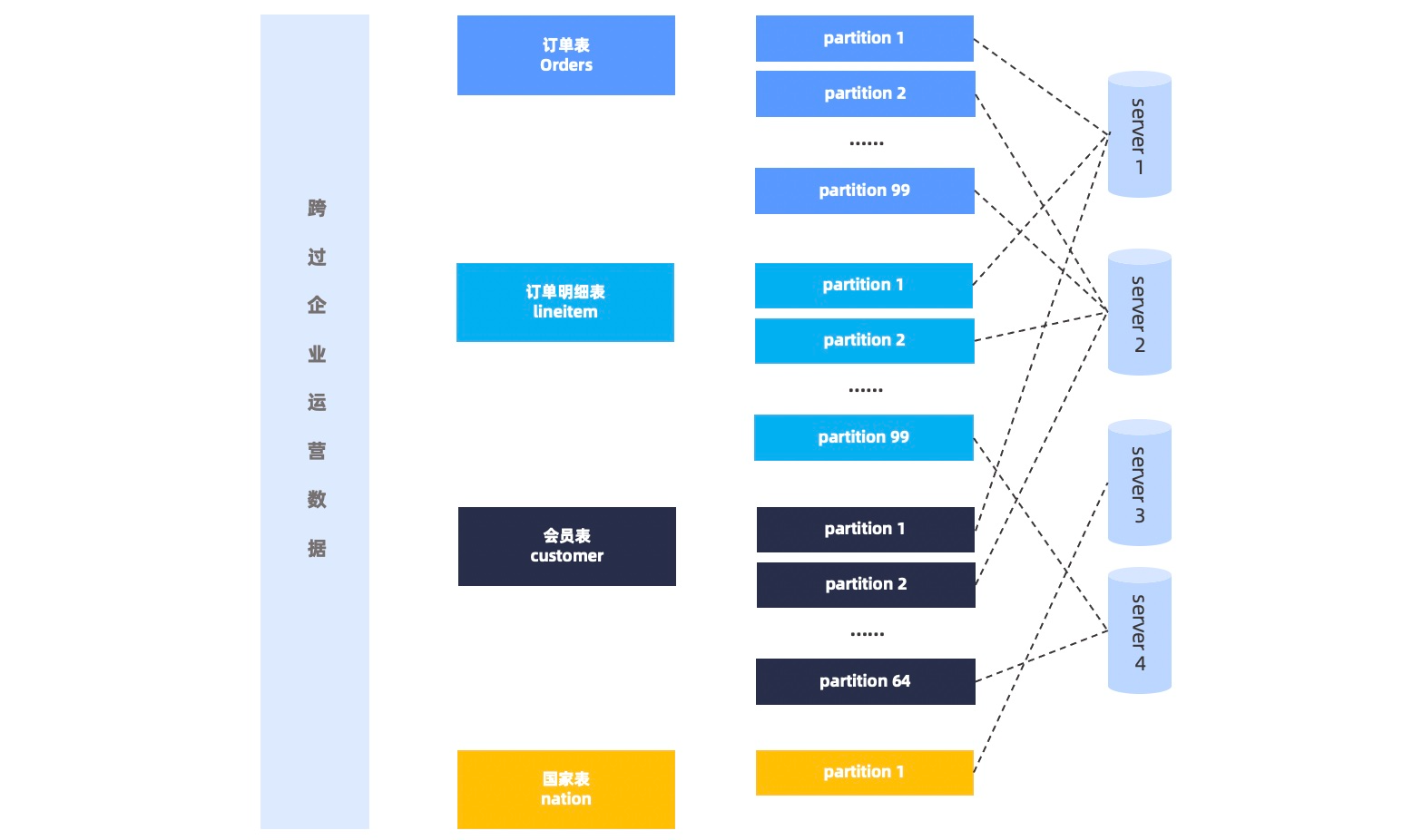
OceanBase 数据库会根据一定的均衡策略将数据分片均衡到多个 observer 进程上,因此对于一个并行查询一般需要同时访问多个 observer 进程。如下图所示。
欢迎访问 OceanBase 官网获取更多信息:https://www.oceanbase.com/


