




PDI(Kettle)介绍
Kettle最早是一个开源的ETL工具,全称为KDE Extraction, Transportation, Transformation and Loading Environment。后来,Pentaho公司收购了Kettle项目,从此,Kettle成为企业级数据集成及商业智能套件Pentaho的主要组成部分,Kettle亦重命名为Pentaho Data Integration(简称PDI)。Pentaho公司后来又被日本的日立收购,成为Hitachi Vantara的一部分。

PDI以Java开发,支持跨平台运行,其特性包括:支持100%无编码、拖拽方式开发ETL数据管道;可对接包括传统数据库、文件、大数据平台、接口、流数据等数据源;支持ETL数据管道加入机器学习算法。KDI分为商业版与开源版,一般人仍习惯把Pentaho Data Integration的开源版称为Kettle。

主要功能
PDI作为一个端对端的数据集成平台,可以对多种数据源进行抽取(Extraction)、加载(Loading)、数据落湖(Data Lake Injection)、对数据进行各种清洗(Cleaning)、转换(Transformation)、混合(Blending),并支持多维联机分析处理(OLAP)和数据挖掘(Data mining)。部分特色功能包括:
1.无代码拖拽式构建数据管道
2.多种数据源支持
3.数据管道可视化
4.模板化开发数据管道
5.可视化计划任务
6.大数据处理
01 | 无代码拖拽式构建数据管道

Pentaho采用拖拽组件、连线、配置的方式来构建数据管道,透过几百个不同的组件,用户可以在不编写一句代码就能轻松完成对数据源读取,对数据进行关联、过滤、格式转换、计算、统计、建模、挖掘、输出到不同的数据目标,极大程度地降低开发技术门槛和有效减低开发和维护成本。
02 | 多种数据源支持
关系型数据库支持类型包括:DB2,Greenplum, Hive, MS SQL Server, MySQL, Oracle, PostgreSQL等。大数据源支持包括:Avro, Cassanddra, HBase, HDFS, MongoDB等。文件格式支持包括:CSV, TXT, JSON, Excel, XML等。流数据支持包括:AMQP, Kafka, MQTT, 其他数据源对接包括:S3, SAS, Salesforce, REST等。
03 | 数据管道可视化
支持用户在数据管道任何一个步骤对当前数据进行查看(Examine),并可以在线以表格和图表(例如:柱状图、饼图等)输出步骤的数据,甚至可以支持不落地直接把任何一个步骤的数据以JDBC的方式提供给第三方应用访问。
04 | 模板化开发数据管道
PDI提供了一个叫MDI的功能,MDI全称是Metadata Injection元数据注入,用户可以透过MDI把数据转换模板化,然后把像数据表名、文件路径、分隔符、字符集等等这些变量放在一个表或者文件里,然后利用MDI把这些变量注入数据转换模板,PDI即可自动生成所需要的数据转换。
05 | 可视化计划任务
PDI提供可视化方式配置任务计划(Schedule),用户可透过Spoon或网页端的Pentaho User Console(商业版)来配置和维护任务具体的执行时间、间隔、所使用的参数值、以及具体运行的服务器节点。用户亦可以透过Spoon或Pentaho User Console(商业版)查看任务计划列表。当然,用户也可以透过Spoon或Pentaho User Console(商业版)对任务执行情况进行实时监控。
06 | 大数据处理
使用转换步骤连接到各种大数据数据源,包括 Hadoop、NoSQL 和分析数据库(如 MongoDB)。
项目结构
1.assemblies:项目分发存档在此模块下生成
2.core:核心实现
3.dbdialog:数据库对话框
4.ui:用户界面
5.engine:PDI引擎
6.engine-ext: PDI引擎扩展插件
7.plugins:PDI core插件
8.integration:集成测试
PDI客户端
PDI 客户端(也称为 Spoon)是一个桌面应用程序,可让您构建转换以及安排和运行作业。
PDI 客户端的常见用途包括:
1.不同数据库和应用程序之间的数据迁移
2.充分利用云、集群和大规模并行处理环境将庞大的数据集加载到数据库中
3.使用从非常简单到非常复杂的转换的步骤进行数据清理
数据集成,包括利用实时 ETL 作为 Pentaho Reporting 数据源的能力
4.内置支持缓慢变化维度和代理键创建的数据仓库填充
相关链接

PDI相关地址

01
源码地址:
https://github.com/pentaho/pentaho-kettle/
02
官方社区版下载地址: https://www.hitachivantara.com/en-us/products/dataops-software/data-integration-analytics/pentaho-community-edition.html
03
sourceforge下载地址:
https://sourceforge.net/projects/pentaho/files/
如果需要最新的PDI,可使用Maven(3+)构建。注意:最新的PDI已使用Java JDK 11。
安装PDI
01 | 前提
a.安装JDK 11
b.对于Linux/Uubuntu安装,还需要安装libwebkitgtk-1.0-0才能使PDI正常工作
02 | 下载Zip
从Hitachi Vantara Pentaho社区页面下载适用于您的操作系统的压缩包,版本和构建名为:pdi ce-<version>-<build>.zip。
03 | 解压Zip
将文件解压到指定目录
04 | 添加JDBC
在PDI安装目录的data-integration\lib下添加相应数据库的JDBC驱动
04 | 启动PDI
对于Windows,找到spoon.bat。双击此文件以启动PDI。对于Linux/Ubuntu,输入./spoon.sh命令启动PDI
spoon迁移表结构

新建一个作业或者转换

DB连接-新建数据库连接向导
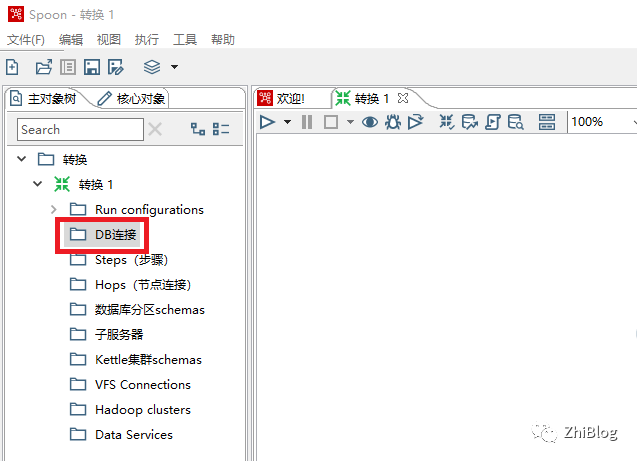
选择数据库名称和类型
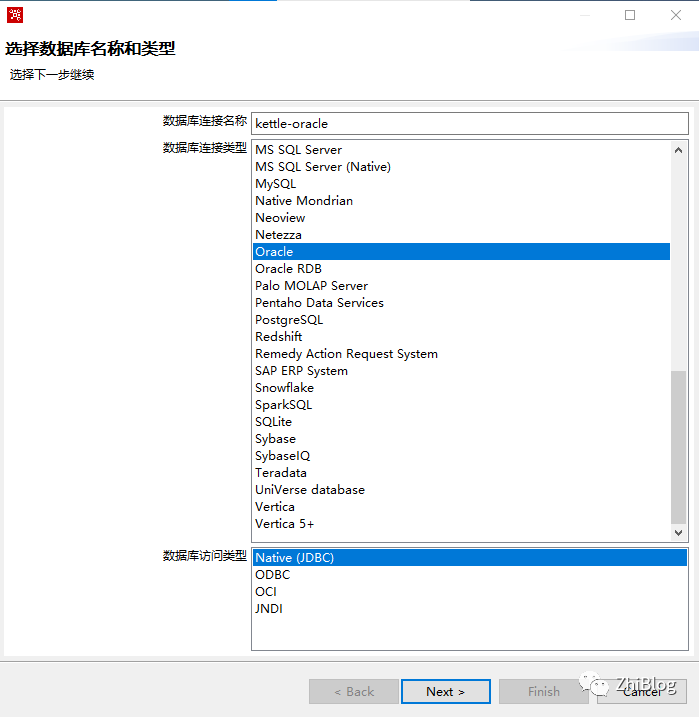
输入数据库地址、端口以及数据库名

数据库空间和索引表空间可不设置
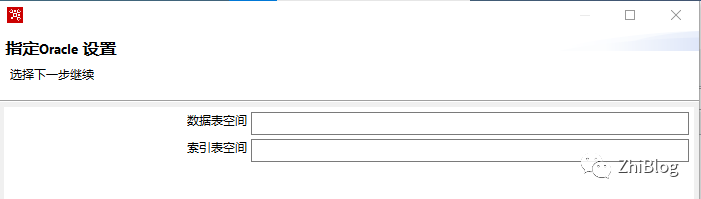
设置数据库用户名和密码并测试连接
复制多表向导
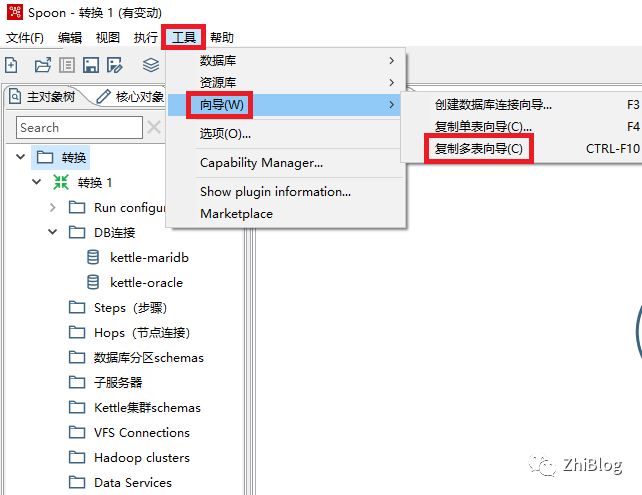
选择源和目的数据库

选择要迁移的表
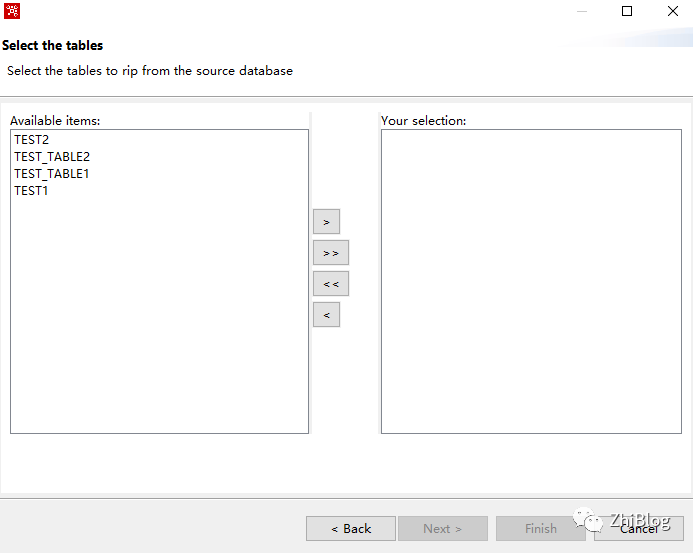
注意1:这里的表是按表创建时间排序的,无法按其他方式进行排序。特别是对于需要迁移的表以及表数据众多的时候,如果表转换出现问题,很难排查,建议批量转换。
注意2: Kettle最主要的作用在于数据的抽取和转换,函数、存储过程、视图以及索引、约束等无法通过Kettle进行迁移。
配置Job名以及Job存放目录
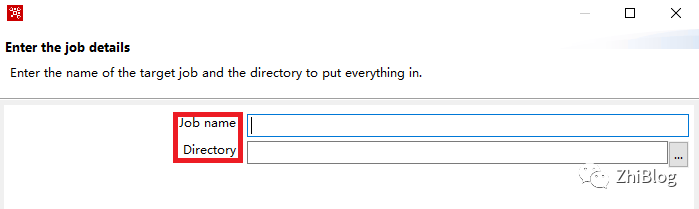
生成了一个作业
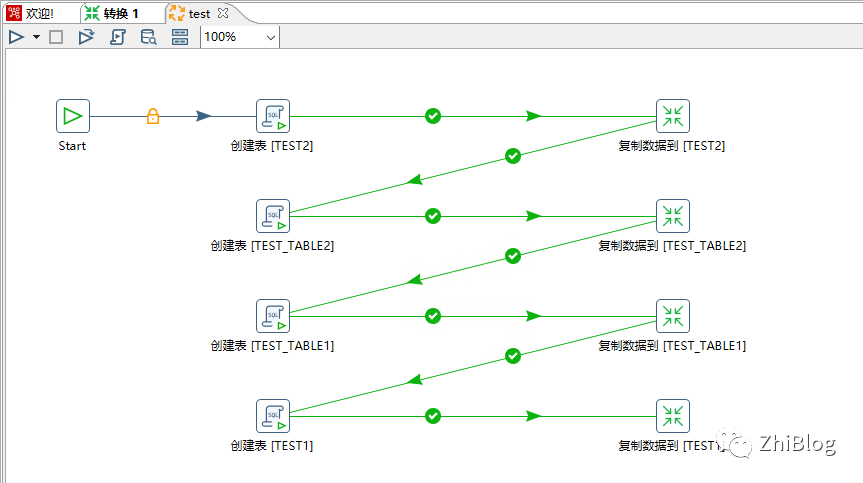
注意:如果需要迁移的数据很少,直接点击RUN箭头迁移即可。
Generate the SQL needed to run this job-生成SQL
查看并执行SQL
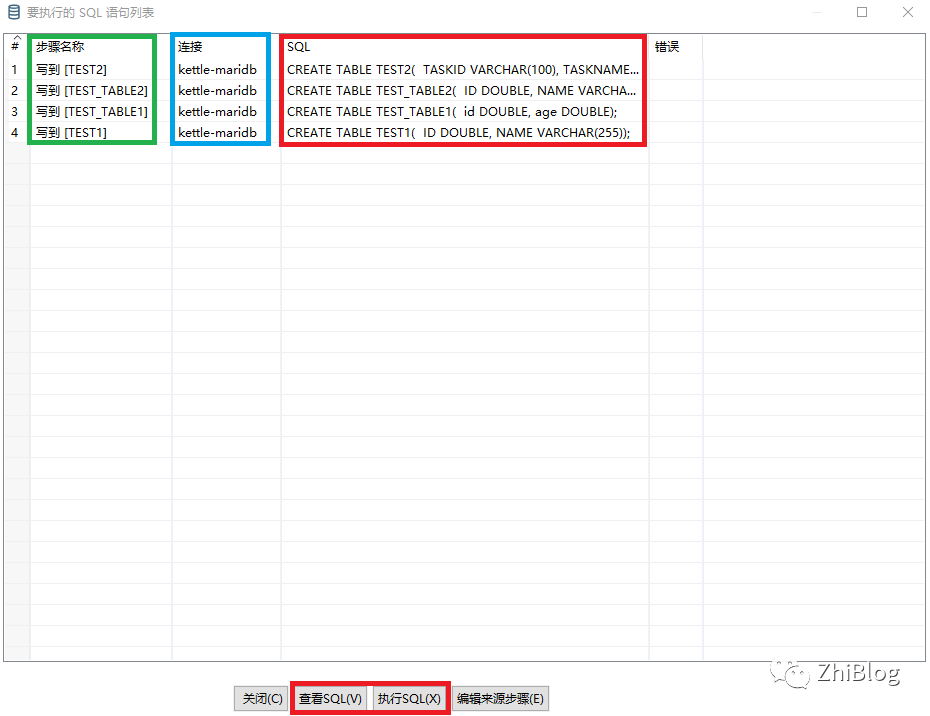
查看表结构迁移情况
MariaDB [test]> show tables;Empty set (0.000 sec)MariaDB [test]> show tables;+----------------+| Tables_in_test |+----------------+| test1 || test2 || test_table1 || test_table2 |+----------------+4 rows in set (0.000 sec)
定时同步单表数据
新建转换
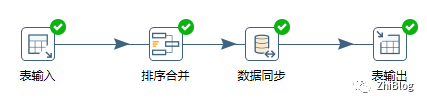
新建作业
表输入组件
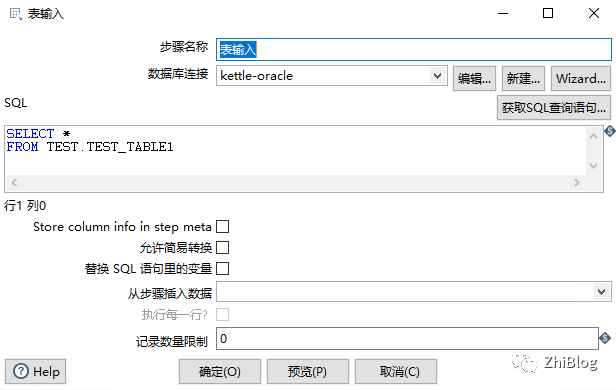
排序合并组件
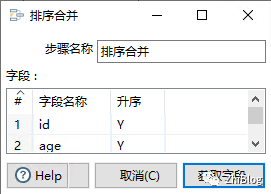
数据同步组件
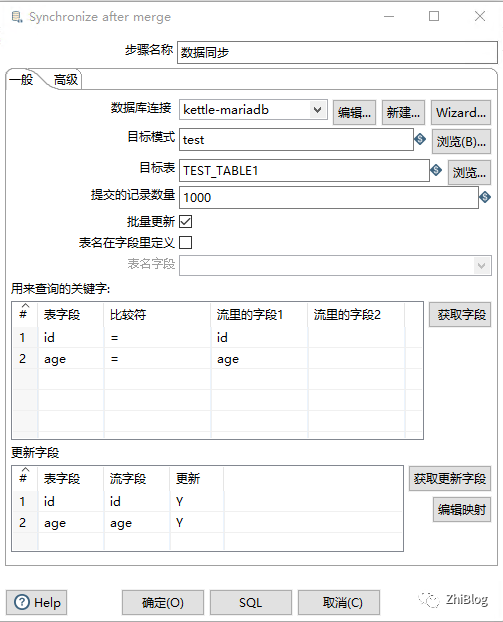
表输出组件
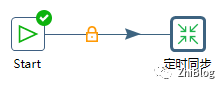
指定作业中转换文件的路径
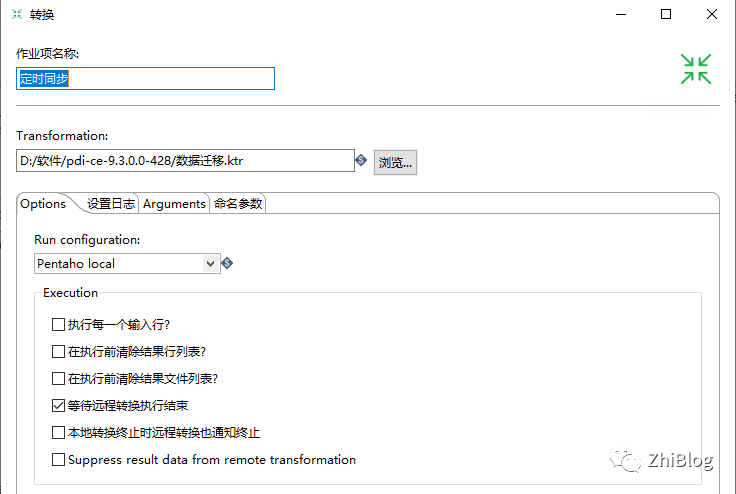
配置每30秒同步一次
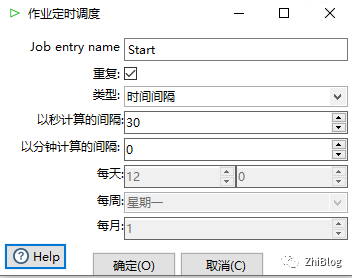
点击RUN执行作业
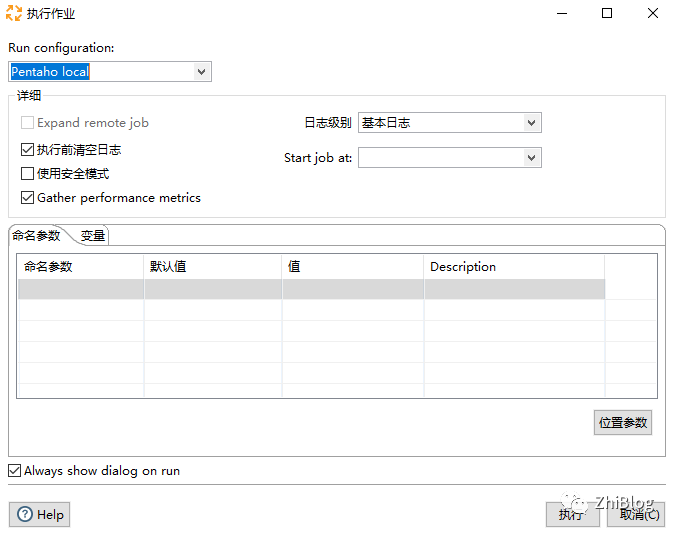
查看执行结果

源库insert
INSERT INTO "TEST_TABLE1" ("id", "age") VALUES ('5', '21');INSERT INTO "TEST_TABLE1" ("id", "age") VALUES ('6', '21');INSERT INTO "TEST_TABLE1" ("id", "age") VALUES ('7', '22');INSERT INTO "TEST_TABLE1" ("id", "age") VALUES ('8', '22');
目标库查看同步情况
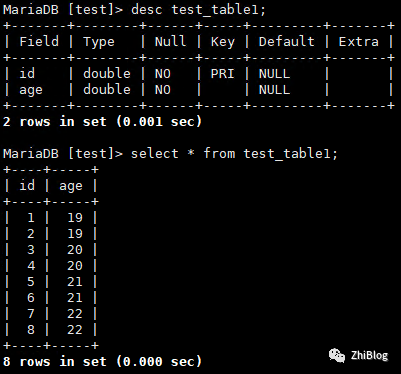
源库update
UPDATE "TEST_TABLE1" SET "age" = '24' WHERE "id" = '1';UPDATE "TEST_TABLE1" SET "age" = '26' WHERE "id" = '2';
目标库查看同步情况
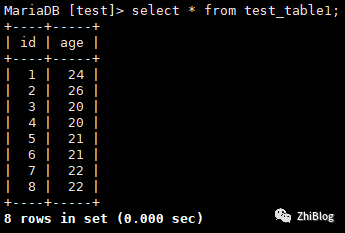
源库delete
DELETE "TEST_TABLE1" WHERE "id" = '7';DELETE "TEST_TABLE1" WHERE "id" = '8';
目标库查看同步情况
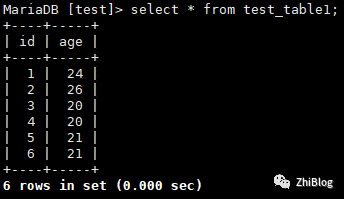
定时多表数据同步
多表同步任务-主作业
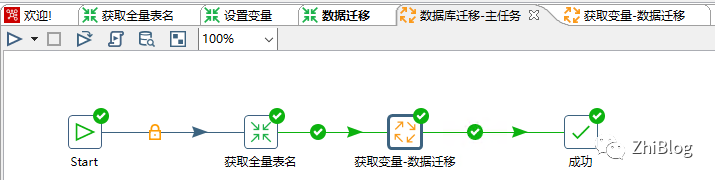
获取变量-数据迁移-作业
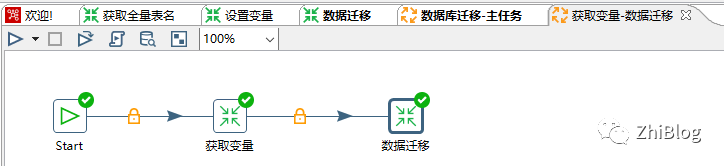
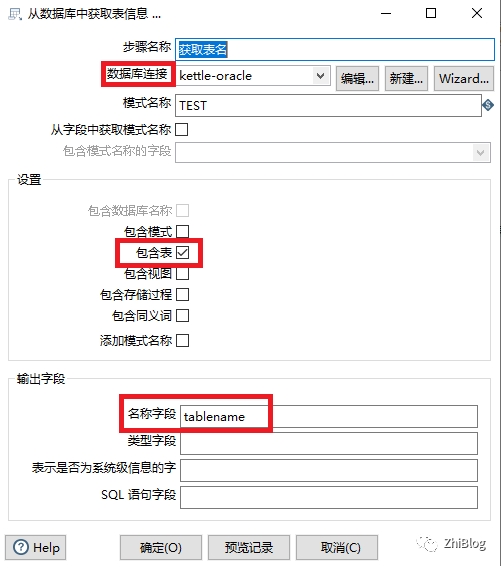
获取全量表名-转换任务
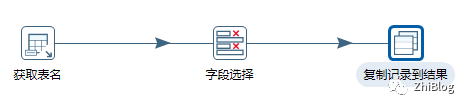
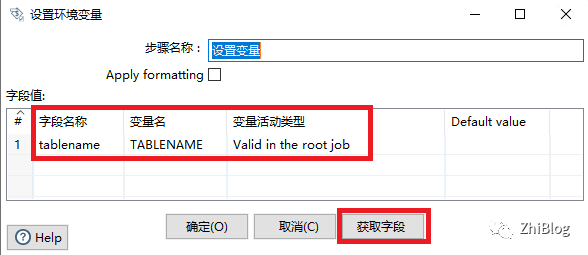
设置变量-转换任务
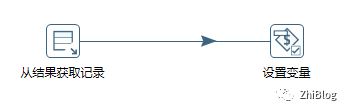
数据迁移同步-转换任务
获取表名组件
字段选择组件
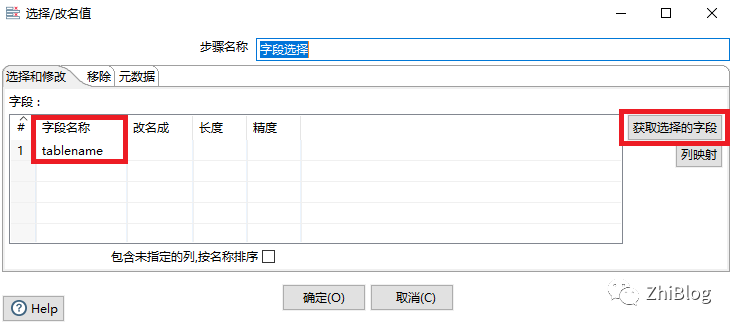
复制记录到结果组件
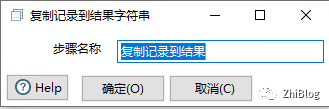
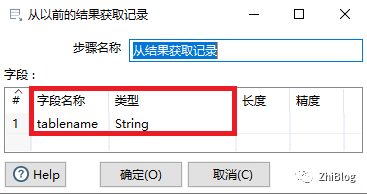
从结果获取记录组件
设置环境变量
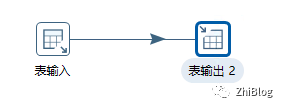
表输入组件
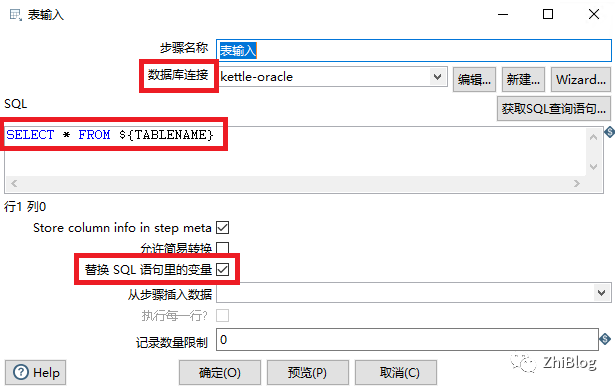
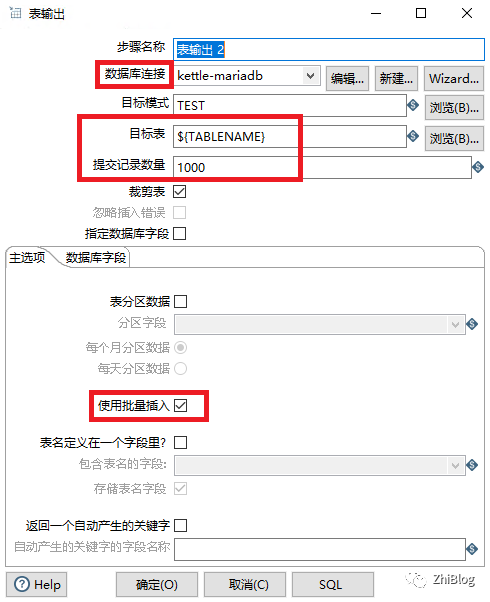
表输出组件
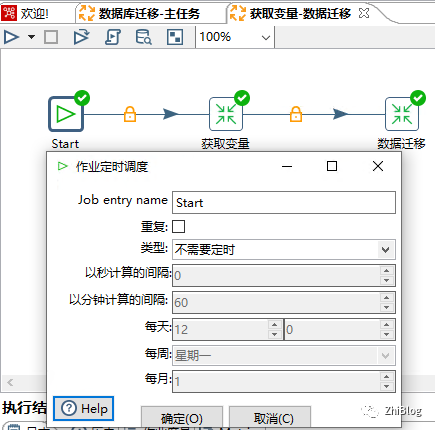
获取变量-数据迁移作业-start
指定转换任务-获取变量-文件路径
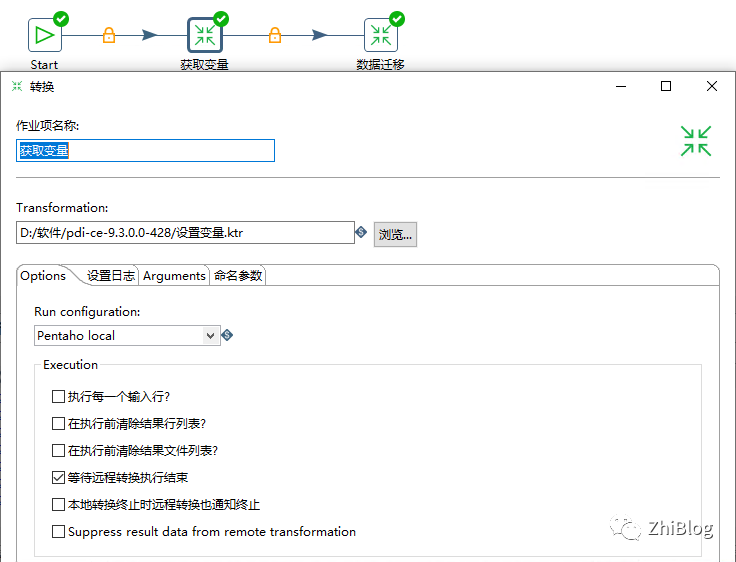
指定转换任务-数据迁移-文件路径
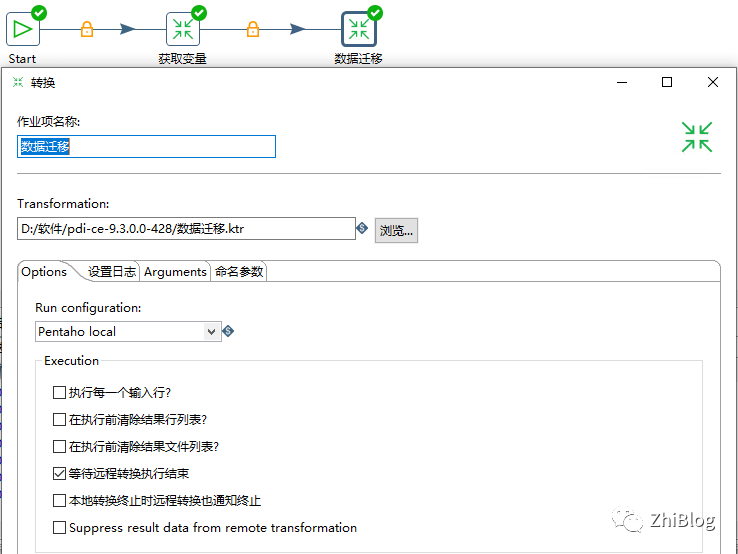
数据迁移作业-主任务-配置定时任务
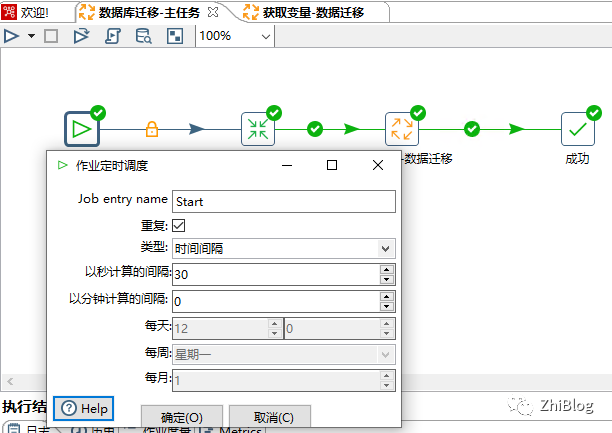
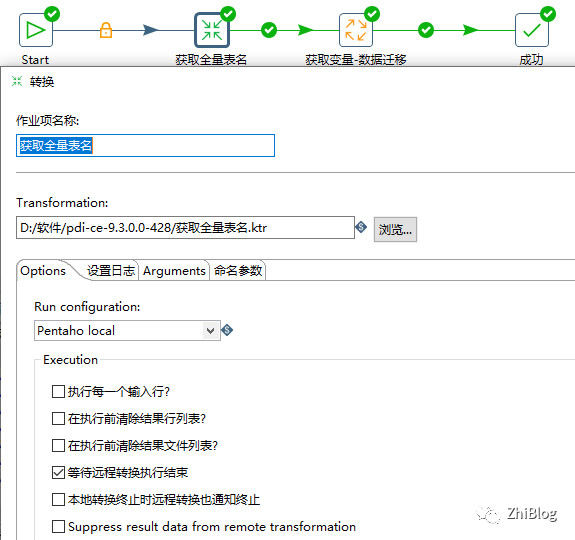
主任务-配置获取全量表名任务路径
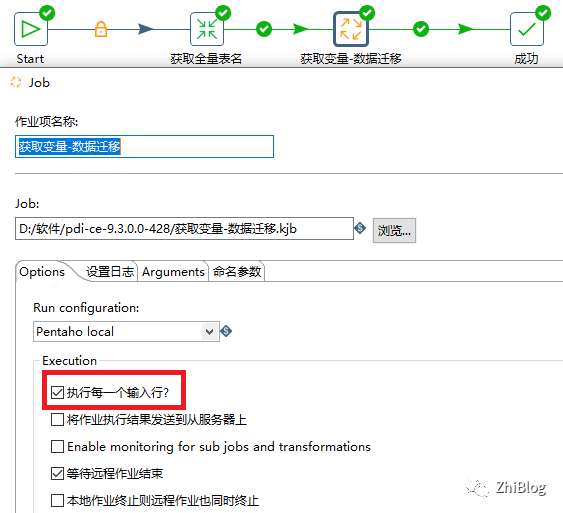
主任务-配置获取变量与数据迁移作业并勾选执行每一个输入行
点击主任务-RUN-执行作业

查看执行结果




