




1、问题复现
巡查生产环境慢SQL日志,发现一条很简单的语句需要执行35S,而改变一下驱动表只需要0.047S,性能相差744倍
执行35秒的原语句
explain
SELECT
A.gid
FROM B
inner join A ON A.profileid = B.profileid AND A.billid = B.billid
inner join c ON A.gid = c.GID
WHERE B.col1= 200002125
AND B.col2= 604
AND B.col3= 5915606
AND B.col4!= 19
AND c.col1= 0
AND c.col2 = 0
limit 100
B表数据量 1036417
A表数据量 3435916
C表数据量 2246
a,c表关联字段上均有索引
b表 col2,col2,col3表上有联合索引 idx_a(col1,col2,col3)
c表 col1,col2上均无索引
2、解决问题
分析上述查询执行计划

可以看到两个问题。
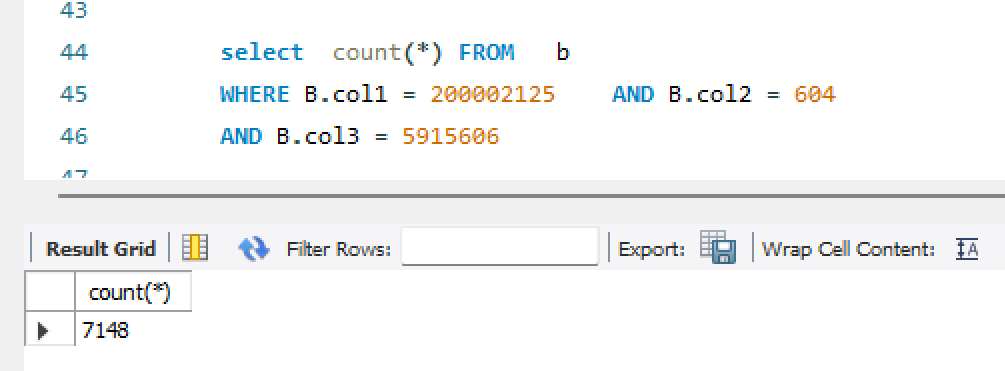
1、我B表上明确col2,col2,col3 有联合索引。且符索引条件的只有7148行,由于变成了被驱动表,这个很好的过滤性就没有使用了。
2、由于mysql改变了我的驱动顺序。被驱动表A与C的关联关系很差。 是1:1543
强制指定关联顺序
修改后的语句
explain
SELECT /*+NO_PARALLEL() JOIN_PREFIX(b,a) */
A.gid
FROM B
inner join A ON A.profileid = B.profileid AND A.billid = B.billid
inner join c ON A.gid = c.GID
WHERE B.COL1= 200002125
AND B.COL2= 604
AND B.COL3= 5915606
AND B.COL4!= 19
AND c.COL1= 0
AND c.COL2= 0
limit 100
强制改了关联顺序后 执行时间只需要0.047S
改了关联顺序的执行计划

3、分析原因
如此大的性能差距,且关联的表也不多,为什么mysql也会选错驱动表呢?
我们来分析 B表与C表在这个语句中应用where条件后MySQL评估的最终行数
先看B表
explain
select * FROM b
WHERE B.col1 = 200002125 AND B.col2 = 604
AND B.col3 = 5915606

由于B表在col2,col2,col3 有联合索引 评估行数为 11732 实际行数我在上面提到过有7148行。filtered为100% 这里代表应用索引直接在存储层就过滤了剩下 11732行。不需要再在server层另外过滤了。
再看C表的评估行数
explain
select count(*) from bas_goods c where c.col1= 0 and c.col2= 0

可以看到MySQL,存储层走的是全表,得到所有记录2246,认为col1与col2过滤性将达到1%,filtered为1%, 在server层将额外过滤。最终C表的结果只是 2246*1/100 只有22行
所以选用了c表做驱动表
但实际上不是。实际上c.col1= 0 and c.col2= 0 在C表中。没有过滤性。上面语句最后结果为2237行。只有几行排除了在外
扩展一下filtered知识
如果字段没有索引和直方图获取更多信息,mysql将常量等式filtered默认为10% 而C表在这个SQL中有两个常量等。filtered 就变成了10%*10% 变成了1%.
可以简单的做一个验证

上图中看到。一个常量等式 filtered = 10%

上图中看到。两个常量等式 filtered = 1%
贴一个八怪大神文章中MySQ几种情况的默认的filtered值
/// Filtering effect for equalities: col1 = col2
#define COND_FILTER_EQUALITY 0.1f
/// Filtering effect for inequalities: col1 > col2
#define COND_FILTER_INEQUALITY 0.3333f
/// Filtering effect for between: col1 BETWEEN a AND b
#define COND_FILTER_BETWEEN 0.1111f
要了解更多的filtered知识 看这篇 八怪大神写的文章
在8.0版本。想解决此问题。可以通过创建直方图的方式,来让mysql获取更准确的统计信息,就可以不选错驱动表了。
