




前言
在关系型数据库中,一般都会提供执行计划来帮助开发者们内部查询方式以及查询行数等,在 MySQL
中通过 Explain
命令,在 PgSQL
中同样也是使用 Explain
来查看执行计划。只是这两者不同的是,返回的数据格式不同。
对 MySQL 执行计划有兴趣的可以看些这篇文章,这篇文章有对 MySQL 执行计划返回结果的每个字段有详细的介绍,并且都有一个示例。
PostgreSQL
文章中统称PgSQL
。
简单示例
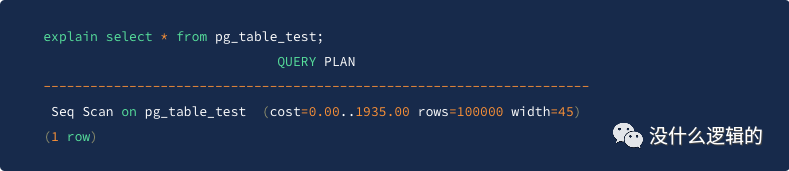
从上述代码块中可以看出,在 PgSQL
中查看执行计划与 MySQL
查看执行计划相同,同样在 SQL
命令前使用 Explain
即可。
输出结果解释
从上面的简单示例中的运行结果中看可以分为两个部分:
•Seq Scan on pg_table_test
这段又可以分两个部分,即:Seq Scan
表示全表扫描(顺序扫描),如果数据量较大的话,那么这种查询方式为最慢的,那就需要考虑优化表结构或者优化查询 SQL
了,还有 pg_table_test
表示查询的表。•cost=0.00..1935.00 rows=100000 width=45
表示查询消耗的成本以及返回行数
•cost
由 .. 分割成两段即 0.00 和 1935.00,第一个数字表示启动成本,也就是说返回第一行需要多少 cost 值;第二个数字表示返回所有数据的成本。•rows
表示返回行数,示例中结果 rows=100000
则表示会返回 100000 行。•width
表示每行平均宽度,示例中每行平均宽度为 45 字节。
PgSQL 中 Explain 命令的语法

其中 option
可选项有很多,例如:ANALYZE
、VERBOSE
等,通过这些参数控制返回实际执行计划或者附加信息等等。
ANALYZE
ANALYZE
选项可以查看实际执行 SQL
来获得 SQL
命令的实际执行计划,因为被真正执行过,所以可以看到执行计划每一步耗费了多长时间,以及它实际返回的行数。
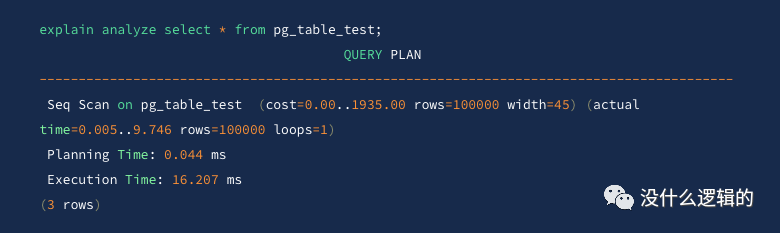
在返回结果中比基础结果新增了 (actual time=0.005..9.746 rows=100000 loops=1)
•time
则表示花费的时间,与 cost
相同,同样使用 .. 将查询第一行与查询所有数据所花费的时间,在示例中,查询第一行所花费的时间为 0.005,查询所有数据花费 9.746 单位为 ms;•row
返回行数;•loops
表示索引扫描被执行过几次,在示例中 loops=1
则表示索引扫描只执行了 1 次;
通过 ANALYZE
选项可以得到实际执行计划所真正花费的时间,从而可以预估出真正花费的成本。
VERBOSE
VERBOSE
参数为 true
时则显示计划的附加信息,计划输出的各个列。
COSTS
COSTS
参数为 true
时则显示执行的启动成本和总成本,以及返回查询结果所返回的行数以及每行的宽度。
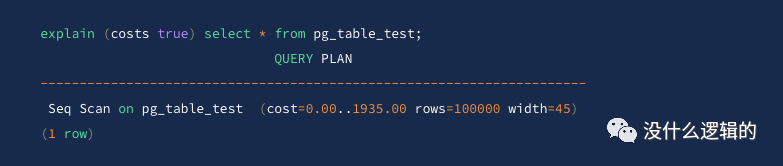
可以看出,即使不加如 costs
参数,也会输出成本等信息,因为 costs
的参数默认值就是 true
大家可以看一下执行计划中使用
*
以及指定了查询列的width
参数,是不是有些许不同,若指定了查询列的width
比*
要小一些,这个测试的表还仅仅只有三列的情况,可以想一下若有很多列,那差距是不是会很大,所以强烈建议,大家在查询时带上需要查询的列。
BUFFERS
BUFFERS
参数为 true
时则显示缓冲区使用的信息,其中包括共享块读和写的块数、本地块读和写的块数,以及临时块读和写的块数。共享块、本地块和临时块分别包含表和索引、临时表和临时索引,以及在排序和物化计划中使用磁盘块。
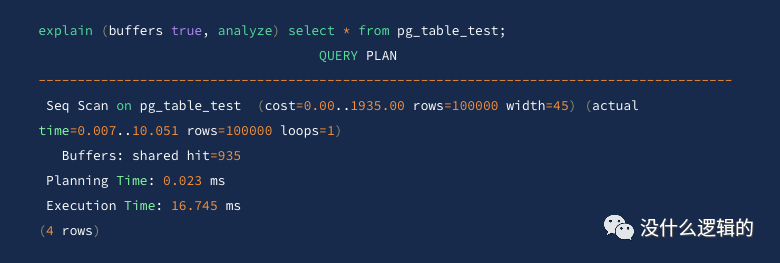
该选项必须与 VERBOSE
一起使用,否则会抛出 ERROR: EXPLAIN option BUFFERS requires ANALYZE
错误。
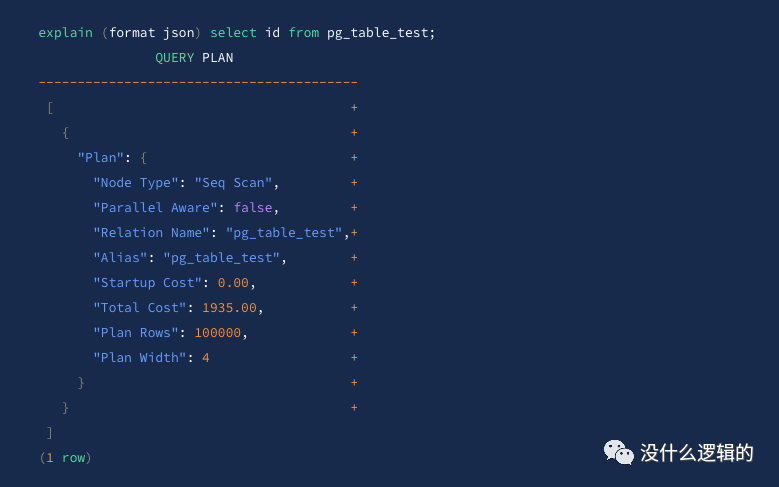
FORMAT
FORMAT
选项控制返回结果的格式,其中格式有Text
、XML
、JSON
和 YAML
,默认值为 Text
。
非查询语句执行 Explain
并非只有 select
关键词才能使用执行计划,其实 create table
、insert into
、delete
等关键词同样可以使用。但是 SQL 不会真正的执行,若加入了 analyze
参数,则 SQL
会被真正的执行。

执行计划中的数据扫描几种方式
通过执行计划我们可以知道本次执行的 SQL
数据扫描的方式,例如全表扫描,我们可以通过这个关键信息来调整我们查询方式或者调整表结构,来达到调优的效果。
全表扫描
全表扫描在 PgSQL
中也叫顺序扫描 Seq Scan
,全表扫描就是把表中所有数据块从头到尾全部读一遍,然后找到符合条件的数据块,若数据量较大的情况下,那么这种查询方式为最慢的,若数据表中只有少量的数据,那么效率可能比其他查询方式快。
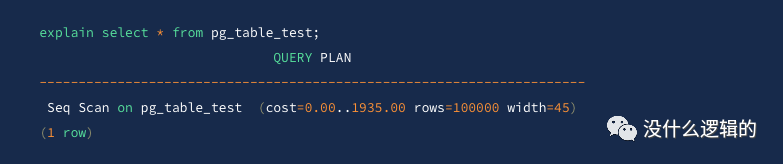
其中 Seq Scan
则表示全表扫描。
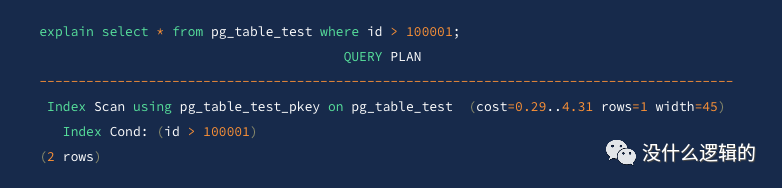
索引扫描
一般为了加快查询速度,我们都会在某一列上建立索引,索引扫描就是在索引中找出需要的数据行的物理位置,然后再到表的数据块把相应的数据读出来的过程,其中用 Index Scan
表示。
位图扫描
位图扫描也是走索引的方式,方法是扫描索引,把满足条件的行或块在内存中建一个位图,扫描完索引后,再根据位图到表的数据文件中把相应的数据读出来。如果走了两个索引,可以把两个索引形成的位图通过 AND
或 OR
计算合并成一个,再到表的数据文件中把数据读出来。
当执行计划的结果行数很多时,会走这种扫描,如非等值查询、IN
子句或有多个条件都可以走不同的索引时。
其中位图扫描使用 Bitmap Heap Scan
表示。
条件过滤
条件过滤一般在 where
子句中加上过滤条件,当扫描行数据行时会找出满足过滤条件的行。条件过滤使用 filter
表示。
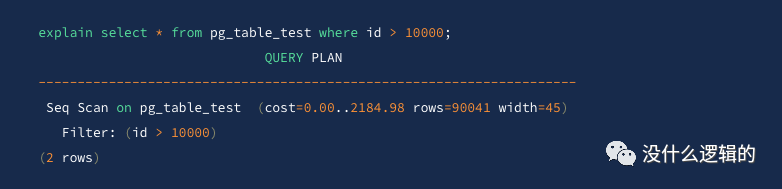
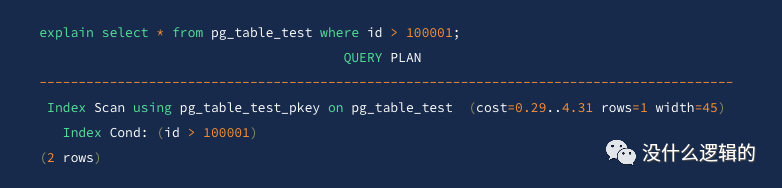
如果条件的列上有索引,可能会走索引而不走过滤,例如:
执行计划相关的配置项
不同的参数项会影响查询优化器选择不同的执行计划,以及查询规划的算法等。
这里只列举参数的意义,不具体列举所有参数,关于这些参数感兴趣的可以自行在文档中查看。
ENABLE_*
参数
在 PgSQL 中有一些以 ENABLE_*
开头的参数,这些参数提供了影响查询优化器选择不同执行计划的方法。有时,如果优化器为特定的查询选择的执行计划并不是最优的,可以设置这些参数强制优化器选择一个更好的执行计划来临时解决问题。
COST
基准值参数
执行计划在选择最优路径时,不同路径的 cost
值只有相对意义。
基因查询优化的参数
GEQO
是一个使用探索式搜索来执行查询规划的算法,它可以缩短负载查询的规划时间。GEQO
的检索是随机的,因此它生存的执行计划会有不确定性。
其他
还有其他配置项,同样,若感兴趣可以自行在官方文档中查看。
总结
在 SQL
性能调优时,通过执行计划进行查看数据库是如何执行我们的 SQL
是非常重要的,所以需要了解返回字段的意义,个人认为 PgSQL
返回的信息不如 MySQL
返回的信息友好,但是 PgSQL
返回的信息已经足够我们使用了。
参考
《PostgreSQL 修炼之道:从小工到专家》
