





Hive Thrift Protocol:兼容HiveServer2语法,提供JDBC方式提交SQL的能力。RESTful APIs:提供管理engines、sessions、operations功能和REST方式提交SQL的能力。
源码编译
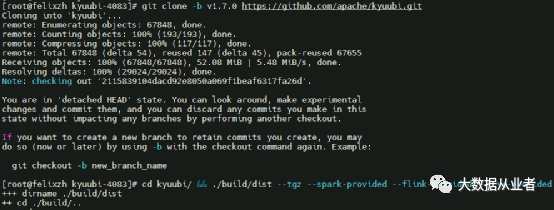
git clone -b v1.7.0 https://github.com/apache/kyuubi.gitcd kyuubi && ./build/dist --tgz --spark-provided --flink-provided --hive-provided
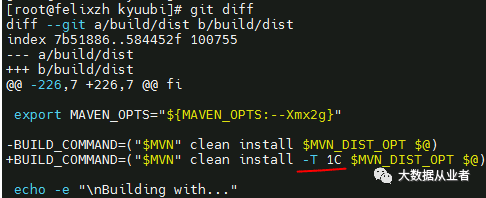

build/mvn clean package -pl kyuubi-common -DskipTests
mvn clean install -pl '!dev/kyuubi-codecov,!kyuubi-assembly' -DskipTests
Kyuubi1.7整合Flink1.16
./bin/yarn-session.sh –d

kyuubi-env.sh、kyuubi-defaults.conf
export HADOOP_CONF_DIR=/etc/hadoop/confexport FLINK_HOME=/home/myHadoopCluster/flink-1.16.0export FLINK_HADOOP_CLASSPATH=/usr/hdp/3.1.5.0-152/hadoop-hdfs/*:/usr/hdp/3.1.5.0-152/hadoop-hdfs/lib/*:/usr/hdp/3.1.5.0-152/hadoop-yarn/*:/usr/hdp/3.1.5.0-152/hadoop-yarn/lib/*:/usr/hdp/3.1.5.0-152/hadoop/*:/usr/hdp/3.1.5.0-152/hadoop-mapreduce/*
kyuubi.ha.zookeeper.quorum felixzh:2181kyuubi.ha.zookeeper.namespace kyuubikyuubi.engine.type FLINK_SQLflink.execution.target yarn-sessionkyuubi.session.engine.flink.max.rows 5
./kyuubi start
./beeline -u 'jdbc:hive2://felixzh:2181/default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi;#flink.yarn.application.id=application_1679471682027_0006'
SELECTname,COUNT(*) AS cntFROM(VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name)GROUP BY name;
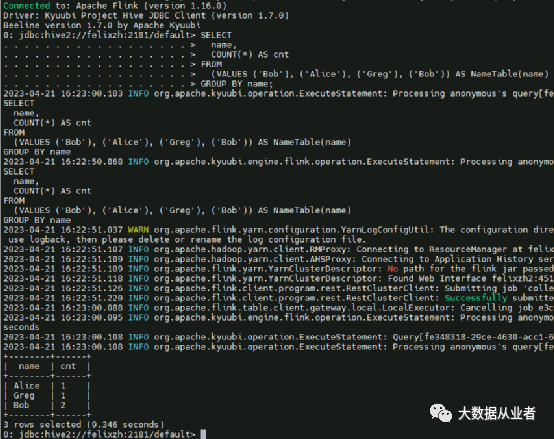
源码改造之select
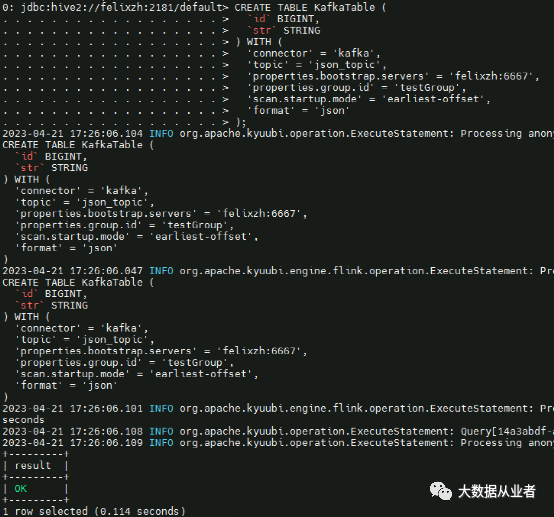
CREATE TABLE KafkaTable (`id` BIGINT,`str` STRING) WITH ('connector' = 'kafka','topic' = 'json_topic','properties.bootstrap.servers' = 'felixzh:6667','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','format' = 'json');

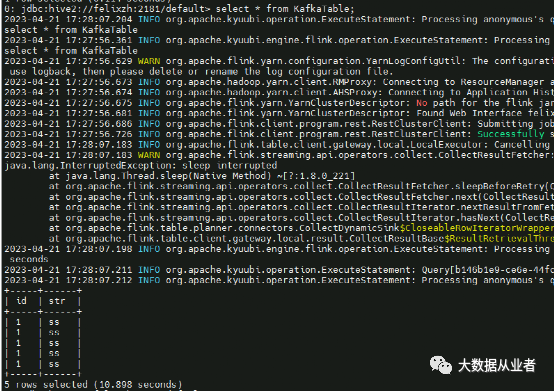
select * from KafkaTable;
https://github.com/apache/kyuubi/issues/4083
https://github.com/apache/kyuubi/pull/4701
mvn test -Dsuites=org.apache.kyuubi.engine.flink.operation.FlinkOperationSuite
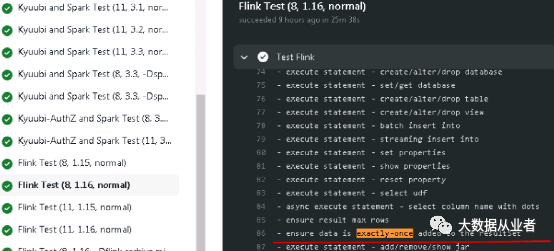
源码改造之insert
insert into KafkaTable values(2, 'ss');
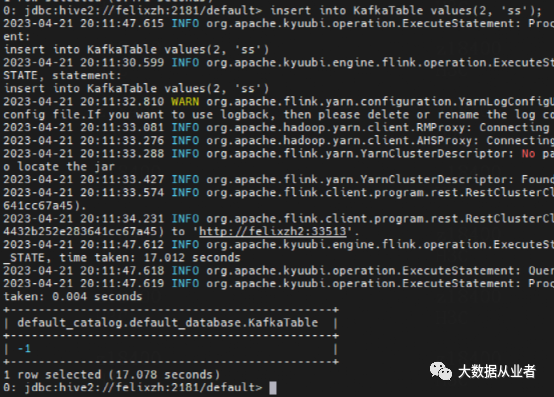


https://github.com/apache/kyuubi/issues/4446
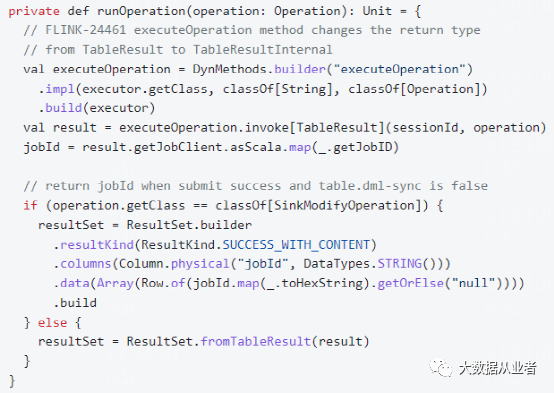
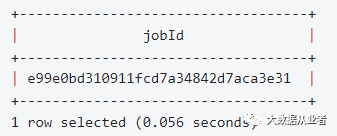
源码改造之日志
org.apache.hadoop.security.ShellBasedUnixGroupsMapping$PartialGroupNameException: The user name 'anonymous' is not found. id: anonymous: no such userid: anonymous: no such user
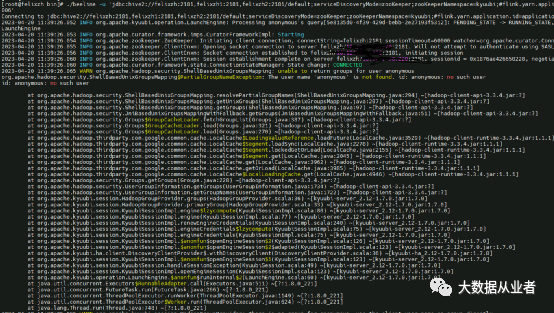
https://github.com/felixzh2020/kyuubi/commit/5f02d2cbc3d8792486c9e8eace2b3696b536d5cf
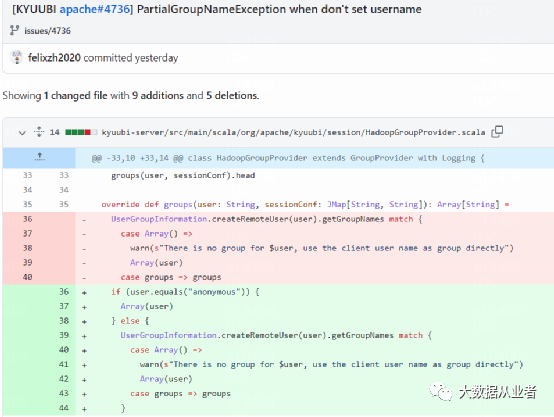
总结
文章转载自大数据从业者,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
