




项目背景
南拳王小亨与北腿王小利的矛盾斗争表面上来看原因是门派有别,功夫有分,实际上是工作面对立,导致矛盾冲突深厚,不可协调!小亨是应用开发部的老大,带领一个团队负责前端界面和后端业务应用开发,小利则是平台维护部的老大,带领一个团队负责公司所有系统包括数据库、中间件、操作系统及相关的容器、虚拟机正常运行及资源调度布署。小亨需要小利提供资源支持,小利需要小亨展现业务效果,按理他俩应该是兄弟。两个闹得不和源于历史上发生一次重大事件,测试环境系统尚好,但是正式上了生产环境 系统上线慢得不行,领导展开事故调查,追踪到直接致命的原因一个老旧驱动JAR包,而这个驱动JAR包说不清楚是由谁管理负责,因为当时要背责任事故,两人就开始拳打脚踢起来。
从那次事件开始,后面又发生数据库中间件事件,为了高性能,小利引进了mycat实现读写分离和流量导向,小亨一看对我的业务逻辑有大量的侵入,我需要重构,我之前的活不仅白干了,我还要干一大堆活 ,两人又是一场大战。
问题分析
深究两人的矛盾,其实就是客户端与服务端的矛盾,社会类似的事非常多,举个快递行业的发展。客户端是取件人,服务端是快递店,最初快递量不多的时候,服务端支持送货上门,电话联系后亲手递给取件人,计算机术语叫同步。
量大的时候, 我们通过异步的方式,服务端把快递放到保安处, 后来为了增强安全性性,服务端建了快递柜子上,并建设了相关的管理系统,给取件人一个密码去哪里拿快递。这可能对取件人体 验不舒服,所以体贴的服务端都会把柜子离取件人近一些。这样快递量大了,客户端的服务体验质量也没有下降,服务端也没有增加太多的人力成本。
如果遇上双11,快递量太多,柜子早已经塞满了,我们可以理解一级缓存已经满了。取件人必须要到驿店取件,除了驿站要离客户近一点,最重要的是把快速货物拿给客户。过去,双11的时候,服务端会加派人手,类比多线程加分布式,而且三更半夜把物品分类分级排列好,提高服务效率。为了提高效率,不再是服务端拿东西给客户端,而是客户端自己去拿东西。性能效率取决于客户端,首先客户端会收到信息提醒, 上面有快递的详细位置【货架位置、层数、尾数】,取件人拿到物品后,拿到出库机扫描一下,就可以进行出库。为了整个链条清晰可见,服务端需要加载摄像机、监控头、人脸识别,保证不会发生误拿、错拿的事。
前车可鉴,快递系统的升级改造必须服务端做改造,客户端做相应的配合。对客户端来说,让我改造习惯和方式,那是入侵,服务端必须重视客户端的情绪,同时提供一系列措施让安抚客户。产品技术布道也是同样的道理。
既要安全也有性能,必须要实现全链路监控跟踪,应用程序和数据库交互可以粗略分为以下流程。
- 用户发起请求, 数据库客户端发起请求到指定的数据库集群。
- 目标数据库响应 指定的数据库集群指定一个节点响应用户的请求。
- 两者建立会话, 数据库集群其中一个节点与客户端产生会话。
- 对象请求解析, 数据库将接收的请求进行 语法检查,对象解析、转换对应的关系代数结构、并进行计划任务优化。
- 调度并且执行, 寻找最合适的副本 ,根据优先级进行,是内存、缓存、数据快照、存储等等。
- 监测任务状态, 观测数据库的执行中状态。
- 返回数据结果, 数据库服务端返回结果给数据库客户端
从细节方面来看,客户端可以是JDBC、ODBC、C API的方式,而且下面还有细分,同样是JDBC,你使用mysql5.0.4.jar 与mysql8.0.4.jar两个完全不同的效果。目标数据库响应,有些数据库是中心化架构,而OB4.1则是去中化、点对点的架构,OB由obproxy模块担任对外服务的接入管理,正式建立会话连接后,用户请求会经过常规的检查,假如有历史有同样的请求,直接去缓存里找。如果没有,就要经历流程4和流程5。
流程4和流程5是数据库的核心能力,流程4好比是大脑,流程5好比是手脚,用户请求将会映射成什么样的数据对象,对象之间的路径是什么样的?对象执行花了多长时间?大脑会根据规则引擎和消耗成本转换成一个最佳的执行计划,可能使用MPP多机执行的方式,可能是索引导向到指定分区,可能是全盘扫描的方式 ,可能先广播后分发的方式。流程5提供数据计算能力和数据存储能力,为了计算贴近存储,可以采用MVCC,可以采用深度的列式存储,可以采用先行后列的存储方式,可以优先内存、缓存、数据快照的方式 。客户端到服务端的全链路监控管理,我们知道的细节越多越好。
应用实践
第一次安装OB4.1在Ubuntu 20.04.6,非常担心安装发现兼容问题,后面发现是多余的。下载介质oceanbase-all-in-one-4.1.0.0-100120230323143519.el7.x86_64.tar.gz,解压,第一步运行./bin/install.sh ,第二步运行obd demo就可以自动完成OB4.1单机的安装。
环境配置
| 操作系统 | Ubuntu 20.04.6 LTS |
|---|---|
| CPU | Intel® Core™ i7-4710HQ CPU @ 2.50GHz 8核 |
| 内存 | 12G |
| 硬盘 | 320G 5400转 |
| 软件版本 | OceanBase4.1 |
| 集群规模 | 单个 |
| 目标 | 实践应用OceanBase的全链路跟踪 |
测试数据
CREATE TABLE EMP
(EMPNO INT(4) NOT NULL,
ENAME VARCHAR(10),
JOB VARCHAR(9),
MGR INT(4),
HIREDATE DATE,
SAL DECIMAL(7, 2),
COMM DECIMAL(7, 2),
DEPTNO INT(2)
);
测试用例
启用链路跟踪很简单,只需要把会话变量变成ON,如下
obclient [fish]> set ob_enable_show_trace=ON;
再运行SQL,SQL执行后会保存数据在/root/oceanbase-ce/log/trace.log ,跟踪日志的数据都是从trace.log里面出的。
最后运行== show trace ==,注意,show trace显示上一次会话SQL追踪执行日志记录。
下面准备了3个测试用例
- 命令行层面,激活跟踪,执行SQL,收集链路信息,依次输入错误的SQL,输入不存在的表,输入关联表。
- 代码层面链路跟踪,基于代码层,使用mysql5.1.46版本的JDBC驱动,执行SQL后,前端检测是否能收集跟踪信息,知道SQL在服务端运行的动态。
- 两个不同SQL,同是相同结果,查看他们链路执行过程,通过一个DEMO,查询计划和链路跟踪去排查两个SQL的执行过程。
CLI层面的链路跟踪
obclient [fish]> set ob_enable_show_trace='ON';
Query OK, 0 rows affected (0.001 sec)
obclient [fish]> sellect * from t_order;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual
that corresponds to your OceanBase version for the right syntax to use near
'sellect * from t_order' at line 1
obclient [fish]> show trace;
+-------------------------------+----------------------------+------------+
| Operation | StartTime | ElapseTime |
+-------------------------------+----------------------------+------------+
| com_query_process | 2023-04-24 23:37:04.767402 | 0.262 ms |
| └── mpquery_single_stmt | 2023-04-24 23:37:04.767407 | 0.247 ms |
| └── sql_compile | 2023-04-24 23:37:04.767417 | 0.142 ms |
| ├── pc_get_plan | 2023-04-24 23:37:04.767418 | 0.004 ms |
| └── hard_parse | 2023-04-24 23:37:04.767460 | 0.084 ms |
| └── parse | 2023-04-24 23:37:04.767461 | 0.066 ms |
+-------------------------------+----------------------------+------------+
6 rows in set (0.004 sec)
obclient [fish]> select * from dkk;
ERROR 1146 (42S02): Table 'fish.dkk' doesn't exist
obclient [fish]> show trace;
+-------------------------------+----------------------------+------------+
| Operation | StartTime | ElapseTime |
+-------------------------------+----------------------------+------------+
| com_query_process | 2023-04-24 23:34:07.266692 | 0.308 ms |
| └── mpquery_single_stmt | 2023-04-24 23:34:07.266695 | 0.295 ms |
| └── sql_compile | 2023-04-24 23:34:07.266702 | 0.202 ms |
| ├── pc_get_plan | 2023-04-24 23:34:07.266703 | 0.002 ms |
| └── hard_parse | 2023-04-24 23:34:07.266731 | 0.161 ms |
| ├── parse | 2023-04-24 23:34:07.266732 | 0.030 ms |
| └── resolve | 2023-04-24 23:34:07.266777 | 0.099 ms |
+-------------------------------+----------------------------+------------+
7 rows in set (0.004 sec)
obclient [fish]> SELECT a.ord_number, a.ord_status, a.order_time,
b.product_number, b.product_name FROM tb_order a inner join
tb_product b on(a.product_number = b.product_number) limit 10;
obclient [fish]>show trace; 如下
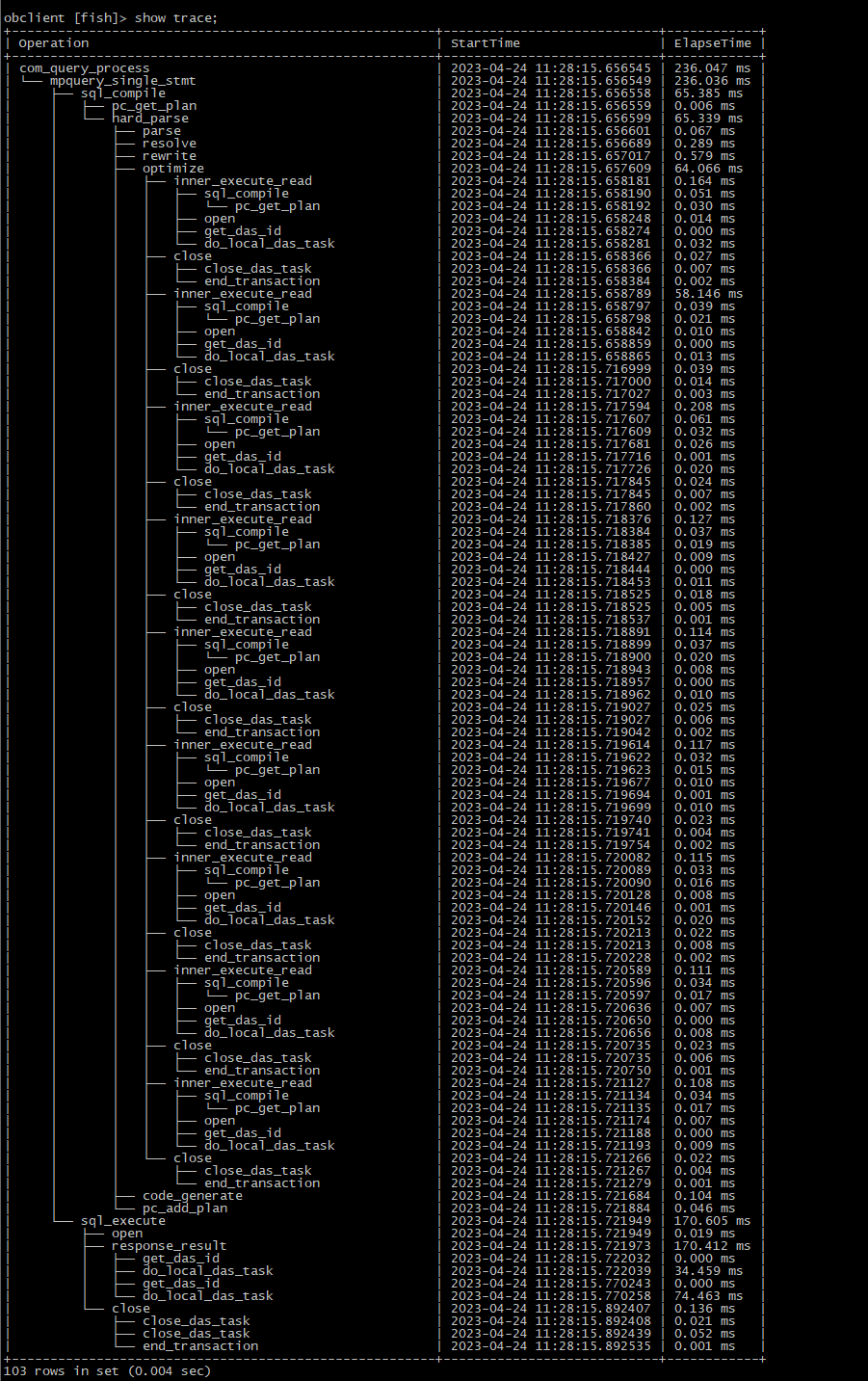
CLI层面小结
ob的sql_compile和对应前文的流程4对象请求解析, pc_get_plan是查看缓存,parse检测SQL语法有没有满足OB标准规范、resolve将会去检阅请求中的数据库对象,例如表是否存在。rewrite则是把SQL转换为内部的树结构,就绪后优化器就可以正工作、optimize优化器对当前的所有数据库对象进行排列组合,选择一个最佳的优化路径执行计划,code generate把计划编译成机器文件,准备执行。
sql_execute对应前文的流程5调度并执行,按照产品路径的发展,以后演变会有分布式执行还是本地执行,计算和存储用了哪几个节点。
code层面的链路跟踪
从IDEA里面提交代码,目标是jdbc:mysql://192.168.10.8:2883/fish,进行两表查询。
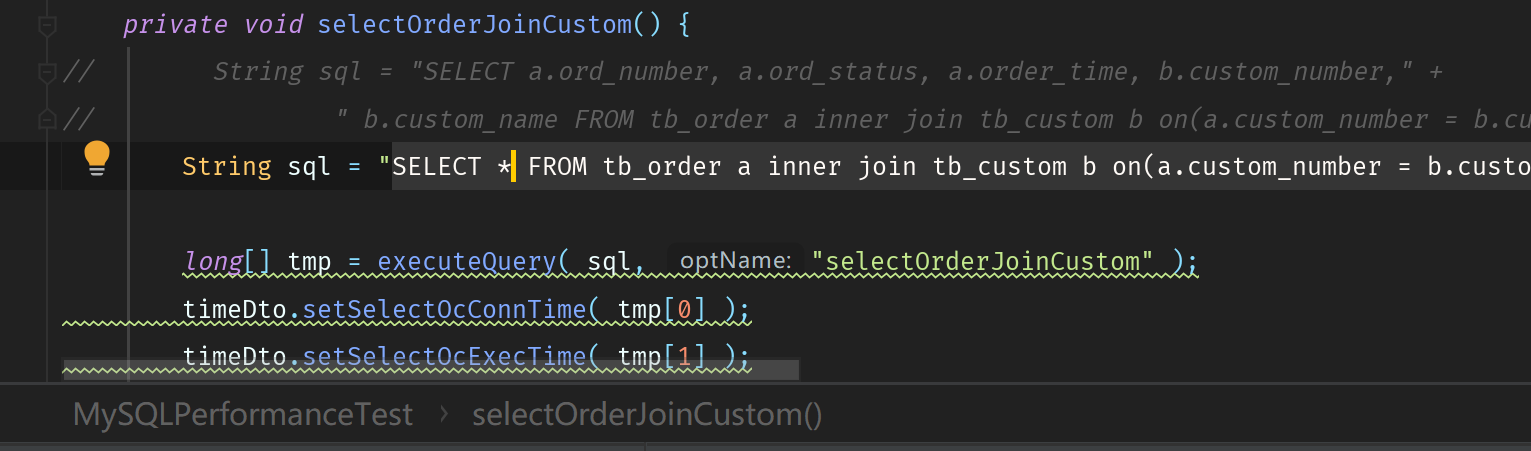
根据与OB工程师交流,必须要在代码层传递show trace,所以代码层面上必须要有String sql = set session ob_enable_show_trace=on; 代码如下
try (Connection connection = DriverManager.getConnection( JDBC_URL, JDBC_USER, JDBC_PWD );
PreparedStatement ps = connection.prepareStatement( "set session ob_enable_show_trace=on" )
) {
int ResultUpdate = ps.executeUpdate();
ps.executeQuery(sql);
ResultSet rs = ps.executeQuery("show trace");
try{
while (rs.next()) {
System.out.print(rs.getString(1));
System.out.print(rs.getString(2));
System.out.println(rs.getString(3));
成功输出以下界面
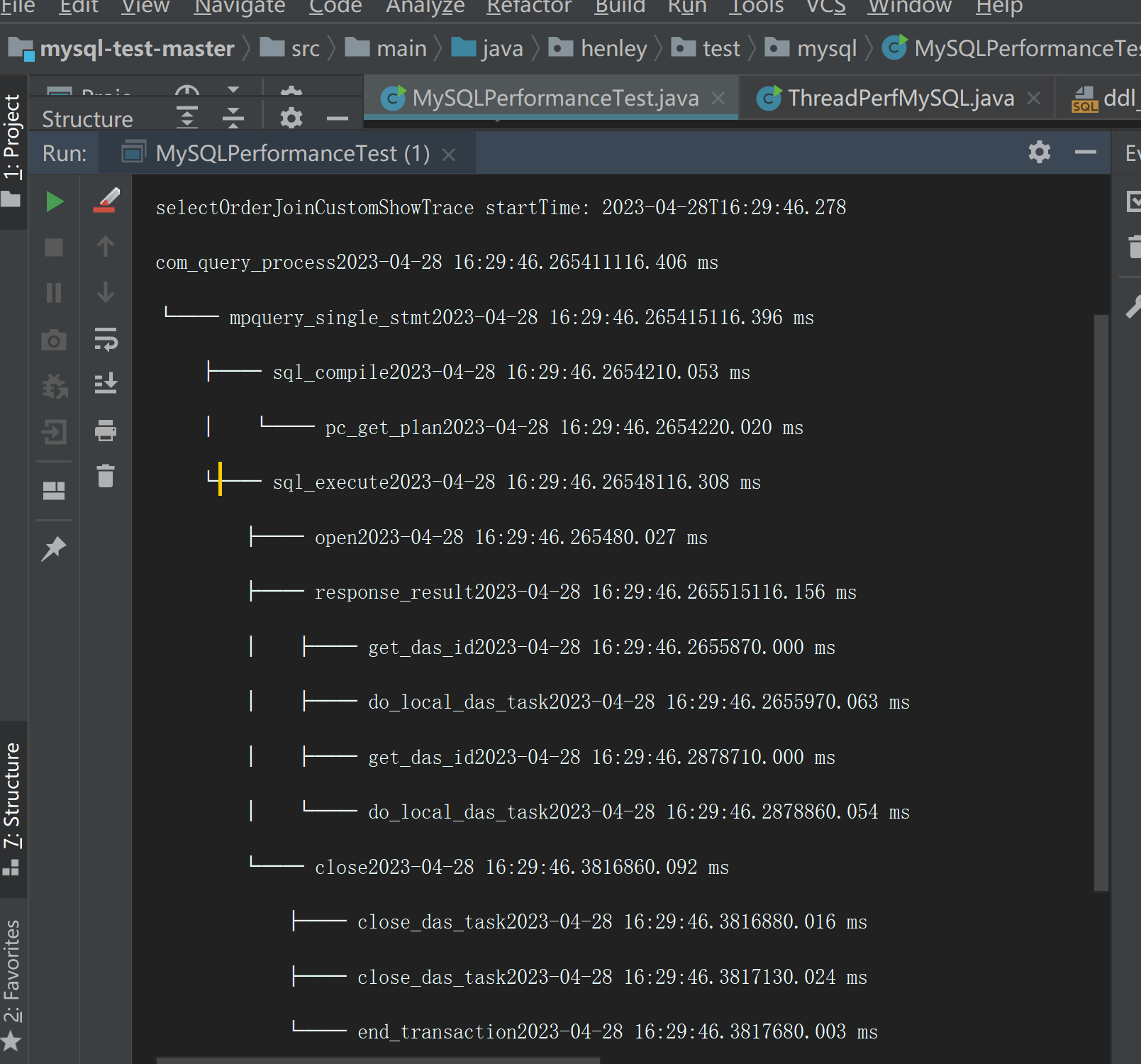
code层面小结
客户端通过JDBC递交的SQL请求,可以在代码层拿到trace log,这样客户端可以知道请求在服务端的运行情况。
不同的SQL链路跟踪
针对EMP表【ORACLE经典表】,SQL1是一个针对单表使用over窗口函数并进行分区的扫描,SQL2是基于单表EMP表派生两表关联查询。
按照正常思维理解,SQL1比SQL2快,结合explain查看相关逻辑执行计划进行SQL全盘查看。
obclient [fish]> explain select count(*) from (
select ename, deptno, sal from (select a.*, max(sal) over(partition by deptno) max_sal from emp a) where sal = max_sal );
+-------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+-------------------------------------------------------------------------------------------------------------------------------------------------------+
| ============================================================ |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------------ |
| |0 |SCALAR GROUP BY | |1 |152943 | |
| |1 | SUBPLAN SCAN |ANONYMOUS_VIEW1|24 |152943 | |
| |2 | WINDOW FUNCTION| |166188 |150108 | |
| |3 | PARTITION SORT| |166188 |31085 | |
| |4 | TABLE SCAN |a |166188 |8309 | |
| ============================================================ |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([T_FUN_COUNT(*)]), filter(nil), rowset=256 |
| group(nil), agg_func([T_FUN_COUNT(*)]) |
| 1 - output(nil), filter([.SAL = .max_sal]), rowset=256 |
| access([.SAL], [.max_sal]) |
| 2 - output([a.SAL], [T_FUN_MAX(a.SAL)]), filter(nil), rowset=256 |
| win_expr(T_FUN_MAX(a.SAL)), partition_by([a.DEPTNO]), order_by(nil), window_type(RANGE), upper(UNBOUNDED PRECEDING), lower(UNBOUNDED FOLLOWING) |
| 3 - output([a.SAL], [a.DEPTNO]), filter(nil), rowset=256 |
| sort_keys([HASH(a.DEPTNO), ASC], [a.DEPTNO, ASC]) |
| 4 - output([a.SAL], [a.DEPTNO]), filter(nil), rowset=256 |
| access([a.SAL], [a.DEPTNO]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([a.__pk_increment]), range(MIN ; MAX)always true |
+-------------------------------------------------------------------------------------------------------------------------------------------------------+
23 rows in set (0.003 sec)
obclient [fish]> select count(*) from (
select ename, deptno, sal from (select a.*, max(sal) over(partition by deptno) max_sal from emp a) where sal = max_sal );
+----------+
| count(*) |
+----------+
| 30216 |
+----------+
1 row in set (4.865 sec)
obclient [fish]> show trace;
+-------------------------------------------+----------------------------+-------------+
| Operation | StartTime | ElapseTime |
+-------------------------------------------+----------------------------+-------------+
| com_query_process | 2023-04-24 11:10:43.391681 | 4864.419 ms |
| └── mpquery_single_stmt | 2023-04-24 11:10:43.391686 | 4864.401 ms |
| ├── sql_compile | 2023-04-24 11:10:43.391696 | 2.333 ms |
| │ ├── pc_get_plan | 2023-04-24 11:10:43.391698 | 0.008 ms |
| │ └── hard_parse | 2023-04-24 11:10:43.391748 | 2.274 ms |
| │ ├── parse | 2023-04-24 11:10:43.391749 | 0.079 ms |
| │ ├── resolve | 2023-04-24 11:10:43.391848 | 0.291 ms |
| │ ├── rewrite | 2023-04-24 11:10:43.392279 | 1.054 ms |
| │ ├── optimize | 2023-04-24 11:10:43.393344 | 0.451 ms |
| │ ├── code_generate | 2023-04-24 11:10:43.393806 | 0.098 ms |
| │ └── pc_add_plan | 2023-04-24 11:10:43.393977 | 0.038 ms |
| └── sql_execute | 2023-04-24 11:10:43.394035 | 4861.638 ms |
| ├── open | 2023-04-24 11:10:43.394036 | 17.532 ms |
| ├── response_result | 2023-04-24 11:10:43.411583 | 4765.348 ms |
| │ ├── get_das_id | 2023-04-24 11:10:43.412222 | 0.000 ms |
| │ └── do_local_das_task | 2023-04-24 11:10:43.412236 | 0.065 ms |
| └── close | 2023-04-24 11:10:48.176946 | 78.652 ms |
| ├── close_das_task | 2023-04-24 11:10:48.176948 | 0.026 ms |
| └── end_transaction | 2023-04-24 11:10:48.255575 | 0.003 ms |
+-------------------------------------------+----------------------------+-------------+
19 rows in set (0.144 sec)
obclient [fish]> explain select count(*) from (
select ename,deptno,sal from emp a where sal = (select max(sal) from emp b where a.deptno = b.deptno) );
+--------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------+
| ================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------- |
| |0 |SCALAR GROUP BY | |1 |49577 | |
| |1 | HASH JOIN | |2304 |49536 | |
| |2 | SUBPLAN SCAN |VIEW1|100 |24811 | |
| |3 | HASH GROUP BY| |100 |24811 | |
| |4 | TABLE SCAN |b |166188 |8309 | |
| |5 | TABLE SCAN |a |166188 |8309 | |
| ================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([T_FUN_COUNT(*)]), filter(nil), rowset=256 |
| group(nil), agg_func([T_FUN_COUNT(*)]) |
| 1 - output(nil), filter(nil), rowset=256 |
| equal_conds([a.SAL = VIEW1.max(sal)], [a.DEPTNO = VIEW1.b.DEPTNO]), other_conds(nil) |
| 2 - output([VIEW1.max(sal)], [VIEW1.b.DEPTNO]), filter(nil), rowset=256 |
| access([VIEW1.max(sal)], [VIEW1.b.DEPTNO]) |
| 3 - output([T_FUN_MAX(b.SAL)], [b.DEPTNO]), filter(nil), rowset=256 |
| group([b.DEPTNO]), agg_func([T_FUN_MAX(b.SAL)]) |
| 4 - output([b.DEPTNO], [b.SAL]), filter(nil), rowset=256 |
| access([b.DEPTNO], [b.SAL]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([b.__pk_increment]), range(MIN ; MAX)always true |
| 5 - output([a.DEPTNO], [a.SAL]), filter(nil), rowset=256 |
| access([a.DEPTNO], [a.SAL]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([a.__pk_increment]), range(MIN ; MAX)always true |
+--------------------------------------------------------------------------------------------+
28 rows in set (0.158 sec)
obclient [fish]> select count(*) from (
select ename,deptno,sal from emp a where sal = (select max(sal) from emp b where a.deptno = b.deptno) );
show trace;+----------+
| count(*) |
+----------+
| 30216 |
+----------+
1 row in set (0.023 sec)
obclient [fish]>
obclient [fish]> show trace;
+-------------------------------------------+----------------------------+------------+
| Operation | StartTime | ElapseTime |
+-------------------------------------------+----------------------------+------------+
| com_query_process | 2023-04-24 11:12:56.004332 | 20.213 ms |
| └── mpquery_single_stmt | 2023-04-24 11:12:56.004335 | 20.203 ms |
| ├── sql_compile | 2023-04-24 11:12:56.004340 | 0.043 ms |
| │ └── pc_get_plan | 2023-04-24 11:12:56.004341 | 0.014 ms |
| └── sql_execute | 2023-04-24 11:12:56.004388 | 20.126 ms |
| ├── open | 2023-04-24 11:12:56.004389 | 0.031 ms |
| ├── response_result | 2023-04-24 11:12:56.004426 | 20.025 ms |
| │ ├── get_das_id | 2023-04-24 11:12:56.004482 | 0.001 ms |
| │ ├── do_local_das_task | 2023-04-24 11:12:56.004490 | 0.029 ms |
| │ ├── get_das_id | 2023-04-24 11:12:56.014238 | 0.000 ms |
| │ └── do_local_das_task | 2023-04-24 11:12:56.014254 | 0.021 ms |
| └── close | 2023-04-24 11:12:56.024464 | 0.042 ms |
| ├── close_das_task | 2023-04-24 11:12:56.024465 | 0.009 ms |
| ├── close_das_task | 2023-04-24 11:12:56.024482 | 0.005 ms |
| └── end_transaction | 2023-04-24 11:12:56.024499 | 0.001 ms |
+-------------------------------------------+----------------------------+------------+
15 rows in set (0.003 sec)
不同的SQL层面小结
结果意外的是,SQL1耗时是4.865 sec,而SQL2耗时是0.023 sec,SQL1比SQL2慢,虽然SQL1的执行计划只有一个TABLE SCAN,但是PARTITION SORT和WINDOW FUNCTION消耗了大量的时间,最重要的运行SQL多次无法被 缓存,总是需要hard parse,时间成本主要在执行上。
而SQL2虽然它的执行计划用了两个TABLE SCAN【全盘扫描】,消耗时间最长的是HASH JOIN,从trace日志上, 多次运算后不需要hard parse,直接从缓存里拿出来就可以使用。
explain结合trace,我们注意emp这个表根本没有做索引,没有做分区,这个可能是SQL1为什么慢的原因。
用户收益
基于事实说话,基于客观的数据说话,基于全链路跟踪的数据大屏,以后测试用例,小亨与小利知道应用堵 在哪里了,两个再不用打架,从此两个人过上没羞没噪的幸福生活。笔者的体检,目前的全链路跟踪 还处于发展阶段,相信以后的功能会更丰富。
后记
全链路跟踪是一个很大的话题,从客户端到服务端,两者之间来回多次,ob的trace只是其中一个环节,它记录的是服务端接收到SQL请求,SQL在服务端怎么拆解,进行下一步的划分。客户端采用什么样的驱动,mysql jdbc?oceanbase jdbc? 这些信息还没有纳入进来管理,所以全链路跟踪的细节还有很大的提升优化空间。
