





MySQL之
到底该查哪个分区?
PART 01
背景介绍
PART 02
什么是分区剪枝?
我们以一个简单的range类型的分区来简单说明什么是分区剪枝:
CREATE TABLE t1 (...)PARTITION BY RANGE (F(a)) (PARTITION P1 VALUES LESS THAN (L1),PARTITION P2 VALUES LESS THAN (L2),...PARTITION Pn VALUES LESS THAN (Ln))
根据以上的分区定义,我们可以得到分区的范围序列:(,L1), [L1, L2), [Ln-1, Ln)
,其中F(*)
是分区表达式,a
是参与分区的列。对于如下的查询:
select * from t1 where(t1.a > 10 AND t1.a <= 20) OR (t1.a > 0 AND t1.a < 5)
在WHERE条件,其分区列a的取值范围的序列为(0, 5) (10, 20]
,我们用S(RC)
来表示这个序列。
分区剪枝就是找到分区范围与F(S(RC))
有交集的分区的集合。根据范围进行剪枝时,分区表达式F(*)
需要是一个单调函数,否则在优化器层无法根据WHERE条件进行剪枝。这里简单的总结一下MySQL分区剪枝的适用范围:
WHERE条件的中的比较谓词为
=, <>, <, <=, >, >=, BETWEEN, IN, IS NULL, IS NOT NULL
,由AND-OR连接。比较谓词中由分区列名与常量进行比较,否则优化器无法确定
S(RC)
的值。分区表达式
F(*)
是一个单调函数或者S(RC)
是一个单点区间(等值查询或者IN(a, b, c)这类的用法)才可以进行分区剪枝,否则在优化器层无法根据WHERE条件进行剪枝。对于hash类型的分区而言,同样S(RC)
是一个单点区间才能进行剪枝。
PART 03
分区剪枝是怎么实现的?
1. 修剪分区后的信息存储在哪?
支持分区剪枝最原始的版本在JOIN::optimize
中调用分区剪枝的代码,其剪枝操作发生在GROUP BY优化(optimize_aggregated_query
)之前,因为在这里面可能会访问查询的表,这样就可以在访问表之前就可以确定哪些分区不需要访问。在WL#4443
中,对这个流程又进行了优化,剪枝操作提前到了Query_block::prepare
中,这是因为希望在lock_tables()
之前就行剪枝,这样只对剪枝后的分区加锁即可。在包含子查询的query中,也可能会再次调用剪枝操作来对子查询进行剪枝。
MySQL使用partition_info
来维护分区表相关的信息,分区剪枝通过一个bitmap来保存需要访问哪些分区来获取搜索结果。分区对应数据位为1则表示需要对该分区进行搜索,否则该分区内的记录不满足查询条件,可以直接跳过。在MySQL中这个bitmap通过两个bitmap对象来存储:
read_partitions: 记录需要访问哪些分区
lock_partitions: 记录需要锁住哪些分区
在ha_partition::open()
函数中对它们进行初始化,如果用户指定查询某些分区,在open_and_lock_tables()
函数中会显式地设置它们的值。
比如select * from t1 partition(p0, p1)
会对p0, p1
分区所在的数据位进行设置。在函数prune_partitions()
也会对它们进行修改,WL#4443
中允许了prune_partitions()
对lock_partitions
进行修改。
通常read_partitions
与lock_partitions
是一样的,但是在以下情景下会有所不同:
UPDATE更新分区表达式中的字段,
lock_partitions
不会在prune_partitions()
后进行修改,其包含所有的分区。因为这可能会导致记录更新到其他分区,会把所有的分区都锁住。read_partitions
为分区剪枝后的分区。REPLACE/INSERT ... VALUES
通常也只会锁住修剪后的分区,但是如果包含自增列且自增列位分区字段,那么lock_partitions
同样也会锁住所有的分区。INSERT ... VALUES ... ON DUPLICATE KEY
这个类似于UPDATE,如果更新分区字段,那么也是lock_partitions
也是所有分区。INSERT SELECT
中,对于select的表read_partitions
与lock_partitions
是一样的,但是对于insert的表,lock_partitions
会锁住所有的分区。LOAD
指令不会进行分区剪枝,因为LOAD
通常是大批量的插入。对一大批量进行分区剪枝带来的收益可能并不明显。因为对于一批插入,每行都需要分区剪枝代价再汇总,这个代价也是很大的。
2. 剪枝流程
分区剪枝主要是利用SEL_TREE
描述的区间范围进行剪枝,剪枝函数find_used_partitions
处理的粒度为SEL_ARG
,一个SEL_TREE
包含一个或多个SEL_ARG
。为方便理解,本章先讲解SEL_ARG
的组织形式以及如何在上面进行剪枝,关于SEL_TREE
的内容放在后面进行讨论。
下面是SEL_ARG
的一个简单示例:
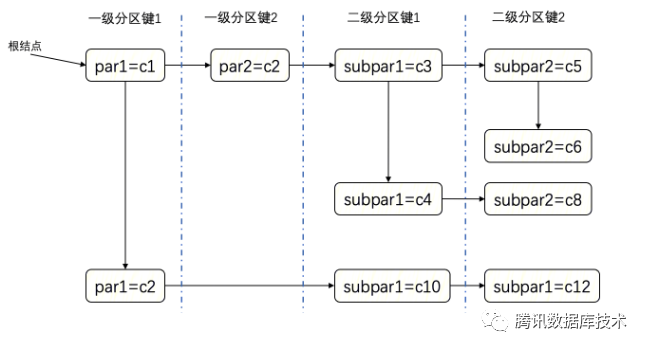
图中par1
、par2
、subpar1
、subpar2
分别表示一级分区和二级分区的分区键。垂直方向的连接表示由OR
条件进行连接,代码中由其用SEL_ARG::left
和SEL_ARG::right
进行表示。水平方向的连接表示由AND
条件进行连接,代码中由SEL_ARG::next_key_part
进行表示。水平方向连接的是不同的分区字段,垂直方向连接的是相同字段的条件。所以图中表示的查询条件为:

图中通过虚线按照分区键将SEL_ARG
切割成了4部分,虚线切割的每个部分中相连的区间组成了一个红黑树。图中可以看作是切割成了7个红黑树:
1) "par1=c1 or par1=c2"2) "par2=c2"3) "subpar1=c3 or subpar1=c4"4) "subpar1=c10"5) "subpar2=c5 or subpar2=c6"6) "subpar2=c8"7) "subpar2=c12"
1) "par1=c1 AND par2=c2 AND subpar1=c3 AND subpart2=c5",2) "par1=c1 AND par2=c2 AND subpar1=c3 AND subpar2=c6",3) "par1=c1 AND par2=c2 AND subpar1=c4 AND subpar2=c8"4) "par1=c2 AND subpar1=c10 AND subpar2=c12"
剪枝时递归调用find_used_partitions
对每个范围进行处理,在遇到最后一个一级分区和二级分区的分区键时,分别对一级分区和二级分区进行剪枝。对于1)剪枝的时的堆栈为如下的形式:

在(**)
处得到一级分区剪枝的条件,在(***)
处得到二级分区剪枝的条件。find_used_partitions
进行搜索时,递归的顺序大致如下:

那么在find_used_partitions
中是如何确定哪些分区符合条件呢?在遍历到最后一个一级分区的的分区键或二级分区的分区键进行剪枝时,剪枝操作根据分区类型和剪枝条件是否为一个等值查询会有所区别:
1) 如果是一个等值查询,则直接根据具体的值定位到具体的分区即可。
2) 如果是一个范围查询,则需要确定哪些分区符合查询的条件,这需要针对不同的分区类型来判断:对于range类型的分区,首先会找到查询条件上下边界所在的分区,因为range类型中分区的范围是递增的,所以在包含在上下边界之内的分区都是需要被搜索的。对于list类型的分区,内部会将所有分区中的值进行排序并存到一个数组中,然后对于查询条件的上下边界定位到数组中的上下边界,根据数组中的值是可以定位到哪些分区需要搜索的。
3. SEL_TREE的组织方式以及剪枝
SEL_TREE
可以简单的理解为由一个或多个SEL_ARG
组成,在剪枝时,会先生成SEL_TREE
,然后遍历SEL_TREE
上的SEL_ARG
进行剪枝,在本章后面介绍SEL_TREE
的三种组织方式。在构造SEL_TREE
之前,需要构造一个虚拟的分区索引(包含一级分区、二级分区的所有字段),构造虚拟分区索引时会将分区的字段信息添加到虚拟索引信息中。如果分区字段为GEOMETRY
或者ENUM
类型的话,将不会对其进行剪枝,因为对这两种类型字段无法进行区间范围的比较。比如一级分区的字段包含GEOMETRY
类型,二级分区的字段不包含GEOMETRY
和ENUM
类型,则一级分区不会进行剪枝,只会对二级分区进行剪枝。
构造完虚拟索引后,调用get_mm_tree
构造SEL_TREE
。在get_mm_tree
中会调用field->optimize_range()
来判断索引能否处理当前的区间范围。对于分区剪枝而言,就是判断能否对当前的范围进行剪枝。MySQ在构造SEL_TREE
时,如果是分区剪枝,那么field->optimize_range()
都是为true,即在这个流程中先默认可以对范围进行剪枝。对于能否剪枝的真实判断放到find_used_partitions
中。这样做的原因是在这里并不能100%确定一个范围是否与另一个范围组成一个单点区间。比如某个分区表达式下只能对单点区间进行剪枝,对于t.key >= 10 AND t.key <= 10
这个表达式是一个单点区间,但是判断t.key >= 10
时可能会错误的认为无法进行剪枝。
在无法对区间范围只创建一个SEL_ARG
的时候,get_mm_tree
对单个索引也会创建index_merge tree
。比如对于keypart1=c1 OR keypart2=c2
,会创建一个包含两个子树(SEL_ARG
)的index_merge tree
。这个特性对于分区剪枝而言,意味着可以对更广的范围区间进行剪枝。根据是否进行index_merge
以及index_merge tree
的数量,SEL_TREE
可以分为三种情况:
SEL_TREE
只有一个树,通过SEL_ARG* graph
来描述一个区间范围的序列S(RC)
,比如part_field1 = c1 OR part_field1 = c2
。SEL_TREE
是一个index merge tree
,由多个SEL_ARG
用OR条件连接。可以描述成tree1 OR tree2 OR ... treeN
的方式。每个tree的组织方式类似于第一种情况,比如part_field1 = c1 OR subpart_field1 = c2
。SEL_TREE
是多个index merge tree
,可以描述成merge_tree1 AND merge_tree2 ... AND merge_treeN
,每个merge tree类似于上面的第二中情况,比如(part_field1 < c1 OR subpart_field1 = c2) AND (part_field1 > c3 OR subpart_field1 = c4)
。
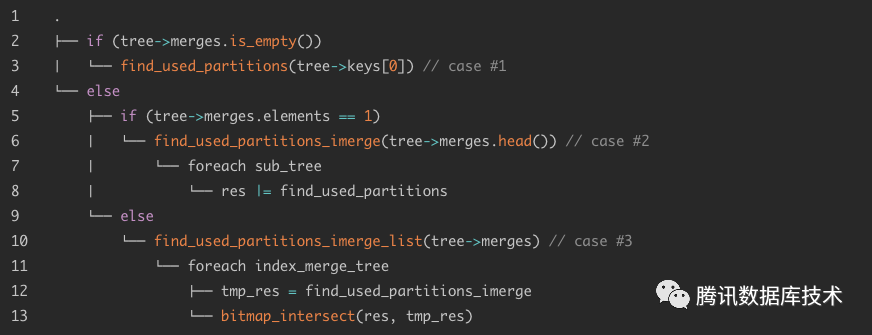
分区剪枝的主要函数为find_used_partitions
,其对SEL_ARG
描述的区间范围序列进行分析并剪枝。上面描述的的第一种情况,直接调用find_used_partitions
并传入传入SEL_ARG
,对于第二种情况,需要调用find_used_partitions_imerge
对每个子树调用find_used_partitions
并对剪枝的结果取并集,对于第三种情况,会调用find_used_partitions_imerge_list
对每个index merge tree
调用find_used_partitions_imerge
并对剪枝的结果取交集。其代码逻辑如下:
4. 一个例子
我们以range类型的分区为例来解释分区剪枝的流程,创建如下表:
CREATE TABLE test (a INT, b INT, C INT)PARTITION BY RANGE COLUMNS(a, b)SUBPARTITION BY HASH( c )SUBPARTITIONS 5 (PARTITION p0 VALUES LESS THAN (0,0),PARTITION p1 VALUES LESS THAN (10,10),PARTITION p2 VALUES LESS THAN (20,20),PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE));
EXPLAIN SELECT * FROM test WHERE (a > 0 and a < 10 AND b = 0 and (c = 2 OR c = 1)) OR (b = 1 and (a > 20 or b = 12) and c = 2);
我们可以得到如下的SEL_ARG
:
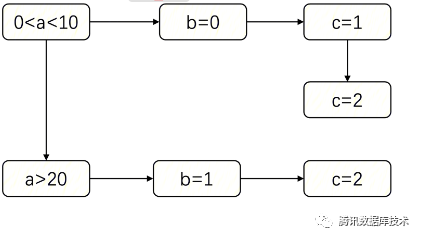
那么剪枝的步骤如下:
从
0 < a < 10
开始进入剪枝函数find_used_partitions
,因为SEL_ARG::left
为空,所以先在水平方向进行遍历。因为字段a是一级分区的最后一个字段,所以a < 10
可以对一级分区进行剪枝。剪枝时定位到10为p1的上界,因为a的范围不包含10,所以a范围的上界所在的分区为p1,a的下界为0,为分区p0的上界,但a的取值大于0,所以a的范围的下届所在的分区为p1。所以在这一步剪枝得到的结果为p1。然后在水平方向继续往后,得到等值条件
b = 0
,这不是二级分区的最后一个字段,会继续向下寻找,找到条件c = 1
。此时已经到二级分区的最后一个字段了,b+c
的值1,计算所在的二级分区为sp1。所以此条路径剪枝的结果为p1sp1。此时
c = 2
这个条件的find_used_partitions
出栈,然后根据SEL_ARG::right
指针进入条件c = 2
,同理得到剪枝的结果为p1sp2。跟上面的流程一样,在
a > 20
时,一级分区的剪枝结果为p3。在b = 1 and c = 2
时,二级分区的剪枝结果为sp3,所以此条路径的剪枝结果为p3sp3。汇总上面的剪枝结果,最终保留的分区为:p1sp1,p1sp2,p3sp3。

PART 04
总结
分区函数不是单调递增函数时,在进行范围查询时,是无法进行剪枝的。 比较谓词中分区字段与非常量进行比较时,是无法进行剪枝的。 WHERE条件中只支持 =, <>, <, <=, >, >=, BETWEEN, IN, IS NULL, IS NOT NULL
等比较谓词,由AND-OR连接。分区字段为 GEOMETRY
或者ENUM
类型时是不支持分区剪枝的,因为这两种类型在mysql内部并不好处理其范围比较。如果分区字段上有 BEFORE INSERT/UPDATE
类型的触发器,则也不会进行分区剪枝,因为触发器中可能会修改分区字段的值。
-END-
