





1. 环境介绍
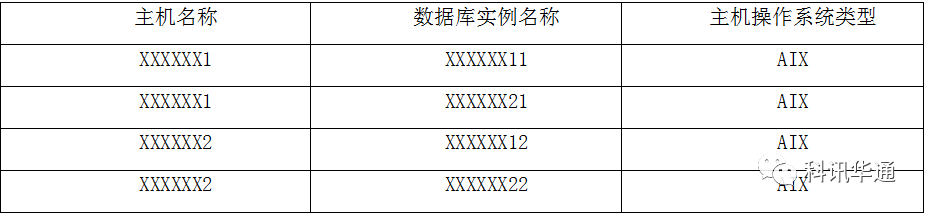
现场故障系统为某电信运营商核心数据库,数据库分为两套RAC数据库。两套RAC数据库分布在两台AIX6.1小机上。其中小机1节点运行XXXXXX11和XXXXXX21实例,小机2节点运行XXXXXX12和XXXXXX22实例,具体见下表:
2. 问题处理
2.1故障分析/问题处理
2.1.1 背景情况简述
由于两套数据库实例的故障现象类似,此处仅以XXXXXX2的故障分析做报告。此次宕机未出现集群级别Crash的情况。
数据库实例XXXXXX22 alert报“IPC Send timeout detected. Receiver ospid 23986328,LMON (ospid: 4457910) is not heartbeating for 636 seconds,LMD0: terminating instance due to error 482”;
当前问题主要分析方向主要有以下几点:
⑴IPC Send timeout报错问题;
⑵故障期间系统资源使用情况;
由于故障期间是由于数据库HANG导致,所以故障期间的AWR报告和ASH报告均未生成。以下分析完全借助科讯华通自主研发的DCMP系统的帮助,该系统在问题时刻仍然在采集数据库挂起前一刻的详细相关信息,这极大帮助该问题的定位判断,报告中相关截图均来自DCMP产品.
DCMP是一套专业的数据库运维管理平台,该系统集成了专业指标监控、性能告警、自动化运维等功能。其中专业指标监控实现针对数据库上千个专业指标进行细粒度的采样分析并提供图形化展示。性能告警不仅提供基础告警功能能,还会增加告警时段的相关数据采样。自动化运维可以在发生特定告警时配置相关自定义处理故障应急脚本,从而进行自动化处理分析。
2.1.2 故障时间流
XXXXXX1数据库故障期间活动回话详情图
XXXXXX11:
XXXXXX12:
XXXXXX21:
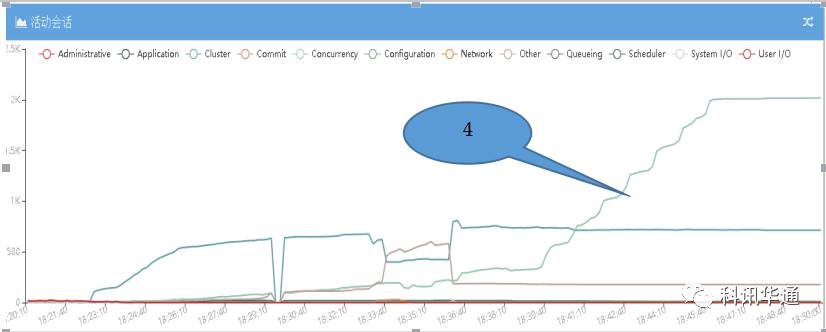
XXXXXX222:
分析点:
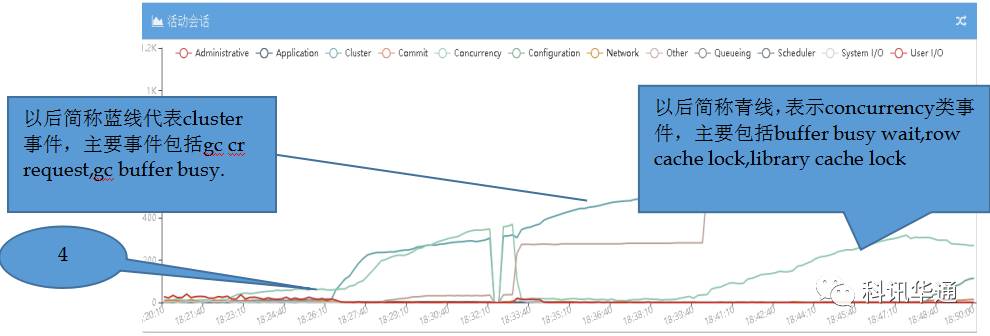
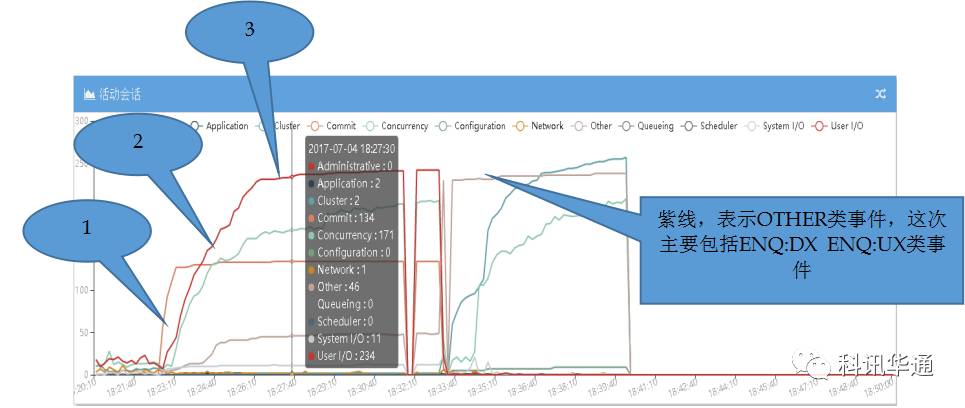
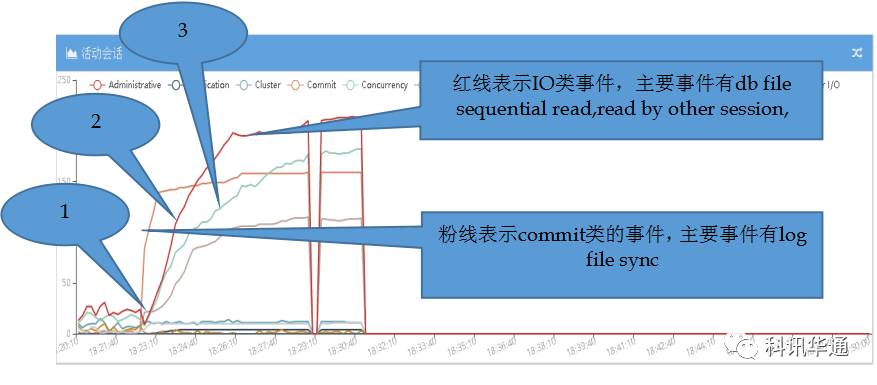
⑴18:22:40,从图XXXXXX12与XXXXXX22中可以看出,两个实例所在的主机XXXXXX2主机上的两个实例同时率先突发大量“commit“类事件(粉色线)。从活动回话视图里分析,COMMIT类事件相关SESSION全部等待“LOG FILE SYNC”从XXXXXX12与XXXXXX22的活动会话明细表格中发现,在出现大量LOG FILE SYNC之前一直到数据库发生脑裂LGWR进程一直在等待“LOG FILE PARALLEL WRITE“,这里推测LGWR被IO卡住了,后续有具体分析。现象是LGWR 等待IO事件被HANG,详情见下图“XXXXXX数据库LGWR进程写次数统计“及分析,导致出现了大量的 LOG FILE SYNC等待堵塞了大批业务进程。
⑵18:23:20,在COMMIT类事件异常之后,紧接着XXXXXX12与XXXXXX22数据库同时大量等待USER/IO类事件,这些事件主要包括两种,DB FILE SEQUTIAL READ与READ BY OTHER SESSION,从下图“CRM数据库DB FILE SEQUENTIAL READ等待次数统计”可以看出,18:22:50秒DB FILE READ数量有断崖式下滑,而LGWR堵塞是不会影响正常的数据库读。所以,数据库活动SESSION中出现大量的IO等待与断崖式的IO次数下滑可以综合分析故障期间XXXXXX2主机的IO请求大量出现超时现象。
⑶ 18:24:00左右,XXXXXX2主机上两个实例的青色线开始突发上涨,青线等待事件主要包括“BUFFER BUSY WAIT””ROW CACHE LOCK”,这些进程是被阻塞进程,经检查ROW CACHE LOCK等待回滚,BUFFER BUSY WAIT等待IO进程。
⑷18:23:10左右,在XXXXXX2主机上的两个实例发生堵塞之后,XXXXXX1主机上的两个实例先后发生堵塞,堵塞事件最明显的是GC类事件如:“GC CR REQUEST“。

5. 所以,XXXXXX数据库所有1实例被2实例阻塞,阻塞原因是2实例的LMS进程被LGWR进程堵塞。
总结,根据以上截图轻易可以分析出,XXXXXX1上的两个实例由于IO相关进程率先出现问题而引发阻塞,随后XXXXXX2上的两个实例受到影响引发了大量的GC等待,高峰时有2K多个活动回话等待GC.
2.1.3 IO分析
XXXXXX2主机相关实例IO分析图:
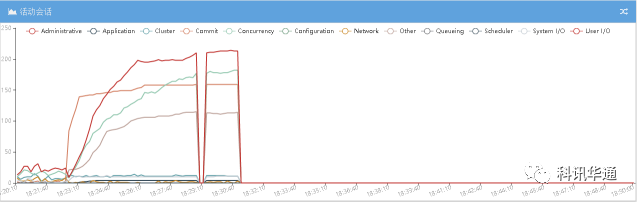
⑴DBFILE SEQUENTIAL READ 流量图
 ⑵LGWR写响应时长图
⑵LGWR写响应时长图
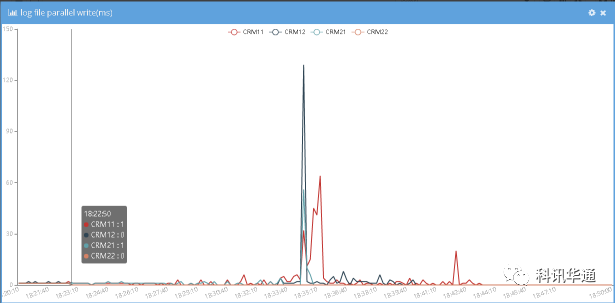 ⑶ LGWR写次数统计图
⑶ LGWR写次数统计图
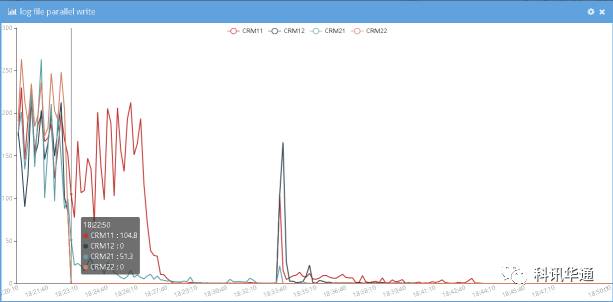 分析:
分析:
18:22:50, XXXXXX2主机上两个实例单块读IO突然降低到一个比较低的值。
18:22:50, XXXXXX2主机上两个实例LGWR进程写磁盘次数直接降低到0次。
18:22:50,XXXXXX2主机上两个实例LGWR进程响应时长直接变为0,这个是统计问题,如果统计时段内没有发生过一次读写,响应时长将统计为0。
从XXXXXX2上的LGWR TRACE里可以看出 “Warning: log write time 636410ms, size 22KB“,经过时间推算,超时开始的IO时间就是以上故障发生的时间点。
从NMON日志看18:25分到18:35分没有日志,另外本人在18:30分左右尝试无法登陆XXXXXX2,说明在NMON无法生成的期间,主机被HANG住。
总结,在18:22:50秒的时候,很明显的可以看出,当时LGWR IO已经没有响应。而数据库IO并没有完全HANG住,部分数据库读写还可以进行。
3. 问题总结
通过上述分析,我们掌握了明显的证据说明故障发生时系统IO出现了异常.
