





开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共790人左右 1 + 2)
Serverless 是一个在云端较热的话题,云上的数据库也都在进行SERVERLESS 化,RDS OR POLARDB ,但是这就提出一个问题,数据库都能进行serverless 吗,如有些数据库不能serverless 原因是什么,Serverless 对数据库有什么影响,是良性的还是良性的呢?
首先serverless 提出于云上的概念,serverless 是一种云计算执行的模式,通过云服务提供商运行和扩展应用所需的基础设施,在这种模型中,开发人员可以专注编写代码,无序担心底层服务器的资源问题,serverless 最早的出现的意义在于将管理服务器的责任从上层,移动到下层,针对使用的资源付费,而在不需要资源的时候,资源会自动进行协调。
而首先推出SERVERLESS 的产品的如 AWS lambda, Google Could functions , Microsoft Azure functions. 这些产品早期的目的也是为了开发人员在测试方面进行工作,以为测试的主机并不是很重要同时也不是满负荷的工作,尤其在非测试阶段等。

那么为什么又牵扯进来 RDS 的数据库产品呢,主要的原因是serverless与数据库之间的匹配度的问题, serverless 本身并不是一项技术,而是一个概念,而概念的实现到了技术层面本身就有各种限制和方式,RDS 数据库产品对于 serverless 在实现上限制较多,主要体现在以下几点
1 弹性的扩展能力差:serverless 场景一种关键点是应用负载具有显著的波峰和波谷,当面临洪峰的时候,需要及时的快速的扩容,在波谷的时候,需要快速的有效的缩容,而在扩容和缩容的情况下,对于业务不应该有卡顿和影响,RDS 的产品很难做到对业务的100% 的无影响。
2 运维复杂度高: 以MYSQL为例,基于MYSQL的复制机制,以及数据库本身对于内存和CPU的使用的方式等,在进行SERVERLESS 时考虑的点较多,很难做到全面顾及,这就导致在有些云上的数据库对于SERVERLESS的部分,在早期的版本很难做到让人满意的 SERVERLESS 。
3 成本优化的目的无法达到:这也是一个问题,基于传统数据库形成的RDS 产品部分资源很难做到SERVERLESS 如内存方面,这也就导致早期的SERVERLESS 产品很难做到有很大的成本优势,同时在磁盘成本方面目前的RDS 产品也很难有突破。
而截至目前,基于SERVERLESS 部分的准确的在数据库上的概念还未有行业的准确定义,这里简单的根据部分产品的定义来看看什么是在数据库上实现的 SERVERLESS
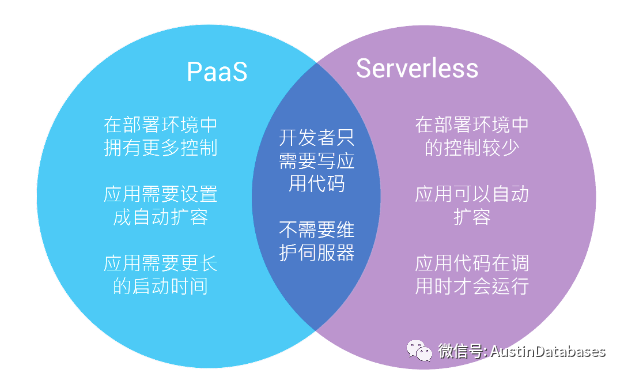
1 根据数据库负载,来自动进行弹性的扩容,主要为云上的数据库的费用计算和资源合理化使用来做出相关的工作。
2 按量计费,基于我使用多少,我付多少钱的原则,让云上的数据库产品像自来水一样
3 运维投入低,数据库在出现问题的大部分情况是由于资源的问题导致的,在这样的情况下数据库可以自动进行扩容,则会避免掉大面积的由于资源导致的问题。
上面我们大概了解了什么是SERVERLESS 以及SERVERLESS 数据库 产品的一些特点。目前各大云运营商提供的SERVERLESS 数据库主要有那些






