




说明:
介绍下达梦的执行计划包含的操作符,以及生产系统上的调优一例。
一. DM 执行计划的操作符介绍
NSET: 结果集
PRJT:投影,用于选择表达式的计算
CSCN:基础全表扫描(a),从头到尾,全部扫描
SSCN:二级索引扫描(b),从头到尾,全部扫描
SSEK:二级索引范围扫描(b),通过键值精准定位到范围或者单值
CSEK:聚簇索引范围扫描(c),通过键值精准定位到范围或者单值
BLKUP:通过二级索引的ROWID回原表中取出全部数据(b+a)
SLCT:过滤条件,是对结果集进行过滤
SORT:SORT是做排序操作时使用到的操作符
HAGR:HASH AGR操作,是最基础的分组方式,对于没有优化条件的分组语句,一般都会按这种方式进行分组。
SAGR:SORTED AGR操作,同一分组的数据按照顺序取出。
NEST LOOP INNER JOIN (嵌套循环连接):最基础的连接方式,将一张表的一个值与另一张表所有值拼接,形成一个大结果集,再从大结果集中过滤出满足条件的行。
HASH JOIN (哈希连接):没有索引情况下,大多数连接的处理方式,将一张的连接列做成哈希表,另一张表的数据向这个哈希表匹配,满足条件返回。
INDEX JOIN(索引连接):将一张表的数据拿出,去另一张表上进行范围扫描找出需要的数据行,需要右表连接列上存在索引
MERGE JOIN (归并连接):两张表都扫描索引,按照索引顺序进行归并。
二. 如何定位存储过程中的慢sql
动态性能视图、sqllog等只能定位普通的DML语句,对于在package、procedure等对象中的慢sql无法直接定位具体在哪一条语句。
目前还是通过Manager管理工具中的sql调试进行定位
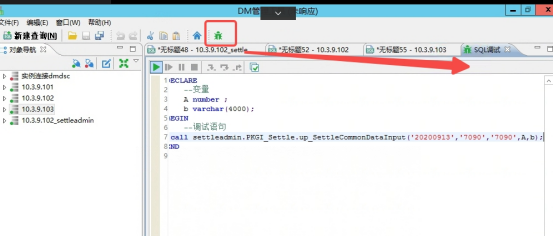
进入对象后,逐步运行或是打断点。内容如果太多,这两种方式也比较麻烦,推荐在可疑sql前后,增加日志记录,方便定位。
三. 具体的性能优化举例
1)问题表现
前端WEB页面,点击按钮后,长时间卡死,等待十几分钟没有响应。
2)数据库情况
--查看集群会话情况
select *from gv$sessions where state=’ACTIVE’;
--可以看到DSC集群3个节点的活动会话连接情况
结果:会话正在执行的SQL为:
call PKGI_Settle.up_SettleCommonDataInput(?,?,?,?,?)
--查询正在执行的慢SQL
SELECT* FROM ( SELECT SESS_ID,SQL_TEXT,DATEDIFF(SS,LAST_RECV_TIME,SYSDATE) Y_EXETIME, SF_GET_SESSION_SQL(SESS_ID) FULLSQL,CLNT_IP FROM V$SESSIONS WHERE STATE='ACTIVE') WHERE Y_EXETIME>=2;
--执行超过2秒的SQL
结果同样为:
call PKGI_Settle.up_SettleCommonDataInput(?,?,?,?,?)
--查询锁
--锁
SELECT O.NAME,L.* FROM V$LOCK L,SYSOBJECTS O WHERE L.TABLE_ID=O.ID AND BLOCKED=1;
--意向锁
SELECT O.NAME,L.* FROM V$LOCK L,SYSOBJECTS O WHERE L.TABLE_ID=O.ID AND LMODE IN(‘IX’,’IS’);
结果:
可以查询到表SettleIn.T_LASTFUND上一直保持有IX意向排他锁,可能正在执行该表上的部分数据更新或者插入。
3)定位慢sql
在SQL调试窗口,步进调试存储过程,
结果:定位慢SQL为
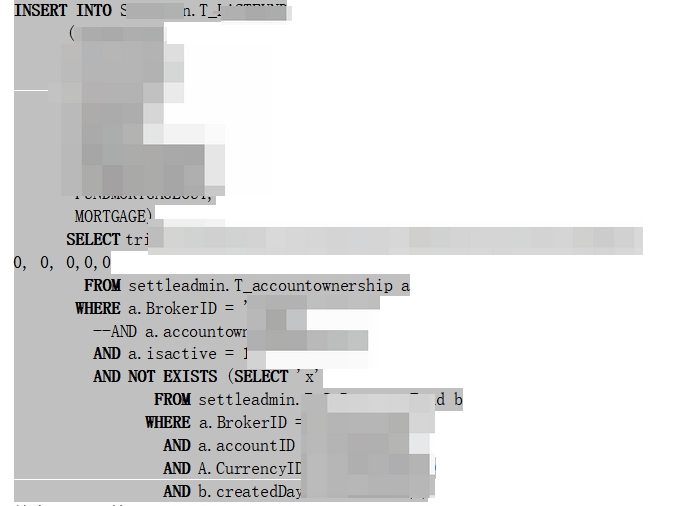
符合v$lock情况
4)查看执行计划
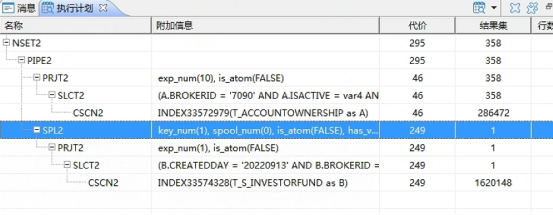
分析:根据执行计划,前后查询的结果集都是全表扫描,没有索引辅助,而且两个结果集通过管道连接(PIPE2),即前结果集输出一行结果后,带入到后一个中进行判断,满足not exist条件则输出,循环执行。前后结果集的数据记录分别有27万+,28万+。执行效率特别低,长时间得不到结果。
5)优化
--先收集一遍统计信息,确保统计信息准确。
DBMS_STATS.GATHER_SCHEMA_STATS('SETTLEADMIN',100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
DBMS_STATS.GATHER_SCHEMA_STATS('SETTLEIN',100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
--清理执行计划缓存
SP_CLEAR_PLAN_CACHE
--再次查看执行计划
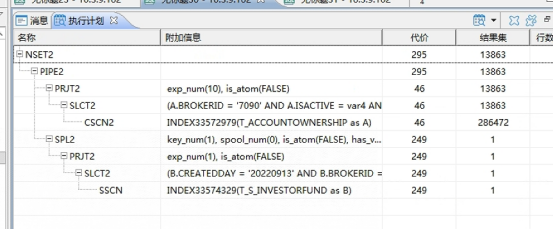
有所优化,有一个表查询有了索引辅助,但开销最大的PIPE2连接没变。代价估算的结果值也不准确,和实际相差太大,执行SQL还是长时间没结果。
优化思路:需要调整表连接的方式,前后表数据量都不低的情况下,不能通过PIPE2做管道连接。尽量走HASH连接。
优化方式一:修改SQL语句,不使用not exist,改用外连接和判空的方式
--查看执行计划
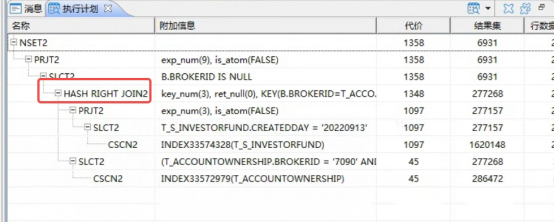
可以看到,执行计划走了hash连接,代价估算为1358,实际执行时间为10s左右,相比之前好几分钟都无法执行完成,已经进步很大。前端页面也可以完成响应。
优化方式二:使用hint方式,拼接子查询相关优化参数,其它sql内容不变
SELECT
/*+SUBQ_CVT_SPL_FLAG(1) ENABLE_RQ_TO_NONREF_SPL(1)*/ ...

执行计划使用了索引辅助(虽然是索引全扫,相比全表扫还是降低了代价)和hash连接,实际执行时间到了2s左右。完全满足了业务需要。
6)总结
SUBQ_CVT_SPL_FLAG(1) ENABLE_RQ_TO_NONREF_SPL(1)
这两个参数控制使用SPL2方式实现相关子查询,并对查询表达式进行优化处理,将相关列转为变量VAR,从而简化了执行计划。
