




本文将带你解读Transformer的论文《Attention Is All You Need》,以及Tensorflow中转化器模型的详细实现。


本文将描述并解读论文“Attention Is All You Need”(Vaswani、Ashish和Shazeer、Noam和Parmar、Niki和Uszkoreit、Jakob和Jones、Llion和Gomez、Aidan和Kaiser、Lukasz和Polosukhin, Illia.(2017)). 这篇论文在使用注意力机制方面取得了很大进步,是对一个叫做Transformer的模型的主要改进。目前在NLP任务中出现的最有名的模型由数十个转换器或它们的一些变体组成,例如GPT-2或BERT。
将描述这个模型的组成部分,分析它们的操作,并建立一个简单的模型,将把它应用于一个小规模的NMT问题(神经机器翻译)。
为什么需要Transformer?
在神经机器翻译等序列到序列问题中,最初的建议是基于在编码器-解码器架构中使用RNN。但是这些架构在处理长序列时有很大的局限性,当新的元素被纳入到序列中时,它们保留第一个元素的信息的能力就丧失了。在编码器中,每一步的隐藏状态都与输入句子中的某个词相关,通常是最近的一个。因此,如果解码器只访问解码器的最后一个隐藏状态,它将失去关于序列中第一个元素的相关信息。为了解决这一局限性,引入了一个新的概念——注意力机制。
在解码器的每一步中,不是像通常的RNN那样关注编码器的最后一个状态,而是关注编码器的所有状态,从而能够访问关于输入序列所有元素的信息。这就是注意力的作用,它从整个序列中提取信息,是所有过去编码器状态的加权和。这使得解码器能够为输出的每个元素分配更大的权重或重要性给输入的某个元素。学习在每一步中关注输入的正确元素以预测下一个输出元素。
但这种方法仍然有一个重要的局限性,每个序列必须一次处理一个元素。编码器和解码器都必须等到步骤完成t-1
才能处理该t-th
步骤。因此,在处理庞大的语料库时是非常耗时且计算效率低下的。
什么是Transformer?
Transformer是一个避免递归的模型结构,完全依靠注意力机制来得出输入和输出之间的全局依赖关系。Transformer允许显著提高并行化程度。Transformer是第一个完全依靠自我注意力来计算其输入和输出表征而不使用序列对齐RNN或卷积的转换模型,
“Attention Is All You Need”论文
Transformer模型使用自我注意机制为每个词提取特征,以计算出句子中所有其他词对上述词的重要性。而且,没有使用递归单元来获得这个特征,它们只是加权和激活函数,所以它们可以非常并行化和高效。
接下来将更深入地研究Transformer的结构(如下图所示),以了解所有这些部分的作用。
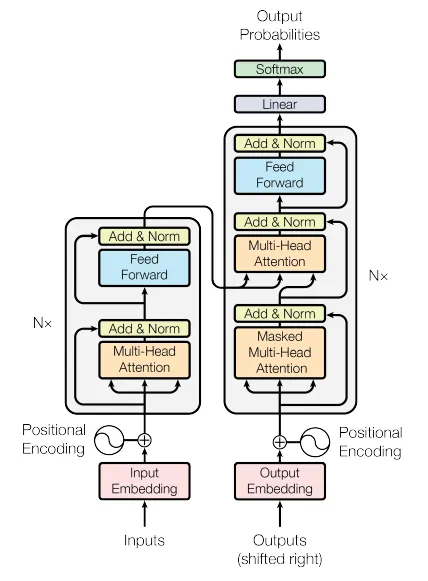
可以观察到,左侧有一个编码器模型,右侧有一个解码器模型。两者都包含重复N次的“注意力和前馈网络”的核心块。但首先需要深入探讨一个核心概念:self-attention机制。
Self-Attention:基本操作
Self-attention是一个序列到序列的操作:输入一个向量序列,然后输出一个向量序列。将输入向量称为
x1
,x2
,…,xt
以及相应的输出向量y1
,y2
,…,yt
。这些向量都具有维度k。产生输出向量yi
, Self-attention操作只是对所有输入向量进行加权平均,最简单的选择是点积。“Transformers from scratch”by Peter Bloem
在模型的self-attention机制中,需要引入三个元素:Queries、Values和Keys。
Queries、Values和Keys
在self-attention机制中,每个输入向量都有三种不同的使用方式:Query,Key和Value。在每个角色中,它都要与其他向量进行比较,以获得自己的输出yi
(Query),获得第j个输出yj
(Key),并在权重确定后计算每个输出向量(Value)。
为了获得这些元素,需要三个维度为k x k的权重矩阵,并为每个xi
计算三个线性变换:
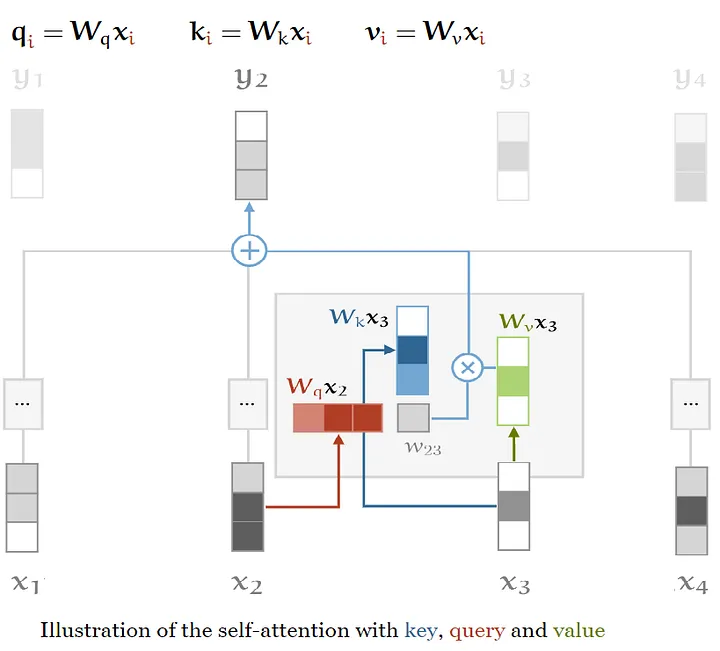
这三个矩阵通常被称为K、Q和V,是应用于同一编码输入的三个可学习权重层。因此,由于这三个矩阵中的每一个都来自同一个输入,可以应用输入向量与自身的注意机制,即“Self-Attention”。
缩放点积注意力
输入包括查询和维度为dk的键,以及维度为dv的值。计算查询与所有键的点积,将每个键除以dk的平方根,并应用
softmax
函数来获得数值上的权重。“Attention Is All You Need”论文
然后,使用Q、K和V矩阵来计算注意力分数。这些分数衡量对输入序列中的其他地方或单词的关注程度,以及对某一位置的单词的关注程度。也就是说,查询向量与各个单词的关键向量的点积就是得分。因此,对于位置1,计算q1
和k1
的点积(.),然后是q1
.k2
,q1
.k3
,以此类推......
接下来我们应用“缩放”因子,以获得更稳定的梯度。softmax
函数在大的数值下不能正常工作,导致梯度消失,使学习速度减慢。在“softmaxing
”之后,乘以Value矩阵,以保留想要关注的词的值,并最小化或删除不相关的词的价值(它在V矩阵中的值应该非常小)。
这些操作的公式是:
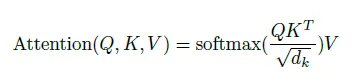
def scaled_dot_product_attention(queries, keys, values, mask):
# 计算点积,QK_transpose
product = tf.matmul(queries, keys, transpose_b=True)
# 获得比例因子
keys_dim = tf.cast(tf.shape(keys)[-1], tf.float32)
# 将比例系数应用于点积
scaled_product = product / tf.math.sqrt(keys_dim)
# 在需要的时候应用遮蔽
if mask is not None:
scaled_product += (mask * -1e9)
# 用值进行点积
attention = tf.matmul(tf.nn.softmax(scaled_product, axis=-1), values)
return attention复制
多头注意力
在前面的描述中,注意力的分数每次都集中在整个句子上,即使两个句子以不同的顺序包含相同的词,这也会产生同样的结果。相反,希望能关注不同的词段。“我们可以赋予self-attention更大的辨别能力,通过组合几个self-attention heads,将词向量分成固定数量(h,heads数量)的chunks,然后将self-attention应用在相应的chunks上,使用Q、K和V子矩阵。”,Peter Bloem,“Transformers from scratch”。这产生了h个不同的分数输出矩阵。
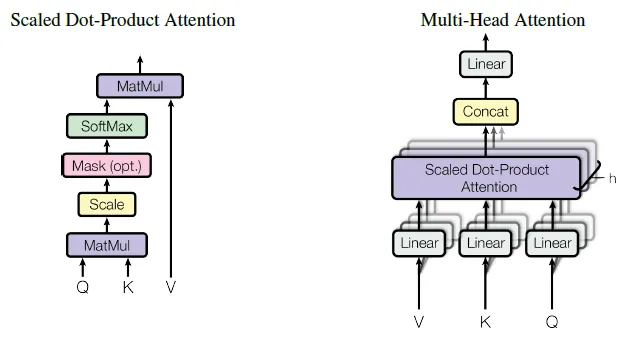
但是下一层(前馈层)只需要一个矩阵,每个词都是一个向量,所以“在计算每个头的点积之后,把输出矩阵串联起来,再乘以一个额外的权重矩阵Wo
,”。这个最终的矩阵捕获了来自所有注意力头的信息。
class MultiHeadAttention(layers.Layer):
def __init__(self, n_heads):
super(MultiHeadAttention, self).__init__()
self.n_heads = n_heads
def build(self, input_shape):
self.d_model = input_shape[-1]
assert self.d_model % self.n_heads == 0
# 计算每个头部或投影的尺寸
self.d_head = self.d_model // self.n_heads
# 设置Q、K和V的权重矩阵
self.query_lin = layers.Dense(units=self.d_model)
self.key_lin = layers.Dense(units=self.d_model)
self.value_lin = layers.Dense(units=self.d_model)
# 设置多头注意力输出的权重矩阵W0
self.final_lin = layers.Dense(units=self.d_model)
def split_proj(self, inputs, batch_size): # 输入:(batch_size, seq_length, d_model)
# 设置投影的维度
shape = (batch_size,
-1,
self.n_heads,
self.d_head)
# 分割输入向量
splited_inputs = tf.reshape(inputs, shape=shape) # (batch_size, seq_length, nb_proj, d_proj)
return tf.transpose(splited_inputs, perm=[0, 2, 1, 3]) # (batch_size, nb_proj, seq_length, d_proj)
def call(self, queries, keys, values, mask):
# 获取批次大小
batch_size = tf.shape(queries)[0]
# 设置Query、Key和alue矩阵
queries = self.query_lin(queries)
keys = self.key_lin(keys)
values = self.value_lin(values)
# 在头或投影之间分割Q、K y V
queries = self.split_proj(queries, batch_size)
keys = self.split_proj(keys, batch_size)
values = self.split_proj(values, batch_size)
# 应用缩放的点积
attention = scaled_dot_product_attention(queries, keys, values, mask)
# 获得注意力分数
attention = tf.transpose(attention, perm=[0, 2, 1, 3])
# 将h个头或投影连接起来
concat_attention = tf.reshape(attention,
shape=(batch_size, -1, self.d_model))
# 应用W0来获得多头注意力的输出
outputs = self.final_lin(concat_attention)
return outputs复制
位置编码
在模型中,句子中的词的顺序是一个需要解决的问题,因为网络和自我注意机制是排列不变的。如果打乱输入句子中的单词,会得到同样的解决方案。需要创建句子中的表示,并将其添加到单词嵌入中。
为此,在编码器和解码器堆栈的底部向输入嵌入添加“位置编码”。位置编码与嵌入具有相同的维度,因此两者可以相加。位置编码有多种选择。
“Attention Is All You Need”论文
因此,应用一个函数将句子中的位置映射到一个实值向量。网络将学习如何使用这些信息。另一种方法是使用位置嵌入,类似于词嵌入,用一个向量对每个已知的位置进行编码。“在训练循环中,它需要所有接受位置的句子,但位置编码允许模型推断出比训练中遇到的序列长度更长的序列”。
在本文中,应用了一个正弦波函数:
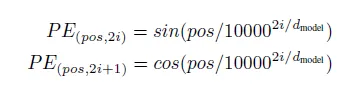
class PositionalEncoding(layers.Layer):
def __init__(self):
super(PositionalEncoding, self).__init__()
def get_angles(self, pos, i, d_model): # pos: (seq_length, 1) i: (1, d_model)
angles = 1 / np.power(10000., (2*(i//2)) / np.float32(d_model))
return pos * angles # (seq_length, d_model)
def call(self, inputs):
# 输入 shape batch_size, seq_length, d_model
seq_length = inputs.shape.as_list()[-2]
d_model = inputs.shape.as_list()[-1]
# 计算给定输入的角度
angles = self.get_angles(np.arange(seq_length)[:, np.newaxis],
np.arange(d_model)[np.newaxis, :],
d_model)
# 计算位置编码
angles[:, 0::2] = np.sin(angles[:, 0::2])
angles[:, 1::2] = np.cos(angles[:, 1::2])
# 用一个新的维度扩展编码
pos_encoding = angles[np.newaxis, ...]
return inputs + tf.cast(pos_encoding, tf.float32)复制
编码器
现在,模型的所有主要部分都已经描述过了,可以介绍一下编码器组件:
编码:将位置编码添加到输入嵌入中(输入词被转换为嵌入向量)。“两个嵌入层(编码器和解码器)和
pre-softmax
线性变换之间共享相同的权重矩阵。在嵌入层中,将这些权重乘以模型维度的平方根”。N=6
相同的层,包含两个子层:一个多头的自我注意机制,和一个全连接的前馈网络(两个带有ReLU激活的线性变换)。但它是按位置应用于输入的,这意味着同一个神经网络被应用于属于句子序列的每一个“标记”向量。
每个子层(注意和FC网络)周围都有一个残差连接,将该层的输出与输入相加,然后进行层的归一化。
在每个残差连接之前,都会应用一个正则化:“对每个子层的输出进行剔除,然后再将其添加到子层的输入中并进行归一化。此外,对编码器和解码器堆栈中的嵌入和位置编码的总和进行剔除”,剔除率为0.1。
归一化和残差连接是用于帮助深度神经网络更快、更准确地训练的标准技巧。层的归一化仅适用于嵌入维度。——Peter Bloem,“Transformers from scratch”
首先实现编码器层,六个块中的每一个,都包含在一个编码器中:
class EncoderLayer(layers.Layer):
def __init__(self, FFN_units, n_heads, dropout_rate):
super(EncoderLayer, self).__init__()
# 前馈组件的隐藏单元
self.FFN_units = FFN_units
# 设置projectios或heads数量
self.n_heads = n_heads
# 剔除率
self.dropout_rate = dropout_rate
def build(self, input_shape):
self.d_model = input_shape[-1]
# 构建多头层
self.multi_head_attention = MultiHeadAttention(self.n_heads)
self.dropout_1 = layers.Dropout(rate=self.dropout_rate)
# 图层归一化
self.norm_1 = layers.LayerNormalization(epsilon=1e-6)
# 全连接前馈层
self.ffn1_relu = layers.Dense(units=self.FFN_units, activation="relu")
self.ffn2 = layers.Dense(units=self.d_model)
self.dropout_2 = layers.Dropout(rate=self.dropout_rate)
# 图层归一化
self.norm_2 = layers.LayerNormalization(epsilon=1e-6)
def call(self, inputs, mask, training):
# 多头注意力的正向传递
attention = self.multi_head_attention(inputs,
inputs,
inputs,
mask)
attention = self.dropout_1(attention, training=training)
# 调用残差连接和层的归一化
attention = self.norm_1(attention + inputs)
# 调用到FC层
outputs = self.ffn1_relu(attention)
outputs = self.ffn2(outputs)
outputs = self.dropout_2(outputs, training=training)
# 调用残差连接和层的归一化
outputs = self.norm_2(outputs + attention)
return outputs复制
下图将详细显示组件:
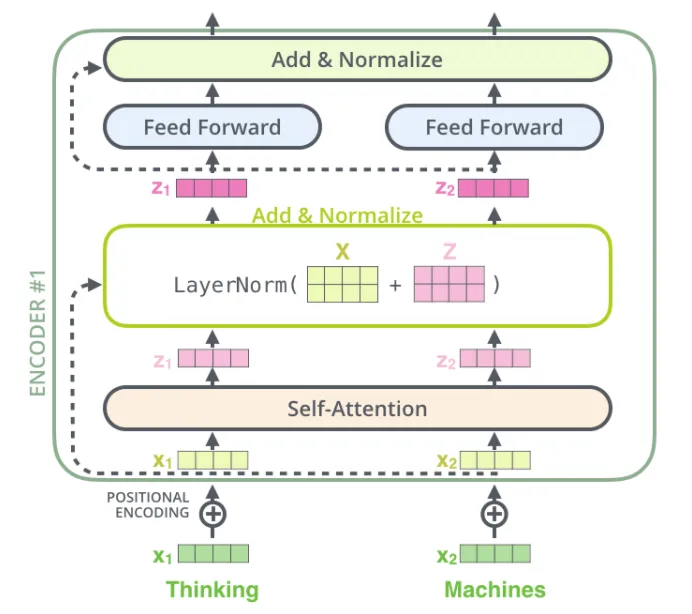
还有编码器的代码:
class Encoder(layers.Layer):
def __init__(self,
n_layers,
FFN_units,
n_heads,
dropout_rate,
vocab_size,
d_model,
name="encoder"):
super(Encoder, self).__init__(name=name)
self.n_layers = n_layers
self.d_model = d_model
# 嵌入层
self.embedding = layers.Embedding(vocab_size, d_model)
# 位置编码层
self.pos_encoding = PositionalEncoding()
self.dropout = layers.Dropout(rate=dropout_rate)
# 多头注意力和FC的n个层的堆栈
self.enc_layers = [EncoderLayer(FFN_units,
n_heads,
dropout_rate)
for _ in range(n_layers)]
def call(self, inputs, mask, training):
# 获得嵌入向量
outputs = self.embedding(inputs)
# 用d_model的平方来衡量嵌入的大小
outputs *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
# 位置编码
outputs = self.pos_encoding(outputs)
outputs = self.dropout(outputs, training)
# 调用堆叠层
for i in range(self.n_layers):
outputs = self.enc_layers[i](outputs, mask, training)
return outputs复制
请记住,只有最后一层(第6层)的向量被发送到解码器。
解码器
解码器与编码器共享一些组件,但它们以不同的方式使用,以考虑到编码器的输出,:
位置编码:与编码器中的类似。 N=6
相同的层,包含3个子层。首先,Masked Multi-head attention或Masked causal attention,以防止位置注意到随后的位置。“这种屏蔽,结合输出嵌入偏移一个位置的事实,确保对位置i的预测只取决于小于i的位置的已知输出”。它的实现是将点积注意模块的softmax
层中对应于禁止状态的值设置为-∞
。第二组成部分或“编码器-解码器注意”对解码器的输出进行多头注意,Key和Value向量来自编码器的输出,但查询来自前一个解码器层。“这使得解码器中的每个位置都能参与输入序列中的所有位置”。最后是全连接的网络。围绕每个子层的残差连接和层的归一化,与编码器类似。 并重复在编码器中执行的相同的残差丢失。
解码器层:
class DecoderLayer(layers.Layer):
def __init__(self, FFN_units, n_heads, dropout_rate):
super(DecoderLayer, self).__init__()
self.FFN_units = FFN_units
self.n_heads = n_heads
self.dropout_rate = dropout_rate
def build(self, input_shape):
self.d_model = input_shape[-1]
# 自身多头注意,因果注意
self.multi_head_causal_attention = MultiHeadAttention(self.n_heads)
self.dropout_1 = layers.Dropout(rate=self.dropout_rate)
self.norm_1 = layers.LayerNormalization(epsilon=1e-6)
# 多头注意,编码器-解码器注意
self.multi_head_enc_dec_attention = MultiHeadAttention(self.n_heads)
self.dropout_2 = layers.Dropout(rate=self.dropout_rate)
self.norm_2 = layers.LayerNormalization(epsilon=1e-6)
# 向前传播
self.ffn1_relu = layers.Dense(units=self.FFN_units,
activation="relu")
self.ffn2 = layers.Dense(units=self.d_model)
self.dropout_3 = layers.Dropout(rate=self.dropout_rate)
self.norm_3 = layers.LayerNormalization(epsilon=1e-6)
def call(self, inputs, enc_outputs, mask_1, mask_2, training):
# 调用被屏蔽的因果注意
attention = self.multi_head_causal_attention(inputs,
inputs,
inputs,
mask_1)
attention = self.dropout_1(attention, training)
# 残差连接和层的归一化
attention = self.norm_1(attention + inputs)
# 调用编码器-解码器注意
attention_2 = self.multi_head_enc_dec_attention(attention,
enc_outputs,
enc_outputs,
mask_2)
attention_2 = self.dropout_2(attention_2, training)
# 残差连接和层的归一化
attention_2 = self.norm_2(attention_2 + attention)
# 调用前馈程序
outputs = self.ffn1_relu(attention_2)
outputs = self.ffn2(outputs)
outputs = self.dropout_3(outputs, training)
# 残差连接和层的归一化
outputs = self.norm_3(outputs + attention_2)
return outputs复制

在N个堆叠解码器的末端,线性层,一个全连接的网络,将堆叠的输出转化为一个更大的向量,即logits。“然后softmax
层将这些分数(logits)转化为概率(全部为正数,全部加起来为1.0)。选择概率最高的单元,并产生与之相关的词作为这个时间步骤的输出”,Jay Alammar, “The Ilustrated Transformer”。
解码器组件:
class Decoder(layers.Layer):
def __init__(self,
n_layers,
FFN_units,
n_heads,
dropout_rate,
vocab_size,
d_model,
name="decoder"):
super(Decoder, self).__init__(name=name)
self.d_model = d_model
self.n_layers = n_layers
# 嵌入层
self.embedding = layers.Embedding(vocab_size, d_model)
# 位置编码层
self.pos_encoding = PositionalEncoding()
self.dropout = layers.Dropout(rate=dropout_rate)
# 多头注意和前馈的叠加层
self.dec_layers = [DecoderLayer(FFN_units,
n_heads,
dropout_rate)
for _ in range(n_layers)]
def call(self, inputs, enc_outputs, mask_1, mask_2, training):
# 获得嵌入向量
outputs = self.embedding(inputs)
# 以d_model的平方为尺度
outputs *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
# 位置编码
outputs = self.pos_encoding(outputs)
outputs = self.dropout(outputs, training)
# 调用堆叠层
for i in range(self.n_layers):
outputs = self.dec_layers[i](outputs,
enc_outputs,
mask_1,
mask_2,
training)
return outputs复制
推荐书单

《PyTorch深度学习简明实战》
本书针对深度学习及开源框架——PyTorch,采用简明的语言进行知识的讲解,注重实战。全书分为4篇,共19章。深度学习基础篇(第1章~第6章)包括PyTorch简介与安装、机器学习基础与线性回归、张量与数据类型、分类问题与多层感知器、多层感知器模型与模型训练、梯度下降法、反向传播算法与内置优化器。计算机视觉篇(第7章~第14章)包括计算机视觉与卷积神经网络、卷积入门实例、图像读取与模型保存、多分类问题与卷积模型的优化、迁移学习与数据增强、经典网络模型与特征提取、图像定位基础、图像语义分割。自然语言处理和序列篇(第15章~第17章)包括文本分类与词嵌入、循环神经网络与一维卷积神经网络、序列预测实例。生成对抗网络和目标检测篇(第18章~第19章)包括生成对抗网络、目标检测。
本书适合人工智能行业的软件工程师、对人工智能感兴趣的学生学习,同时也可作为深度学习的培训教程。
【半价促销中】购买链接:https://item.jd.com/13512395.html


精彩回顾
《探索Python FastAPI核心功能和CRUD实例讲解》
《知识图谱并不难,用Neo4j和Python打造社交图谱(下)》
《知识图谱并不难,用Neo4j和Python打造社交图谱(中)》
长按关注《Python学研大本营》,加入读者群 长按访问【IT今日热榜】,发现每日技术热点

