




知识图谱是一种用于表示和存储知识的图形化知识库,它描述了现实世界中实体、概念、实体间的关系以及属性等信息。知识图谱的构建需要从多个来源收集数据,并使用自然语言处理、机器学习等技术进行数据清洗、实体识别、关系抽取等处理,最终形成一个结构化的知识库。


C.查看推T的数据
正如在开头提到的,在本文中,将使用Neo4j来探索推T的数据。这些数据从推T的API中收集,存储在MongoDB
中,并从那里导出为JSON
文件。
数据中的每个条目都包含三个主要的键:
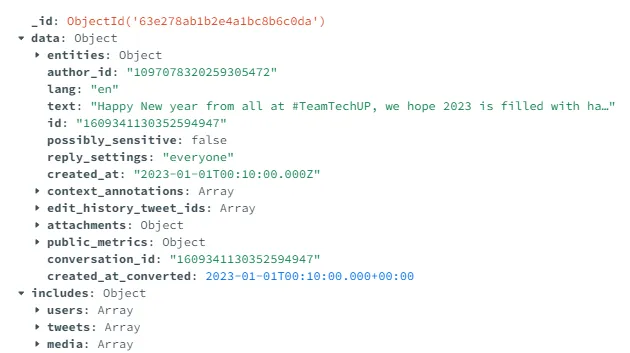
_id:
一个由MongoDB自动生成的ID,可以忽略它。data
:包括推文的元数据,如推文的唯一ID、创建时间、语言等。includes
: 包括关于用户的元数据,推文和任何媒体(视频、图片等)(如果有的话)。
本文将专注于“includes
”键下的数据,因为可以从那里提取想要用于此项目目的的所有信息。

在“inlcudes
”键下主要有三个键:
users
:这里可能有(如上图所示)两个子键:“0
”和“1
”。“0
”始终存在,它包含有关正在探索的推文作者的多个数据。当提到推文的“作者”时,不一定是指原作者,而是指发布推文的用户。帖子可以是原始推文、回复、引用或转推。如果推文中有“引用对象”,例如另一个用户或另一条推文,则键“1
”存在。在键“1
”下,可以找到与键“0
”下包含的信息类似的信息,但在这种情况下,信息是关于引用用户的。例如,如果用户A回复了用户B的推文,则有关用户A的信息将在键“0
”下找到,而用户B的信息将在键“1
”下找到。tweets:包含有关推文的信息。与“users”键相同的逻辑适用:“
0
”子键包含“用户-0”发布的推文信息,而“1
”包含“用户-1”发布的推文信息。media:包含有关推文中可能存在的任何媒体的信息。在分析中没有使用这个键,因此可以在本文中忽略它。
了解了不同的相关键之后,再看看是如何处理数据的:在获取JSON
文件后,创建了一个Python脚本来解析文件并提取在Neo4j中进行分析所需的字段。
更具体地说,使用想要在Neo4j中构建的图形模型的节点和关系相关的数据创建了不同的pandas
数据框。然后,创建了想要运行的查询,并运行它们以便在Neo4j中创建和探索图形模型。
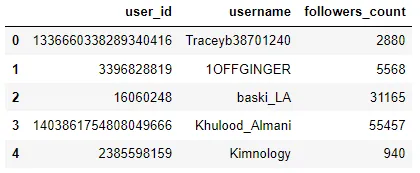
为了让你了解上述情况,下面是处理有关用户的数据而运行的代码的摘要版本,以及相应的输出:
import json
import pandas as pd
# 从文件中加载数据到Python
tweets_json = 'C:\\Path\\to\\json\\file.json'
with open(tweets_json, encoding='utf-8') as data_file:
data = json.load(data_file)
# 初始化`users_dict`
users_dict = {'user_id': [],
'username': [],
'followers_count': []}
# 提取相关数据
for tweet in data:
# 提取用户0信息,即Tweet作者信息(tweet/reply/quote/retweet)。
user_id_0 = tweet['includes']['users'][0]['id']
username_0 = tweet['includes']['users'][0]['username']
user_followers_count_0 = tweet['includes']['users'][0]['public_metrics']['followers_count']
# 将用户数据保存到一个字典中
users_dict['user_id'].append(user_id_0)
users_dict['username'].append(dusername_0)
users_dict['followers_count'].append(user_followers_count_0)
# 将`users_dict`转换为`pandas`数据框架
users_df = pd.DataFrame(users_dict)
# 删除任何潜在的重复值
users_df = users_df.drop_duplicates(subset=['user_id'], keep='first')
.reset_index(drop=True)
users_df.head()
在继续介绍如何通过Python在Neo4j中创建和探索图形模型之前,应该提到,使用neo4j
库来连接Python实例和本地Neo4j实例。本文使用如下所示的代码完成了这个工作:
from neo4j import GraphDatabase
# 建立数据库连接
db_connection = GraphDatabase.driver(uri = "bolt://localhost:7687",
auth=("neo4j", "<YOUR_PASSWORD_HERE>"))
# 创建一个会话对象,用于运行任何Cypher查询
session = db_connection.session()
在pandas数据框中收集数据并将Python实例连接到本地Neo4j之后,剩下的就是创建和运行Cypher查询。要使用展示的数据创建用户节点,运行以下代码块:
# 用户节点
for index, row in users_df.iterrows():
create_user_statement = 'CREATE (u:User {{userid: \'{}\', username: \'{}\', followers_count: \'{}\'}})' \
.format(row['user_id'],
row['username'],
row['followers_count'])
session.run(create_user_statement)
正如所看到的,通过解析放在一起的数据框架来创建必要的Cypher查询,然后通过session.run()
命令简单地运行查询。
为了使一切更清楚,其余的查询将以纯Cypher的形式呈现,没有周围所有的python代码,以及必要的数据存放位置。
D.使用从Python中收集的推文创建Neo4j图形模型
要在Neo4j中创建图形模型,需要两个组件:节点、节点之间的关系。重要的是要注意,节点和关系都可以以键值对的形式具有许多不同的属性。关系是命名的、有方向的,并且应该始终有一个开始和结束节点。
为了创建图形模型,使用了以下节点,每个节点都有其相应的属性:
1.User节点: user_id
,username
,followers_count
。2.Tweet节点: tweet_id
,text
,impression_count
,tweet_date
,reply_count
。3.URL节点: url
。4.Hashtag节点: hashtag
。
为了创建上述节点,需要运行以下4个Cypher查询:
CREATE (u:User {userid: '<user_id>',
username: '<username>',
followers_count: '<followers_count>'})
CREATE (t:Tweet {tweet_id: '<tweet_id>',
tweet_text: '<text>',
impression_count: '<impression_count>',
created_at: '<created_at>',
reply_count: '<reply_count>'})
CREATE (u:URL {url: '<URL>'})
CREATE (h:Hashtag {hashtag: '<hashtag>'})
现在创建节点之间的关系,为图形模型使用了以下关系:
TWEETED_ORIGINAL/RETWEETED/REPLIED/QUOTED关系:从 User
结点到Tweet
结点。HAS_URL关系:从 Tweet
结点到Url
结点。HAS_HASHTAG关系:从 Tweet
节点到Hashtag
节点。USED_URL关系:从 User
结点到Url结点。MENIONED关系:从 User
结点到User
结点。这里需要注意的是,这种关系包含了转发、回复、引用以及在推特正文中对用户的简单提及(例如,像“@用户”)。
这些关系可以通过以下Cypher查询来创建:
// Create User TWEETED_ORIGINAL Tweet relationship
MATCH (u:User), (t:Tweet)
WHERE u.userid = '<user_id>' AND t.tweet_id = '<tweet_id>'
CREATE (u)-[to:TWEETED_ORIGINAL]->(t)
RETURN type(to)
// Create User RETWEETED Tweet relationship
MATCH (u:User), (t:Tweet)
WHERE u.userid = '<user_id>' AND t.tweet_id = '<tweet_id>'
CREATE (u)-[rt:RETWEETED]->(t)
RETURN type(rt)
// Create User REPLIED Tweet relationship
MATCH (u:User), (t:Tweet)
WHERE u.userid = '<user_id>' AND t.tweet_id = '<tweet_id>'
CREATE (u)-[rp:REPLIED]->(t)
RETURN type(rp)
// Create User QUOTED Tweet relationship
MATCH (u:User), (t:Tweet)
WHERE u.userid = '<user_id>' AND t.tweet_id = '<tweet_id>'
CREATE (u)-[qt:QUOTED]->(t)
RETURN type(qt)
// Create Tweet HAS_URL Url relationship
MATCH (t:Tweet), (u:URL)
WHERE t.tweet_id = '<tweet_id>' AND u.url = '<url>'
CREATE (t)-[tu:HAS_URL]->(u)
RETURN type(tu)
// Create Tweet HAS_HASHTAG Hashtag relationship
MATCH (t:Tweet), (h:Hashtag)
WHERE t.tweet_id = '<tweet_id>' AND h.hashtag = <'hashtag'>
CREATE (t)-[th:HAS_HASHTAG]->(h)
RETURN type(th)
// Create User USED_URL Url relationship
MATCH (user:User), (u:URL)
WHERE user.userid = '<user_id>' AND u.url = '<url>'
CREATE (user)-[uu:USED_URL]->(u)
RETURN type(uu)
// Create User MENTIONED User relationship
MATCH (u0:User), (u1:User)
WHERE u0.userid = '<user_id>' AND u1.userid = '<user_id>'
CREATE (u0)-[mnt:MENTIONED]->(u1)
RETURN type(mnt)
请记住,根据数据的大小和计算机规格,上面列出的查询可能需要一些时间来完成,所以要有耐心,如果看到需要的时间太长,建议先尝试加载一个小的数据样本,以确保在建立整个数据库之前一切正常工作。
运行这些命令后,终于准备好图形数据库,可以开始探索数据了。可以在下图中看到图形的可视化示例:
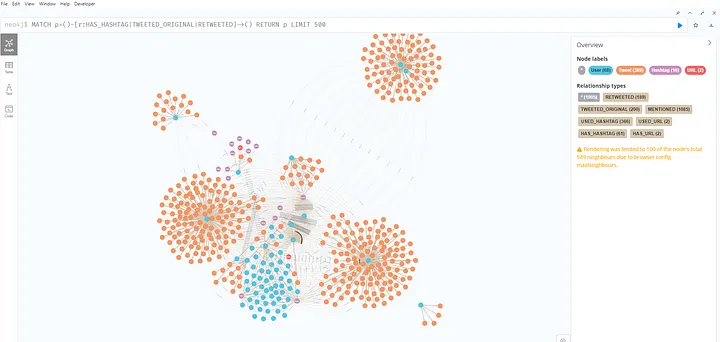
可以用不同的颜色看到在图形模型中的不同节点,以及不同的关系(选择对所有节点使用相同的颜色以使图片更清晰,但如果想要改变,可以通过点击右侧功能区上的关系选择更改它)。
现在准备好通过Neo4j使用不同的查询来探索数据。
推荐书单

《Python数据分析从入门到精通》
《Python数据分析从入门到精通》全面介绍了使用Python进行数据分析所必需的各项知识。全书共分为14章,包括了解数据分析、搭建Python数据分析环境、Pandas统计分析、Matplotlib可视化数据分析图表、Seaborn可视化数据分析图表、第三方可视化数据分析图表Pyecharts、图解数组计算模块NumPy、数据统计分析案例、机器学习库Scikit-Learn、注册用户分析(MySQL版)、电商销售数据分析与预测、二手房房价分析与预测,以及客户价值分析。
该书所有示例、案例和实战项目都提供源码,另外该书的服务网站提供了模块库、案例库、题库、素材库、答疑服务,力求为读者打造一本“基础入门+应用开发+项目实战”一体化的Python数据分析图书。
《Python数据分析从入门到精通》内容详尽,图文丰富,非常适合作为数据分析人员的学习参考用书,也可作为想拓展数据分析技能的普通职场人员和Python开发人员学习参考用书。
购买链接:https://item.jd.com/13288736.html


