排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
L-FBF:用于键值存储的学习型功能Bloom过滤器
L-FBF:用于键值存储的学习型功能Bloom过滤器
时空实验室
2023-03-06
188
用学习模型来替代传统数据结构是一种具有挑战性的尝试,论文提出了一种用于键值存储的学习型功能
Bloom
过滤器(
L-FBF
)。在
L-FBF
中,学习模型学习给定数据的特征和分布,并对每个输入进行分类。理论分析表明,在相同的内存大小下,
L-FBF
比单个
FBF
的搜索失败率更低,同时提供了相同的语义保证。本次为大家带来的论文:《
Learned FBF: Learning-Based Functional Bloom Filter for Key–Value Storage
》
一.背景
最近的研究表明,与传统的数据结构相比,使用学习模型的新数据结构具有显著的优势。
Bloom
过滤器(
BF
)是用来指示一个输入是否是给定集合中的一个元素的传统二值分类数据结构,在给定的假阳性率下,学习型的
BF
比单个
BF
使用更少的内存,因此,基于学习的结构能够在内存需求和搜索失败方面提高性能。而键值数据结构返回一个键对应的值,高效的键值存储可以在有限的内存中存储大量数据,同时提供更好的性能。
论文认为学习模型可以取代键值存储的操作,同时提高搜索性能并节省内存。此外基于学习的方法通过利用精确单位数据分布信息来优化各种数据结构。但学习型
Bloom
过滤器只能解决存储成员关系信息的二分类任务,因此不用于键值数据结构。功能
Bloom
过滤器(
FBF
)作为
Bloom
过滤器的变体之一可以用作键值结构。
FBF
具有期望的特征,即它不会给插入的元素返回错误的值和不会产生假阴性。然而,它可能会返回假阳性和不确定的结果,从而导致搜索失败。
论文提出了
L-FBF
,一种学习型的功能
Bloom
过滤器,该模型可以应用于多分类任务。由于学习模型可能会产生假阴性或者错误分类的问题,所以论文提出的
L-FBF
由一个学习模型和两个小型的备份结构(假类结果
Bloom
过滤器(
FR-BF
)和一个验证功能
Bloom
过滤器(
V-FBF
))组成,以期望可以到达和
FBF
相同的效果。论文所提出的
L-FBF
结构有两个优点。首先是对于给定的内存大小,
L-FBF
通过在模型中添加
FR-BF
和
V-FBF
等辅助结构来达到比单一
FBF
更好的分类精度。此外,由于
L-FBF
的内存需求相当小且和数据大小无关,所以它对于大规模的数据更有效。
二.学习型功能
Bloom
过滤器
2.1
模型框架
通过将
FBF
的核心部分替换为一个学习模型,论文提出了一个学习型功能
Bloom
过滤器(
L-FBF
)来解决多分类问题,这是一种利用学习模型进行键值存储的高级
FBF
结构。但由于学习模型可能返回错误的分类结果或产生假阴性,因此构建
L-FBF
是具有挑战性的。
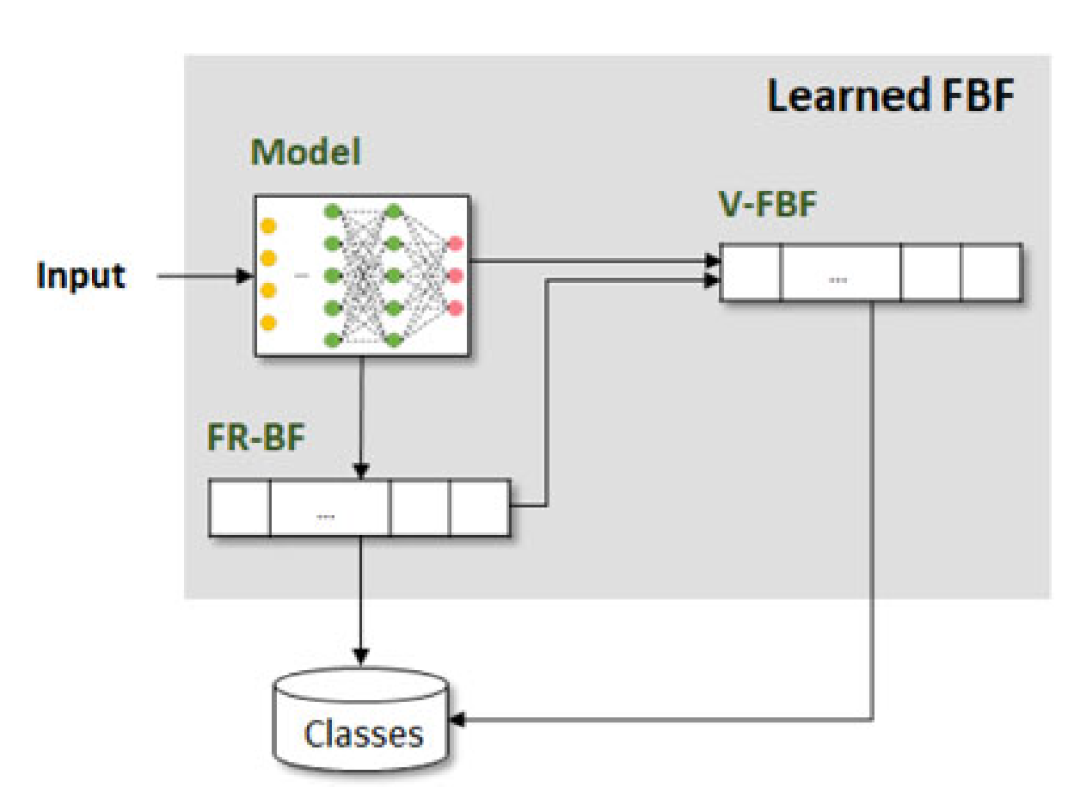
图
1
显示了所提出的学习型功能
Bloom
过滤器结构,它包括一个学习模型和两个小的附加结构:一个假类结果
Bloom
过滤器(
FR-BF
)和一个验证功能
Bloom
过滤器(
V-FBF
)
图
1
总体框架图
2.2
学习模型
FBF
可以被视为将每个输入分类为一个类的模型。换句话说,一个神经网络(
NN
)可以被用来取代一个
FBF
的核心部分。因为一个
FBF
有两个搜索失败的原因:假阳性和不确定性,当构建使用模型的
L-FBF
结构时,其主要目标是最小化搜索失败的概率。
当使用学习模型替代
FBF
时,该模型必须能够将属于集合
S
的元素和集外元素(属于
S
c
)
区分开来,并将
S
中的元素分类到
S
q
,
1
≤
q
≤
Q
(
Q
是
S
中元素的类别数目),假设可以观察到每个类中元素的特定分布,并且
S
c
中包含的未来输入与测试集中的集外元素的分布相同,那么可以通过学习一个期望的哈希函数来构建一个
FBF
的模型。在这里,所需的哈希函数需要降低元素和集外元素之间哈希冲突以及不同类中的元素之间的哈希冲突。该函数可以在每个类中的元素之间或者集外元素之间有许多哈希冲突。
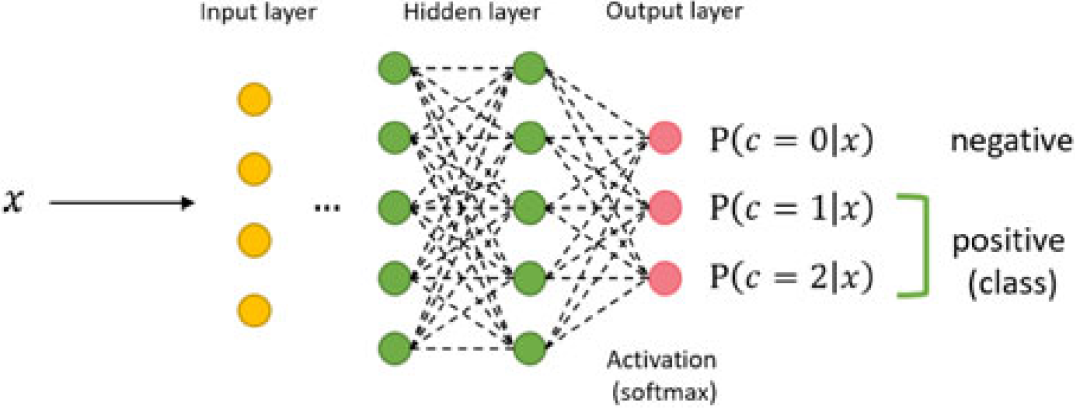
图
2
展示了一个用于多分类问题的神经网络,它使用分类交叉熵作为损失函数,
softmax
作为输出层的激活函数,输出的结果可以视为属于该类别的概率。其中集外元素也作为一类(负类),集合中的元素称为正类。因此类别总数为
Q
+1
。类别
0
代表集外元素,
Q
是集合
S
中元素的类别数目。在图
2
中有两个正类。
图
2
多分类的神经网络
为了保证不会产生假阴性或错误分类结果,论文在学习模型中分别添加了一个
V-FBF
和一个
FR-BF
。
2.3 V-FBF
与
FR-BF
V-FBF
是根据从模型中返回的假阴性元素构建的。
FR-BF
用于指示一个正类输入是否被错误地分类,因此,
FR-BF
根据从模型中返回的具有错误结果的元素进行构建。具有错误结果的元素的返回给
V-FBF
,因此,
V-FBF
是由从模型中返回的假阴性元素和被错误分类的元素来的。此外,由于
FR-BF
的假阳性元素属于模型返回的真实类之一,
V-FBF
也由
FR-BF
返回的假阳性元素构建,以返回它们的实际类。
在该结构中,阈值τ被用来控制假阳率(
FPR
)。模型的输出可以被写为一个向量
o
=(
o
0
,
o
1
.....
o
Q
)
,其中
o
0
是输入
x
被分类到
S
c
的概率(负类),
o
q
是被分类到
S
q
的概率
,
,模型使用最大概率值
o
i
作为预测的分类结果。然而如果最大概率值并没有和其他概率值有很大的差别,预测结果可能是不正确的。因此为了处理错误结果,尤其是控制假阳率,论文使用了阈值τ。当最大概率值
o
i
大于等于τ时,返回类别
i
作为预测结果,否则,模型返回一个阴性结果。如果是假阴性,则可以被
V-FBF
纠正。为了降低
FPR
,应该设置一个较大的τ,这可能会导致模型出现更多的假阴性。
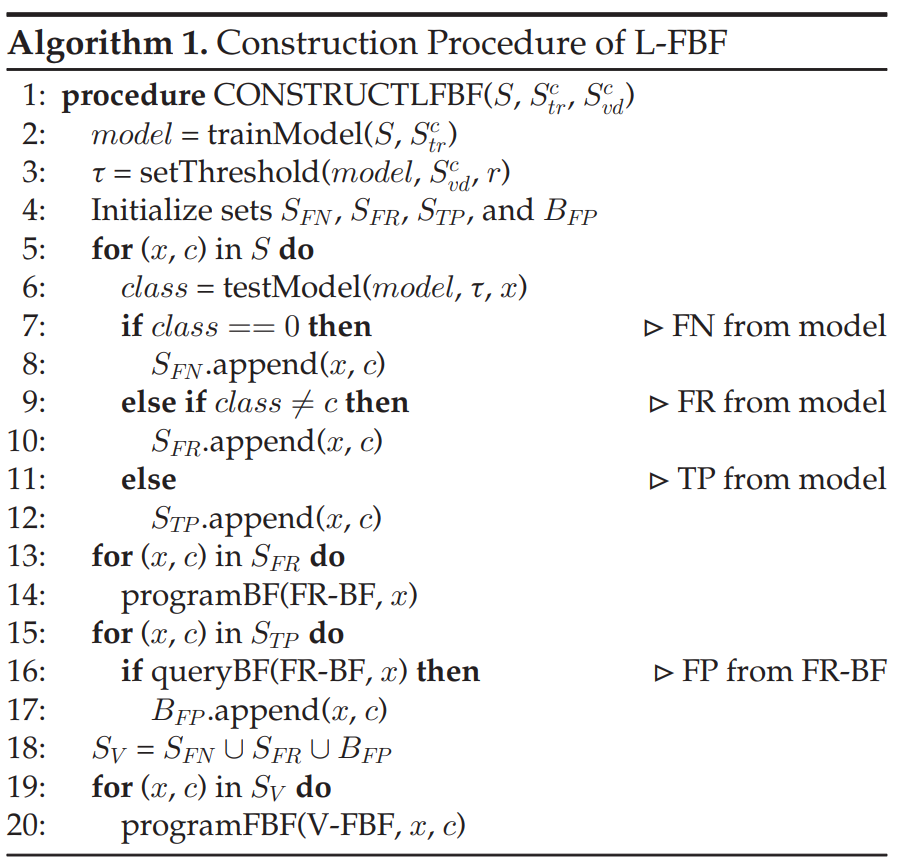
算法
1
展示了
L-FBF
结构的构造过程。首先针对给定的数据集
S
和
S
c
tr
(第
2
行)训练一个模型。
S
c
tr
是训练用的
S
c
的一个子集。模型的阈值τ是根据
S
c
vd
(是用于验证的
S
c
的一个子集)为所需的
FPR (r)
设置的。
FR-BF
是通过
S
FR
(
FR
表示模型预测了一个不正确的正类且预测的类的概率大于或等于τ)中的元素构建的。
V-FBF
由
S
V
中的元素构建,其中
S
V =
S
FR
∪
S
FN
∪
B
FP
,
其中,
FN
表对于
S
中的一个正类元素模型预测了一个负类或模型输出的最大概率小于τ,
B
FP
存放的是
FR-BF
中的元素。
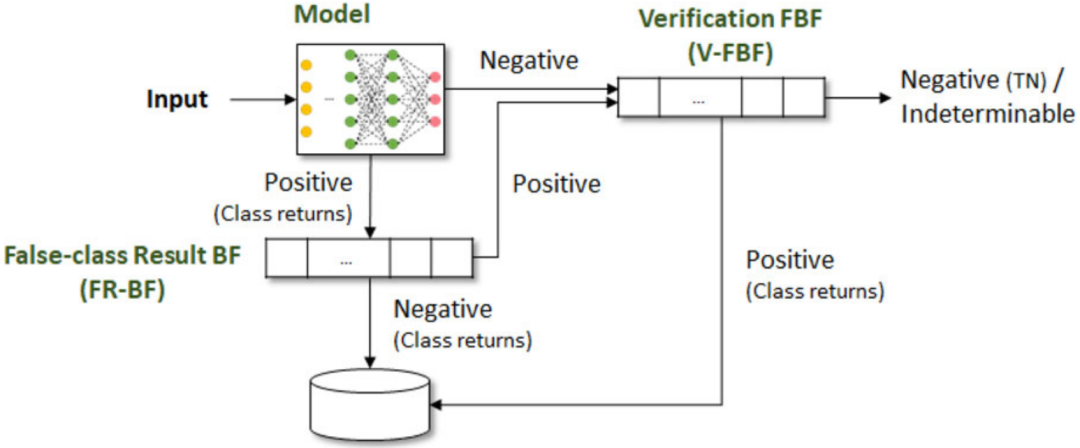
图
3
说明了
L-FBF
的搜索过程。给定一个输入
y
,首先使用模型进行预测。如果模型返回一个负类,则查询
V-FBF
以确保没有假阴性,然后将
V-FBF
的结果作为预测类返回。如果模型返回预测类别
q
,则查询
FR-BF
来过滤错误分类结果。如果
FR-BF
返回一个正值,这意味着从模型返回的类是错误的,则查询
V-FBF
,然后将
V-FBF
的结果作为一个预测类别返回。否则,如果
FR-BF
返回一个负值,这意味着从模型返回的类是正确的,那么类
q
将作为预测结果返回。
图
3
学习型功能
Bloom
过滤器的搜索过程
三.实验
由于论文的目的是用
L-FBF
代替
FBF
来提高性能,因此论文对所提出的
L-FBF
的性能进行了评估,并与单一
FBF
进行了比较。论文的实验数据集来自公开的数据集。对于正类集合,使用来自
Curlie
的集合,这是为社区提供识别和分类其最佳内容的一个最大的人工编辑
Web
目录。正类集合包括
485,423
个两个类别的独特的白名单
URLs
。对于负类集,则使用来自
Shalla
的黑名单,这是一个公开的第三方黑名单资源。负数据集由
1,491,178
个独特的黑名单
URLs
组成。负集被随机分割以进行训练(
81%
)、验证(
9%
)和测试(
10%
)。因此,训练集包含所有的正类和
81%
的负类,测试集包含所有的正类和
10%
的负类(即在训练中或在验证中都不使用负类)。
假设学习模型的期望假阳性率(
FPR
)为
0.005
,并在模型训练后使用验证集设置
FPR
的阈值τ。在使用测试集测试
L-FBF
结构时,不确定性同时通过正输入和负输入报告,而假阳性仅通过负输入报告。
由于
URLs
是字符序列,
RNNs
能够对依赖时间和顺序的数据任务进行建模,因此论文首先考虑
RNNs
。然而,
RNNs
存在梯度消失的问题,这阻碍了对长数据序列的学习。门控循环单元(
GRU
)和长短期记忆(
LSTM
)是解决标准
RNN
中消失梯度问题的
RNNs
。
GRU
可以被认为是
LSTM
的一种变体。
LSTM
使用输入门、输出门和忘记门,而
GRU
使用更新门和复位门,这是两个向量,决定哪些信息应该传递给输出。
GRU
和
LSTM
的设计相似,效果很好,但
GRU
的参数比
LSTM
少。由于
URLs
在同一分量中的特征之间具有很高的相关性,而一维(
1D
)
CNN
对于从数据集的固定长度片段中提取特征非常有效,因此论文的实验还考虑了
1D-CNN
。
3.1
内存消耗
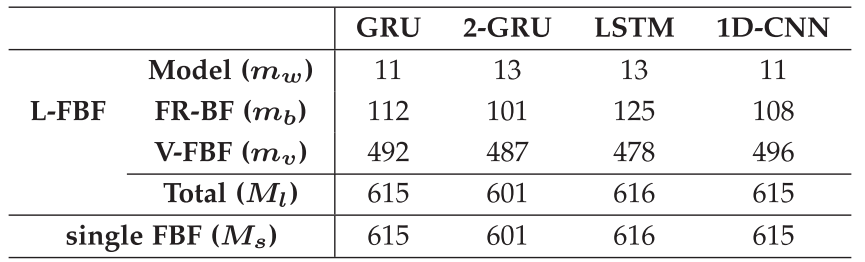
表
1
显示了各模型特征的比较。设
n
w
表示模型中的权值个数,
t
为包含单个
GRU
层的模型的相对训练时间。包含两个
GRU
层(
2- GRU
)的模型由于有两个
RNN
层,其权重数最大。包含单个
1D-CNN
层的模型的训练时间最短,因为
CNN
的训练时间通常比
RNN
(即
GRU
和
LSTM
)要短。
CNN
的精度迅速提高,然后趋于稳定,而
RNN
的准确性在更长的训练迭代中继续略有提高。
表
1
各模型的特征比较
L-FBF
结构的内存需求是一个学习模型、一个
FR-BF
和一个
V-FBF
的内存需求的总和。用
m
w
表示模型所需的内存,
m
b
表示
FR-BF
中的神经元数量,
m
v
表示
V-FBF
中的神经元数量,
l
表示
V-FBF
的神经元中的比特数。
L-FBF
结构的总内存需求(
M
l
)如下:
M
l =
m
w +
m
b +
m
v
l
表
2
对比了
L-FBF
结构和单个
FBF
的内存需求。
表
2 L-FBF
和单个
FBF
的内存需求(
KB
)
3.2
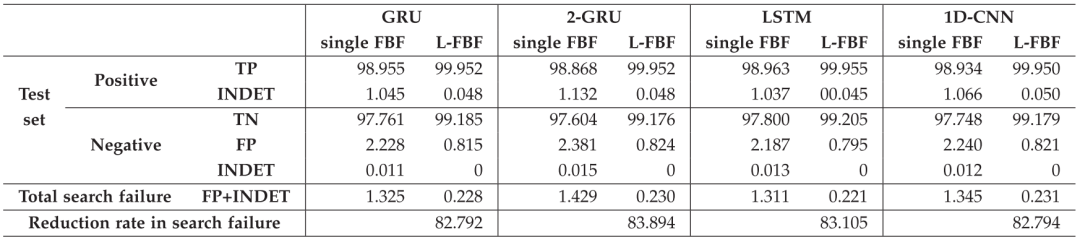
搜索失败率
表
3
展示了单个
FBF
和基于不同模型的
L-FBF
结构之间的搜索失败率(
SFRs
)的比较。减少率是通过减少的搜索失败的次数(即单个
FBF
的搜索失败的次数减去
L-FBF
的搜索失败的次数)和单个
FBF
的搜索失败的次数来计算的。如图所示,与单一的
FBF
相比,所提出的
LFBF
结构减少了
82.792%
和
83.894%
的搜索失败。该模型并不会较大地受元素数量的影响,而且每个
L-FBF
中模型的内存需求相当小,与数据大小无关。因此,随着数据大小的增加,
L-FBF
比单一的
FBF
更有效。即使随机数据包含在负集中,因为负类数据既不存储在
V-FBF
中,也不存储在
FR-BF
中,所以
L-FBF
也会返回具有相同的假阳性概率的结果。
表
4
单一
FBF
和基于不同模型的
L-FBF
之间搜索失败率的比较(
%
)
四.总结
论文提出了一种学习型功能
Bloom
过滤器结构,用学习的模型替换
FBF
的核心部分,以提高
FBF
的搜索性能。所提出的
L-FBF
由一个学习模型、假类结果
Bloom
过滤器(
FR-BF
)和一个验证功能
Bloom
过滤器(
V-FBF
)组成,以提供与
FBF
相同的语义保证。实验结果表明,与使用相同内存的
FBF
相比,
L-FBF
结构减少了
82.792% 83.894%
的搜索失败概率。此外,如果有一个更准确的模型,
L-FBF
的内存需求还会减少。
-End-
本文作者
孙莹莹
重庆大学计算机科学与技术专业大三在读学生,重庆大学START团队成员。
主要研究方向:时空数据管理
时空艺术团队
(
START,Spatio-Temporal Art
)来自重庆大学时空实验室,旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有2~3名研究生名额,欢迎
计算机、GIS
等相关专业的学生报考!
概率计算
分类数据
预测模型
文章转载自
时空实验室
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨