





高瑞冬,中国移动磐基PaaS平台中间件专业服务项目资深顾问,专注于云原生等领域产品研发。
| 1. 前言 |
nfs是广泛使用的网络化存储服务,用户基础大,技术成熟,具有操作知识的工程师很多。但是,在云原生和分布式存储的角度看,原生的nfs存储服务不能提供存储高可用能力,然而存储高可用能力是云原生的普遍需求。
本文探索通过ceph为nfs服务提供存储的高可用的可行方案。ceph存储结合nfs-ganesha服务,为nfs客户端提供了基于ceph对象存储的nfs协议输出。ceph提供的存储类型丰富,包括RBD,cephfs,RGW,能够有效满足不同业务场景的需求。本文给出了提供cephfs和RGW两种后端存储机制的nfs集成方案。期望nfs的众多用户可以在云原生环境中继续安心使用熟悉的nfs挂载提供存储能力,而同时获得了ceph存储提供的多副本或者纠删码的高可用特性,满足云原生环境对业务运行的新需求。
本文尝试通过rook(1.10.11)管理的ceph(17.2.5)创建nfs导出,为nfs用户提供一种新的选择和参考。
| 2. 准备cephfs后端存储 |
2.1 cephfs的一些准备性知识
Volume
Volume是cephfs文件系统的一个抽象。在这个层面可以指定存储使用的ceph池,从而指定是使用多副本还是纠错码作为数据高可用的提供者。每个volume会有独立的metadata server为其提供目录等元数据服务。
首先我们通过rook提供的如下yaml创建一个三副本的cephfs(ceph文件系统):
使用rook提供的krew插件 rook-ceph命令,可以ceph命令行的形式直接操作k8s中的ceph集群,如同ceph的主机化部署一样。如下命令用来查看上面新文件系统对应的ceph存储池是否已经创建:
kubectl rook-ceph ceph osd pool ls | grep cephfs4nfs cephfs4nfs-metadata cephfs4nfs-replicated |
可以看到为新文件系统已经创建两个存储池:
用于存储元数据:cephfs4nfs-metadata
用于存储数据:cephfs4nfs-replicated
2.3 创建cephfs上的nfs导出目录
目前需要使用ceph原生命令查看创建出来的ceph文件系统。工程上一般不会把整个cephfs volume做nfs导出,那么在新创建的cephfs volume上创建一个subvolumegroup常常是很有必要的,subvolumegroup对应的是ceph文件系统的目录。以此便于控制nfs导出访问权限,容量,专门用于nfs挂载。以下命令创建了空间配额为204800KB的subvolumegroup:
| kubectl rook-ceph ceph fs subvolumegroup create cephfs4nfs nfsexport --size 204800 |
需要查看并记录创建的这个subvolumegroup的绝对路径,这个路径在创建nfs export时候需要用到:
kubectl rook-ceph ceph fs subvolumegroup getpath cephfs4nfs nfsexport /volumes/nfsexport |
| 3. 准备RGW后端存储 |
为了提供nfs导出的RGW后端存储,我们需要在ceph中创建一个存储对象桶(bucket),通过nfs读写的业务数据将存储在这个桶的对象中。
创建对象桶可以通过s3客户端完成,这里我们使用ceph的仪表盘可视化的完成这个操作。通过浏览器打开仪表盘,在左侧菜单栏中选择Object Gateway/Buckets,打开对象桶的管理页面。

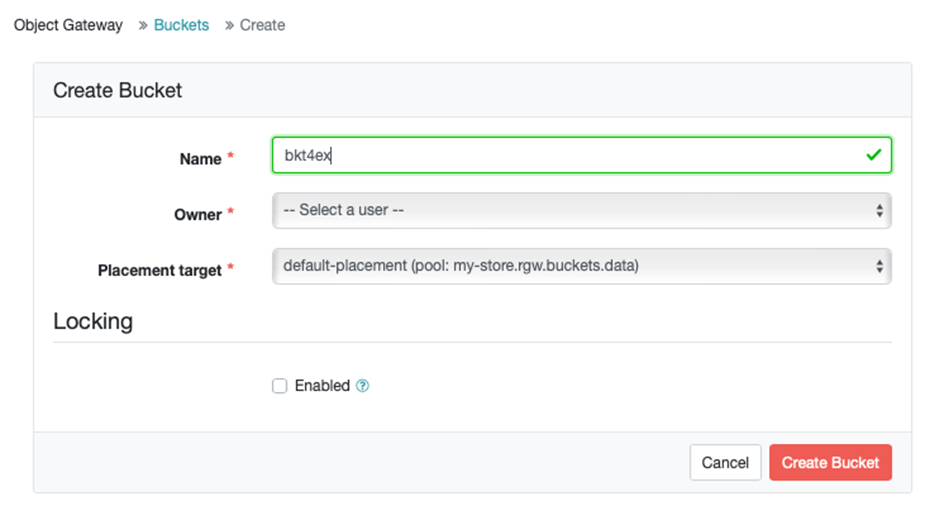
这个对象桶将在后面创建nfs rgw导出时使用。
| 4. 创建ganesha-nfs服务提供nfs导出 |
然后我们通过rook提供的cephnfs模版创建一个nfs集群。这一步将在k8s上启动一个基于ganesha-nfs的服务。
apiVersion: ceph.rook.io/v1 kind: CephNFS metadata: name: nfs-cluster namespace: rook-ceph spec: server: active: 1 logLevel: NIV_INFO |
稍后会有pod启动,正是pod中运行的这个服务提供nfs导出到ceph存储的转换服务。
运行kubectl rook-ceph ceph nfs cluster ls
nfs-cluster nfs4cephfs nfs4rgw |
可以看到新的nfs集群nfs-cluster已经创建出来了。
为了挂载nfs导出,需要查看和记录nfs-ganesha服务nfs-cluster所在的ip。下面输出的结果显示nfs服务ip地址是169.169.165.85。
kubectl get svc -n rook-ceph| grep nfs-cluster rook-ceph-nfs-nfs-cluster-a ClusterIP 169.169.165.85 <none> 2049/TCP 9m29s |
| 5. 创建nfs导出 |
nfs-ganesha服务已经就绪,需要的信息也已经搜集和记录。这样我们就可以根据需要创建nfs导出了。目前ceph支持使用cephfs和rgw作为存储后端。
下面是在ceph系统内部创建一个基于cephfs的nfs导出,挂载到cephfs4nfs文件系统的目录/volumes/nfsexport下。这个目录是在前面2.3节中准备好的。运行如下命令:
kubectl rook-ceph ceph nfs export create cephfs nfs-cluster /fsexport cephfs4nfs /volumes/nfsexport { "bind": "/fsexport", "fs": "cephfs4nfs", "path": "/volumes/nfsexport", "cluster": "nfs-cluster", "mode": "RW" } |
nfs导出创建成功。在可以访问此服务的主机环境下,运行如下命令挂载nfs存储:
| mount -t nfs -o port=2049,nfsvers=4.1,noauto,soft,sync,proto=tcp 169.169.165.85:/fsexport /mnt/mountpoint/cephfs |
这样挂载成功以后,就可以通过目录/mnt/mountpoint/cephfs使用这个数据高可用的存储了。
5.2 创建rgw导出
使用对象存储提供nfs的底层支持有一定的优势。首先是对象存储具有比cephfs更加简洁的技术堆栈,数据的读写效率比较高。其次对象存储同样的具有ceph的数据高可用特性。这无疑为nfs的老铁用户带来了无缝升级nfs却又接口无忧的一个技术方案。
不过这部分功能目前还处于初期。其中存在一个bug导致rgw导出创建以后,ganesha-nfs服务循环重启。这个问题得到社区的反馈和关注,已经有一个PR正在提交解决中:
lhttps://github.com/rook/rook/pull/11598
在这个修复合并到master前,我们可以通过如下步骤绕过这个问题:
创建配置文件rgw.conf,内容如下:
RGW { name = "client.nfs-ganesha.nfs-cluster.a"; } |
运行如下命令,设置nfs-cluster服务的用户定义配置:
| ceph nfs cluster config set nfs-cluster -i ./rgw.conf |
设置完成以后需要重启nfs-ganesha服务。
爬过了这个坑,我们就可以开始创建rgw nfs导出了。
使用第3节中准备的RGW存储桶,可以借助nfs-ganesha服务在存储桶bkt4exp上完成nfs export的创建。运行如下命令:
| ceph nfs export create rgw --cluster-id nfs-cluster --pseudo-path /rgwexport --bucket bkt4exp |
在可以访问此服务的主机环境下,使用和cephfs导出相同的nfs-ganesha服务完成挂载:
| mount -t nfs -o port=2049,nfsvers=4.1,noauto,soft,sync,proto=tcp 169.169.165.85:/rgwexport /mnt/mountpoint/rgw |
这样挂载成功以后,就可以通过目录/mnt/mountpoint/rgw使用这个数据高可用的存储了。
| 6. 总结 |
目前存在的其他的类似方案一般是非云原生环境的主机化部署,往往需要繁复的ceph命令行操作,对技术栈中各个组件需要单独的修改配置文件。通过rook管理ceph集群,同样的ceph nfs导出配置过程得到很大的简化。一方面体现了声明式编程的强大力量。另一方面也能够看到operator sdk为复杂系统的运维知识的封装提供了完美的支撑。
至此我们走了一遍基于cephfs和rgw的nfs导出和挂载过程。rook这方面的相关资料比较少,本文给出了完整的实施步骤,相信对云原生环境下小伙伴们深入使用nfs存储能够有所帮助。虽然目前RGW导出功能还处于试验阶段。不过通过cephfs的导出的nfs还是很值得在实际环境中考虑使用的。
另外的一个场景是nfs导出服务(nfs-ganesha)的高可用。目前社区还在讨论和开发中,相信通过开源社区的协同努力,这方面的需求在不久的将来也能够得到很好的满足。
