




国外 AI 真的赢麻了!!!
Google Bard
原文:Try Bard and share your feedback[1]
官网:Bard[2]

2023 年 3 月 21 日,谷歌推出了一个名为 Bard 的早期试验,它使用生成式人工智能来协助用户提高生产力、加速想法的实现和满足好奇心。Bard 可以为用户提供各种服务,如给出建议、解释科学概念或者激发创造力。
Bard 试验目前仅限于美国和英国,但未来将扩展到更多的国家和语言。Bard 的目标是帮助人们更高效地处理任务,它是谷歌继去年推出 Lamda 之后又一个 AI 试验。这一次,Bard 的目标是为用户提供一个与人工智能协作的平台,以支持用户在各种领域中的工作和学习。
Bard 由一个研究型大型语言模型(LLM)驱动,是 LaMDA[3] 的轻量级和优化版本,随着时间的推移更新为更新、更强大的模型(简单来说:是将用户的问题转化为自然语言形式,然后使用生成式人工智能来生成回答或提供解决方案)。它基于谷歌对高质量信息的理解。可以将 LLM 视为预测引擎。当给定提示时,它会逐个选择从可能出现的单词中选择来生成响应。每次选择最有可能的选择不会导致非常创造性的响应,因此需要一定的灵活性。当我们使用越多,LLM 的预测效果也会变得越好。虽然 LLM 是令人兴奋的技术,但它们并非没有缺陷。例如,因为它们学习的信息范围广泛,反映了现实世界的偏见和刻板印象,这些偏见有时会在它们的输出中出现。它们可能会提供不准确、误导性或错误的信息,同时表现得很自信。了解更多 An overview of Bard: an early experiment with generative AI[4]。
有人在 Hacker News 上预测一年后 Google 会关闭 Bard($today + 1 year: "Google shuts down Bard, its AI chatbot"[5]),你认为呢?
NVIDIA AI 云工具
原文:NVIDIA and Google Cloud Deliver Powerful New Generative AI Platform, Built on the New L4 GPU and Vertex AI[6]

英伟达和谷歌云在新的 L4 GPU 和 Vertex AI 上构建了强大的生成式 AI 平台,将深度学习和机器学习技术应用于自然语言处理、计算机视觉和其他领域。
2023 年 3 月21,谷歌云宣布 G2 虚拟机[7]在私人预览中可用,是第一个提供 NVIDIA L4 Tensor Core GPU[8] 的云服务提供商。此外,L4 GPU 将在 Vertex AI 上提供优化支持,该平台现在支持构建、调整和部署大型生成式 AI 模型。开发人员可以访问最新的技术,以帮助他们快速、经济高效地启动新应用程序。NVIDIA L4 GPU 是一种适用于所有工作负载的通用 GPU,具有增强的 AI 视频功能,可提供比 CPU 高 120 倍的 AI 视频性能,同时具有 99% 的更高能效。
WOMBO 首席执行官 Ben-Zion Benkhin 表示:“WOMBO 依靠最新的人工智能技术,让人们根据用户的提示创建身临其境的数字艺术作品,让他们只需一个想法就可以创作出任何风格的高质量、逼真的艺术作品。” “NVIDIA 的 L4 推理平台将使我们能够为寻求创造和分享独特艺术作品的用户提供更好、更高效的图像生成体验。”
谷歌云基础设施,为生成式 AI 应用程序提供了支持,来帮助他们更好、更快地完成工作。目前可以填表申请(原文有申请链接)。
Adobe Firefly
原文:Adobe Unveils Firefly, a Family of new Creative Generative AI[9]
官网:Adobe Firefly[10]
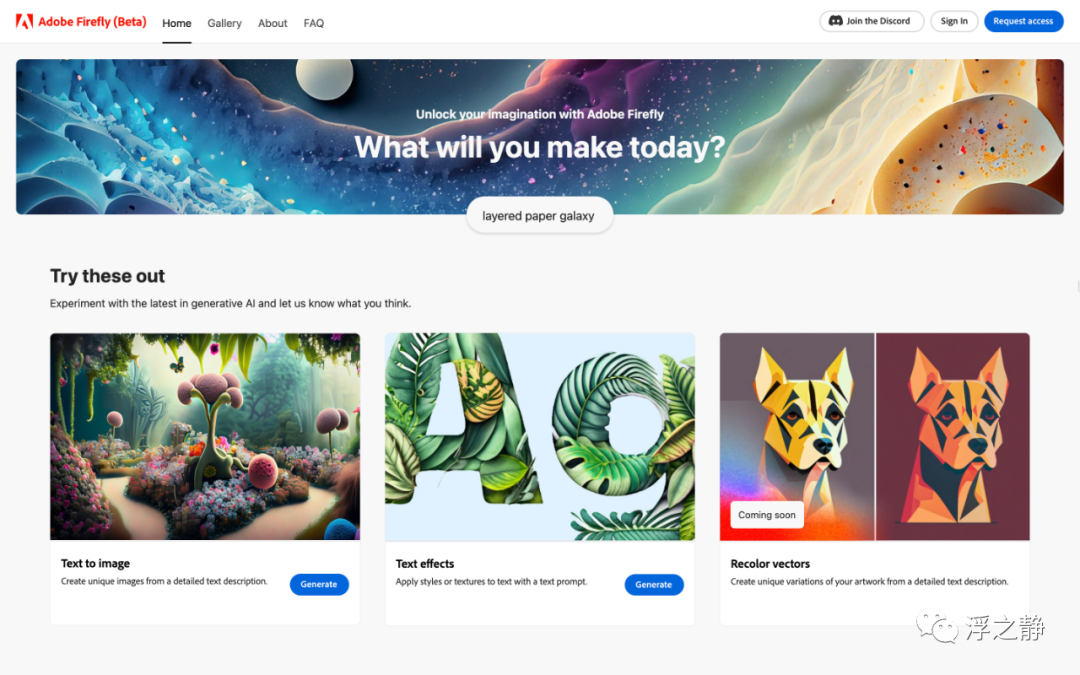
Adobe 推出了全新的创意生成 AI 模型 Adobe Firefly,首先聚焦于生成图像和文本效果。Firefly 将直接集成到 Creative Cloud、Document Cloud、Experience Cloud 和 Adobe Express 工作流程中,为内容创建和修改带来更高的精度、功率、速度和易用性。Firefly 是 Adobe Sensei 生成 AI 服务系列的一部分。
Firefly 的推出是 Adobe 在人工智能创新方面超过十年的历史的延续,将更多的智能功能带入到数以亿计的用户依赖的应用程序中。这些创新的功能使 Adobe 的客户能够以更高的能力、精度、速度和易用性创建、编辑、衡量、优化和审查数十亿个内容。这些创新功能是在符合 Adobe 的 AI 伦理原则——问责、责任和透明——的前提下开发和部署的。
Adobe 总裁 David Wadhwani 表示,“生成 AI 是 AI 驱动的创造力和生产力的下一个发展阶段,将创作者与计算机之间的对话转化为更自然、直观和强大的形式。通过 Firefly,Adobe 将直接将生成 AI 驱动的'创意元素'带入客户的工作流程中,从高端创意专业人士到创作者经济的长尾,提高了所有创作者的生产力和创造性表达能力。”此外,Adobe 还计划推出 “Do Not Train” 标签,供不想让其内容用于模型训练的创作者使用。
Firefly 旨在赋予所有创作者超能力,以实现他们的想象。使用它,无论经验或技能如何,每个创作者都可以使用自己的话语以前所未有的速度和轻松程度生成内容,包括图像、音频、向量、视频和 3D,以及创意元素,如画笔、颜色渐变和视频转换等。创作者可以在品牌范围内快速简单地制作各种变化和修改。
加入测试体验 Meet Adobe Firefly[11]。
Bing Image Creator
原文:Create images with your words – Bing Image Creator comes to the new Bing[12]
官网:Bing Image Creator[13]
上个月,微软推出了基于人工智能的 New Bing 和 Edge 浏览器,提供更好的搜索和聊天体验。聊天正在重新定义人们的搜索方式,截至目前,微软统计到已有超过 1 亿次的聊天记录。人们以各种方式使用聊天,从细化复杂问题的答案到作为娱乐形式或创意灵感的来源。现在,微软要将聊天体验提升到更高的层次,使 New Bing 可视化。
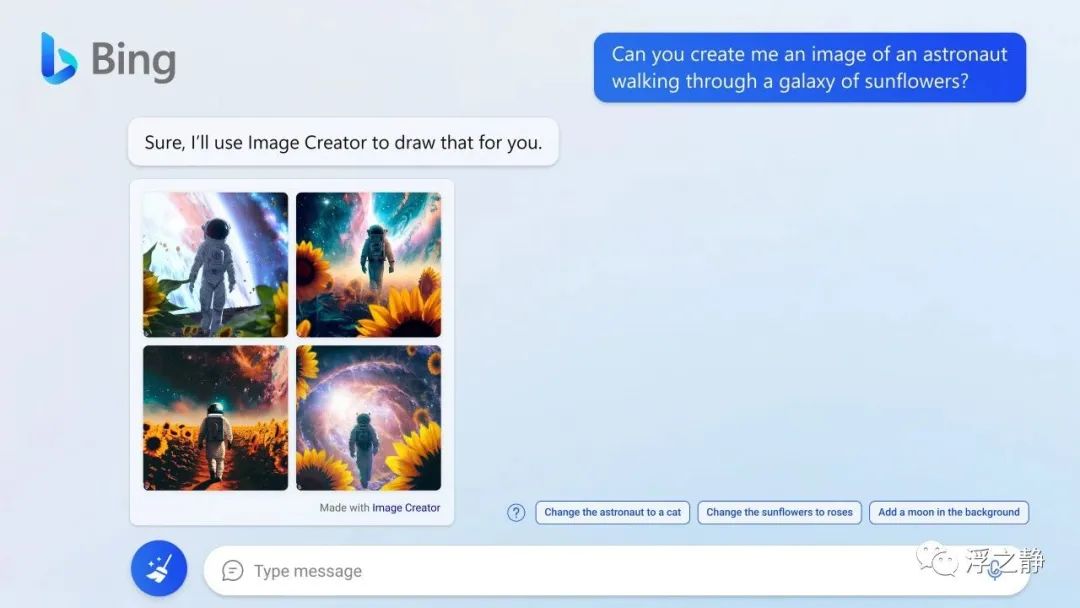
在新版必应和 Edge 预览版中推出必应图像创作者、新的基于人工智能的视觉故事和更新的知识卡片。必应图像创作者由微软合作伙伴 OpenAI 提供的 DALL∙E 模型的高级版本驱动,使你只需用自己的话描述想看到的图片,就可以创建出一幅图片。现在,你可以在聊天中生成文字和图片内容,而且只需在一个地方即可。
研究表明,人脑对视觉信息的处理速度大约比文本快 60,000 倍,因此视觉工具是人们搜索、创建和获得理解的重要途径。根据必应的数据,图像是搜索量最多的类别之一,仅次于一般的网络搜索。在历史上,搜索仅限于已经存在于网络上的图片。现在,你几乎可以搜索和创建任何东西。
Midjourney V5
官网:https://www.midjourney.com
备受期待的 Midjourney V5 现已发布,它有很多最新突破。在根据文本提示创建令人叹为观止的图像方面,一些人已经将其称为“逼真的奇迹世界”。不管你是否好奇,新训练的模型有望在语言理解、准确性和文体灵活性方面取得显著改善。
改进的连贯性,特别是涉及面部和肢体:Midjourney 社区最期待的改变之一就是不再有六指人了。在新模型中,你会注意到更少的混乱区块,因为它拥有更多处理肢体的知识。此外,V5 应该能更好地生成面部和眼睛的最细节部分。
以真实感为主要改进:V5 模型可以提供更为逼真的图像。事实上,如果你没有指定艺术风格、参考艺术家的名字或媒体来源,你将获得默认的系统设置,结果将完全逼真。新版本中的提示被设计成看起来像照片,所以,如果你需要更抽象或艺术的东西,建议调整措辞。调整 Midjourney 如何读取文本描述的另一个可能是在提示的末尾添加参数
stylize N
(其中 N 从 0(最小)到 1000(最大)变化)。数值越低,AI 的风格影响最终图片的程度就越小。这意味着,如果需要生成类似于文森特·梵高(Vincent van Gogh)的图像,可以尝试在描述文本中加入- stylize 1000
即可。更高的细节和改进的性能提示:除了一些担心外,新 Midjourney 模型声称的另一个特点是其增强的完整性。生成的艺术细节更有可能正确地呈现,而且 V5 对你的输入更加响应。创作者称此版本比 V3 和 V4 “产生更可控和可预测的结果”。但是,这种改进意味着使用可能会更加困难。简短的提示可能不再像以前那样有效。在 V5 中,开发人员建议编写句子而不是列表,并使用更明确的文本描述想要的内容。
更高的分辨率和其他纵横比:V5 提供了两倍的分辨率增加,现在可以生成高达 1024×1024 的图像。需要注意的是,“upscale” 按钮在此模型中的工作方式有所不同。使用 V5 获得的所有图像都处于最高质量状态,因此此按钮只是将预放大图像与网格分开。最终有生成 2048×2048 图片的可能。另一个更新包括更广泛的纵横比选项(以前不支持自定义)。在新模型中,可以创建更宽或更窄的画布尺寸,并尝试喜欢的任何纵横比。
图片权重:对于重新出现的图片权重功能,现在可以使用参数
iw N
增加其影响,其中 N 的范围从0.5-2.0
不等。
最后放几张 V5 生成的图片(源自网络):





References
Try Bard and share your feedback: https://blog.google/technology/ai/try-bard
[2]Bard: https://bard.google.com
[3]LaMDA: https://blog.google/technology/ai/lamda
[4]An overview of Bard: an early experiment with generative AI: https://ai.google/static/documents/google-about-bard.pdf
[5]$today + 1 year: "Google shuts down Bard, its AI chatbot": https://news.ycombinator.com/item?id=35246669
[6]NVIDIA and Google Cloud Deliver Powerful New Generative AI Platform, Built on the New L4 GPU and Vertex AI: https://nvidianews.nvidia.com/news/nvidia-and-google-cloud-deliver-powerful-new-generative-ai-platform-built-on-the-new-l4-gpu-and-vertex-ai
[7]G2 虚拟机: https://cloud.google.com/blog/products/compute/introducing-g2-vms-with-nvidia-l4-gpus
[8]NVIDIA L4 Tensor Core GPU: https://www.nvidia.com/en-us/data-center/l4
[9]Adobe Unveils Firefly, a Family of new Creative Generative AI: https://news.adobe.com/news/news-details/2023/Adobe-Unveils-Firefly-a-Family-of-new-Creative-Generative-AI/default.aspx
[10]Adobe Firefly: https://firefly.adobe.com/
[11]Meet Adobe Firefly: https://www.adobe.com/sensei/generative-ai/firefly.html
[12]Create images with your words – Bing Image Creator comes to the new Bing: https://blogs.microsoft.com/blog/2023/03/21/create-images-with-your-words-bing-image-creator-comes-to-the-new-bing
[13]Bing Image Creator: https://www.bing.com/create
