





基于源码梳理 openLooKeng 解析并执行传入的 SQL 语句的过程,执行流程:
提交查询 -> 生成查询计划 -> 查询调度 -> 查询执行
在解析语句生成查询计划时,主要的流程为:
语法/语义分析 -> 执行计划生成 -> 执行计划优化
语法/语义分析
1.1
语法分析
openLooKeng 的词法与语法分析模块 SQL Parser 是基于 ANTLR 实现的。通过输入词法描述文件来自动构造语法分析树,且生成基于 Visitor 模式的树遍历器。
Visitor 模式的工作方法为:对于由若干节点元素 Node 构成的语法树,每个 Node 都拥有一个 accept 方法来接受访问者对象 Visitor 的访问;Visitor 类是一个拥有 visit 方法的接口,对访问到的不同类型 Node 做出不同的反应。
在遍历语法树时,对遍历到的每个 Node 都调用 accept 方法,在每个元素的 accept 方法中回调 Visitor 的 visit 方法,从而使得 Visitor 得以处理树上的每个 Node。
openLooKeng 的词法分析在
io.prestosql.sql.parser.SqlParser 类的 invokeParser 方法中。使用词法分析器 SqlBaseLexer 进行词法分析,生成 token 序列:

接下来先生成抽象语法树,然后进入语法分析:

openLooKeng 使用 Visitor 模式进行语法分析。invokeParser 中的 new AstBuilder().visit(tree)经过多层调用进入 AstBuilder 中不同的 visitXXX 方法中;以 select 单列为例:

可以发现,visitSelectSingle 方法会构造一个 SingleColumn 对象,它包含 select 的表名和一个 Expression 对象,该对象也是通过 visit(context.)调用 AstBuilder 类中其他 visitXXX 方法得到的。因此语法分析实际上是一个递归调用过程,构造出若干节点并形成抽象语法树。一棵语法树实际上就是一个 Statement。
1.2
语义分析
查询语句在 openLooKeng 中经过词法语法分析后,生成抽象语法树 AST。io.prestosql.sql.analyzer.StatementAnalyzer 类,对传入的 SQL 语句,针对不同的 Statement 实现类进行语义分析。StatementAnalyzer 使用 Visitor 模式进行语义分析,类中的各个 visitXXX 方法针对不同的 Statement 实现类做了处理。以 visitQuery 方法为例:

visitQuery 首先分析 With 语句,然后对查询语句主体进行分析,最后对某些没有分析的 order by 语句进行分析,先检验 order by 所需的列是否在 select 语句中,然后考虑 order by 不是简单的列而是更复杂的语句时的情况,对其进行分析。
分析子语句时,每个 analyzeXXX 方法中表达式分析的入口都是 Visitor 子类中的 process 方法。表达式分析器主要获取表达式的类型、函数信息、列名与列编号及 in 语句子查询等。
1.3
分析查询主体语句
分析语句主体的入口在该类的 visitQuerySpecifiction 方法中。存储传入的查询语句的实现类是 io.prestosql.sql.tree.QuerySpecification,该方法将对各类子句分别进行分析。
select id, name from test where salary > 500 order by id;
获取传入的查询,经过词义与语义分析后每个子语句已经被分离出来:

以 seclect 子语句为例,词义分析的结果中 select 的 selectitems 即为提取出的列,analyzeSelect 方法返回的结果为 Expression 类型的 ImmutableList 列表 outputExpression,其中的每一个 Expression 表示 select 的一列。该方法遍历 select 中的每一列 item,根据列的类型进行分析。
如果列为*时,找到列描述符对应的 field,记录其对应的索引下标,存入 outputExpression 中:

如果列为单列,就使用表达式分析器对其进行分析,并将列表达式存入 outputExpression:

执行计划生成
在语义分析后,要根据针对 SQL 语句分析的结果,生成逻辑执行计划。与语义分析树 AST 类似,执行计划也会生成执行计划树,不同类型的节点对应不同种类的语句。
执行这项工作的是 io.prestosql.sql.planner.LogicalPlanner 类,
根据 SQL 语句的类型生成不同的执行计划,并选择对应的执行计划优化器进行优化。以上述 SQL 语句为例,查看 QueryPlanner 子类中对 QuerySpecifiction 的处理:
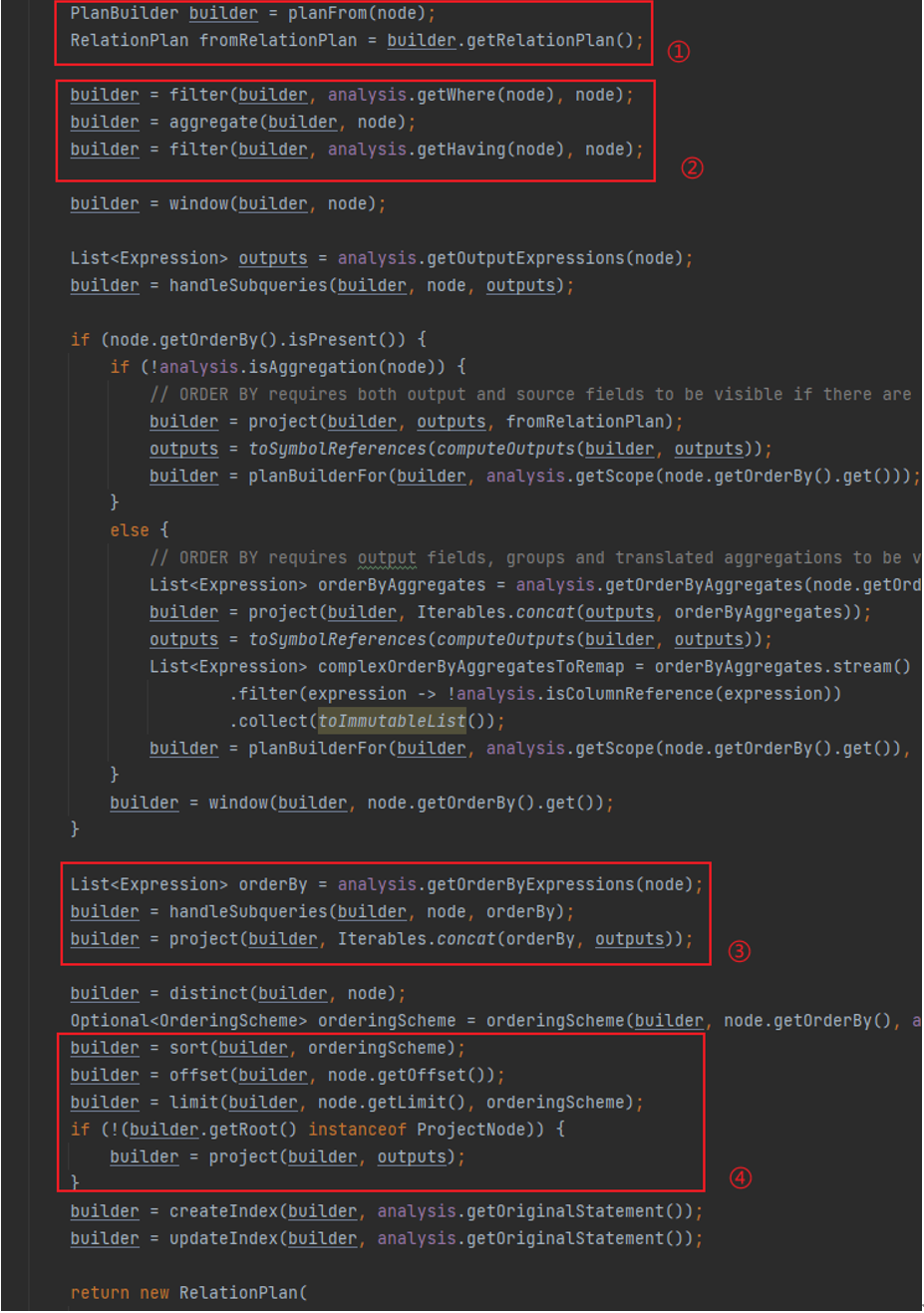
①:planFrom 处理 from 语句,使用 RelationPlanner 处理语句生成 Relation 执行计划。此处如果不存在 from 语句,说明输入的 SQL 语句是属于简单语句,直接构造 ValuesNode 返回。
②:FilterNode 是进行过滤操作的节点。此处 filter 为 where 条件添加一个 FilterNode,然后 aggregation 处理聚合操作,接着后面的 filter 再为 Having 语句添加一个 FilterNode。
③:ProjectNode 是用于列映射的节点,将该节点的下层节点(例如 TableScanNode)等输出的列映射到该节点的上层节点。此处 project 将 order by 等条件分析出的 Expression 列表进行传递。
④ :进行其他操作的处理,例如 SortNode 用于排序操作。
对于生成的初始查询计划,要对其进行优化。当查询计划需要优化时,遍历已有的所有 Optimizer,如果当前待优化的执行计划可以使用这个 Optimizer,就进行优化:

查看运行信息可发现,在优化过程中多次调用了 io.prestosql.sql.planner.iterative.IterativeOptimizer。
IterativeOptimizer 可以看作是在 PlanOptimizer 的基础上改进的。PlanOptimizer 中只有一个接口,输入一个 PlanNode 以及辅助参数,输出优化后的 PlanNode。这个接口实现一般都是实现一个使用 Visitor 设计模式的类,将多个优化策略杂糅到一个类中处理。
IterativeOptimizer 在 PlanOptimizer 上面又包装了一层,将每一条优化规则抽象出单独的类 Rule,这样在查询优化的时候只需要编写 Rule,不需要实现 Visitor 模式。
另一方面,IterativeOptimizer 为了执行计划优化的方便性及提高性能,在对 PlanNode 优化前会将其转化成一个可变的对象 Memo。在这个类中,所有的 PlanNode 被一个新的类 GroupReference 包装一层,这里的 GroupReference 仍然是不可变的,但它可以映射到可变的 Group,PlanNode 优化的过程实际上就是遍历 GroupReference 树,不断修改对应的 Group 里面的 PlanNode。
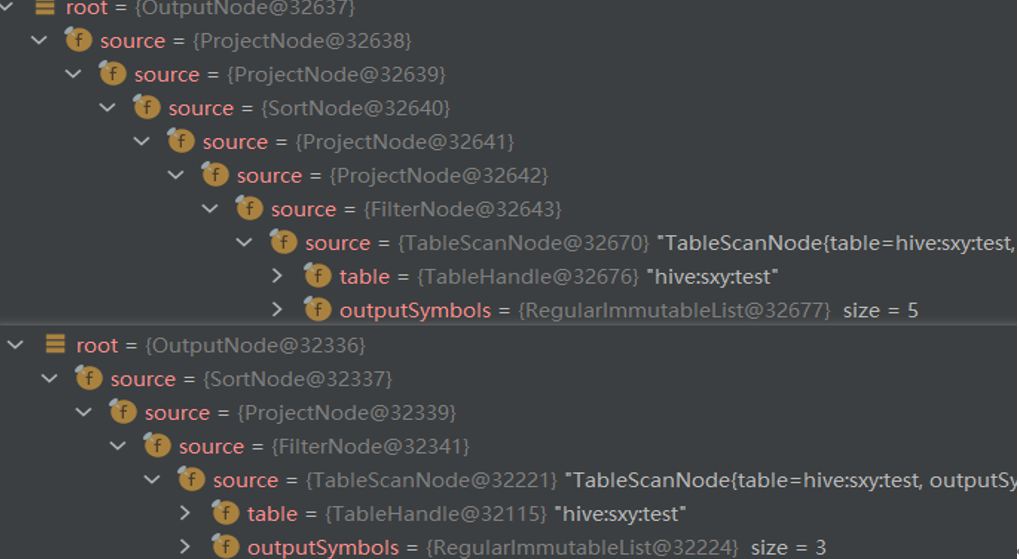
上述语句优化过程中还使用了 SetFlatteningOptimizer,合并能够合并的 union 节点,减少执行计划树层数。优化前后的执行计划树节点情况对比如下:
最后,使用 explain 命令查看执行计划。为了观察执行计划分段情况,执行如下语句:

如图,该条语句的执行计划分为两段,Source 阶段是从数据源的表中读取数据的阶段,一般有 TableScanNode 和 FilterNode 等,此处同时进行了局部聚合;有时局部聚合、局部 Join 等操作也会在 Source 之后的 Fixed 阶段中;最后是 Single 阶段,只在单个节点上执行以汇总所有的处理结果,例如最终聚合、全局排序等。先通过 filter 扫描表的数据处理 where 语句,然后进行排序。排序时采用的是分段排序再合并的思想。
openLooKeng 在生成查询计划后,会将其分段,拆分成多个有层级关系的 stage。在查询计划的调度与执行中,每个 stage 都会被进一步分解成若干个 task,分配到各个计算节点中执行。
查询调度
对于每一个 stage,openLooKeng 都生成一个对应的 SqlStageExecution 实例,称为调度执行器。对于 Single 和 Fixed 类型的 stage,均为调用 NodeSelector.selectRandomNodes。因此运行如下语句,主要观察 Source stage:select count(\*) from hive.sxy.test where salary >400;

在 io.prestosql.execution.SqlStageExecution 中的 NodeSelector 是查询调度的核心,维护了一个 nodeMap,由 nodeManager 获取存活的节点列表;同时维护一个保存当前分配的 task 和节点的映射的列表 nodeTaskMap。在查询请求中,一个 table 会对应一个 Source stage,而 Source Stage 的节点选择策略是由 table 中 spilt 的数目决定的,尽量使每个节点处理的 split 相对平均。在进行调度前,先由 selectExactNodes 方法选择出一批候选节点 candidateNodes:

接下来针对每个 source split 从候选节点中选择出满足条件的节点进行调度。遍历所有的 split,对于当前的 split,在 candidateNodes 范围内,选择出[历史已分配 split 个数 splitCountByNode]与[当前批次已分配 split 个数 assignmentCount]较小的节点。此二者之和定义为 TotalSplitCount,同时 TotalSplitCount 不能超过每个节点允许的最大数目 maxSplitsPerNode,如下图:

通过查看 split 计数 assignmentCount 或选择出的节点 chosenNode 均可发现,此查询计划的 splits 被轮流分配到 candidateNodes 中的两个节点上,以保证这两个节点基本上是对 splits 平均分配的。
查询执行
在制定与调度查询计划的过程中,openLooKeng 中的查询会依次转化为 SqlQueryExecution、SqlStageExecution、SqlTaskExecution。因此所有的查询最终都转化为若干 Task 在每一个 worker 节点上执行。
在创建 Task 时,调用 HttpRemoteTask 类的方法创建一个 RemoteTask 对象并启动其 start 方法,这个方法又会调用 httpClient 向 worker 节点发起 RESTful 请求,从而启动 SqlTaskExecution 进行数据处理。
Client 端
新 task 的创建是由 io.prestosql.execution.SqlStageExecution 类中的 scheduleTask 方法完成的,它的作用就是在指定的 Node 上启动一个 Task 并执行。以 SourceTask 为例,由于分批调度 Task,因此可能会多次调用这个方法。先判断对应的 Node 上是否已经创建 Task,若已经存在则直接 addNewTask(taskId)。

①:收集所有的 SourceSplit。将 Source Stage 传入参数中的 split 与上游 Stage 中每个 Task 的输出组合起来,作为整体的 split 集合 initialSplits。从代码可以看出,planNodeId 代表一个 Stage,遍历每个上游 Stage 中的每个 task,将其组装成一个 split 添加进 initialSplits 中。
②:更新当前 stage 的所有 outputBuffers,它用于将当前 stage 的数据传给下游 stage。
③:根据已有的 initialSplits、Node、taskId 等信息,在 Node 上创建一个 Task,并调用 task.start()启动 initialSplits 的处理。
Resource 端
收到 RESTful 请求后,对其的处理主要是 io.prestosql.server.TaskResource 类中的 createOrUpdateTask 方法完成。该方法会调用 SqlTaskManager 类中的 updateTask()方法:

该方法是通过全局缓存 tasks 的 getUnchecked(taskId)获取 SqlTask 对象的,获取到 SqlTask 对象后就会调用 SqlTask.UpdateTask()启动 Task 进行计算,此方法会更新 TaskId 所对应的 OutputBuffers 和待处理的 Split 列表。
从前面对 Task 创建过程的梳理可以发现,openLooKeng 中每个 Task 在 worker 端(即 TaskResource 端)是以 SqlTaskExecution 的形式运行的。
io.prestosql.execution.executor.TaskExecutor 类在每个 worker 节点启动的时候调用 start 方法运行,在该类中启动多个线程并加入线程池,每个 split 的处理都由一个内部类 TaskRunner 中的 split.process()完成:

该方法逐级调用,经过 PrioritizedSplitRunner.process()最终调用 split.processFor()。此处代码中 split 的类型为 SplitRunner,而查看 SqlTaskExecution 类中的设置可得其实现类为 DriverSplitRunner,作用在 split 上的一系列操作的封装类也为 Driver 类:

对 Split 的实际处理工作是由 Driver.processInternal()方法完成的。在该方法中,遍历所有的 operators,每次从 operators 中取出相邻的两个 operator,计算得到前一个 operator 的输出数据,然后将该数据作为后一个 operator 的输入数据:

扫码加小助手微信
进入社区交流群

