




索引基本概念
为了提高查询的速度,在 SQL 语言中提供了建立索引的命令。索引机制类似于书的目录,无需阅读整本书,利用目录就可以快速查找相关信息。数据库中的索引是建立在基本表上的,通过索引DBMS无须对整个表进行扫描,可以快速定位到要查找的元组记录。其工作过程是:当需要对表进行某些数据查找时,首先查找与该表有关的索引,当查到索引后,根据索引提供的信息直接可以找到所需的数据。在执行查询前,如果恰当地在列上建立了索引,则可以节省上千次、上万次,在极限情况下甚至节省百万次的磁盘 I/O。但是索引也需要占用空间和资源,来进行额外的处理和索引维护等工作。
索引基本类型
唯一索引
唯一索引在列中不允许重复的值出现,可以用来定义和约束表中的一列或者多列组合值,在执行 INSERT 和 UPDATE 语句时需要检查唯一性。GBase 8s 中的主键(PRIMARY KEY)会自动创建一个唯一的索引。一个良好的表设计都应该定义主键或者唯一约束索引。特别是在 OLTP 系统中,唯一索引可以帮助快速定位少量记录(目标选中的一条或者几条记录)。
--unique
CREATE UNIQUE INDEX idx_name ON tabname(col);
--distinct
CREATE DISTINCT INDEX idx_name ON tabname(col);
由于需要在 INSERT、UPDATE 时进行唯一性判断,所以不建议在一个表上创建多个唯一性索引。为了确保唯一性要求,一般在一张表中创建一个唯一索引就足够。
复合索引(组合索引)
简单索引是基于一个列或者函数创建的索引,与之相对应的是复合索引。复合索引也叫组合索引,即索引包含两个或者更多的列。GBase 8s 的复合索引最多支持 16 个索引列,列的总和大小要小于 390 bytes。
--创建col1,col2的复合索引
CREATE INDEX idx_name ON tabname(col1,col2);
采用复合索引可以减少索引的个数,增强索引的唯一性,同时可以提高基于多列组合的连接查询性能。例如,上面的索引可以提高如下查询语句的性能:
select * from tabname where col1=1 and col2='xxx';
在使用复合索引时,需要考虑索引占用空间、索引层次,特别是字段的区分度。否则会出现复合索引性能比单一索引性能低的情况。
函数索引
GBase 8s 支持函数索引,可以在列上使用自定义函数创建索引,用来解决一些应用系统中历史遗留的不良设计带来的性能问题。下面通过一个实际场景来说明函数索引的使用方法和注意事项。
有如下表和索引:
--表结构
create table car (car_number char(7),
color char(5), car_type char(6),
address varchar(128),reg_time datetime year to second);
--唯一索引
create unique index idx_unique_car on car(car_number);
表 car 的 car_numer 为车牌号,在多数情况下通过查询完整的车牌号如 津C1A376,可以快速查找到车辆。但是在实际的应用场景中,为了简化工作人员的输入,往往只输入之后的三位,那么此时使用如下 SQL 查询:
select * from car where car_numer like '%376';
--或
select * from car where substr(car_number,6,3)='376';
它们都不能利用到索引,而需要采用顺序扫描的方式检索数据。
为了提高查询效率,可以使用 GBase 8s 的函数索引。
(1)首先创建函数 f_car_num,该函数返回字符串从第 6 个字符开始的 3 个字符。注意,由于需要使用该函数创建索引,所以 GBase 8s 需要在创建函数时增加 WITH (NOTVARIANT)选项,省略时默认为 VARIANT。
CREATE FUNCTION f_car_num( i_str char(8))
RETURNING char(3) WITH (NOT VARIANT);
Return substr(i_str,6,3);
END FUNCTION;
(2)创建函数索引 idx_f_car_num,使用函数 f_car_num(car_number)
CREATE INDEX idx_f_car_num ON car(f_car_num(car_number));
使用函数索引时有一些注意事项和限制要求。除了前面提到的函数索引所创建的函数必须为 NOT VARIANT,函数必须是自定义函数,不能使用 GBase 8s 中的内置函数,比如UPPER、INSTR、SUBSTR 等。我们可以定义一个新的函数来封装内置函数,例如利用UPPER 定义 toUpper 函数:
CREATE FUNCTION toUpper( i_str varchar(100))
RETURNING varchar(100) WITH (NOT VARIANT);
Return UPPER(i_str);
END FUNCTION;
聚簇索引
聚簇索引也叫聚集索引,创建有聚簇索引的表时,表中数据是按照聚簇索引的索引列顺序存储的,如下图所示
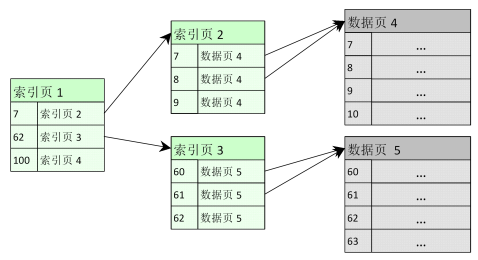
如图所示,聚簇索引的数据按照顺序存放,对于查询一个范围值的 SQL 语句或者多个 SQL 语句,在需要查询相邻记录时,采用聚簇索引的 I/O 效率较高。由于数据是按顺序存储的,所以磁盘扫描为连续顺序扫描的方式,在这种场景下聚簇索引比非聚簇索引的离散扫描磁盘方式效率要高。
由于聚簇索引要求表的记录按顺序存放,所以在插入、删除记录以及更新聚簇索引列的 UPDATE 操作时,需要进行数据的移动。对于 INSERT 操作,首先根据索引找到对应的数据页,然后通过挪动已有的记录为新数据腾出空间,最后插入数据。在删除数据时将导致其下方的数据行向上移动以填充删除记录造成的空白。对于数据的删除操作,可能导致在索引页中仅有一条记录,这时,该记录可能会被移至邻近的索引页中,原索引页将被回收,即所谓的“索引合并”。聚集索引的建立会严重降低数据插入和删除的效率。
--在customer 表上创建了一个索引,并按行的邮政编码对行做物理的升序(缺省的)排序。
CREATE CLUSTER INDEX c_clust_ix ON customer (zipcode);
如果指定了 CLUSTER 选项并且数据中存在分片,则仅在每个分片内集群数据值,而非在整个表全局集群数据值。
因此,聚簇索引能提高区间查询的查询性能,但会大大降低插入和删除记录的效率。在使用聚簇索引之前,一定要对表中记录的新增、删除和更新情况有全面了解,权衡后再创建。一般只建议在静态的表(表的记录不变化或者很少变化)上创建聚簇索引,避免在经常进行记录 INSERT/DELETE/UPDATE 操作的表上创建聚簇索引。
索引分片
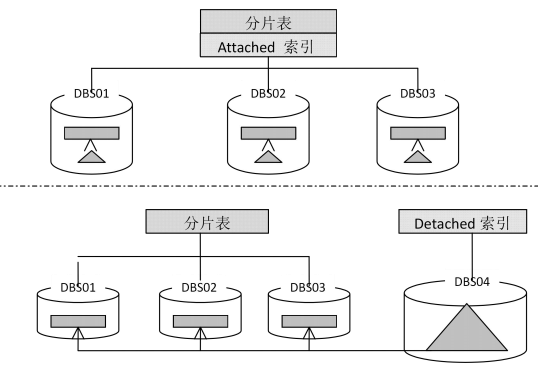
GBase 8s 的索引分为 attached 和 detached 两种,attached 即数据与索引存放在相同的dbspace 上或者采用相同的分片策略,严格地讲 attached 索引是指每个分片的数据都有对应的索引独立存在。detached 即索引和数据存储在不同的 dbspace 上。如图所示,图的上半部分为 attached 索引,表中每一个分片的数据都有一个对应的分片索引;下部分为detached索引,索引存储在独立的 dbspace 上,并且索引所有分片的数据或者一个全局的索引。
--e.g1:轮转分片法
CREATE TABLE frag_rb_tab(
sale_time datetime year to second,
product_id int,
product_time datetime year to second,
price float,
sale_amount int
)FRAGMENT BY ROUND ROBIN IN
datadbs01, datadbs02, datadbs03, datadbs04;
--创建索引,默认为attached索引
CREATE INDEX idx_frag_rb_tab ON frag_rb_tab(sale_time,product_id);
--e.g2:表达式分片
CREATE TABLE frag_exp_tab(
sale_time datetime year to second,
product_id int,
product_time datetime year to second,
price float,
sale_amount int
) FRAGMENT BY EXPRESSION
sale_time < '2012-01-01 00:00:00' AND sale_time>= '2011-01-01 00:00:00' IN datadbs01,
sale_time < '2011-01-01 00:00:00' AND sale_time>= '2010-01-01 00:00:00' IN datadbs02,
sale_time < '2010-01-01 00:00:00' AND sale_time>= '2009-01-01 00:00:00' IN datadbs03,
sale_time < '2009-01-01 00:00:00' AND sale_time>= '2008-01-01 00:00:00' IN datadbs04;
/*idx_frag_exp_tab 和idx_frag_exp_tab2 都是 attached 索引,
即在每一个 dbspace 上创建一个单独的索引来索引该分片上的数据,相当于一个分片索引*/
CREATE UNIQUE INDEX idx_frag_exp_tab ON frag_exp_tab(sale_time,product_id);
CREATE INDEX idx_frag_exp_tab2 ON frag_exp_tab(product_time,product_id);
--对索引进行分片
CREATE UNIQUE INDEX idx_frag_exp_tab ON frag_exp_tab(sale_time,product_id)
FRAGMENT BY EXPRESSION
sale_time < '2012-01-01 00:00:00' AND sale_time>= '2011-01-01 00:00:00' IN datadbs06,
sale_time < '2011-01-01 00:00:00' AND sale_time>= '2010-01-01 00:00:00' IN datadbs07,
sale_time < '2010-01-01 00:00:00' AND sale_time>= '2009-01-01 00:00:00' IN datadbs08,
sale_time < '2009-01-01 00:00:00' AND sale_time>= '2008-01-01 00:00:00' IN datadbs09;
--存储在单独的dbspace,所以为detached索引
CREATE INDEX idx_frag_exp_tab2 ON frag_exp_tab(product_time,product_id) in bigdatadbs;
- 在默认情况下,GBase 8s 对分片表(轮转法、基于表达式法)所创建的索引都采用 attached 索引;
- 在默认情况下,GBase 8s 对分片表上创建的主键、外键、唯一约束,自动创建一个 unique、detached 索引;
- 在分片表上,GBase 8s 支持创建一个 unique、detached 索引,因为唯一索引要求全局唯一;
- 在分片表上,如果要创建一个 unique、attached 索引,则需要在索引中包含分片的 key 字段,所以能在基于表达式的分片表上创建一个包含分片 key 字段的unique、attached 索引。轮转法则只能创建一个 unique、detached 索引,否则报-872 错误。
