




一、Latch通用数据结构
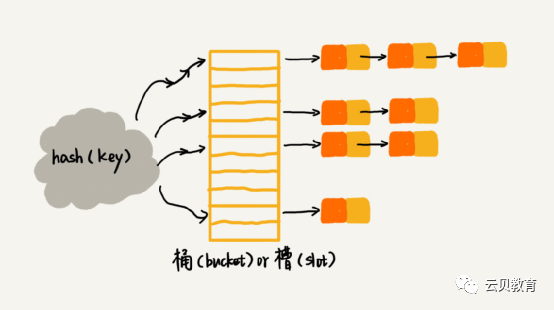
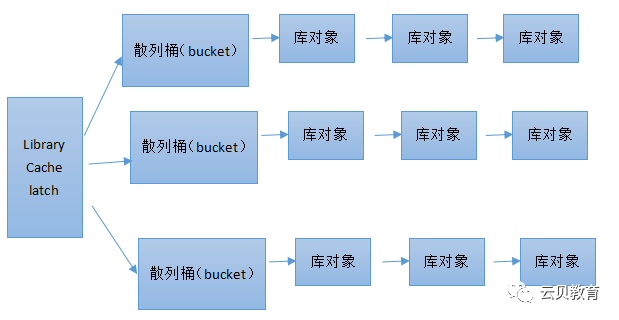
Library cache:库缓存
Library cache latch,库缓存闩锁。
为什么需要这个闩锁呢。其实就是问共享池内存数据为什么需要被保护。也就是为什么内存数据会涉及到DML,如果是只读的,且不修改任何属性,也就不存在问题。
我们知道共享池用于缓存执行计划,数据字典缓存,SQL结果集和函数缓存,而缓存是有大小的,那些使用次数最少的缓存会从内存中老化退出。也就是针对上图的hash table,链表中的数据会被清除掉,而新的缓存又不断加入进来,所以这个链表会动态变化,修改链表的next值等于next的next的时候(其实是双向链表,所以还有last),如果这时还有会话去访问此链表,那么就会有问题。相当于读的时候,不能写,写的时候不能读。这不就是共享锁和排它锁吗?
但是Oracle的锁(lock),是用于保护磁盘数据,如果要处理高速内存数据,机制太慢,我们需要一个轻量级的内存锁-闩(lacth),要求获取和释放时间都极短,去保护内存的数据。Lock最主要是需要排队,而latch谁在一个时间片内抢到了就算谁的。
锁和闩分别对应视图v$lock和v$latch。除此之外我们还有互斥锁,pin锁,DDL锁,自定义锁。我们的hash table的数组上,每一个桶都有一个互斥锁(如果是保护lock的latch,则每个桶上还会有latch锁,比如enqueue hash chains),而pin锁会锁链表上的每一个节点。比如链表节点存储了执行计划,为了防止你正在使用执行计划EXECUTE SQL的时候,系统把此节点从链表删除.
我们主要关注桶前面的library cache latch锁
Latch 分类
1.愿意等待:如果获取不到闩,会话休眠,然后再次尝试。休眠时间称之为latch free wait time。library cache latches主要是愿意等待模式
2.立即:如果当前进程获取不到闩,转而获取另一个闩,直到所有闩的都获取失败。
Latch视图分析
正常情况misses= spin_gets+sleeps
获取闩锁的顺序
1.成功获取,然后释放
2.获取失败->自旋->自旋超过spin_count,开始从CPU调度出去,开始休眠->休眠完毕唤醒,继续获取->(1获取又失败misses+1,->自旋->……睡眠时间上升)->(2成功获取gets+1,然后释放)
监测latch: library cache
SELECTsid, serial#, osuser, programFROM v$sessionWHEREsidIN (SELECT blocking_sessionFROM v$sessionWHERE event = 'latch: library cache');
查询高子游标计数和高版本sql
SELECTDISTINCT sql_id FROM v$sql_plan WHERE child_number >= 300SELECT sql_id, version_count, sql_textFROM v$sqlareaWHERE version_count > 300;
查询高绑定变量sql
SELECTAVG(bind_count) avg_num_bindsFROM (SELECT sql_id, COUNT(*) bind_countFROM v$sql_bind_captureWHERE child_number = 0GROUPBY sql_id);SELECT *FROM (SELECT sql_id, COUNT(*) bind_countFROM v$sql_bind_captureWHERE child_number = 0GROUPBY sql_id)HAVING bind_count >=300
再次讨论latch: cache buffers chains
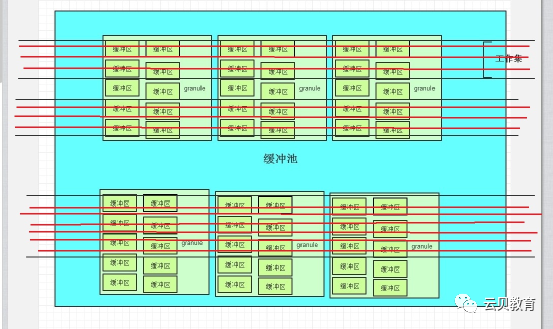
下图是块缓冲区的各个缓冲池示意图
select * from v$sgainfo where name='Granule Size';
SELECT s.component,s.current_size 1024 1024 current_size,s.granule_size 1024 1024 granule_sizeFROM v$sga_dynamic_components sWHERE s.component in ('DEFAULT buffer cache','shared pool')COMPONENT CURRENT_SIZE GRANULE_SIZE1 shared pool 240 42 DEFAULT buffer cache 28 4
可以看到共享池240M,60个粒度,块缓冲区默认池28M,也就是7个粒度
查询块缓冲区粒度的链表
SELECT ge.grantype,ct.component,ge.granprev,ge.grannum,grannextFROM x$ksmge ge,x$kmgsct ctWHERE ge.grantype != 6AND ct.grantype = ge.grantypeand ct.component='DEFAULT buffer cache'GRANTYPE COMPONENT GRANPREV GRANNUM GRANNEXT1 9 DEFAULT buffer cache 0 63 642 9 DEFAULT buffer cache 63 64 653 9 DEFAULT buffer cache 64 65 664 9 DEFAULT buffer cache 65 66 675 9 DEFAULT buffer cache 66 67 686 9 DEFAULT buffer cache 67 68 697 9 DEFAULT buffer cache 68 69 0
GRANNEXT指向下一个粒度的指针,GRANNUM是当前指针,从上图可以看到按顺序排列,所以可以得出结论,我的块缓冲区没有动态调整过,当然因为我启用的是手动SGA内存管理。缓冲池内的所有的GRANULE双向链表串联起来组成大的缓冲池。
--查询所有内存组件的粒度
SELECT ct.component,COUNT(1) * 4FROM x$ksmge ge,x$kmgsct ctWHERE 1 = 1AND ct.grantype = ge.grantypeGROUP BY ct.component
SELECT s.component,s.current_size 1024 1024 current_size,s.granule_size 1024 1024 granule_sizeFROM v$sga_dynamic_components sWHERE s.component in ('DEFAULT buffer cache','shared pool')
select * from v$buffer_pool;
LRU
我们的缓冲池里面的缓冲区个数是固定的,缓冲区链由工作集管理,当新的数据进入内存的时候,如何决定哪些缓冲区需要clear,LRU(Least recently used)算法就是最近最少被使用缓冲区应该被老化退出。
回到我们的工作集
SELECT k.cnum_set --工作集中缓存区数量,k.set_latch --cache buffer latch地址,k.cnum_repl --缓冲区数量总和,k.nxt_repl--最多使用的缓冲区,缓冲区链的热端(链表头部),k.prv_repl--最少使用的缓冲区,缓冲区链的冷端(链表尾部),k.cold_hd --缓冲区头部链表冷热分界点,K.NXT_REPLAX--备用链头部,备用链比主链少了刷新脏块,获取和释放pin,所以从备用链获取可老化的缓冲区比主链更快--一般而言,备用链头部链接在k.prv_repl对应的主链的尾部,K.PRV_REPLAX--备用链尾部,k.addr--等于x$bh.set_ds 表示此工作集有多少缓冲区FROM x$kcbwds k;
我们只关注主链,这个表的每一行就是一个工作集,由链表头部nxt_repl和链表尾部prv_repl决定的链表就是缓冲区头部链表,那么此链表的每一个节点就是代表一个个缓冲区。
缓冲区头部可以简单理解成缓冲区的指针,所以后面遇到缓冲区还是缓冲区头部,可以理解他们都是指代同一个东西,就是缓冲区。每个缓冲区内部里面有很多block。

上面的链表就是cache buffer lru chain 链表,每一个缓冲区上有一个TCH接触计数,这个TCH的修改机制比较复杂,这里不详细描述,所以我们简化一下,可以简单看成,链表左边的TCH较高,越往右越低,温度较低的缓冲区是从内存老化的优先选择对象。
(TCH计算逻辑并不是访问一次就+1,这里不详细讨论,只是大概表达意思)
而我们下面要讲到的cache buffer chain ,虽然节点还是一样的,都是缓冲区,不过他们能链接到一个链表上完全是因为hash 散列的结果,所以这个cache buffer chain链上的温度排列并不是左边的最高,右边的越低
Latch锁
这里的key值简单等价为块号,传入的桶对应的链表就是缓冲区,也就是上图链表中的矩形节点。我们顺序读,读入一个BLOCK,然后通过散列函数,计算出它应该放入那个桶中,然后按某种规则加入到缓冲区链表中。
桶1 | ------- | 缓冲区1 | 缓冲区2 | 缓冲区3 | |
桶2 | ------- | 缓冲区4 | 缓冲区5 | ||
桶3 | ------- | 缓冲区6 | 缓冲区7 | ||
桶4 | ------- | 缓冲区8 | |||
桶5 | ------- | 缓冲区9 | |||
桶6 | ------- | 缓冲区10 | 缓冲区11 | 缓冲区12 | 缓冲区13 |
工作集1 | 缓冲区3 | 缓冲区5 | 缓冲区1 | 缓冲区10 | |
| 缓冲区8 | 缓冲区2 | 缓冲区7 | ||
工作集2 | 缓冲区4 | 缓冲区6 | 缓冲区9 | 缓冲区11 | |
| 缓冲区13 | 缓冲区12 |
颜色越淡,表示越冷,因此备选缓冲区是2,我们需要修改缓冲区2的数据,回顾我们的库缓存latch,修改前必须要对其加锁,所以改造一下我们的缓冲区hash链
latch1 | 桶1 | ------- | 缓冲区 | 缓冲区 | 缓冲区 | |
桶2 | ------- | 缓冲区 | 缓冲区 | |||
latch2 | 桶3 | ------- | 缓冲区 | 缓冲区 | ||
桶4 | ------- | 缓冲区 | ||||
latch2 | 桶5 | ------- | 缓冲区 | |||
桶6 | ------- | 缓冲区 | 缓冲区 | 缓冲区 | 缓冲区 |
我们必须首先获取桶1和桶2对应的latch1,然后再去修改桶1的缓冲区链表,这个latch就是标题的latch:cache buffers chains 既然是我们熟悉的latch锁,回想一下
Misses,spin_gets,sleeps这些关键词,一旦我们有两个SQL访问的块位于同一个latch管辖的桶内,这两个SQL又都在大量进行buffer gets,他们都会争抢latch锁,最后造成此等待事件。
此时我们假如获取到了latch1,同时通过LRU链我们选择把数据放在缓冲区2中,先pin住缓冲区2,如果不能pin住,则需要等待,此时触发等待事件 buffer busy wats 成功获取pin之后释放闩锁,再缓存我们的数据(这里都不考虑一致性读情况),然后获取闩锁,解除pin,再解除latch锁,完成访问。(LRU链也发生了更新,所以LRU上也会有LATCH锁去控制,这里不详细讨论)
重现latch: cache buffers chains
SELECT addrFROM v$latch_childrenWHERENAME = 'cache buffers chains'ANDrownum = 1;然后查一下这个buffer header 链上都有哪些块的数据SELECT e.owner || '.' || e.segment_name segment_name,e.file_id,e.extent_id extent#,x.dbablk,x.dbablk - e.block_id + 1 block#,x.tch,l.child#,l.gets,l.misses,l.sleeps,l.wait_time 1000000 3600,l.latch#,l.hashFROM v$latch_children l,x$bh x,dba_extents eWHERE1 = 1AND l.addr = '000000006BDE6660'AND e.file_id = x.file#AND x.hladdr = l.addrAND x.dbablk BETWEEN e.block_id AND e.block_id + e.blocks - 1ORDERBY x.tch DESC;
SEGMENT_NAME | FILE_ID | EXTENT# | DBABLK | BLOCK# | TCH | CHILD# | GETS | MISSES | SLEEPS |
SYS.AQ$_SUBSCRIBER_LWM | 1 | 0 | 17432 | 1 | 4 | 1024 | 66047 | 0 | 0 |
SYS.C_OBJ# | 1 | 17 | 12264 | 105 | 0 | 1024 | 66047 | 0 | 0 |
SYS.OPTSTAT_SNAPSHOT$ | 1 | 20 | 118530 | 3 | 0 | 1024 | 66047 | 0 | 0 |
SYS.SYS_C003253 | 1 | 0 | 20016 | 1 | 1 | 1024 | 66047 | 0 | 0 |
select * from SYS.AQ$_SUBSCRIBER_LWM where rownum=1;
第二行是一个聚簇,与索引聚簇表有关,第4行是一个索引,这里我们没有函数去查询索引块对应的数据是哪一行,第三行是一个表,因此用第三行对应的表测试。
select * from dba_extents d where d.file_id=1 and d.extent_id=20;
OWNER | SEGMENT_NAME | PARTITION_NAME | SEGMENT_TYPE | TABLESPACE_NAME | EXTENT_ID | FILE_ID | BLOCK_ID | BYTES | BLOCKS |
SYS | OPTSTAT_SNAPSHOT$ |
| TABLE | SYSTEM | 20 | 1 | 118528 | 1048576 | 128 |
SELECT ROWID,dbms_rowid.rowid_block_number(ROWID)FROM sys.optstat_snapshot$ sWHERE dbms_rowid.rowid_block_number(ROWID) - 118528 <= 3AND dbms_rowid.rowid_block_number(ROWID) - 118528 >= 0;
因此直接按ROWID排序,取前1000行数据
select * from (select * from sys.optstat_snapshot$ order by rowid ) where rownum<=1000;
因此改造这两个SQL,期望重现latch锁等待事件
窗口1:
--SELECT userenv('sid') FROM dual;--470declarecursor a_cur isselect * from SYS.AQ$_SUBSCRIBER_LWM whererownum=1;beginfor i in1..1000000 loopfor a_rec in a_cur loopnull;endloop;endloop;end;
窗口2:
--SELECT userenv('sid') FROM dual; --467declarecursor a_cur isselect * from (select * from sys.optstat_snapshot$ orderbyrowid ) whererownum<=1000;beginfor i in1..10000 loopfor a_rec in a_cur loopnull;endloop;endloop;end;
执行后查看等待事件表
SELECT * FROM v$session_wait s WHERE s.sid IN (467, 470)
SID | SEQ# | EVENT | P1TEXT | P1 | P1RAW |
467 | 1938 | direct path write temp | file number | 201 | 00000000000000C9 |
470 | 431 | latch: cache buffers chains | address | 1809474512 | 000000006BDA63D0 |
1.找到一个latch锁,其中包含表数据
SELECT l.addr, e.owner || '.' || e.segment_nameFROM v$latch_children l, x$bh x, dba_extents eWHERE1 = 1AND e.file_id = x.file#AND x.hladdr = l.addrAND x.dbablk BETWEEN e.block_id AND e.block_id + e.blocks - 1AND e.segment_type = 'TABLE'AND e.tablespace_name <> 'SYSTEM'
2.随便取一个latch,将此latch地址传入
SELECT e.owner || '.' || e.segment_name,segment_name,l.addr,e.extent_id extent#,x.dbablk,x.dbablk - e.block_id + 1 block#,x.tch,l.child#,l.gets,l.misses,l.sleeps,l.wait_time 1000000 3600,l.latch#,l.hashFROM v$latch_children l,x$bh x,dba_extents eWHERE l.addr in ('0000001934656D68')AND e.file_id = x.file#AND x.hladdr = l.addrAND x.dbablk BETWEEN e.block_id AND e.block_id + e.blocks - 1
SEGMENT_NAME | DBABLK |
MTL_SYSTEM_ITEMS_B | 3219221 |
PO_REQUISITION_LINES_ALL | 1738115 |
3.通过块号找到缓存的ROWID
SELECTROWID,dbms_rowid.rowid_block_number(ROWID)FROM MTL_SYSTEM_ITEMS_B sWHERE dbms_rowid.rowid_block_number(ROWID) = 3219221;SELECTROWID,dbms_rowid.rowid_block_number(ROWID)FROM PO_REQUISITION_LINES_ALL sWHERE dbms_rowid.rowid_block_number(ROWID) =1738115
4.开两个窗口循环取数
--2266DECLARECURSOR a_cur ISSELECT *FROM po_requisition_lines_all msiWHEREROWID IN ('AAAdlDAIbAAGoWDAAA','AAAdlDAIbAAGoWDAAB','AAAdlDAIbAAGoWDAAD','AAAdlDAIbAAGoWDAAC','AAAdlDAIbAAGoWDAAG','AAAdlDAIbAAGoWDAAF','AAAdlDAIbAAGoWDAAE','AAAdlDAIbAAGoWDAAI','AAAdlDAIbAAGoWDAAH','AAAdlDAIbAAGoWDAAK','AAAdlDAIbAAGoWDAAJ','AAAdlDAIbAAGoWDAAM','AAAdlDAIbAAGoWDAAL');BEGINfor i in1..100000 loopFOR a_rec IN a_cur LOOPNULL;ENDLOOP;endloop;END;--4045DECLARECURSOR a_cur ISSELECT *FROM mtl_system_items_b msiWHEREROWID IN ('AAQ54NAKNAAMR8VAAA','AAQ54NAKNAAMR8VAAC','AAQ54NAKNAAMR8VAAE','AAQ54NAKNAAMR8VAAG','AAQ54NAKNAAMR8VAAI','AAQ54NAKNAAMR8VAAK','AAQ54NAKNAAMR8VAAM','AAQ54NAKNAAMR8VAAO');BEGINFOR i IN1 .. 100000LOOPFOR a_rec IN a_cur LOOPNULL;ENDLOOP;ENDLOOP;END;
5.查询等待事件
select * from v$session_wait s where s.sid in (4045,2266);
SID | EVENT | P1RAW |
2266 | latch: shared pool | 60292678 |
4045 | latch: shared pool | 00000000602922B8 |
select * from V$SESS_TIME_MODEL s where s.SID in (4045,2266) orderbyvaluedesc;
硬解析花费时间并不严重,所以这个等待事件可能是我第一次装载此SQL,同时绑定变量过多导致,再次重复执行
SID | EVENT | P1 |
2266 | SQL*Net message from client | 1952673792 |
4045 | latch free | 107898301512 |
出现了latch free,这个包括了所有的闩锁现象,如果我们对此会话开启了跟踪,并打开原始trace文件,搜索latch free
WAIT #1: nam='latch free' ……number=228
搜索此number号
select * from v$latchname l where l.latch#=228LATCH# NAME DISPLAY_NAME HASH CON_ID1 228 cache buffers chains cache buffers chains 3563305585 0
SID | EVENT | P1 |
2266 | SQL*Net message from client | 1952673792 |
4045 | SQL*Net message from client | 1952673792 |
符合我们的预测
