




原理:如果我们有一个长时查询,比如需要执行10分钟,从9点整开始执行查询,到9点10分返回结果。
9点整的数据如下:
select value from table where name=’a’
name | value |
a | 1 |
如果这十分钟内有人修改了数据(不管有没有提交)
name | value |
a | 2 |
但是我们上述的select查询结果仍然要是1,因为要保持一致性读。一致性读的意思是,执行查询的时刻数据是1,查询结束后,返回结果也要是1。
那么数据库是怎么让我们能得到原始的结果呢?(即使有人在9:05修改了数据并提交)原因是我们使用undo段“缓存”历史数据(这里的缓存其实是写入磁盘的意思,而不是在内存中缓存),当9:05分,执行update后,会将原始数据写入undo段(段都在磁盘上)中,执行查询时,去undo段上找最新的数据,找到了value=2,然后再看一下,value=2的时间是否是对应9点整的,不是的话,找第二新的数据,……重复这段过程,最后找到了9点整的value=1数据。
undo段也是有大小的,可记录的数据有限,也就是说,你重复找的次数不会超过某个值,假设针对某一行数据,undo段只缓存8个块的内容,一个块是默认8K,每一行假设是1K的数据,当你在9:00到9:10重复更新该行65次,undo段回滚查询不到第1次的数据了(因为只有8*8k=64K的”缓存“,“缓存”满之后,又执行了更新,就会把最早的数据覆盖),就会报错:快照过旧,因为找不到当时的数据,无法满足一致性读要求,查询失败。
一般情况下,如果我们采用手动undo管理,undo段大小固定,则查询时会重用undo段,新的“缓存”会覆盖旧的。如果我们采用自动undo管理,则undo段快满时会自动扩展当前大小(是否在低负载的时候自动收缩未知),也就是说旧的“缓存”不会被清理,新的undo一直写入,按道理说,不会出现快照过旧错误,但是undo信息不可能从数据库第一次dml操作后,就一直记录,如果真的这么做,那么undo文件将比数据文件大几百上千倍。对于数据库层面,采用自动undo管理,通过参数undo_retention控制undo信息存留时间,这个值一般是900秒=15分钟。
所以,如果一个sql语句查询超过15分钟,极有可能会出现快照过旧,当然可供分配undo段太小,即使是自动undo管理,可能都等不到15分钟,undo段用完了,开始进行覆盖写,马上就会出现快照过旧。
(我们rollback回到原始数据,也是去undo段上找,然后回滚,所以undo段也叫回滚段,回滚delete,就是从undo段找原始数据做insert.回滚insert,就是找到原始数据,做delete,所以insert生成的undo信息最少,delete最多)。
查看当前undo管理模式

Auto表示自动undo管理。
查询每个undo留存时间

900单位是秒
查看当前undo所在表空间

查看表空间详细信息

说明undo表空间对应的物理文件是有限制的

表示undo表空间对应的数据文件可自动扩展
SELECT *FROM v$undostat uWHERE 1=1and u.ssolderrcnt > 0
重现:接下来重现一下快照过旧错误
我的测试环境是自动undo管理,undo_retention是15分钟,由于采用undo段自动扩展,且undo表空间大小为2147483645/1024/1024/1024=2G大小。
正常情况下出现快照过旧有点难,我只能创建一个很小的undo段,且不支持自动扩展,然后循环修改数据,让undo段用完之后,开始覆盖最老的undo信息,为了维持一致性读,去循环找历史undo信息,找不到就报错。测试脚本如下,仅供参考。
SQL> show parameters UNDO_NAME TYPE VALUE------------------------------------ ----------- ------------------------------temp_undo_enabled boolean FALSE--用于临时表的UNDO写入临时表空间中,而不是UNDO表空间undo_management string AUTOundo_retention integer 900undo_tablespace string APPS_UNDO_TEST
1.create undo tablespace apps_undo_testdatafile '/usr/local/oracle19c/oradata/ORCL/APPS_UNDO_TEST_TABLESPACE.dbf'--此路径可能和你们测试环境不一致,请用dba_data_files查询应该放置在哪size 100k--实测最小100多kautoextend off;--禁止扩展,即使我的undo_retention是900秒,在非自动扩展的undo表空间,undo_retention设置失效2.show parameters UNDO_TABLESPACE--事先记录下当前的表空间是什么,方便实验结束恢复alter system set undo_tablespace =apps_undo_test;--设置为较小的undo表空间3.--查看undo数据文件信息SELECT SUM(bytes) / 1024 / 1024 || 'm'FROM dba_data_filesWHERE tablespace_name = 'APPS_UNDO_TEST';4.创建索引,使得update的时候产生更多的undo,更好模拟快照过旧Create table dba_objects_test as select * from dba_objects;Create index dba_objects_test_n1 on dba_objects_test(object_id);CREATE OR REPLACE FUNCTION sleep_time(p_time IN NUMBER) RETURN NUMBER ISBEGINdbms_lock.sleep(p_time);RETURN p_time;END;一个窗口下执行查询DECLARECURSOR a_cur ISSELECT *FROM dba_objects_test tWHERE 1 = 1-- AND ROWID = 'AAAWVDAAFAAAAaTAAA'--这个注释去掉或者不去都会产生快照过旧错误,测试的时候请自行替换自己系统的ROWIDAND sleep_time(30) = 30;--模拟长时间运行的SQL,这个游标30秒后返回数据,但取出来的数据还是30秒前的,所以假如你们测试系统不能自己创建undo表空间并切换表空间,可以尝试把这个 AND sleep_time(30) = 30 改成 AND sleep_time(1000) =1000i NUMBER := 0;BEGINFOR a_rec IN a_curLOOPNULL;END LOOP;END;--另一个窗口下执行修改DECLAREg_total_undo_size NUMBER := 0;CURSOR a_cur ISSELECT ROWID FROM dba_objects_test;PROCEDURE print_undo_size ISl_undo_size NUMBER;BEGINBEGINSELECT t.used_ublk * 8 --返回KBINTO l_undo_sizeFROM v$session s,v$transaction tWHERE s.saddr = t.ses_addrAND s.sid = userenv('SID');EXCEPTIONWHEN OTHERS THENl_undo_size := 0;END;g_total_undo_size := g_total_undo_size + l_undo_size;dbms_output.put_line(l_undo_size);EXCEPTIONWHEN OTHERS THENdbms_output.put_line(SQLERRM);END;BEGINFOR a_rec IN a_curLOOPCOMMIT; --如果去掉这个commit,将会报错ora-01552或ORA-30036因为为了保证能够回滚,原有undo段是不能被覆盖的,而我们undo只有1m,又不能自动扩展--如果不能保证undo段全部被覆盖,那么不一定能产生快照过旧错误BEGIN--打印此事务产生的undo-- print_undo_size;--commit之后肯定是0,或者自行修改,获取所有的事务的undoUPDATE dba_objects_testSET object_id = dbms_random.valueWHERE ROWID = a_rec.rowid;print_undo_size;EXCEPTIONWHEN OTHERS THENprint_undo_size;dbms_output.put_line(SQLERRM);RETURN;END;END LOOP;dbms_output.put_line(g_total_undo_size);END;5.实验完毕恢复修改alter system set undo_tablespace =UNDOTBS1;--恢复原始的undo表空间,原始的表空间是什么请事先在command 中执行,show parameters UNDO_TABLESPACE,如果 恢复不了,按上面的步骤再创建一个自定义的undo表空间。
不过写之前要意识到,不仅select语句会出现快照过旧,update+where,delete +where,还有insert+where,都是先查再增删改,因此都会出现快照过旧错误。
还有一种触发ora-01555的情况可以自行搜索“延迟块清除”,因为比较少见,所以不做讨论。
解决办法:
1.最直接的方法,检查可用的undo段够不够用,是自动管理还是手动管理,是否支持扩展,增加数据文件max_size需要dba协助操作。
2.增大undo_retention值,alter system set UNDO_RETENTION=9000;--150分钟或者设置更大的值,可以参考v$undosta表信息(https://docs.oracle.com/cd/B19306_01/server.102/b14237/dynviews_2174.htm#REFRN30295)
3.优化你的查询,由于查询时间太长(一般是报表程序),导致该时间内,查询开始时刻undo信息已被覆盖,才会出现快照过旧错误。同时检查该时刻哪些程序在进行大量dml操作。所有的dml都是共用一个undo段,因此你批量改表B,也会导致查表A的时候发生这个错误。
4.使用v$undostat,可以找到期间内运行时间最长的 SQL 语句的 SQL 标识符和标识期间内并发执行的最高事务数
疑问点:
这个一致性读到底是读的内存的undo block,还是磁盘上的undo segment。我做上面的试验是基于磁盘的undo segment的假设。所以即使没有刷新buffer cache,也能出现快照过旧,后续有时间通过dump段头信息继续分析。
下图附上update的过程:1创建改变向量(undo vector,table vector),合并成改变record->2刷日志缓冲区(内存)->3修改undo块(磁盘)->4修改数据块(磁盘)
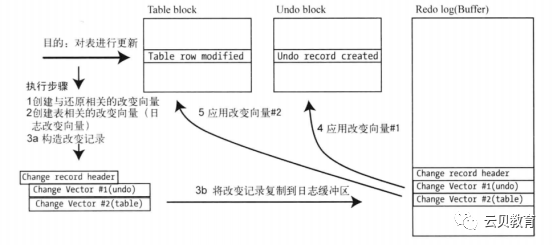
参考链接
